Apache Spark: Reading Data - CSV Files
Preparing for Databricks Certified Associate Developer for Apache Spark 2.4 with Python 3
Technical Accomplishments:
Read data from:
- CSV without a Schema.
- CSV with a Schema.
Read data from ‘CSV’ file
There are a couple of things to note here:
- The file has a header.
- The file is tab separated (we can infer that from the file extension and the lack of other characters between each “column”).
- The first two columns are strings and the third is a number.
Knowing those details, we can read in the “CSV” file.
Step #1 - Read The CSV File
Let’s start with the bare minimum by specifying the tab character as the delimiter and the location of the file:
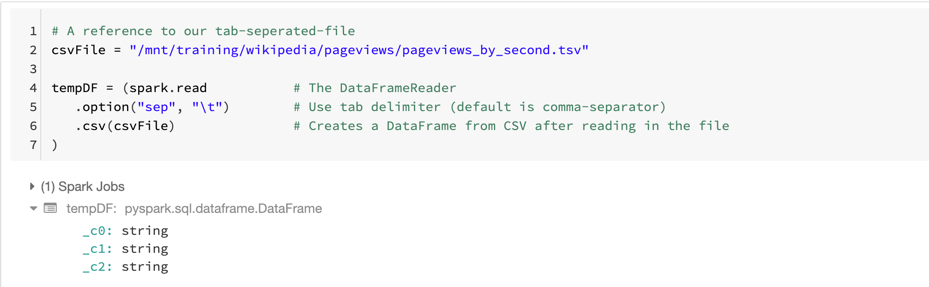
# A reference to our tab-seperated-filecsvFile = "/mnt/training/wikipedia/pageviews/pageviews_by_second.tsv"tempDF = (spark.read # The DataFrameReader.option("sep", "\t") # Use tab delimiter (default is comma-separator).csv(csvFile) # Creates a DataFrame from CSV after reading in the file)
This is guaranteed to trigger one job.
A Job is triggered anytime we are “physically” required to touch the data.
In some cases, one action may create multiple jobs (multiple reasons to touch the data).
In this case, the reader has to “peek” at the first line of the file to determine how many columns of data we have.
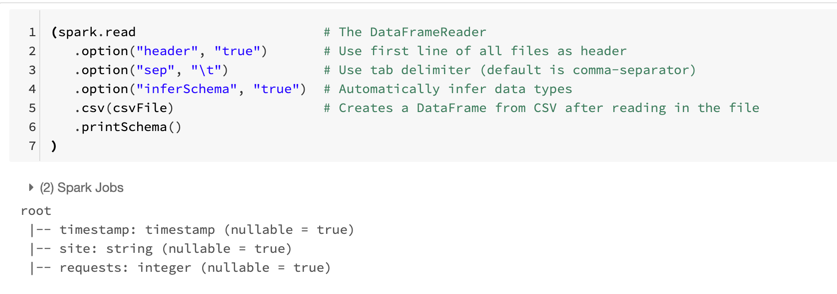
We can see the structure of the DataFrame by executing the command printSchema()
It prints to the console the name of each column, its data type and if it’s null or not.
We can see from the schema that…
- there are three columns
- the column names _c0, _c1, and _c2 (automatically generated names)
- all three columns are strings
- all three columns are nullable
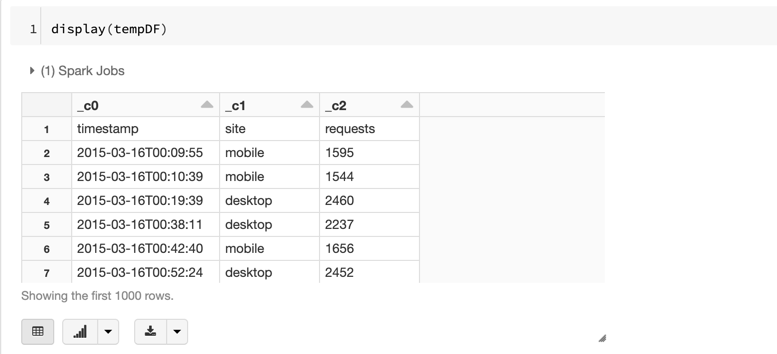
And if we take a quick peek at the data, we can see that line #1 contains the headers and not data:
Step #2 - Use the File’s Header
Next, we can add an option that tells the reader that the data contains a header and to use that header to determine our column names.
NOTE: We know we have a header based on what we can see in “head” of the file from earlier.

A couple of notes about this iteration:
- again, only one job
- there are three columns
- all three columns are strings
- all three columns are nullable
- the column names are specified: timestamp, site, and requests (the change we were looking for)
A “peek” at the first line of the file is all that the reader needs to determine the number of columns and the name of each column.
Before going on, make a note of the duration of the previous call - it should be just under 3 seconds.
Step #3 - Infer the Schema
Lastly, we can add an option that tells the reader to infer each column’s data type (aka the schema)
 Reading from CSV w/User-Defined Schema
Reading from CSV w/User-Defined Schema
This time we are going to read the same file.
The difference here is that we are going to define the schema beforehand and hopefully avoid the execution of any extra jobs.
Step #1
Declare the schema.
This is just a list of field names and data types.
# Required for StructField, StringType, IntegerType, etc.from pyspark.sql.types import *csvSchema = StructType([StructField("timestamp", StringType(), False),StructField("site", StringType(), False),StructField("requests", IntegerType(), False)])
Step #2
We can specify the schema, or rather the StructType, with the schema(..) command:
(spark.read # The DataFrameReader.option('header', 'true') # Ignore line #1 - it's a header.option('sep', "\t") # Use tab delimiter (default is comma-separator).schema(csvSchema) # Use the specified schema.csv(csvFile) # Creates a DataFrame from CSV after reading in the file.printSchema())

若有收获,就点个赞吧
0 人点赞
