- 1.YML格式
- 2.理论上是抽象类的所有抽象方法必须被覆写,但是为什么HttpServlet的子类中覆写或者不覆写都不会报错?
- 3.在后端向jsp页面传递参数的时候可以使用对象传递,之后用EL表达式,也可以用JSON数据传递,在选择的时候优先选择哪一种好?
- 4.什么是异步IO,和同步IO的区别有哪些?BIO,NIO,AIO实现区别?
- 5.在构造方法里面进行调用的时候为什么要使用“类.class”,而不使用“对象.getClass()”?
- 6.反射与new的关系
- 1.缓存流与内存流的区别
- 2.基本类型与包装类型选择
- 3.基本数据类型与引用传递
- 4.集合信息取得
- 5.接口标准
- 6.链表为什么要用内部类?
- 1.进程间通讯方式有哪些?
- 2.数据库事务未结束宕机后,重启事务回滚原理。
- 3.进程执行和线程执行优缺点比较。
- 4.什么时候使用Object类?
- 5.CycleBarrier和CountDownLatch区别及实现原理
- 6.什么情况下使用虚拟内存,好处是什么?
- 1.MVC模式中,各个层级的职能划分,哪些功能写在哪块?
- 2.SSO的处理流程
- 3.关于读、写性能
- 4.分布式锁
- 5.项目的负载均衡设计
- 6.复杂度
- 7.红绿灯系统设计
- 8.项目中的人员安排
- 9.密码加密处理
- 10.商品秒杀设计方案
- 11.日志输出
- 12.企业项目部署
- 13.实际的项目开发
- 14.数据库优化
- 15.项目阐述
1.YML格式
yml格式是与properties对应的一种格式,基本上可以方便的描述资源的配置。如果现在使用properties,那么定义格式如下:
如果要采用yml配置如下:
没有必要去考虑具体的格式,转换也很容易,之前SpringBoot有说过。(大家可以点击下方“阿里云大学-面试技巧”去看看)
2.理论上是抽象类的所有抽象方法必须被覆写,但是为什么HttpServlet的子类中覆写或者不覆写都不会报错?
它们的关系:
(1) 爷爷类(抽象类):GenericServlet;
(2) 老子类(抽象类):HttpServlet;
(3) 类(普通类):自定义的Servlet
关键的问题在于HttpServlet抽象类中的所有方法并不完全都是抽象方法,对于抽象类的子类需要覆写的只是抽象方法,而对于非抽象方法是不需要强制覆写的。
3.在后端向jsp页面传递参数的时候可以使用对象传递,之后用EL表达式,也可以用JSON数据传递,在选择的时候优先选择哪一种好?
如果想玩高档界面,整个页面不直接生成,那么使用JQuery加载最好。
EL工作在服务器端,而JSON操作工作在客户端处理(服务器生成),这两点完全没有可比性。
当使用JSP处理的时候,必须明确所有的代码是由容器负责生成,生成的是HTML代码,这些代码依靠一些对象生成,生成完成之后才会把生成的代码发送给客户端,客户端要进行整体的解析处理。而JSON只是一个传输的格式,它要求在整个的处理里面需要通过前台的JS来进行数据的控制。
4.什么是异步IO,和同步IO的区别有哪些?BIO,NIO,AIO实现区别?
在进行图形的用户信息输入的时候你会发现如果用户不输入信息,则程序就进入一种阻塞状态,这种阻塞状态一定是要在输入完成后才会解除,就会成为同步IO。阻塞状态下执行,所谓的异步IO简单一点来讲在阻塞的时候其它的线程依然可以执行。
BIO:同步阻塞IO,就是传统的操作实现模式,传统的IO处理,像最基础的InputStream;
NIO:异步阻塞IO,做一个零拷贝操作,正常的文件操作是通过CPU向内存要数据,而后内存向硬盘要数据,而零阻塞指的是内存直接将读取到的数据发送给客户端,中间不再经过CPU处理,里面重要的是一个Channel;
AIO:异步非阻塞IO,等待发出之后用户就继续向下执行了,完成后获得一个通知。
5.在构造方法里面进行调用的时候为什么要使用“类.class”,而不使用“对象.getClass()”?
