- 我们知道,kubernetes集群上运行的所有Pod资源默认都会从同一平面网络上得到一个IP地址,无论是否处于同一名称空间,各Pod彼此之间都可以使用各自的地址直接通信,另一方面,Pod网络的管理却非kubernetes系统内置的功能,而是由第三方项目以CNI插件方式完成。进一步来说,除了Pod网络管理,有相当一部分CNI网络插件还实现了网络策略,这些插件赋予管理员和用户通过自定义Networkpolicy资源来管控Pod通信的能力
容器网络模型
- 自从Docker技术诞生以来,采用容器技术用于开发、测试甚至是生产环境的企业或组织与日俱增。然而,将容器技术应用于生产环境时如何确定合适的网络方案依然是急需解决的最大问题,这也曾是主机虚拟化时代的著名难题之一,它不仅涉及了网络中各组件的互联互通,还需要将容器与不相关的其他容器进行有效隔离以确保其安全性
- Network、IPC和UTS名称空间隔离技术是容器能够使用独立网络的根本,而操作系统的网络设备虚拟化技术是打通各容器间通信并构建起多样化网络拓扑的至关重要因素,在Linux系统上,这类的虚拟化设备类型有VETH、Bridge、VLAN、MAC VLAN、IP VLAN、VXLAN、MACTV和TAP/IPVTAP等。这些网络虚拟化相关的技术是支撑容器与容器编排系统网络的基础
容器网络通信模式
- 在Host模式中,各容器共享宿主机的根网络名称空间,它们使用同一个接口设备和网络协议栈,因此,用户必须精心管理共享同一网络端口空间容器的应用与宿主机应用,以避免端口冲突。
- Bridge模式对host模式进行了一定程度的改进,在该模式中,容器从一个或多个专用网络(地址池)中获取IP地址,并将该IP地址配置在自己的网络名称空间中的网络端口设备上。于是,拥有独立,隔离的网络名称空间的各容器有自己独占的端口空间,而不必再担心各容器及宿主机间的端口冲突
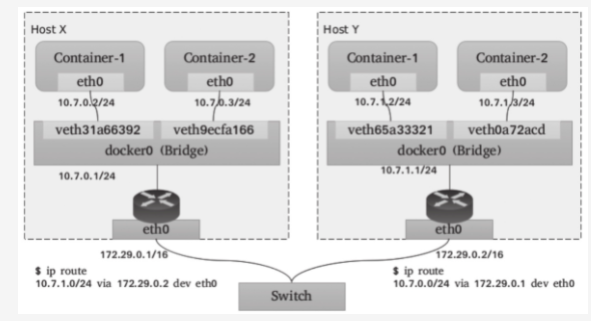
- 这里反复提到的Bridge是指Linux内核支持的虚拟网桥设备,它模拟的是物理网桥设备,工作于数据链路层,根据习得的MAC地址表向设备端口转发数据帧。虚拟以太网接口设备对(veth pair)是连接虚拟网桥和容器的网络媒介:一端插入到容器的网络栈中,表现位通信接口(例如eth0等),另一端则于宿主机上关联虚拟网桥并降级为当前的”从设备”,失去调用网络协议栈处理数据包的资格,从而表现为桥设备的一个端口。如下图所示

- Linux网桥提供的是宿主机内部的网络,同一主机上的各容器可基于网桥和ARP协议完成本地通信。而在宿主机上,网桥表现为一个网络接口并可以拥有IP地址,常见的如docker0桥,docker0会在docker daemon进程启动以后被自动配置172.17.0.1/16的IP地址。于是,由宿主机发出的网络包可以通过此桥接口送往连接至同一个桥上的其他容器,如上图所示的container1或container2,这些容器通常需要由某种地址分配组件(IPAM)自动配置一个相关网络(例如172.17.0.0/16)中的IP地址
- 但是此私有网络中的容器却无法直接宿主机之外的其他主机或容器进行通信,通常作为请求方,这些容器需要由宿主机上的iptables借助SNAT机制实现报文转发,而作为服务方时,它们的服务需要宿主机借助于iptables的DNAT规则进行服务暴漏。因而,总结起来,配置容器使用Bridge网络的步骤大概有如下几个:
- 若不存在,则需要现在宿主机上添加一个虚拟网桥
- 为每个容器配置一个独占的网络名称空间
- 生成一对虚拟以太网接口(如veth pair),将一端插入到容器网络名称空间,一端关联之宿主机上的网桥
- 为容器分配IP地址,并按需生成必须要的NAT规则
- 尽管Bridge模型下各容器应用使用独立且隔离的网络名称空间,且彼此间能够互联互通,但跨主机的容器通信时,请求报文会首先由源宿主机进行一次SNAT(源地址转换)处理,而后由目标宿主机进行一次DNAT(目标地址转换)处理方可送到目标容器。这种复杂的NAT机制将会使得网络通信管理的复杂度随容器规模的增长呈几何倍数上升,而且基于iptables实现的NAT规则也限制了解决方案的规模和性能。如下图所示跨节点通信

- kubernetes系统依然面临着类似的问题,只不过,跨节点的容器通信问题变成了更抽象的Pod资源问题。我们知道,kubernetes将具有亲密关系的容器整合成Pod作为基础单元,并设计了专用的网络模型来支撑kubernetes组件间以及与其他应用程序的通信。这种网络模型基于扁平网络结构,无需将主机端口映射到容器端口便能够完成分布式环境中的容器间通信,并负责解决4类通信需求:
- 同一Pod内容器间的通信:如前所述,Pod是kubernetes调度的原子单元,其内部的各容器必须运行在同一节点之上。一个Pod资源内的各容器共享同一网络名称空间,它通常由构建Pod对象的基础架构容器pasue所提供。因而,同一Pod内运行的多个容器通过Lo接口即可在本地协议栈上完成交互,如下图所示,Pod P内的container1和container2之间的通信,这类似与同一主机上的多个进程间的本地通信
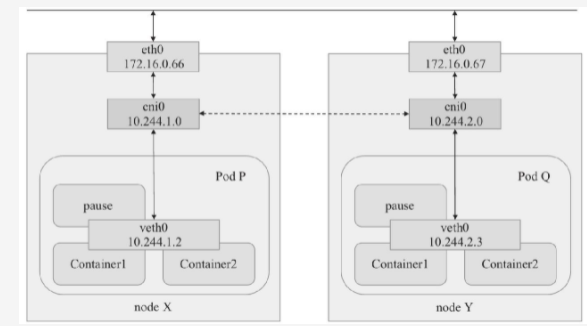
- Pod间的通信:各Pod对象需要运行在同一个平面网络中,每个Pod对象拥有一个虚拟网络接口和集群全局唯一的地址,该IP地址可用于直接与其他Pod进行通信,例如下图中的Pod P和Pod Q之间的通信。另外,运行Pod的各节点也会通过桥接设备等持有此平面网络中的一个IP地址,例如下图中的cni0接口,这意味着node和Pod间的通信也可以直接在此网络进行。因此,Pod间的通信或Pod到Node间的通信类似于同一IP网络中的主机间进行的通信, kubernetes设计了Pod通信模型,却把相关功能及编排机制的实现通过kubenet或CNI插件API开发给第三方来实现。这些第三方插件要负责为各Pod设置虚拟网络接口、分配IP地址并将其接入到容器网络中等各种任务,以实现Pod间的直接通信。目前,流行的CNI网络插件有数十种之多,例如后面讲到的flannel以及calico、canal和weavenet等
- service到Pod间的通信:service资源的专用网络也称为集群网络,需要在启动kube-apiserver时由—service-cluster-ip-range选项进行指定,例如默认的10.96.0.0/12,每个service对象在此网络中拥有一个称为cluster-ip的固定地址。管理员或用户对service对象的创建或更改操作,会由apiserver存储完成后触发各节点上的kube-proxy,并根据代理模式的不同将该service对象定义为相应节点上的iptables规则或ipvs规则,Pod或节点客户端对service对象的IP地址的范围跟请求将由这些iptables或ipvs规则进行调度和转发,从而完成Pod与service之间的通信
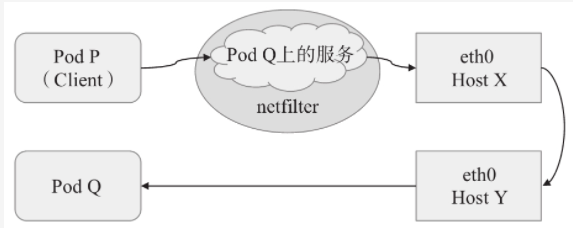
- 集群外部与service间的通信:引入集群外部流量到达Pod对象有四种方式,有两种是基于本地节点的端口或根网络名称空间(hostNetwork),另外两种则是基于工作在集群级别的NodePort或者LoadBalancer类型的service对象。不过,即便是四层代理的模式也要经过两级转发才能到达目标Pod资源:请求流量首先会到达外部负载均衡器,尤其调度至某个节点之上,而后再由工作节点的netfilter(kube-proxy)组件上的规则(iptables或者ipvs)调度至某个目标Pod对象
- 同一Pod内容器间的通信:如前所述,Pod是kubernetes调度的原子单元,其内部的各容器必须运行在同一节点之上。一个Pod资源内的各容器共享同一网络名称空间,它通常由构建Pod对象的基础架构容器pasue所提供。因而,同一Pod内运行的多个容器通过Lo接口即可在本地协议栈上完成交互,如下图所示,Pod P内的container1和container2之间的通信,这类似与同一主机上的多个进程间的本地通信
