那些人人称道的美丽,里面都有PS的痕迹。
人是视觉型动物,每个人都有自己的审美标准,那些共同的准则形成了社会潮流。
随着计算机技术升级,我们现在可以用手机随时拍出漂亮的照片。
“PS”技术不再局限于“电脑”,而且计算机慢慢开始拥有了自己的“视觉”能力。
计算机视觉,就是让计算机读懂图像内容,是人工智能的一部分。
所以,用Python处理图像的场景,有两大类:
- 批量自动化处理图像,如裁剪、滤镜、旋转等效果叠加。
- 智能识别图像内容,如人脸识别、人物识别等,用“PS”术语可以叫“自动抠图”。
处理图像,其实就是处理色彩的数据,最常见的比如RGB格式。
当图像要保存到磁盘时,人们会用压缩算法缩小数据占用空间,再次读取和显示时就解压缩还原。
Python处理图像的模块主要有3类:
Pillow,即PIL最活跃分支,普及度高,提供多种图像格式处理能力。还有不少依赖于它的项目应用,如之前介绍的openpyxl和python-pptx,以及图像增强工具Augmentor。scikit-image,是科学计算生态scipy的图像能力补充。OpenCV,Intel发起的计算机视觉库,用C++实现后提供Python接口封装。
从性能角度看OpenCV最强,但Pillow和scikit-image的接口更简单,尤其是Pillow,不需要直接面对numpy.ndarray的矩阵数据。当然了,图像处理到深处,那就都是数学,尤其是线性代数。
好在图像研究已经很多年,我们从应用角度看,重点是掌握如何用Python解决日常工作中的问题。
选择哪一类模块,需要从实际应用需求和知识背景2个角度出发:
- 只做一些简单图片处理,比如大小、基本滤镜等,
pillow足够。 - 需要灵活自定义高级滤镜,或研究图像算法,
scikit-image和opencv更适合,有不少三方模块底层使用了opencv,所以根据具体应用情况可以穿插使用。只不过需要注意opencv内部数据不是RGB顺序,而是BGR顺序。 - 绘制图表,比如折线图、饼图等,不需要以上模块,用
matplotlib更适合。
对于初学者,建议先用pillow,不够用时再从scikit-image和opencv中寻找解决算法。
此外,虽然三者内部图像数据存储方式不同,但可以互相转换。
本文重点介绍pillow模块用法,部分兼用opencv和scikit-image。
模块安装:
pip install pillowpip install scikit-imagepip install opencv
本文包含如下常见应用场景:
- 基本使用:打开、显示、保存,灰度化、锐化
- 数据互转:三个类库中图像数据互相转换
- 基本图像处理:调整大小、旋转、翻转、裁剪
- 图像滤镜:换底色、各类风格,如漫画、油画、漫画头像、复古、黑白
- 实战应用:屏幕截图、抠图、批量加水印
- 智能应用:人脸识别,如带口罩、情绪
基本使用
先来分别感受下pillow、scikit-image和opencv三个模块的基本使用方式。
包括:读写文件、灰度化和锐化图像。
Pillow基本使用
import pathlibfrom PIL import Image, ImageFilterpath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = Image.open(file_path)print(img.size, img.mode, type(img))# img.show()img_gray = img.convert('L') # 灰度化img_gray.save(path.joinpath('006image_pillow_gray.png'))img_sharp = img.filter( ImageFilter.SHARPEN ) # 锐化img_sharp.save(path.joinpath('006image_pillow_sharp.png'))
scikit-image基本使用
import pathlibfrom skimage import io, colorfrom skimage.filters import unsharp_maskpath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = io.imread(file_path)print(img.shape, type(img))# io.imshow(img) # 使用matplotlib显示图像img_gray = color.rgb2gray(img)io.imsave(path.joinpath('006image_skimage_gray.png'),img_gray)# enhanced image = original + amount * (original - blurred)img_sharp = unsharp_mask(img, radius=20, amount=1)io.imsave(path.joinpath('006image_skimage_sharp.png'),img_sharp)
opencv基本使用
import pathlibimport cv2import numpy as nppath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = cv2.imread(str(file_path))print(img.shape, type(img))# cv2.imshow('image',img)# cv2.waitKey(0)# cv2.destroyAllWindows()img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰化cv2.imwrite(str(path.joinpath('006image_cv2_gray.png')),img_gray)kernel = np.array([[-1,-1,-1],[-1, 9,-1],[-1,-1,-1]])img_sharp = cv2.filter2D(img, -1, kernel) # 锐化cv2.imwrite(str(path.joinpath('006image_cv2_sharp.png')),img_sharp)
可以看到,pillow 的使用门槛最低,代码也最容易读懂;scikit-image和numpy无缝结合,图片读取出来的就是一个numpy.ndarray对象;opencv读取出的也是numpy.ndarray,但色彩模式是BGR模式,需要用cvtColor函数进行模式转化。
三个模块间数据互转
当我们用pillow处理图像到一半时,如果需要用到opencv内置的算法,怎么办?