Class实际上主要表示一个类的结构,例如:Date有Class类、String也有与之匹配的Class类,而获得了Class类就相当于获得了类的操作权限,哪怕获得的时候没有实例化对象存在,也是可以操作的。

一般使用getClass()方法都会在某一个方法里通过反射获取对象结构的时候采用。
6.反射与new的关系
对于反射机制而言,本质的目的:避免具体的对象操作,而new处理是需要有明确的耦合性。
范例:以接口实例化为例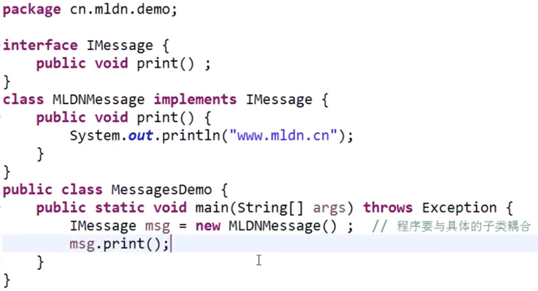
如果一个程序类的代码要进行类耦合处理的话,这个时候就必须清楚地认识到一个问题:该程序子类在使用之中就无法动态更换了,IMessage只能够使用一个固定的子类。
而如果要使用反射处理的话,就不再受到一个固定类的限制。
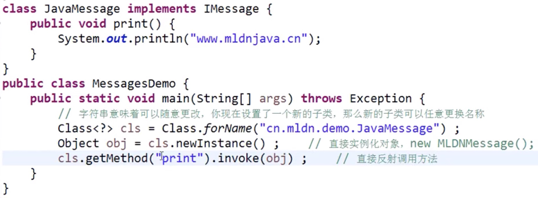
反射并不是一个容易被初学者理解的话题,因为如果要想清楚反射的作用,那么就必须要求学完java业务分析设计。
1.缓存流与内存流的区别
内存流的本质就是将所有的数据在内存之中进行完整的处理操作。核心的概念在于内存流可以进行整体的数据处理。
从实现的角度来讲,两者是可以部分互通的,从实用角度来讲,缓存流更多的是一个暂时的操作,缓存操作流更多的情况下是有一个间隔的,这个间隔往往不会保存过多的内容。
在缓存流的操作概念里面重点只有一个核心因素:处理中文(BufferedReader),这种操作本身只适合于字符串的操作,本身没有验证处理,所以会使用Scanner完成。
2.基本类型与包装类型选择
基本类型与包装类型最大的区别有亮点:
(1)包装类是以对象的形式运行,而且JDK1.5之后对于包装类又提供自动的装箱与拆箱处理机制;
(2)包装类可以进行null的描述。(这个描述的操作要追溯到Hibernate盛行的时期,因为对于一些设置的字段,如果使用了基本类型,不设置内容就是对应数据类型默认值,如果说现在年龄使用了int,则不设置年龄表示0,而如果使用了包装类年龄表示的就是null。)
对于现在的开发,基本都是在数据层上的保存对象内容类(VO类)使用包装类,这样对null的控制比较方便。
3.基本数据类型与引用传递
在Java里面数据类型一共分为两种:基本、引用,对于引用可以发生引用传递,而基本类型只是一个值拷贝,引用类型传入到某一个方法之中,修改之后会影响原始对象中的内容,而基本数据类型不会。
不过从后续的开发开始,为了方便用户的使用专门提供有一个包装类的概念,利用包装类可以方便的实现基本数据类型与引用数据类型的操作,最为重要的是包装类里面提供有一个null的概念,这对于一些开发框架,例如:MyBatis、Hibernate等都有非常重要的意义。
4.集合信息取得
如果说现在有一个List集合,想要取得里面某一个索引的数据,这种情况下一定要考虑使用get()方法(要清楚ArrayList、LinkedList区别所在),可以轻松地进行元素的定位,get()方法是其主要扩充的方法,也是List和Set最大区别所在。例如:FileUpload、MyBatis里面获得的数据都是通过List中的get()方法取得。
而对于集合的输出操作有两种做法:
(1)使用for循环,在集合里面存在有size()方法,而且List有get()方法,很明显可以使用循环。如果你使用的是LinkedList子类,那么会出现时间复杂度攀升的问题;如果使用的是ArrayList,由于其时间复杂度为1,所以可以快速查找;
(2)对于集合而言,为了避免这些时间复杂度过高问题,有了迭代的输出接口,使用Iterator。
5.接口标准
所谓的标准指的是所有类都要奉行的法则,因为普通类的继承关系里面是不存在有这样的硬性的子类定义法则(强制性覆写),所以才会衍生出抽象类与接口的概念,对于接口本身而言,它只是一个方法视图。
就好比你使用一款空调遥控器,都一定可以找到开关键,如果不开空调无法制冷,而如果太冷一定要关,这些就是标准,如下图,遥控器的标准在设计里面就像是接口,没有关联的层要想捆绑在一起,就要使用接口。
6.链表为什么要用内部类?