- 我们知道,集群内的Pod间通信,即便通过service进行“代理”和“调度”,但绝大部分都无需使用NAT,而是Pod间的直接通信,由此可见,上面的四种通信模型中,仅“分布式Pod间通信”是负责解决跨节点间容器通信的核心所在,但再kubernetes从1.0之前的版本起就把这个问题通过kubenet插件API开放给了社区,把网络协议栈的管理从容器运行时分离出来,这种抽象有助于将容器管理和网络管理分开,也为不同的组织独立解决容器编排和容器网络编排的问题提供了空间。任何遵循该API开放的容器网络编排插件都可以同kubernetes系统一起协同工作,这其中以CoreOS维护的flannel项目为最具代表性
- kubenet是一个非常基础、简单的网络插件,它本身并未实现任何跨节点网络和网络策略一类更高级的功能,且仅适用于Linux系统,于是,kubernetes试图寻求一个更开放的网络插件接口标准来替代它。分别由docker与coreos涉及的CNM(Container Network Model)和CNI是两个主流的竞争模型,但CNM在设计上做了很多与kubernetes不兼容的假设,而CNI却有着与kubernetes非常一致的设计哲学,它远比CNM简单,不需要守护进程,并且能够跨多个容器运行时平台。于是,CNM因专注Docker容器引擎设计且难分离而落选,而CNI就成了目前kubernetes系统上标准的网络插件接口规范。目前,绝大多数为kubernetes解决Pod网络通信问题的插件都是遵循CNI规范的实现
CNI网络插件基础
- 每个Pod对象内的基础架构容器均使用一个独立的网络名称空间,并共享给同一Pod内的其他容器使用。每个名称空间均有其专用的独立网络协议栈及其相关的网络接口设备。一个网络接口仅能用于一个网络名称空间,于是,运行多个Pod必然要求使用多个网络名称空间,也就需要用到多个网络接口设备。不过,一个易于实现的方案是使用软件实现的伪网络接口及模拟线缆将其连接至物理接口
- CNI是容器引擎与遵循该规范网络插件的中间层,专用于为容器配置网络子系统,目前由RKT、Docker、kubernetes、openshift和mesos等相关的容器运行时环境所运行
- 通常,遵循CNI规范的网络插件是一个可执行程序文件,它们可由容器编排系统调用,负责向容器的网络名称空间插入一个网络接口并在宿主机上执行必要的任务以完成虚拟网络配置,因而通常被称为网络管理插件,即NetPlugin。随后,NetPlugin还需要借助IPAM插件为容器的网络接口分配IP地址,这意味着CNI允许将核心网络管理功能与IP地址分配等功能相分离,并通过插件组合的方式堆叠出一个完整的解决方案。简单来说,目前的CNI规范主要由NetPlugin和IPAM两个插件API组成,如下图

- 以下是对两个插件的简要说明
- 网络插件也称Main插件,负责创建/删除网络以及向网络添加/删除容器,它专注于连通容器与容器之间以及容器与宿主机之间的通信,同容器相关的网络设备通常都由该类插件所创建,例如Bridge、IP Vlan、MAC Vlan、loopback、PTP、VETH以及VLAN等虚拟设备
- IPAM(IP Adress Management),该类插件负责创建/删除地址池以及分配/回收容器的IP地址;目前,该类型插件的实现主要有host-local和dhcp两个,前一个基于预置的地址范围进行地址分配,而后一个通过DHCP协议获取地址
- 显然NetPlugin是CNI中重要的组成部分,它才是执行创建虚拟网络、为Pod生成网络接口设备,以及将Pod接入网络中等核心任务的插件。为了能够满足分布式Pod通信模型中要求的所有Pod必须在同一平面网络中的要求。NetPLugin目前常用的实现方案有Overlay网络(Overlay Network)和Underlay网络(Underlat Network)两类
- Overlay网络借助于VXLAN、UDP、IPIP或GRE等隧道协议
- Underlay网络通常使用direct routing(直接路由)技术在Pod各子网间路由Pod的IP报文、或使用Bridge、MAC VLAN或IP VLAN等技术直接将容器暴漏给外部网络
- 其实,Overlay网络的底层网络也就是承载网络,因此Underlay网络的解决方案也就是以类非借助隧道协议而构建的容器通信网络。相比较于承载网络,Overlay网络由于存在额外的隧道报文封装,会存在一定程度的性能开销。然而,用户在不少场景中可能会希望创建跨多个L2或者L3的逻辑网络子网,这就只能借助overlay封装协议实现
- 为Pod配置网络接口是NetPlugin的核心功能之一,但不同的容器虚拟化网络解决方案中,为Pod的网络名称空间创建虚拟接口设备的方式也会有所不同,目前较为主流的实现方式有veth(虚拟以太网)设备,多路复用及硬件交换三种
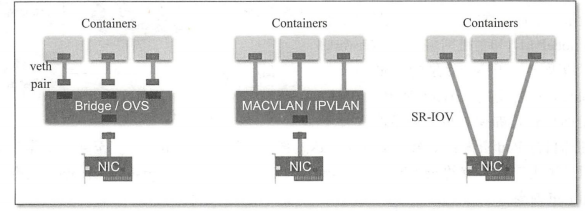
- VETH(虚拟以太网):创建一个虚拟以太网接口,一个接入容器内部,另外一个留置于根名称空间内并借助于Linux内核桥接功能或openVSwitch(OVS)关联至真实的物理接口
- 多路复用:多路复用可以由一个中间网络设备组成,它暴露多个虚拟接口,使用数据包转发规则来控制每个数据包转到的目标接口;MAC VLAN技术为每个虚拟接口配置一个MAC地址并基于此MAC地址完成二层报文收发,IPVLAN则是分配一个IP地址并共享单个MAC,并根据目标IP完成容器报文转发
- 硬件交换:如今市场上有非常多的NIC都支持SR-IOV(单根I/O虚拟化),它是创建虚拟设备的一种实现方式,每个虚拟设备自身表现为一个独立的PCI设备,并有着自己的VLAN及硬件强制关联的QOS;SR-IOV提供了接近硬件级别的性能
- 值得注意的是,IAAS公有云环境中的VPS和云主机内部使用的是已经虚拟网卡,它们通常无法支持硬件交换功能,甚至是对IP VLAN或MAC VLAN等也多有限制,但云服务商通常会提供专有的VPC解决方案
- 一般来说,基于VXLAN Overlay网络的虚拟容器网络中,NetPlugin会使用虚拟以太网内核模块为每个Pod创建一对虚拟网卡;基于MAC VLAN/IP VLAN Underlay网络的虚拟容器网络中,NetPlugin会基于多路复用模式中的MAC VLAN和IP VLAN内核模块为每个Pod创建虚拟网络接口设备;而基于IP报文路由技术的Underlay网络中,各Pod接口设备通常也是借助veth设备完成
- 相比较来说,IPAM插件的功能则要简单的多,目前可用的实现方案中,host-local从本地主机可用的地址空间范围中分配IP地址,它没有地址租约,属于静态分配机制;而DHCP插件则需要一个特殊的客户端守护进程(通常是DHCP插件的子组件)运行在宿主机之上,它充当本地主机上各容器中的DHCP客户端与网络中的DHCP服务器之间的代理,并适当的续订租约
- 无论以上哪种方式应用于容器环境中,其实现过程都需要大量的操作步骤,不过目前kubernetes借助CNI插件体系来组合需要的网络插件完成容器网络编排自动化功能。每次初始化和或删除Pod对象时,kubelet都会调用默认的CNI插件创建一个虚拟设备接口附加到相关的底层网络,为其设置IP地址、路由信息并将其映射到Pod对象的网络名称空间。
- 配置Pod网络时,kubelet首先在默认的/etc/cni/net.d/目录中查找json格式的CNI配置文件,接着基于该配置我呢见中各插件的type属性到/opt/cni/bin/中查找相关的插件二进制文件,由该二进制程序基于提供的配置信息完成相应的操作
[root@kube-master-01 ~]# cat /etc/cni/net.d/10-flannel.conflist{"name": "cbr0","cniVersion": "0.3.1","plugins": [{"type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]}[root@kube-master-01 ~]#
- kubelet基于包含命令参数