不用重新用opencv再处理一遍,直接把pillow数据转为opencv的即可。
import pathlibfrom PIL import Imageimport numpyimport cv2from skimage import io, img_as_float, img_as_ubytepath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = Image.open(file_path)# PIL 转 opencvimg_cv = cv2.cvtColor(numpy.asarray(img),cv2.COLOR_RGB2BGR)print(img_cv.shape)# opencv 转 PILimg_back = Image.fromarray(cv2.cvtColor(img_cv,cv2.COLOR_BGR2RGB))# opencv 转 skimageimg_sk = img_as_float(cv2.cvtColor(img_cv,cv2.COLOR_BGR2RGB))print(img_sk.shape)# skimage 转 opencvimg_cv_back = cv2.cvtColor(img_as_ubyte(img_sk),cv2.COLOR_RGB2BGR)# skimage 转 PILimg_sk2pil = Image.fromarray(img_as_ubyte(img_sk))# PIL 转 skimageimg_pil2sk = img_as_float(img_sk2pil)print(img_sk.shape)
基本图像处理
基本图像处理,pillow足够应付,它通过文件头确定基本信息,如文件格式、大小、模式等。
Image是pillow最基础也是最核心的类,提供了读写文件、显示、格式转换、裁剪、合并、变形等一系列的功能。
比如最常见的使用场景:调整大小、旋转、翻转、裁剪、混合。
import pathlibfrom PIL import Imagepath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = Image.open(file_path)print(img.format, img.size, img.mode)# 创建一个缩略图,大小128x128size = (128, 128)img.thumbnail(size) # 不能放大,同时保持比例img.save(path.joinpath('006image_thumb.png'), 'PNG')img_resize = img.resize((512, 512)) # 自由缩放,放大后会模糊img_resize.save(path.joinpath('006image_resize.png'))img = Image.open(file_path) # 重新打开# 旋转img_rot = img.rotate(45)img_rot.save(path.joinpath('006image_rotate.png'))# 翻转img_all = Image.new('RGB', (512*3, 512*2), (0, 0, 0)) # 创建一个三行两列容器trans_list = [Image.FLIP_LEFT_RIGHT, Image.FLIP_TOP_BOTTOM,Image.ROTATE_90,Image.ROTATE_180, Image.ROTATE_270]img_all.paste(img, (0,0))for i, trans in enumerate(trans_list, start=1):x = (i%3)*512y = (i//3)*512img_trans = img.transpose(trans)img_all.paste(img_trans, (x, y))img_all.save(path.joinpath('006image_transpose.png'))# 裁剪box = (100, 100, 400, 400) #(左、上、右、下)左上角坐标(0,0)img_crop = img.crop(box)img_crop.save(path.joinpath('006image_crop.png'))img_crop_mod = img_crop.transpose(Image.ROTATE_180)# 合并img.paste(img_crop_mod, box)img.save(path.joinpath('006image_merge.png'))
图像滤镜
图像色彩是个专业领域,为表达人眼看到的颜色,专家们建立了不同的数学模型。
其中和设备相关的模型如RGB、CMYK、YCbCr。
RGB常用于显示器,用红(Red)、绿(Green)、蓝(Blue)三色组合出色彩。CMYK常用于打印机,青(Cyan)、品红(Magenta)、黄(Yellow)和黑(blacK,避免与Blue混淆)。YCbCr常用于视频,Y为颜色亮度比例,Cb和Cr表示蓝色和红色浓度偏移量比例。