内部类的特点:
(1)内部类可以方便的与外部类之间进行私有属性的访问;
(2)一个内部类如果使用了private声明,那么外部将无法直接使用它。
为什么不将链表的实现变为如下形式:
之所以没有将Link与Node分开,而直接使用了一个内部类的形式完成,目的是:
(1) Node类如果没有Link类负责整体的协调操作,那么Node类上的方法根本没有任何用处;
(2) 方便引用传递。
如果你想知道为什么要合并为一个类,那就将内部类拿到外部类来,会发现在进行数据删除的时候,需要进行外部类与内部类之间非常繁琐的引用传递。
1.进程间通讯方式有哪些?
如果你面试的是Java开发岗位,那么这个时候所谓的通讯应该指的是JVM间的通讯。每一次执行Java命令的时候都会启动一个JVM进程,而不同进程之间的JVM通讯就可以为进程通讯。
一个简单的C/S应用,就是一个最基础的线程通讯,就是那种不怎么用的Socket编程。如果现在不想经过这么多复杂处理,还可以使用公共文件,或者直接进行管道流处理。
2.数据库事务未结束宕机后,重启事务回滚原理。
如果是Oracle那么就是relog(重做日志),你所有的记录都在日志里完成。
3.进程执行和线程执行优缺点比较。
进程的执行速度慢,线程执行速度快。每当使用Java命令去启动一个JVM进程的时候,实际上都要执行一个完整的进程生命周期,也就是说其所使用的资源会更加的庞大。而对于线程优势在于启动速度快,Java采用了多线程的处理方式,整个系统运行之中进程只会启动一次。
所有的线程都受到进程的控制,如果你的进程一旦被毁了,那么所有的线程也就都完蛋了。
4.什么时候使用Object类?
对于Object类的使用可以分为两个阶段:JDK1.5之前以及JDK1.5之后。Object之所以会被大量的进行参数的接收处理,很大一部分原因在于:你的程序里面需要接收的类型很多,并不固定。现在的开发理念之中强调的问题不再是这一点了,而是如何避免向下转型(如果避无可避,那么就用),因为从JDK1.5之后引入了泛型机制,现在的设计思想是用泛型来避免向下转型的操作(ClassCastException),你如果认真读了API文档就会发现可以接收Object类型的方法是越来越少了,所以你以后的开发中应该尽量以回避Object接收的项目为主。
5.CycleBarrier和CountDownLatch区别及实现原理
这两个类是java.util.concurrent定义的操作类,主要功能是进行线程同步处理的工具类。
CycleBarrier相当于汇聚多个等待线程,都到了,一起操作;
CountDownLatch等所有人都走了,我再操作。
范例:观察CountDownLatch
就是执行了一个阻塞的操作环境。CycleBarrier是一个互相等待状态。

CountDownLatch是一计到底,也就是说如果你一开始设置了2个计数线程就一直减,不能重置。
CycleBarrier可以进行重置处理;
以上就是两者的区别。
6.什么情况下使用虚拟内存,好处是什么?