CNI_ARGS、CNI_COMMAND、CNI_IFNAME、CNI_NETNS、CNI_CONTAINERID、CNI_PATH的环境变量调用CNI插件,而被调用的插件同样使用json格式的文本信息进行响应,描述操作结果和状态。Pod对象的名称和名称空间将作为CNI_ARGS变量的一部分进行传递(例如K8S_POD_NAMESPACE=default;K8S_POD_NAME=myapp-xx-xxx)它可以定义每个Pod对象或Pod网络名称空间的网络配置,比如将每个网络名称空间放在不同的子网中
Overlay网络模型
- 物理网络模型中,连通多个物理网桥上主机的一个简单办法是通过媒介直接连接这些网桥设备,各个主机处于同一个局域网之中,管理员只需要确保各个网桥上每个主机的IP地址不相互冲突即可。类似的,若能够直接连接宿主机上的虚拟网桥形成一个大的局域网,就能在数据链路层打通各宿主机上的内部网络,让容器可通过自有IP地址直接通信。为了避免各容器间的IP地址冲突,一个常见的解决方案是将每个宿主机分配到同一个网络中的不同子网,各主机基于自有子网向其容器分配IP地址
- 显然,主机间的网络通信只能经由主机上可对外通信的网络接口进行,跨主机在数据链路层直接连接虚拟网桥的需求必然难以实现,除非借助宿主机间的通信网络构建的通信”隧道”进行数据帧转发
- 隧道转发的本质是将容器双方的通信报文分别封装成各自宿主机之间的报文,借助宿主机的网络”隧道”完成数据交互。这种虚拟网络的基本要求是各宿主机只需要支持隧道协议即可,对于底层网络没有特殊要求
- VCLAN协议是目前最流行的Overlay网络隧道协议之一,它也是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,采用L2 Over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展,将”二层域”突破规模限制形成”大二层域”。那么,同一大二层域就类似于传统网络中的VLAN(虚拟局域网)的概念,只不过在VXLAN网络中,它被称作Bridge-domain(BD)。类似于不同的VLAN需要通过VLAN ID进行区分,各BD要通过VNI加以标识。但是,为了确保VXLAN机制通信过程的正确性,设计VXLAN通信的IP报文一律不能分片,这就要求物理网络的链路层实现中必须提供足够大的MTU值,或修改其MTU值以保证VXLAN报文的顺利传输。不过,降低默认的MTU值,以及额外的头部开销,必然会影响到报文传输性能
- VXLAN的显著的优势之一是对底层网络没有侵入性,管理员只需要在原有网络之上添加一些额外设备即可构建出虚拟的逻辑网络来。这个额外添加的设备称为VETP(VXLAN Tunnel Endpoints),它工作于VXLAN网络的边缘,负责相关协议报文的封包和解包等操作,从作用来说相当于VXLAN隧道的出入口设备
- VETP代表着以类支持VXLAN协议的交换机,而支持VXLAN协议的操作系统也可以将一台主机模拟为VTEP,Linux内核自3.7版本开始通过vxlan内核模块原生支持协议。于是,各主机上由虚拟网桥构建的LAN便可借助VXLAN内核模块模拟的VTEP设备与其他主机上的VTEP设备进行对接,形成隧道网络。同一个二层域内的各VTEP之间都需要建立VXLAN隧道,因此跨主机的容器间直接进行二层通信的VXLAN隧道是各VTEP之间的点对点隧道。对于flannel.1网络接口其中的”1”是vxlan中的BD标识VNI,因而同一kubernetes集群上所有节点的vtep设备属于VNI为1的同一个BD
- 类似VLAN的工作机制,相同VXLAN VNI在不同的VTEP之间的通信要借助二层网关来完成,而不同VXLAN之间,或者VXLAN与非VXLAN之间的通信则需要经由三层网关实现。VXLAN支持使用集中式和分布式两种形式的网关:前者支持流量的集中管理,配置和维护较为简单,但转发率不高,且容易出线瓶颈和网关可用性问题;后者以各节点为二层或三层网关,消除了瓶颈
- 然而,VXLAN网络中的容器在首次通信之前,源VTEP又如何得知目标服务器在哪一个VTEP,并选择正确的路径传输通信报文呢?常见的解决思路一般有两种:多播和控制中心。多播是指同一个BD内的各VTEP加入同一个多播域中,通过多播报文查询目标服务器所在的目标VTEP。而控制中心则是某个共享的存储服务上保存所有容器子网及相关VTEP的映射信息,各主机上运行着相关的守护进程,并通过与控制中心的通信获取相关的映射信息,各主机上运行着相关的守护进程,并通过与控制中心的哦你更新获取相关的映射信息。flannel默认的VXLAN后端采用的是后一种方式,它把网络配置信息存储在etcd系统上
- Linux内核自3.7版本开始支持vxlan模块,此前的内核版本可以使用UDP、IPIP或GRE隧道技术。事实上,考虑到当今公有云底层网络的功能限制,Overlay网络反倒是一种最为可行的容器网络解决方案,仅那些更注重网络性能的场景才会选择underlay网络
Underlay网络模型
- Underlay网络就是传统IT基础设施网络,由交换机和路由器等设备组成,借助以太网协议、路由协议和VLAN协议等驱动,它海是Overlay网络的底层网络,为Overlay网络提供数据通信服务。容器网络中的Underlay网络是指借助驱动程序将宿主机的底层网络接口直接暴漏给容器使用的一种网络构建技术,较为常见的解决方案由MAC、VLAN、IP VLAN和直接路由等
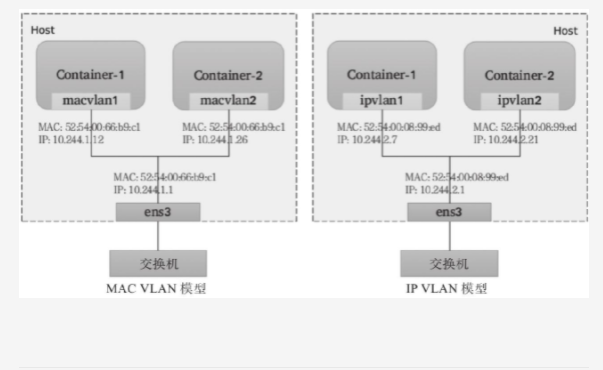
MAC VLAN
- MAC VLAN支持在同一个以太网接口上虚拟出多个网络接口,每个虚拟接口都拥有唯一的MAC地址,并可需配置IP地址。通常这类虚拟接口被网络工程师称作子接口,但在MAC VLAN中更常用上层或下层接口来表述。与Bridge模式相比,MAC VLAN不再依赖虚拟网桥NAT和端口映射,它允许容器以虚拟接口方式直接连接物理接口。如下图所示给出了Bridge与MAC VLAN网络对比示意图

- MAC VLAN有private、VEPA、Bridge和Passthru几种工作模式,它们各自的工作特性如下
- Private:禁止构建在同一物理接口上的多个MAC VLAN实例(容器接口)彼此间的通信,即便外部的物理交换机支持”发夹模式”也不行
- VPEA:允许构建在同一物理接口上的多个MAC VLAN实例(容器接口)彼此简单通信,但需要外部交换机启用发夹模式,或者存在报文转发功能的路由设备
- Bridge:将物理接口配置为网桥,从而允许同一物理接口上的多个MAC VLAN实例基于此网桥直接通信,而无需依赖外部的物理交换机来交换报文;此为最常用的模式,甚至是docker容器唯一支持的模式
- Passthru:允许其中一个MAC VLAN实例直接连接物理接口
- 由上述工作模式可以知道,除了Passthru模式外的容器流量将被MAC VLAN过滤而无法与底层主机通信,从而将主机与其允许的容器完全隔离,其隔离级别甚至高于网桥式网络模型。这对于有多租户需需求的场景尤为有用。由于各实例都有专用的MAC地址,因此MAC VLAN允许传输广播和多播流量,但它要求物理接口工作与混杂模式,考虑到很多公有云环境中并不允许使用混杂模式,这意味着MAC VLAN更适用于本地网络环境
- 需要注意的是,MAC VLAN为每个容器使用一个唯一的MAC地址,这可能会导致具有安全策略以防止MAC欺骗的交换机出线问题,因为这类交换机的每个接口只允许连接一个MAC地址。另外,有些物理网卡存在可支撑的MAC地址数量上限
IP VLAN
- IP VLAN类似于MAC VLAN,它同样创建新的虚拟网络接口并为每个接口分配唯一的IP地址,不同之处在于,每个虚拟接口将共享使用物理接口的MAC地址,从而不再违反防止MAC欺骗的交换机的安全策略,且不要求在物理接口上启用混杂模式
- IPVLAN有L2和L3两种模型,其中IPVLAN L2的工作模式类似于MAC VLAN Bridge模式,上层接口(物理接口)被用作网桥或交换机,负责为下层接口交换报文;而IP VLAN L3模式中,上层接口扮演路由器的角色,负责为各下层接口路由报文