图像的色彩处理,其实就是对其颜色数据的处理。
实际工作生活中,我们经常会看到一些滤镜效果,比如:轮廓图、浮雕图、模糊、铅笔画、平滑、撒盐效果、相片底片效果、手绘效果、抖音效果等等。

这些效果背后,都是对色彩数据调整处理。pillow的ImageFilter提供了一些常用滤镜,此外也可以用Image.point遍历像素点,自定义处理方式。
此外,pillow从3.4版本开始支持创建GIF图像,比如下面的:

下面代码演示了上面提到的一些效果
import pathlibfrom PIL import Image, ImageFilterimport numpy as nppath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = Image.open(file_path)# mode就是采用的色彩模型print(img.format, img.size, img.mode)bands = img.getbands() # 返回所有通道bboxs = img.getbbox() # 返回左上角和右下角坐标extremas = img.getextrema() # 各个通道像素最小和最大值print(bands, bboxs, extremas)# 通道分离r, g, b = img.split()# 这里可以对每个通道的数据做些处理# 比如提高红色通道,降低绿色和蓝色通道,可以把图片变暖一些r = r.point(lambda x: x*1.3)g = g.point(lambda x: x*0.9)b = b.point(lambda x: 0)# 通道合并img_warm = Image.merge('RGB', (r, g, b))img_warm.save(path.joinpath('006image_warm.png'))# ImageFilter提供的预置滤镜filter_list = [ImageFilter.BLUR, ImageFilter.BoxBlur, ImageFilter.DETAIL,ImageFilter.CONTOUR, ImageFilter.EDGE_ENHANCE, ImageFilter.EDGE_ENHANCE_MORE,ImageFilter.EMBOSS, ImageFilter.FIND_EDGES, ImageFilter.SHARPEN,ImageFilter.SMOOTH, ImageFilter.SMOOTH_MORE]img_all = Image.new('RGB', (512*3,512*4),(0,0,0))img_all.paste(img, (0,0))for i, filt in enumerate(filter_list, start=1):if filt == ImageFilter.BoxBlur:im = img.filter(filt(3))else:im = img.filter(filt)x, y = 512*(i%3), 512*(i//3)img_all.paste(im, (x,y))img_all.save(path.joinpath('006image_filters.png'))# 把图像转为numpy.array格式处理im = np.array(img)# 随机生成3000点盐白W, H = img.sizefor i in range(3000):x=np.random.randint(0, W)y=np.random.randint(0, H)im[x,y,:]=255img_salt = Image.fromarray(im)img_salt.save(path.joinpath('006image_effect_salt.png'))# 底片效果im = np.array(img)im_gray = np.array(img.convert('L'))print(im.shape, im.dtype)print(im_gray.shape, im_gray.dtype)md_im = 255 - im_grayImage.fromarray(md_im).save(path.joinpath('006image_effect_photo.png'))# 手绘效果im_gray_float = im_gray.astype('float')# 深度值,范围为0~100# 深度值越大,图像梯度越大,体现为线条越多depth = 10grad_x, grad_y = np.gradient(im_gray_float) # 提取x和y方向的梯度值# 根据深度调整梯度值grad_x = grad_x*depth/100grad_y = grad_y*depth/100A = np.sqrt(grad_x**2 + grad_y**2 + 1.0)uni_x = grad_x/Auni_y = grad_y/Auni_z = 1.0/A# 引入光源vec_el = np.pi/2.2vec_az = np.pi/4.0dx = np.cos(vec_el)*np.cos(vec_az)dy = np.cos(vec_el)*np.sin(vec_az)dz = np.sin(vec_el)gd = 255*(dx*uni_x + dy*uni_y + dz*uni_z) # 光源归一化gd = gd.clip(0,255) #避免数据越界,将生成的灰度值裁剪至0-255之间im_out = Image.fromarray(gd.astype('uint8'))im_out.save(path.joinpath('006image_effect_pencial.png'))# 抖音效果im = np.array(img)im_r = np.copy(im)im_gb = np.copy(im)# 错位10个像素im_r[:-10, :-10, 1:3] = 0 # 去GB两个通道数据im_gb[10:, 10:, 0] = 0 # 去R通道数据im[:-10, :-10, :] = im_r[:-10, :-10, :] + im_gb[10:, 10:, :]img_out = Image.fromarray(im)img_out.save(path.joinpath('006image_effect_douyin.png'))# 如果连续生成不同错位像素的图片,就能拼成一个抖音效果的GIF动画img_dy_list = []for offset in range(2, 13, 2):im = np.array(img)im_r = np.copy(im)im_gb = np.copy(im)im_r[:-offset, :-offset, 1:3] = 0im_gb[offset:, offset:, 0] = 0im[:-offset, :-offset, :] = im_r[:-offset, :-offset, :] + im_gb[offset:, offset:, :]img_dy_list.append(Image.fromarray(im))# Pillow 3.4以上(含)版本可以创建GIF图像img_dy_list[0].save(path.joinpath('006image_effect_douyin_gif.gif'), save_all=True,append_images=img_dy_list[1:], duration=100, loop=0)
实战应用
实战中最常遇到的场景,如:屏幕截图、加水印、朋友圈九宫格切图、抠图、证件照换背景。
加水印和九宫格切图

用pillow处理很方便:
import pathlibfrom PIL import Image, ImageDraw, ImageFontfrom PIL import ImageGrab, ImageFilterpath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('lena.png')img = Image.open(file_path)print(img.format, img.size, img.mode)# 屏幕截图img_screen = ImageGrab.grab((0,0,1024,300))# im = ImageGrab.grab() # 全屏img_screen.save(path.joinpath('006image_screen.png'))# 加文字水印font = ImageFont.truetype(str(path.joinpath('SourceHanSansCN-Bold.otf')), 20)img_txt = Image.new('RGBA', img.size, (0,0,0,0))draw = ImageDraw.Draw(img_txt)draw.text((300, 480), '程一初', font=font, fill=(255,255,255,255))img_txt = img_txt.rotate(45)# 两个图片必须具有相同的mode和sizeimg_wm = Image.alpha_composite(img.convert('RGBA'), img_txt)img_wm.save(path.joinpath('006image_txt_watermark.png'))# 加图片水印img_logo = Image.open(path.joinpath('avatar.jpg')).resize((100, 100))img_mask = Image.new('RGBA', img.size, (0,0,0,0))img_mask.paste(img_logo, (400,400))img_wm = Image.alpha_composite(img.convert('RGBA'), img_mask)img_wm.save(path.joinpath('006image_img_watermark.png'))# 