假如你在玩游戏,你的电脑可能只有2G内存,但你发现依然可以使用,因为操作系统会将你的硬盘进行内存的虚拟化,这样就相当于你在硬盘上可以模拟内存(硬盘的速度很慢,所以你的程序启动的速度也很慢)。
从Java8开始取消了永久代,使用元空间来进行操作,也就是说Java可以直接使用操作系统的内存进行处理,这个时候就有可能导致每一个线程分配的真实的主机内存空间越大,如果内存不足,操作系统会进行虚拟内存的控制,对于虚拟内存不需要做特别多的处理。
当线程访问量追加,JVM就有可能不断的进行内存申请以及内存回收。
1.MVC模式中,各个层级的职能划分,哪些功能写在哪块?
所谓的MVC设计模式实际上是一种思想,虽然从整体上来说分为了三层,但实际上里面会划分了许多层。
比如有一个业务的完成,要分很多步,我们是把这些步骤放在业务层还是Servlet中?
服务层是可以单独抽取出来的,你的一个项目要充分的考虑到可扩展性,那么绝对需要将业务层单独抽取出来实现RPC调用。
一定要清楚的是控制层不负责任何数据库的操作,控制层只有一个功能就是调用业务层,业务的方法只有一个,如果业务操作要返回多个内容,那么就使用Map集合返回。
控制层一定要处理所有的错误操作,如果不处理,你可以直接选择一个抛出,而后在整个的web.xml文件里面配置一个错误页,这个错误页只要是产生了5xx异常,就自动跳转到一个错误页上显示。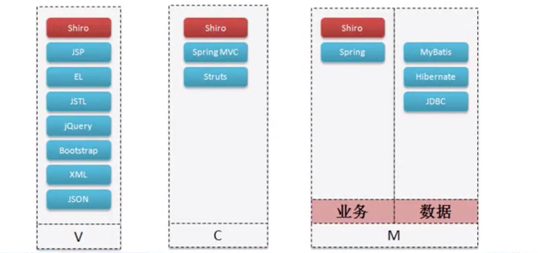
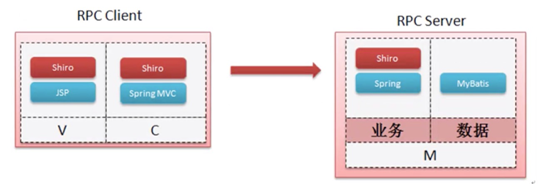
只有把单机的MVC彻底弄清楚后才有可能牵扯到更多实际开发问题,而集群的开发也只是一种扩展。
2.SSO的处理流程
所谓单点登录用在什么场景上?
CAS有一个自己的流程。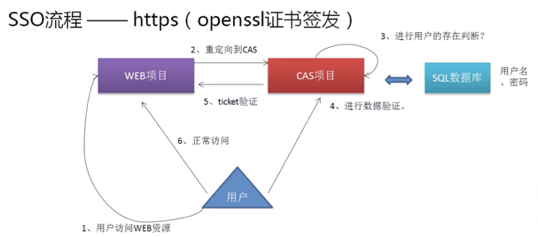
这个流程最麻烦的就是CAS服务器的配置,因为版本区别很大,所以建议大家使用稳定版本开发。同时还需要对源代码进行大量的修改与配置才可以得来。
3.关于读、写性能
数据库的读、写分离。此种考虑需要根据你的实际业务需求,不能凭空设计。
有这样一个简单的架构:
信息的汇总表,同时为了保证查询性能,需要增加索引,但这张表平均每1秒要更新1000次,但这样就和索引产生了冲突,所以定义两张表,一张表作为更新使用,另外一张表在系统安静下来之后进行差异的备份,而后进行数据的保存。
以上是WEB2.0以前的概念,从WEB2.0时代开始,数据量开始暴增,于是你的老板可能就要求你对系统进行大规模的升级,要求保证更新速度,要求保证实时性,要求保证数据的有效性。
如果这个时候的设计还是围绕着传统的关系型数据库展开,那么你的设计一定是失败的。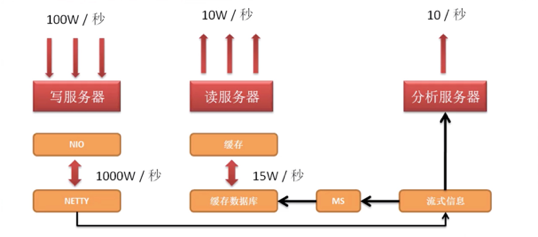
4.分布式锁
分布式锁指的是在高并发访问的情况下使用的一种技术,所谓的高并发访问就是指多个线程对象,为了保证资源的操作完成性而实现的一种技术,这样的技术可以简单的理解为锁。
如果现在多个线程在同一个虚拟机之中,正常编写一个程序,而后这个程序里面产生了若干个线程,并且这些线程要操作同一资源。在这样的情况下,为了保证资源操作的同步最简单的处理模式就是采用synchronized关键字来完成。