- IP VLAN L2模型与MAC VLAN Bridge模型都支持ARP协议和广播流量,它们拥有直接接入网桥设备的网络接口,能够通过802.1d数据包进行泛红和MAC地址学习。但IP VLAN L3模式下,网络栈在容器内处理,不支持多播或广播流量,从这个意义上讲,它的运行模式与路由器的报文处理机制相同
- 虽然支持多种网络模型,但MAC VLAN和IP VLAN不能同时在同一物理接口上使用。Linux内核文档中强调,MAC VLAN和IP VLAN具有较高的相似度,因此,通常仅在必须使用IP VLAN的场景中才不会使用MAC VLAN。一般来说,强依赖于IP VLAN的场景可能有如下几个
- Linux主机连接到的外部交换机或路由器启用了防止MAC地址欺骗的安全策略
- 虚拟接口的需求数量超出了物理接口能够支撑的上限。并且将接口配置成混杂模式会给性能带来较大的负面影响
- 将虚拟接口放入不受信任的网络名称空间中可能会导致恶意的滥用
- 需要注意的是,Linux内核自4.2版本后才支持IP VLAN网络驱动,且在Linux主机上使用ip link命令创建的802.1q配置接口不具有持久性,因此需要依赖管理员通过网络启动脚本保持配置
直接路由
- 直接路由模型放弃了跨主机在L2的连通性,而专注于通过路由协议提供容器在L3的通信方案。这种解决方案因为更易于集成到现在的数据中心的基础设施上,便捷的连接容器和主机,并在报文过滤和隔离方面有着更好的扩展能力及更精细的控制模型,因而称为容器化网络较为流行的解决方案之一
- 一个常用的直连路由方案如下图所示,每个主机上的各容器在二层通过网桥连通,网关指向当前主机上的网桥接口地址。跨主机的容器间通信,需要依据主机上的路由表指示完成报文路由,因此每个主机的物理接口地址都有可能成为另一个主机路由报文中的”下一跳”,这就要求各主机的物理接口必须位于同一个L2网络中
- 于是,在较大规模的主机集群中,问题的关键便转向如何更好的为每个主机维护路由表信息。常见的解决方案有:1.flannel host-gw使用存储总线etcd和工作在每个节点上的flanneld进程动态维护路由;2.Calico使用BGP(Border Gateway Protocol)协议在主机集群中自动分发和学习路由信息。与flannel不同的是,calico并不会为容器在主机上使用网桥,而是仅为每个容器生成一对veth设备,留在主机上的那一端会在主机上生成目标地址,作为当前容器的路由条目。如下图所示,calico的直连路由模型图

- 显然,较overlay来说,无论是MAC VLAN、IP VLAN还是直接路由机制的underlay网络模型的实现,它们因无需额外的报文开销而通常有着更好的性能表现,但对底层网络有着更多的限制条件
配置CNI插件
- CNI具有很强的扩展性和灵活性,例如,如果用户对某个插件有特殊的需求,可以通过输入中的args和环境变量CNI_ARGS传递,然后在插件中实现自定义的功能,这大大增加了它的扩展性。CNI插件把main和ipam分开,为用户提供了自由组合它们的机制,甚至一个cni插件也可以直接调用另外一个插件
- CNI项目中有两个代码仓库:一个是提供用于开发CNI网络插件的库文件libcni,以及命令行工具cnitool的containernetworking/cni;另一个是cni内置的插件程序containernetworking/plugins,它目前附带了如下几类网络插件
- main类别中,各插件主要用于创建容器和容器接口,内置的实现有如下几个
- Bridge: 创建一个虚拟网桥,并将宿主机和每个Pod接入该网桥
- ipvlan:向容器中添加一个IP VLAN网络接口
- macvlan:向容器中添加一个MAC VLAN网络接口,创建一个新MAC地址,并基于该地址向容器转发报文
- loopback: 设置容器lo接口的状态
- ptp:创建一对veth设备
- vlan:分配一个vlan设备
- host-device:将宿主机现有的某网络接口移入Pod中
- ipam类别中,各插件用于为容器分配IP地址,内置的实现包括host-local、dhcp和static
- dhcp: 在每个节点上运行一个DHCP守护进程,它负责代理该节点上的所有容器中的DHCP客户端向DHCP服务发起请求
- host-local:基于本地的IP地址分配数据库,完成IP地址分配
- static:为容器接口直接指定一个静态IP地址,仅应该用于调试目的
- meta类别的网络插件不实现任何网络功能,它们调用其他网络工具或插件完成管理功能,内置的实现有如下几个
- flannel:根据flannel配置文件生成网络接口
- tuning:调整现存某接口的sysctl参数值
- portmap:使用iptables将宿主机的端口映射至容器端口,实现hostPort功能
- bandwidth:基于流量控制工具bdf进行带宽限制
- sbr:为接口配置基于源IP地址的路由
- firewall:防火墙插件,使用iptables或firewalld规则管理进出的流量
- main类别中,各插件主要用于创建容器和容器接口,内置的实现有如下几个
- 具体操作方面,CNI网络插件通常应该支持添加(ADD)、删除(DEL)、检验(CHECK)和报告版本信息(VERSION)几个管理操作。除了VERSION外,其他三个操作通常都需要用到以下几个方面的配置信息
- container ID:容器标识,用于引用容器网络名称空间
- 网络名称空间(netns)路径:即配置的目标网络名称空间的访问路径,例如
/proc/[pid]/ns/net等;通吃指定引用的容器ID后,其网络名称空间路径可通过容器的相关属性获取 - 网络配置参数:一个json格式的配置文件,描述了配置容器网络的各相关参数,例如
/etc/cni/net.d/10-flannel.conflist - 其他配置参数:用于在容器级别为每个容器提供一个简单的配置方式,以取代统一配置机制
- 容器内的网络接口名称:网络插件配置的目标接口,需要是遵循Linux系统网络插件命名规范的接口名称
- 在含有网络配置参数的json格式的配置文件中,type属性用于指定要调用的网络插件的名称,调用者(例如kubernetes或者openshift等)可从预定义的目标列表中查找相关网络插件的可执行文件,并通过如下几个变量向其传递参数
- CNI_COMMAND: 需要执行的网络管理操作,例如ADD、DEL、CHECK或VERSION
- CNI_CONTAINERID:容器ID
- CNI_NETNS:网络名称空间相关的文件路径
- CNI_IFNAME:目标网络接口的名称,如果插件无法使用此接口,则必须返回错误
- CNI_ARGS:额外传入的参数
- CNI_PATH: 搜索CNI插件时使用的目标路径列表
- CNI_CONF_NAME: 使用的网络配置文件
- 插件的相关管理操作执行成功时以0为返回码,其中ADD操作成功时的返回结果是一个json格式的输出,它通常包含cniVersion、interface、ips、routes和dns几个数据段
- 如前所述,kubelet中的CNI网络插件的配置文件以json格式表达,它可以以静态格式存储于磁盘上,也可以由容器管理系统从其他源动态生成,下面是配置文件中的常用字段
cniVersion: <string> #CNI配置文件的语义版本name: <string> #网络的名称,在当前主机上必须唯一type: <string> #CNI插件的可执行文件名args: <map[string]string> #由容器管理系统提供的附加参数,可选配置ipMasq: <boolean> #是否启用IP伪装,可选参数ipam: <map[string]string> #IP地址分配插件,只要有host-local和dhcptype: <string> #能够完成IP地址分配的插件的名称subnet: <string> #分配IP地址时使用的子网地址routes: <string> #路由信息dst: <string> #目标主机网络gw: <string> #网关地址dns: <map[string]string> #配置容器的DNS属性nameservers: <[]string> #DNS名称服务器列表,其值为IPV4或IPV5格式的地址domain: <[]string> #用于短格式主机查找的本地域search: <[]string> #用于短格式主机查找的优先级排序的搜索域列表options: <[]string> #传递给解析程序的选项列表