把水印图片做成圆形,其实就是多加一层遮照logo_mask = Image.new('RGBA', img_logo.size, (0,0,0,0))draw = ImageDraw.Draw(logo_mask)draw.ellipse((0,0,100,100),fill=(0,0,0,255))img_logo_masked = Image.composite(img_logo, logo_mask, logo_mask)img_logo_masked.save(path.joinpath('006image_logo_circle.png'))img_mask = Image.new('RGBA', img.size, (0,0,0,0))img_mask.paste(img_logo_masked, (400,400))img_wm_circle = Image.alpha_composite(img.convert('RGBA'), img_mask)img_wm_circle.save(path.joinpath('006image_img_circle_watermark.png'))# 也可以加一些模糊处理img_mask_blur = img_mask.filter(ImageFilter.GaussianBlur(20))img_wm_circle_blur = Image.composite(img_mask, img.convert('RGBA'), img_mask_blur)img_wm_circle_blur.save(path.joinpath('006image_img_circle_blur_watermark.png'))# 九宫格切图,实际上应用的是`Image.crop`方法out_path = path.joinpath('006image_9cuts_out')if not out_path.is_dir():out_path.mkdir()W, H = img.sizeW /= 3H /= 3for i in range(9):x, y = (i%3)*W, (i//3)*Himg_out = img.crop((x,y,x+W,y+H))img_out.save(out_path.joinpath(f'out_{i}.png'))
其中,加水印,其实就是把图片合并,关键是Image.composite()方法;九宫格切图,就是把图片9等分,然后用Image.crop()方法截取内容。
关于去水印:图像水印并不是那么容易解决,关键是找出特征颜色数据再对图像数据处理。
如果有原图,就可以通过反向使用透明通道尝试消除,但也未必能做到100%消除,反复尝试调整透明度,有时候可以做到肉眼看不清,但仔细观察依旧可以发现“蛛丝马迹”(不可能每个像素都完美消除)。
此外,当前也有项目基于机器学习算法来解决这类问题。如deep_image_prior,除了去水印,还有消除马赛克、提高分辨率、缺失图像修复等功能。但此类算法对硬件要求较高,如需要特殊显卡支持CUDA算法框架。
自动抠图
用过”PS”的人对抠图应该不会陌生,可以很神奇地把图片里的元素单独提取出来,和其他的背景合并。
最常见的应用场景就是证件照,每次去拍照,都要用个纯色的幕布,而且要求衣服不能太浅。
其实背后是有原因的:为了管理部门更准确识别出人像。
抠图的原理,是找出目标物的边界范围,然后把其他地方变透明。
流程很简单,就2步:
- 计算出二值图像(即黑白图),每个像素点数据非0即1。
- 根据二值图像为原图设置透明度,如把非人像部分全透明,再融合其他背景,就实现了换背景效果。
所以,抠图效果好坏,关键在于识别的精准度。
常见做法有3种:
- 根据像素色彩范围,识别出背景。适合纯背景色场景,如证件照。
- 如果背景色彩复杂,就分块识别,在某小块中色彩相对集中。但需要单独设计切分算法。
- 机器学习算法,训练出识别物的特征模型。训练过程非常耗资源,但有了模型就可以快速应用,目前不少大平台也开放出了自己的训练模型,如百度的
paddlehub项目。
篇幅有限,这里就只用pillow做个简单演示,按像素点判断色彩范围:
# 一、把背景高于某个颜色的部分去掉import pathlibfrom PIL import Imagepath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_path = path.joinpath('zjz.jpeg')img = Image.open(file_path).convert('RGBA')print(img.size, img.mode)W, H = img.size# 指定背景颜色,可以用多个点来增强精确度# 前提就是手工去获取背景的像素点颜色bg_color = (73, 112, 169, 255)bg_colors = [(64, 105), (80, 138), (116,190), 255]# 用python数组运行有点慢for w in range(W):for