但是这样的做法只适合单JVM运行的情况,而如果现在划分到网络上。
范例:JVM锁


如果是多虚拟机的状态下,这样的设计就必须做出更改了。
5.项目的负载均衡设计
对于项目的开发需要考虑几个核心问题:高可用(主备关系)、高并发(可以承受大并发用户访问)、分布式。真正做到这个层次的架构,你的系统平均每天的访问量不可能低于500W用户,如果没有到这个量级,基本上可以肯定用这样的架构会造成大量额外的硬件成本(云服务器等)。
在正规的项目开发过程之中,肯定会有专业的前端开发者,这类人员会使用ES6.0标准进行前端开发,例如:JQuery、Vue.JS、React等,所以对于这部分的设计暂时不做考虑。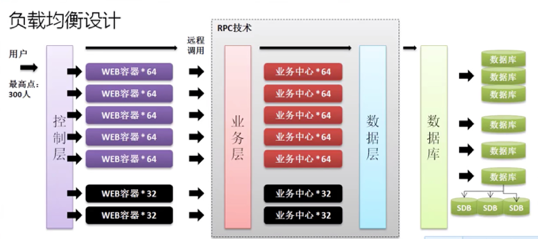
在整体的设计过程之中,就必须考虑性能的均衡,当然服务器的选择和你要使用的技术选择,也需要根据实际情况来确定,根据并发访问人数来决定你的技术架构。
6.复杂度
评价一个项目的好与坏,有一个最简单的标准:时间复杂度和空间复杂度。
时间复杂度指的是你的处理逻辑非常复杂,例如:递归、循环结构复杂。复杂度直接的影响就是你的CPU的占用率高。
空间复杂度指的是你的占用内存大,例如:在JDBC进行数据查询的时候实际上会出现一个问题,假设你的数据库里有1000W条数据,没有使用分页,那么这些记录都将加载到内存之中,所以内存占用率就会很高。假设数据会占用20G内存,你的一个服务器一定需要为上万人服务,那么这个时候占用的内存就会非常庞大,你的服务器根本就无法进行处理。
对于空间复杂度的操作处理,是需要通过最简单的分页算法实现约定,对于时间复杂度,太复杂的逻辑运算,往往不会在一台服务器上进行,需要设计多台的开发服务器。
7.红绿灯系统设计
当面试公司问到这道问题,实际考虑的是你的逻辑分析能力。因为这种开发的操作从现实来看都是通过硬件模拟的,如果非要通过软件模拟,就需要准备好可能使用到的技术:
(1)Java编写:Graphics类进行绘制开发;
(2)WEB编写:HTML5中提供的Canvas进行编写。
面对此类的问题一定要有一个假设前提:
(1)是否需要有黄灯的缓冲,缓冲的变更时间;
(2)是否需要智能调整,如果发现车流量较大,则适当延迟通过时间;
(3)对于违规车辆的监控情况;
(4)还可能考虑转向灯的设计。
实现整个操作的技术环节:
(1)定时器:Timer、TimerTask,这两个类需要时钟的支持,而且不准,如果要准确则需要使用QuartZ这个组件完成;
(2)描述所有的灯的变化,一定需要有一个线程的同步处理机制、synchronized、使用单例实现;
(3)既然有两组灯,就建议设计一个单独红绿灯类,这个类可以使用一些参数变化完成,例如:
控制变量=0,表示红灯;
控制变量=1,表示绿灯;
控制变量=2,表示转向灯;
控制变量=3,表示黄灯(绿灯变为转向灯);
控制变量=4,表示黄灯(转向灯变为红灯);
如果你现在只是希望给出一组状态,实际上就可以设置一下几位:111,可以描述7个值。
如果要编写还需要考虑传感器问题:包括监控传感器、流量传感器。