- 作为基本功能的一个组成部分,CNI插件需要为接口分配和维护IP地址,并负责为IP地址生成必要的路由信息。这为CNI插件提供了极大的灵活性的同时也引入了较大负担,并且众多CNI插件可能需要重复提供相同的代码以完成此类功能。于是,IP地址分配通常由独立的IP地址管理(IPAM)插件负责,并由CNI插件进行调用以完成代码复用,常用的IP地址分配类型有host-local和dhcp两个,它们负责分配地址并将结果返回给调用者
- IPAM插件同CNI插件一样,都是通过运行相关的可执行文件进行调用,调用者在由CNI_PATH变量预定义的路径列表中搜索目标IPAM的可执行文件。IPAM插件必须接收所有传递给CNI插件的相同环境变量,类似于CNI插件,IPAM插件也通过标准输入(stdin)接收网络配置信息
- 下面是一个示例配置,它使用Bridge插件,ipam调用类型为host-local,它通过在一个地址范围内挑选一个未使用的IP完成地址分配
{
"cniVersion": "0.4.0",
"name": "mynet",
"type": "bridge",
// 插件类型专有的配置
"bridge": "cni0",
"ipam": {
"type": "host-local",
// ipam专有的配置
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameserver": ["10.1.0.1"]
}
}
- CNI还支持使用plugins字段组合多个CNI网络插件依次进行网络配置,以实现将核心网络管理插件和meta插件等相结合,以堆叠出一个完整的解决方案。各插件以列表形式依次定义,前一个插件的配置结果将传递给后一个插件,直到列表中的所有插件都成功配置完成。下面是摘自flannel自行提供CNI的网络配置,它使用网络配置列表,分别调用了flannel插件和PortMap插件来完成容器网络
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
- delegate是指将网络配置”委派”给某个指定的CNI内置插件来完成,对于flannel插件来说,它通过delegate调用的插件是bridge,因此容器网络配置实际上是由bridge插件完成,flannel不过是借助delegate向Bridge插件传递部分配置参数,例如网络地址10.244.0.0/16等信息
- 另外delegate配置段中的hairpinMode参数用于定义是否启用发夹模式,在容器中的应用通过宿主机的端口映射(NAT)访问自己提供的服务时,此模式必须要配置成启用状态,默认情况下,网桥设备不允许一个数据报文从同一端口进行收发操作,而发夹模式是用于取消限制。例如,某Pod作为客户端访问自己所属service对象又碰巧被算法调度回自身时,就必须要启用发夹模式
CNI插件与选型
- 如前所述,CNI规范负责连接容器管理系统和网络插件两类组件,它们之间通过json格式的文件进行通信,以完成容器网络管理。具体的管理操作均有插件来实现,包括创建容器netns(网络名称空间)、关联网络接口到对应的netns,以及给网络接口分配IP等。CNI的基本思想是为容器运行时环境在创建容器时,先创建好netns,然后调用CNI插件为这个netns配置网络,而后启动容器内的进程
- CNI本身只是规范,付诸生产还需要有特定的实现。如前所述,目前CNI提供的插件分为main、ipam和meta,各类别中都有不少内置实现。另外,可用第三方实现的CNI插件也有数十种之多,他们多数都是用于提供NetPlugin功能,隶属于main插件类型,只要用于配置容器接口容器网络,这其中,也有不少实现功能支持kubernetes的网络策略。下面是较为流行的部分网络插件项目
- flannel: 由CoreOS提供的CNI网络插件,也是最简单,最受欢迎的网络插件;它使用VXLAN或UDP协议封装IP报文来创建overlay网络,并借助etcd维护网络的分配信息,同一节点上的Pod间通信可基于本地虚拟网桥(cni0)进行,而跨节点的Pod间通信则要由flanneld守护进程封装隧道协议报文后,通过查询etcd路由到目的地;flannel也支持host-gw路由模型
- calico:与flannel一样是广为流行的CNI网络插件,以灵活,良好的性能和网络策略所著称。calico是路由型CNI网络插件,它在每台机器上运行一个vRouter,并基于BGP路由协议在节点之间路有数据包。calico支持网络策略,它借助iptables实现访问控制功能。另外,calico也支持IPIP型的overlay网络
- canal:由flannel和calico联合发布的一款统一网络插件,它试图将二者的功能集成在一起,由前者提供CNI网络插件,由后者提供网络策略
- WeaveNet:由Weaveworks提供的CNI网络插件,支持网络策略。WeaveNet需要在每个节点上部署vRouter路由组件以构建起一个网格化的TCP连接,并通过Gossip协议来同步控制信息。在数据平面上,weavenet通过UDP封装实现L2隧道报文,报文封装支持两种模式:一种是运行在用空间的sleeve(套筒)模式,另一种是运行在内核空间的fastpath(快速路径)模式,当网络拓扑不适合fastpath模式时,weave将自动切换至sleeve模式
- Multus CNI: 多CNI插件,实现了CNI规范的所有参考类插件(例如flannel、MAC VLAN、IP VLAN和DHCP等)和第三方插件(例如calico、weave和contiv等),也支持kubernetes中的SR-IOV、DPDK、OVS-DPDK和VPP工作负载,以及kubernetes中的云原生应用程序和基于NFV的应用程序,是需要为Pod创建多网络接口时的常用选择
- Antrea: 一款致力于成为kubernetes原生网络解决方案的CNI网络插件,它使用openvswitch构建数据平面,基于overlay网络模型完成Pod间的报文交换,支持网络策略,支持使用IPSec ESP加密GRE隧道流量
- DAMM: 由诺基亚发布的电信级的CNI网络插件,支持具有高级功能的IP VLAN模式,内置IPAM模块,可管理多个集群范围的不连续三层网络;支持通过CNI meta插件将网络管理功能委派给任何其他网络插件
- kube-router:kube-router是kubernetes网络的一体化解决方案,它可取代kube-proxy实现基于ipvs的service,能为Pod提供网络,支持网络策略以及拥有完美兼容BGP协议的高级特性
尽管人们倾向于把overlay网络作为解决跨主机容器网络的主要解决方案,但可用的容器网络插件在功能和类型上差别巨大:某些解决方案与容器引擎无关,而也有些解决方案使用后,容易被特定的供应商引擎锁定;有些专注于简单易用,而另一些的主要目标则是更丰富的功能特性等,至于哪一个解决方案更适用,通常取决于应用程序自身的需求,例如性能需求,负载位置编排机制等。通常来说,选择网络插件时应该基于底层系统环境限制、容器网络的功能需求和性能需求三个重要的评估标准来衡量插件的适用性
底层系统环境限制:公有云环境多有自己专有的实现,例如Google GCE、Azure CNI、AWS VPC CNI和Aliyun Terway等,它们通常是相应环境上较佳的选择。若虚拟化环境限制较多,除overlay网络模型别无选择,则可用的方案有flannel VXLAN、Calico IPIP、weave和Antrea等。物理机环境几乎支持任何类型的网络插件,此时一般应该选择性能较好的calico BGP、flannel host-gw或者DAMM IP VLAN等
- 容器网络功能需求:支持NetworkPolicy的解决方案以calico、weaveNet和Antrea为代表,而且后两个支持节点到节点间的通信加密。而大量POD需要与集群外部资源互联互通时,应该选择underlay网络模型一类的解决方案
