一、m3u8类型说明
视频下载,一般而言,无非两种情况。
一种,链接明确是以 mp4、mkv、rmvb 这类视频格式后缀为结尾的链接,这种下载很简单,跟图片下载方法一样,就是视频文件要比图片大而已。
另一种,链接是以 m3u8 这类分段视频后缀结尾的链接。啥是分段视频?
抓包看一下就知道了,打开视频播放链接:http://youku.com-youku.net/share/f0d48bde60d407c45af7ca00d1ef927b
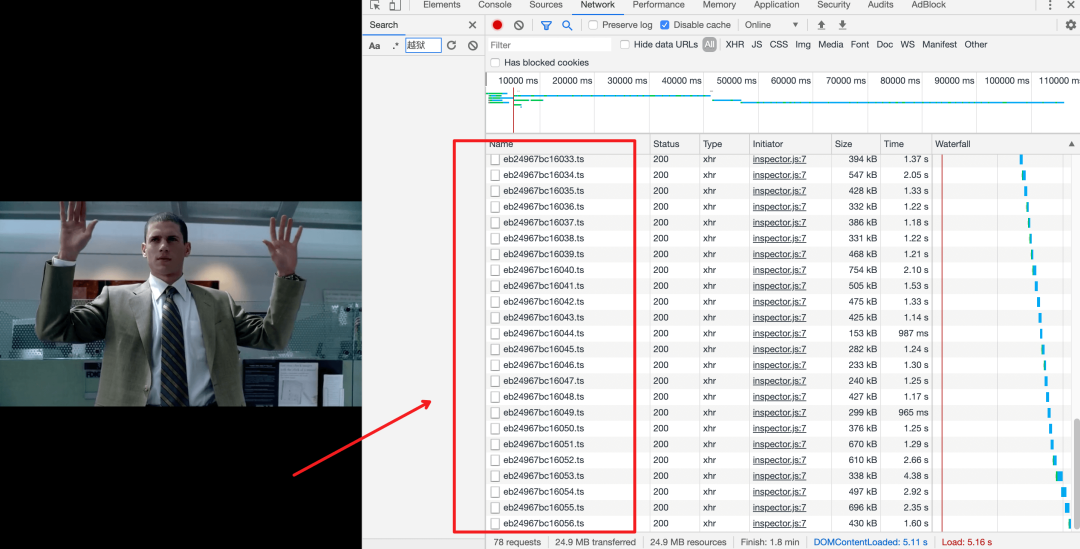
现在很多视频都是分段存储的,你看视频的时候,其实是在加载一个个 ts 视频片段,一个片段是几秒钟的视频。
这种视频要怎么下载?怎么将 ts 视频片段组合成一个视频?
其实,如果知道方法,就很简单。
m3u8 这种格式的视频,就是由一个个 ts 视频片段组成的。
一个 m3u8 文件并不大,你可以把它理解为链表,每个 ts 视频片段文件,都有下一个时序的 ts 视频片段的地址。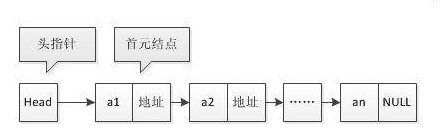
记住一点,解决音频和视频的一些问题,可以看看 FFmpeg,它的中文名叫多媒体视频处理工具。
FFmpeg 有非常强大的功能包括视频采集、视频格式转换、视频抓图、给视频加水印等功能。
这种 ts 视频片段合成,格式转换问题,交给 FFmpeg 就好了。
要使用 FFmpeg,需要先安装配置一番。
FFmpeg 也有 Python API 接口,名字叫 ffmpy3,安装好 FFmpeg 后,可以直接通过 pip 安装。
pip install ffmpy3
比如想要下载 m3u8 文件。
URL:http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8
可以在命令行输入如下指令:
ffmpeg -i "http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8" "第001集.mp4"
视频会保存为「第001集.mp4」。
如果用 Python 接口,也只需要两行代码:
import ffmpy3
ffmpy3.FFmpeg(inputs={'http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8': None}, outputs={'第001集.mp4':None}).run()
FFmpeg 自动整合 ts 分段视频,并保存为 mp4 格式的视频。
二、代码
# -*- coding:utf-8 -*-
import os
import ffmpy3
import requests
from bs4 import BeautifulSoup
from multiprocessing.dummy import Pool as ThreadPool
# search_keyword = '越狱第一季'
serach_res = {}
# 获取url及name
def get_videos_url(search_keyword):
search_url = "http://www.jisudhw.com/index.php?m=vod-search"
serach_headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36',
'Referer': 'http://www.jisudhw.com/',
'Origin': 'http://www.jisudhw.com',
'Host': 'www.jisudhw.com'
}
serach_datas = {
'wd': search_keyword,
'submit': 'search'
}
r = requests.post(url=search_url, headers=serach_headers, data=serach_datas).content.decode('utf-8')
search_html = BeautifulSoup(r, 'lxml')
search_spans = search_html.find_all('span', class_='xing_vb4')
for span in search_spans:
url = 'http://www.jisudhw.com' + span.a.get('href')
# video_dir = span.a.string
# 创建电影文件夹
if search_keyword not in os.listdir('./'):
os.mkdir(search_keyword)
r = requests.get(url=url).content.decode('utf-8')
detail_bf = BeautifulSoup(r, 'lxml')
uls = detail_bf.find('div', id="1").ul.stripped_strings
for m3u8 in uls:
video_num, value_path = m3u8.split("$")
serach_res[value_path] = video_num
# 使用FFmpeg下载视频
def downVideo(url_detail):
global search_keyword
num = serach_res[url_detail]
name = os.path.join(search_keyword, num)
ffmpy3.FFmpeg(inputs={url_detail: None}, outputs={name: None}).run()
if __name__ == '__main__':
# 开8个线程池
search_keyword = "越狱第一季"
get_videos_url(search_keyword)
pool = ThreadPool(8)
results = pool.map(downVideo, serach_res.keys())
pool.close()
pool.join()
三、总结
FFmpeg 配置
下载地址:https://ffmpeg.zeranoe.com/builds/
1.下载最新版 FFmpeg,bin目录为:”D:\Program Files (x86)\ffmpeg-win64-static\bin”,写入环境变量path
2.pip install ffmpy3后,编辑ffmpy3.py文件(import ffmpy3 按住ctrl点击ffmpy3 ),修改”def init(self, executable=r’D:\Program Files (x86)\ffmpeg-win64-static\bin\ffmpeg.exe’)”
3.或直接将bin目录下的ffmpeg.exe文件复制到当前python项目中,不必修改ffmpy3.py文件
使用ffmpy3.FFmpeg下载文件
ffmpy3.FFmpeg(inputs={"http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8": None}, outputs={"第01集.mp4": None}).run()
注意 outputs={“第01集.mp4”: None} 必须有”xxx.mp4” 后缀名,否则会报错
Unable to find a suitable output format for '第01集'
AttributeError: 'NoneType' object has no attribute 'decode'

若有收获,就点个赞吧
0 人点赞