既然已经有了各种传感器,那么就可以再设置几个传感器:车速传感器,可以进行大数据的汇总,计算平均的车速,好为城市的交通规划做出数据的贡献。
开发流程:
(1)需要先实现定时进行灯的切换处理,如果你需要程序编写,如果使用无界面编写,这个输出的信息就非常麻烦了;
(2)需要考虑监控的问题,如果只是在软件上模拟,可以设置几个坐标点,而真实的环境需要有传感器;
(3)考虑数据的分析问题,可以对相应数据进行采集与汇总。
8.项目中的人员安排
任何一个技术型的公司里面都可能有若干个开发团队,每个团队的开发人数基本上就在3~6人之间,每个团队都有1个架构师(写代码),而且每一个团队对应的是一个具体的业务。在团队里面有3个开发,1个美工,这些是一个正规的开发团队的组成,所有的团队都会有项目经理存在。也要一部分公司全部请的都是架构师,这些架构师自己直接实现代码,这一类的人群技术要求是比较高的。在整个的项目里面还会有一些辅助人员:系统测试、支撑的人员,这些就属于项目的维护人员。
如果你想要从事软件行业,那么最好的做法是不去做这些辅助的工作,而直接上手开发,这样对你日后的发展是非常有帮助的。从最初的全栈工程师,到现在强调的是开发+运维,那么以后是全员架构时代,所有的开发人员一定都是能独当一面的高手。这类人的工资很高,但对于整个企业运行来讲,这样的成本是最低的。以后的开发之路:懂架构有未来。
9.密码加密处理
加密往往都会存在一种解密程序。
毒蛇出入七步之内必有解药。
最简单的加密:
(1)你的原始密码:abc;
(2)加密:cba;
如果所有的人都知道有这样的密码结构,那么就可以很轻松的破解了,可是如果你在里面追加一些内容。
你的原始密码:abc;
盐值:-
新密码:c-b-a-;
如果按照原始规则,那么现在就无法得到正确的原始密码。也就是说盐值是让整个密码看起来更加安全。
MD5的结构特征是不可逆,但是慢慢使用的时间长了,有些人就开始找到了一些规律,为了不让这些人破解密码,那么就在生成密码的时候增加一些额外的内容,这样的内容就是盐值,这样就可以避免这些人来破坏。不同的项目使用不同的盐值来进行处理。
10.商品秒杀设计方案
如果要进行商品秒杀操作一定要有一个前提:预估数据量。
小米进行抢购的时候都需要针对数据量进行预估:所有的人需要报名参加抢购;
淘宝或京东抢购的时候发现缺少报名,原因是它们是依靠大数据分析系统得来的预估数据量;
如果没有预估数据量,那么整个系统的先期准备就会不足。如果要进行秒杀操作,可以设计以下的流程:
(1)用户进行秒杀的登记;
(2)时间一到开始进行秒杀操作;
(3)在秒杀操作的过程中需要出现一个等待界面,如果此界面刷新了则抢购失败。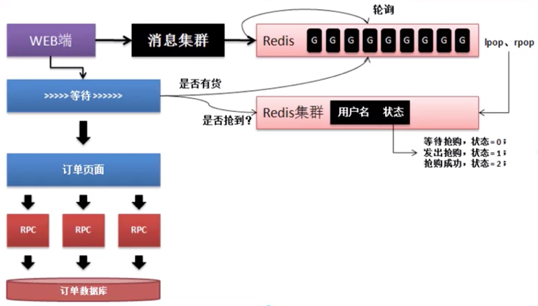
11.日志输出
在一般的系统开发里面,对于一些调试的数据都很少使用System.out进行输出,几乎都会配置Log4j开发包,这个开发并不复杂,你只需要配置上开发包,而后Logger类就可以使用了。
里面分为几种级别:info()、error()、wraning(),如果出现了异常一定使用的是error()。
之所以使用log4j输出,主要是方便进行调整。日志是我们解决问题的关键,所有的日志都应该输出到一个指定的目录之中,这样的配置都是固定的,不需要做特别的处理。