容器网络性能需求:overlay网络中的协议报文有隧道开销,性能略差,而underlay网络则几乎不存在这方面的问题,但Overlay或underlay路由模型的网络插件支持较快的Pod创建速度,而Underlay模型中的IP VLAN或MAC VLAN模式则较慢
随着kubernetes的演进,必将会有越来越多的CNI插件涌现,它们各具特色、各有优劣。实践中,用户根据实际多方评测与需要选择合适的解决方案即可,但不建议中途改换网络插件。
Flannel网络插件
- flannel是用于解决容器跨节点通信问题的解决方案,兼容CNI插件API、支持kubernetes、openshift、cloud Foundy、mesos、Amazon ECS、singularity和opensvc等平台。它使用“虚拟网桥和veth设备”的方式为Pod创建虚拟网络接口,通过可配置的”后端”定义Pod间的通信网络,支持基于VXLAN和UDP的overlay网络,以及基于三层路由的underlay网络。在IP地址分配方面,它将预留的一个专用网络(默认为10.244.0.0/16)切分成多个子网后作为每个节点的Pod CIDR,而后由节点以IPAM插件的host-local形式进行地址分配,并将子网分配信息保存于etcd中
flanne配置基础
- flannel在每个主机上运行一个名为flanneld的二进制代理程序、它负责从预留的网络中按照指定或默认的掩码长度为当前节点申请分配一个子网,并将网络配置、已分配的子网和辅助数据(例如主机的公网IP等)存储在kubernetesAPI或ETCD之中。flannel使用称为后端的容器网络机制转发跨节点的Pod报文,它目前支持的主流后端如下
- vxlan: 使用Linux内核中的vxlan模块封装隧道报文,以overlay网络模型支持跨节点的Pod间互联互通;同时,该后端类型支持直接路由模式,在该模式下,位于同一二层网络内节点之上的Pod间通信可通过路由模式直接发送,而跨网络的节点之上的Pod间通信仍需要使用VXLAN隧道协议转发;因而,VXLAN隶属于overlay网络模型,或混合网络模型;vxlan后端模式中,flanneld监听UDP的8472端口发送的封装数据包
- host-gw:即host gateway,它类似于vxlan中的直接路由模式,但不支持跨网络的节点,因此这种方式强制要求各节点本身必须在同一个二层网络模式中,不太适用于较大的网络规模;host-gw有着较好的转发性能,且易于设定,推荐对报文转发性能要求较高的场景使用
- UDP:使用常规UDP报文封装完成隧道转发,性能较前两种方式低很多,它仅在不支持前两种后端的环境中使用;UDP后端模式中,flanneld监听UDP的8285端口发送的封装报文
- flannel初创的一段时间,不少环境中使用的主流linux发行版的内核尚且不支持VXLAN,而host-gw模式有着较高的网络技术门槛,多数部署场景只好采用UDP后端,flannel也就不幸的被冠以性能不好的名声。好在,随和各主流Linux发行版内核版本内置支持vxlan模块,flannel默认使用的后端也进化为vxlan,再启用直接路由特性后也会有着相当不错的性能表现。另外,除了这三种后端模式之外,flannel还实验性的支持IPIP、IPSec、AliVPC、AWS VPC、Alloc和GCE几种后端
- 为了跟踪各子网分配信息等,flannel使用etcd来存储虚拟IP和主机IP之间的映射,每个节点上运行的flanneld守护进程负责监视etcd中的信息并完成报文路由。默认情况下,flannel的配置信息保存在etcd存储系统的键名
/coreos.com/network/config之下,我们可以使用etcd服务的客户端工具来设定或者修改其可用的相关配置。config的值是一个json格式的字典数据结构,它可以使用的键包含如下几个- Network: flannel在全局使用CIDR格式的IPV4网络,字符串格式,此为必选键,余下的均为可选
- SubnetLen:为全局使用的IPV4网络基于多少位的掩码切割供节点使用的子网,在全局网络的掩码小于24时默认为24位
- SubnetMin: 分配给节点使用的起始子网,默认为切分完成后的第一个子网;字符串格式
- SubnetMax: 分配给节点使用的最大子网,默认为切分完成后的最大一个子网;字符串格式
- Backend:Flannel要使用的后端类型,以及后端相关的配置,字典格式;不同的后端通常会有专用的配置参数
- flannel项目官方给出的在线配置清单中默认使用的vxlan后端,相关的配置定义在kube-system名称空间ConfigMap资源kube-flannel-cfg中,配置内容如下所示
cni-conf.json:
----
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json:
----
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
- 上面的实例可以看出,flannel预留使用的默认网络为10.244.0.0/16,默认使用24位长度的子网掩码为各节点分配切分的子网,因而,它将有10.244.0.0/24~10.244.255.0/24范围内的256个子网可用,每个节点最多支持位254个Pod对象各分配一个IP地址。它使用的后端是vxlan类型,flanneld将监听UPD的8472端口
VXLAN后端
- flannel会在集群中每个运行flanneld的节点之上创建一个名为flannel.1的虚拟网桥作为本节点隧道入口的VTEP设备,其中的1表示VNI,因而所有节点上的VTEP均属于同一VXLAN,或者属于同一个大二层域(BD),它们依赖于二层网关进行通信。flannel采用了分布式的网关模型,它把每个节点都视为到达该节点Pod子网的二层网关,相应的路由信息由flanneld自动生成
- flannel需要在每个节点运行一个flanneld守护进程,启动时,该进程从etcd加载json格式的网络配置等信息,它会基于网络配置获取用于当前节点的子网租约,还要根据其他节点的租约生成路由信息,以正确的路由数据报文等。与kubernetes结合使用时,flanneld也可托管给集群之上的Daemonset控制器。flannel项目仓库中的在线配置清单通过名为kube-flannel-ds的DaemonSet控制器资源在每个节点运行一个flannel相关的Pod对象,Pod模板中使用
hostNetwork:true进行网络配置,让每个节点上的Pod资源直接共享节点的网络名称空间,因而配置结果直接在节点的根网络名称空间生效 - 在VXLAN模式下,flanneld从etcd获取子网并配置了后端之后会生成一个环境变量文件(默认为/run/flannel/subnet.env),其中包含本节点使用的子网,以及为了承载隧道报文而设置的MTU的定义等。如下面的配置示例所示。随后,flanneld海将持续监视etcd中相应配置租约信息的变动,并实时反映到本地路由信息之上
[root@kube-master-01 ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
[root@kube-master-01 ~]#
- 为了确保VXLAN机制通信过程的正确性,通常涉及VXLAN通信的IP报文一律不能分片,这就要求物理网络的链路层实现中必须提供足够大的MTU值,或修改各节点的MTU值以保证VXLAN报文的顺利传输,如上面配置示例中使用的1450字节。降低默认MTU值以及额外的头部开销,必然会影响到报文传输过程中的数据交换效率
- 之前我们使用kubeadm部署kubernetes集群之后,基于flannel项目的在线配置清单部署了默认的vxlan后端的flannel网络插件,因而之前的示例中的跨节点Pod都是基于overlay网络进行通信
- 下面的路由信息取自kube-node-01节点,它由该节点上的flanneld根据集群中各节点获得的子网信息生成