h in range(H):point = img.getpixel((w,h))if point == bg_color: # 一个点效果太差img.putpixel((w,h), (0,0,0,0))elif all( bg_colors[i][0] < c < bg_colors[i][1]for i, c in enumerate(point[:-1])):img.putpixel((w,h), (0,0,0,0))img.save(path.joinpath('006image_pixel_alpha.png'))# 换个红底背景bg_red = Image.new('RGBA', img.size, 'red')bg_red = Image.alpha_composite(bg_red, img)bg_red.save(path.joinpath('006image_pixel_redbg.png'))

全部的4种方式,可以参考源代码,对比后可以发现:
- 按每个像素点色彩判断范围,需要手动指定背景色彩值范围,且用Python数组迭代效率低。
- 用
opencv的inRange函数生成二值数据,也要手动指定范围,但它支持位运算,效率高。 - 用灰度图,手动指定某个值来生成二值图,速度快,但精度差,效果当然也差。
- 使用
paddlehub的人像模型识别,全自动,效果凑合,但资源损耗大,运算效率低。
关于自动抠图,有一些在线API已经可以很好去除背景,比如remove.bg,这类API也提供PythonSDK,效果比以上方式都好,但下载处理后图像的高清版本需要付费。
智能应用
上面提到的paddlehub,除了可以识别人像,还有更多公开的训练模型。
模块安装:pip install paddlepaddle paddlehub
比如人脸、口罩、文字等,使用方法都类似:
- 引入模型:比如人像训练模型
deeplabv3p_xception65_humanseg - 加载图片:指定文件路径
- 算法执行:比如上面的图像切分
segmentation - 输出结果
训练模型在调用时会自动从网上下载,也可以提前调用命令下载:hub install 模型名。
通过hub list可以查看当前已下载了哪些训练模型。
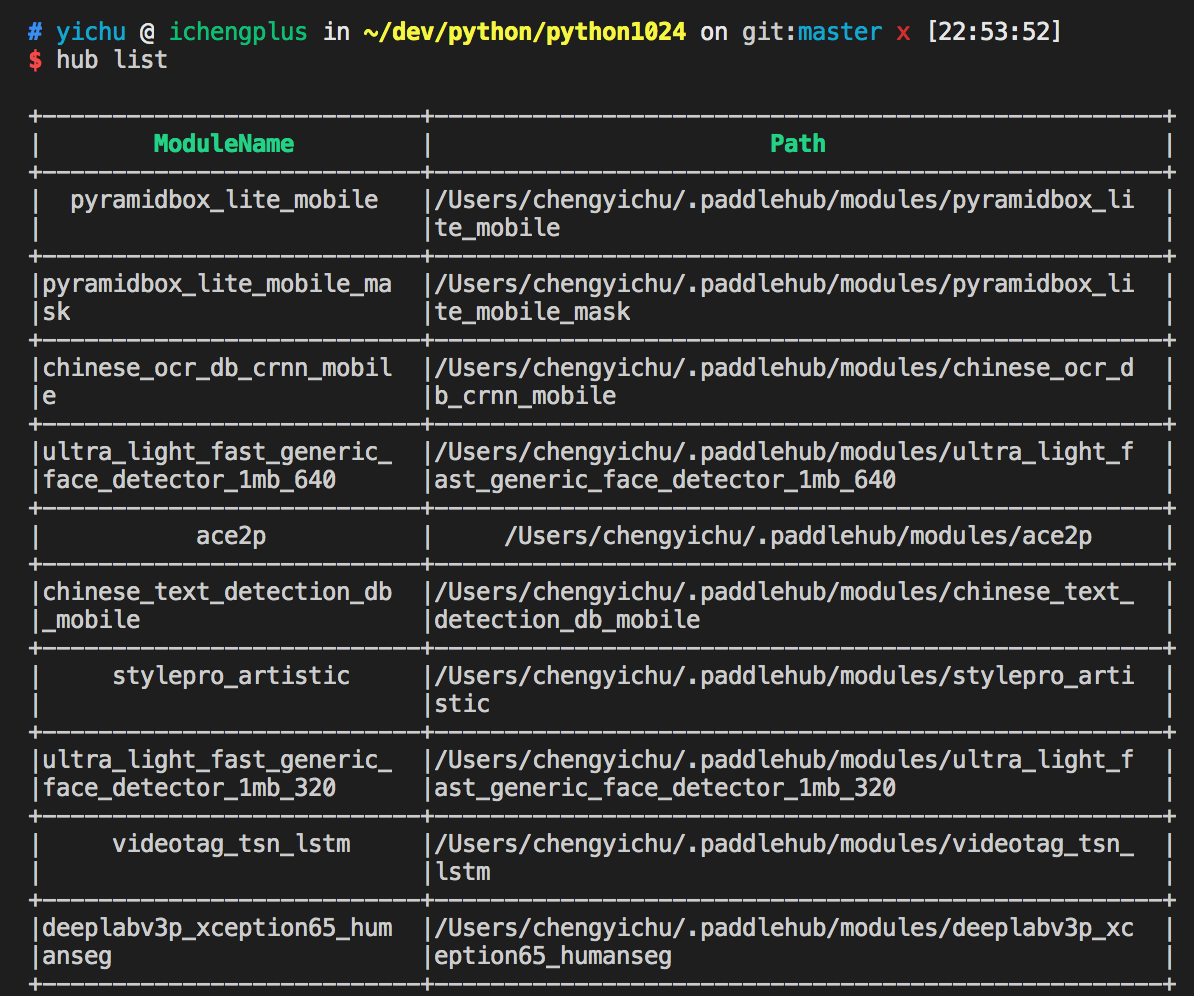
看一个官方的人脸识别的案例:检测口罩佩戴。
import pathlibimport paddlehub as hubfrom PIL import Image, ImageDrawpath = pathlib.Path('~/dev/python/python1024/data/automate/006image').expanduser()file_list = [str(path.joinpath('mask1.jpg')), str(path.joinpath('mask2.jpg'))]out_path = path.joinpath('006image_face_out')module = hub.Module(name="pyramidbox_lite_mobile_mask")results = module.face_detection(data={"image": file_list})for res in results:data = res['data']img = Image.open(res['path'])f_path = pathlib.Path(res['path'])draw = ImageDraw.Draw(img)for d in data:draw.text((d['left'], d['top']-10), f'{d["label"]}: {d["confidence"]:.2%}', 'red')draw.rectangle((d['left'], d['top'], d['right'], d['bottom']), outline='green', width=3)img.save(out_path.joinpath(f_path.name))
可以发现接口非常简单,图像会在本地处理,然后返回json格式的数据,数据中会标出相关图像信息,比如案例中的人脸和口罩佩戴概率值。

总结
本文介绍了Python中图像处理的3个模块,重点介绍了pillow的用法。
现实生活中,我们可以通过各类美图软件随时随地修图,但当我们需要批量处理时,可以采用Python自动化形式。此外,也可以试验一些独创的自定义玩法,这些滤镜可能现有软件还未能提供。
比如实际工作中,运营等岗位经常需要批量制作一些朋友圈海报图,方便用户传播。
目前也有一些在线网站提供半免费半付费的海报制作工具,但如果一次要做上百张海报,工作量也是非常可观的。这种情况非常适合用Python批量处理。
最后,我们也尝试了现有的训练模型来识别人像、人脸的场景。当然应用不仅于此,后面章节中我还会介绍其他好玩的训练模型来处理图像。
加入学习群


若有收获,就点个赞吧
0 人点赞