需要的就是配置log4j、slf4j这样的开发包就可以使用日志输出了。
12.企业项目部署
实际的环境架构设计,必须要充分的考虑到你的业务需求以及所谓的高峰访问的情况。假如说你有一个系统,一年有10个人访问,那么就不需要去搞架构了。
如果要进行架构设计,必须考虑以下几点:
(1)该架构能否动态扩容;
(2)该架构能否支撑HA机制;
(3)该架构是否长期有效。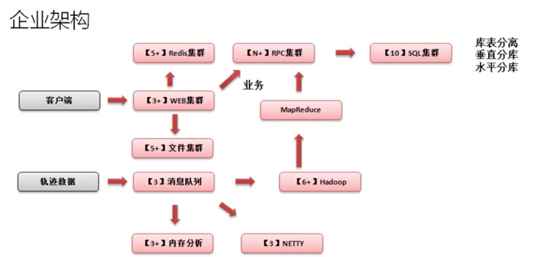
以上的集群设计是为了考虑性能平衡,但是会有一个问题存在:没有考虑到HA机制,如果考虑到高可用机制还需要追加更多的协助主机,这些主机将作为备选使用。
13.实际的项目开发
在实际的项目开发过程中,只有一点是确定的,就是Tomcat里面是没有数据库的。
如果要进行实际的项目开发,往往需要有许多的子系统。现在的开发领域经常出现一个概念:微架构。这种微架构的设计是有两种开发技术:Duubo、SpringColud。
如果要是将项目进行子系统的规划设计,所有的子系统里面包含的就是所有的业务层接口以及数据层的接口。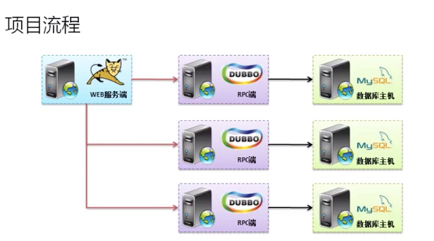
如果你做的是一些基础开发,那么对于整个的开发技术而言,你只需要一个数据库实现数据即可。当然还要考虑库表分离的问题,所有的数据库不可能无限制的让数据增长。
14.数据库优化
数据库本身是存储结构数据的,数据库优化指的是传统的关系型数据库操作,数据库的优化有以下几个使用原则:
(1)需要有一个非常专业的DBA,可以根据你的服务器的配置调整你的数据库的运行环境;
(2)数据库需要选择合适的操作系统才可以发挥优势;
(3)保证你的查询语句不会写的特别荒唐,例如你大量的采用了多表查询,在高并发的情况下依然采用同样的方式进行;
(4)可以将部分的数据静态化到缓存之中,例如学校、城市、姓名基本不会发生什么变化;
如果以上的要求都做到了,数据库的操作依然很慢,那么就有可能是数据量太大的原因了,此时无论你再如何进行优化,你的数据库的操作也不可能得到质的提升,这个时候就必须做先期的项目预估,这个预估的时候就需要考虑进行库表分离的有效设计:
(1)数据的分片保存(数据备份问题,一主多从的备份);
(2)数据的读写分离;
如果从程序本身的角度来讲,每一个用户的请求一定要及时的关闭好数据库的连接,不要打开过多的无效连接,以及在项目之中应该配置数据源。
15.项目阐述
(1)项目实际上没有大小之分,有的只是你的业务逻辑是否清楚。
在你进行项目设计的时候应该更清楚这个项目设计的业务是否合理,可以对某一个项目进行一些头脑风暴扩充;
(2)项目的解释必须要有一个原则:你的项目的使用环境、预估的访问人数、以及并发量;
(3)项目的开发技术,如果是单节点的开发技术,只需要传统的技术名词;
(4)如果你的项目设计的架构比价复杂,使用的服务节点比较多,这个时候你就需要清楚这些节点的作用、这些服务节点的安全处理你是如何进行的、节点间的数据互相同步处理;
(5)描述这个项目之中具备有多少个模块,完成的周期;
(6)你做了哪些项目,这些项目里面具体的业务是什么。

若有收获,就点个赞吧
0 人点赞