[root@kube-node-01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.18.8.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.3.0 10.244.3.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.4.0 10.244.4.0 255.255.255.0 UG 0 0 0 flannel.1
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.18.8.0 0.0.0.0 255.255.248.0 U 0 0 0 eth0
[root@kube-node-01 ~]#
- 这些路由条目反映了同节点Pod间通信时由CNI虚拟网桥转发,而跨节点Pod间通信时,报文将经由当前节点的flannel.1隧道入口转发,隧道出口由下一跳信息指定
- VXLAN网络将各VTEP设备作为同一个二层网络上的接口,这些接口设备组成一个虚拟的二层网络如上面的图形所示,Pod-1发往Pod-4的IP报文将在流经其所在节点的flannel.1接口时封装成数据帧,源MAC是node-01节点上的flannel.1接口的mac地址,而目标MAC则是node-02节点上的flannel.1接口的mac地址。但flannel并非依赖ARP进行MAC地址学习,而是由节点上的flanneld进程启动时将本地flannel.1接口IP与MAC地址的映射信息上报到etcd中,并由其他各节点上的flanneld来动态生成相应的解析记录,下面的解析记录取自node-01节点,它们分别指明了集群中的其他节点上的flannel.1接口各自对应的mac地址,PERMANENT属性表明这些记录均永久有效
[root@kube-node-01 ~]# ip neighbour show |awk '$3=="flannel.1"{print $0}'
10.244.4.0 dev flannel.1 lladdr ae:89:b5:c2:bc:d6 PERMANENT
10.244.1.0 dev flannel.1 lladdr 9a:39:8c:91:ae:64 PERMANENT
10.244.3.0 dev flannel.1 lladdr ae:6c:44:30:0d:40 PERMANENT
10.244.0.0 dev flannel.1 lladdr 62:17:d3:a1:d9:a8 PERMANENT
[root@kube-node-01 ~]#
VXLAN协议使用UDP报文封装隧道内层数据帧,Pod发出的报文经隧道入口flannel.1封装成数据帧,再由flanneld(客户端)进程封装成UDP报文,之后发往目标Pod对象所在节点的flanneld进程(服务端)。该UDP报文就是所谓的VXLAN隧道,它会在已经生成的帧报文之后再封装一组协议头部。如下图所示为VXLAN头部,外出UDP头部,外层IP头部和外层帧头部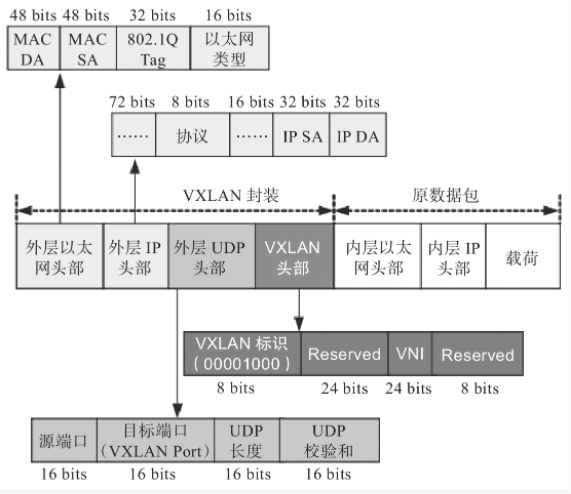
- 显然,该UDP报文的IP头部中,源地址为当前节点某接口的IP地址,目标地址应该为目标Pod所在节点的某接口IP地址。但本地节点上并没有任何路由信息帮助指向目标节点,由flanneld生成的路由中仅指明了到达目标Pod时的隧道出口的flannel.1接口的IP地址。事实上,flannel把flannel.1接口也作为网桥设备使用,该设备上附加了一个同样由flanneld维护的称为FDB(forwarding Database)的转发数据库。该数据库指明了到达目标节点flannel.1接口需要经由的下一跳IP,该IP是目标Pod所在节点的IP地址,即外部IP头部中的目标IP。下面的转发条目取自node-01节点,各条目的功能做了简单注释,这些条目分别指明了到达集群中不同的节点的flannel.1接口时需要经过的下一跳IP地址
[root@kube-node-01 ~]# bridge fdb show flannel.1 |awk '$3=="flannel.1"{print $0}'
9a:39:8c:91:ae:64 dev flannel.1 dst 172.18.14.239 self permanent
62:17:d3:a1:d9:a8 dev flannel.1 dst 172.18.14.244 self permanent
ae:6c:44:30:0d:40 dev flannel.1 dst 172.18.14.237 self permanent
ae:89:b5:c2:bc:d6 dev flannel.1 dst 172.18.14.238 self permanent
[root@kube-node-01 ~]#
- 这种外层封装后的报文就是常规的UDP报文,只是为了避免数据帧超过标准的MTU大小,内层数据帧不得不减小至1450字节。因此,VXLAN Overlay网络可正常运行在任何能够传输常规UDP报文的环境中,包括存在很多底层限制的公有云环境。代价是,牺牲了网络报文的一小部分载荷能力,降低了性能
- 依赖于flanneld维护的、由各VTEP设备flannel.1接口组成的二层网络中的各设备的ARP解析记录,flannel.1虚拟网桥上的FDB转发数据库,甚至不在同一IP网络中的集群各节点,只要它们彼此间经路由互相可达,这种外层转发依然能够成功达成。于是,VXLAN Overlay网络并不要求所有节点都处于一个二层网络,这有利于在更复杂的网络环境下组件kubernetes集群
- 另外,VXLAN后端的可用配置参数除了type之外还有如下几个,它们都有默认值,用户可以按需进行自定义配置
- VNI:VXLAN的标识符,默认为1;数值型数据
- Port:用于发送封装的报文的UDP端口,默认为8472;数值型数据
- GBP: 全称为Group Based Policy,配置是否启用VXLAN的基于组的策略机制,默认为否;布尔型数据
- DirectRouting:是否为同一个二层网络中的节点启用直接路由机制,类似于host-gw后端的功能;此种场景下,VXLAN仅为不在不同一个二层网络中的节点封装并转发vxlan隧道报文;布尔型数据
- 其中,直接路由参数能够配置flannel实现三层转发式的容器网关,该网关能够以直接路由方式在Pod间转发通信报文
直接路由
- 为了提升性能,flannel的VXLAN后端还支持DirecRouting模式,即在集群中的各节点上添加必要的路由信息,让Pod间的IP报文通过节点的二层楼直接传送,如下图所示。仅在通信双方的Pod对象所在的节点跨IP网络时,才启用传统的VXLAN隧道方式转发通信流量。若kubernetes集群节点全部位于单个二层网络中,则DirectRouting模式下的Pod间通信流量基本接近于直接使用二层网络。即便节点分布在有限的几个可互相通信的网络中的kubernetes集群来说,合理的应用部署拓扑也能省去相当一部分的隧道开销
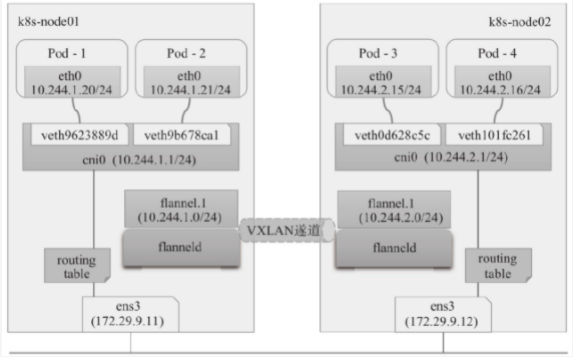
- 对于托管部署在kubernetes上的flannel来说,修改kube-system名称空间下的configmaps/kube-flannel-cfg资源,为VXLAN后端添加DirectRouting子健,并设置其值为true即可
net-conf.json:
----
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": "true"
}
}
- 我们可直接编辑活动状态的configmaps/kube-flannel-cfg资源,也可以基于配置清单修改后再次应用到集群上。修改完成后,还需要以某种策略让各节点上的flannel Pod重新生效配置。更新完成后,节点上的路由规则也会发生相应的变动,到达与本节点位于同一二层网络中的其他节点,Pod子网的下一跳地址由对端flannel.1接口地址变成了宿主机物理接口的地址,本地拥有发出报文的接口从flannel.1变成了本地的物理接口
- 值得注意的是,为了所有Pod均能得到正确的网络配置,建议在创建Pod资源之前事先配置好网络插件,甚至是事先了解并根据自身业务需求测试完成中意的目标网络插件,在选型完成后再部署kubernetes集群,而尽量避免中途修改,否则有些Pod资源可能需要重建
- 我们知道,Pod与节点通常不会在同一个网络。Pod间的通信需要经由宿主机的物理接口发出,必然会经过iptables/netfilter和forward钩子,为了避免该类通信被防火墙拦截,flannel必须为其设定必要的放行规则,所以集群中的每个节点上的iptables filter表中的forward链上都会生成两条规则,以确保由物理接口接收或发送的目标地址或源地址为10.244.0.0/16网络的所有通信能够正常通过
host-gw后端
- flannel的host-gw后端通过添加必要的路由信息,并使用节点的二层网络直接发送Pod间的通信报文,其工作杠十类似于VXLAN后端中的直接路由功能,但不包括该后端支持的隧道转发能力,这意味着host-gw后端要求各节点必须位于同一个二层网络中。其工作模型示意图如下。因完全不会用到VXLAN隧道,所以使用了host-gw后端的flannel网络也就无需用到VETP设备flannel.1
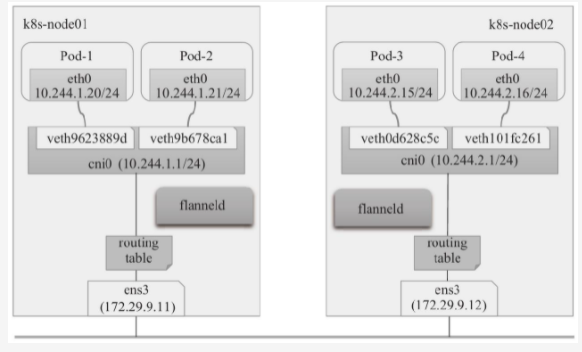
- host-gw后端没有多余的配置参数,直接设定配置文件中的backend.Type键的值为host-gw关键字即可。同样,直接修改kube-system名称空间中的configmaps/kube-flannel-cfg配置文件,类似下面示例中的内容即可
net-conf.json:
----
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
- 配置完成后,集群中的各节点会生成类似VXLAN后端的DirctRouting路由及iptables规则,以转发Pod网络的通信报文,它完全省去了隧道转发模式的额外开销。代价是,对于非同一个二层网络的报文转发,host-gw完全无能为力。相对而言,VXLAN的DirectRouting后端转发模式兼具VXLAN后端和host-gw后端的优势,即保证了传输性能,又具备跨二层网络报文转发能力
- 像host-gw或VXLAN后端的直接路由模式这种使用静态路由实现Pod间通信报文的转发,虽然较之VXLAN Overlay网络有着更低的资源开销和更好的性能表现,但是当kubernetes集群规模比较大的时候,其路由信息的规模也将变的庞大且不容易维护。相比较来说,Calico通过BGP协议自动维护路由条目,较之flannel以etcd为总线以上报、查询和更新配置的工作逻辑更加高效和易于维护,因而更适用于大型网络
- 此外,flannel自身并不具备为Pod网络实施网络策略以实现其网络通信控制的能力,它只能借助calico这类支持网络策略的插件实现该功能,独立的项目calico正为此目的而设立
Calico网络插件
- Calico是一款开源的虚拟化网络方案,用于为云原生应用实现互联与策略控制,可以整合进大多数主流的编排系统,例如Kubernetes,Apache Mesos、Docker和Openstack等。与flannel相比,Calico的一个显著优势是对网络策略的支持,它允许用户动态定义访问控制以管控进出容器的数据报文,从而为Pod间通信按需施加安全策略
- Calico是一个三层的虚拟网络解决方案,它把每个节点都当作虚拟路由器(vRouter),并把每个节点上的Pod都当作是”节点路由器”后的一个终端设备并为其分配一个IP地址。各节点路由器通过BGP协议学习生成路由规则,从而实现不同节点上的Pod间的互联互通。如下图

- BGP是互联网上一个核心的去中心化自治路由协议,它通过维护IP路由表或”前缀”表来实现自治系统(AS)之间的可到达性,通常作为大规模数据中心维护不同的自治系统之间路由信息的矢量路由协议。Linux原生支持BGP,因而我们可以轻易把一台Linux主机配置成边界网关
- Calico把kubernetes集群环境中的每个节点上的Pod所组成的网络视为一个自治系统,而每个节点也就自然由各自的Pod对象组成虚拟网络,进而形成自治系统的边界网关。各节点间通过BGP协议交换路由信息并生成路由规则。但考虑到并非所有网络都支持BGP,而且BGP路由模型要求所有节点必须要位于同一个二层网络,所以calico还支持基于IPIP和VXLAN的Overlay网络模型,它们的工作模式与flannel的VXLAN和IPIP模型并无显著不同
- 类似Flannel在VXLAN后端启用DirectRouting时的网络模型,Calico也支持混合使用路由和Overlay网络模型,BGP路由模型用于二层网络的高性能通信,IPIP或VXLAN用于跨子网的节点间报文转发
- 需要注意的是,Calico网络提供的在线部署清单中默认使用的是IPIP隧道网络,而非BGP或者混合模型,因为它假设节点的底层网络不支持BGP协议。明确需要使用BGP或混合模型时,需要事先将清单下载至本地,按需修改后方可部署在kubernetes集群中
Calico架构
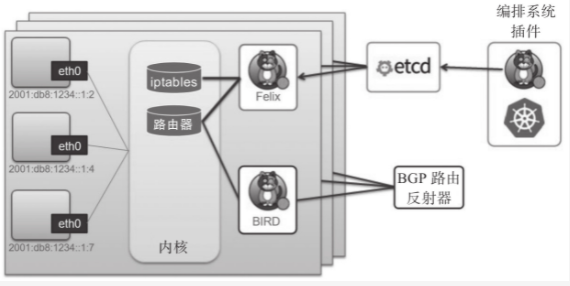
- Calico的系统组件主要有Felix、BGP路由反射器、编排系统插件、BIRD和etcd存储等,各组件的关系如下图
- 如前所述,BGP模式下的Calico所承载的各Pod资源直接基于vrouter经由基础网络进行互联,它非叠加、无隧道、不适用VRF表,也不依赖于NAT,因此每个工作负载都可以直接配置使用公网IP接入互联网,当然,也可以按需使用网络策略控制它的网络连通性
- Felix:Felix是运行于各节点上守护进程,它主要负责完成接口管理、路由规划、ACL规划和状态报告几个核心任务、从而为各端点(VM或container)生成连接机制
- 接口管理,负责创建网络接口、生成必要信息并发往内核,以确保内核能够正确处理各端点的流量,尤其是要确保目标节点MAC能响应当前节点上各工作负载的MAC地址的ARP请求,以及为Felix管理的接口打开转发功能。另外,接口管理还要监控各监控的变动以确保规则能够得到正确应用
- 路由规划,负责为当前节点上允许的各端点在内核FIB(Forwarding Information Base)中生成路由信息,以保证到达当前节点的报文可以正确的转发给端点
- ACL规划,负责在Linux内核中生成ACL,实现仅放行端点间的合规流量,并确保流量不能绕过Calico等安全措施
- 状态报告,负责提供网络健康状态的相关数据,尤其是报告由Felix管理的节点上的错误和问题。这些报告数据会存储在etcd,供其他组件或网络管理员使用
- 编排系统插件:编排系统插件的主要功能是将calico整合进所在的编排系统中,例如kubernetes或openstack等。它主要负责完成API转换,从而让管理员和用户能够无差别的使用calico的网络功能。换句话说,编排系统通常有自己的网络管理API,相应的插件要负责将对这些API调用转换成calico的数据模型,并存储到calico的存储系统中。因而,编排插件的具体实现依赖于底层编排系统,不同的编排系统有各自专用的插件
- etcd存储系统:利用etcd,Calico网络可实现为有明确状态(正常或故障)的系统,且易于通过扩展应对访问压力的提升,避免自身称为系统瓶颈。另外,etcd也是calico各组件的通信总线
- BGP客户端:Calico要求在每个运行着felix的节点上同时运行一个称为BIRD的守护进程,它是BGP协议的客户端,负责将felix生成的路由信息载入内核并通告给整个网络中
- BGP路由反射器:Calico在每一个计算节点利用Linux内核实现了一个高效的vrouter(虚拟路由器)进行报文转发。每个vrouter通过BGP协议将自身所属节点运行的Pod资源的IP地址信息,基于节点上的专用代理程序(felix)生成路由规则向整个calico网络内传播。尽管小规模部署能够直接使用BGP网格模型,但随着节点数量的增加,这些连接的数量就会以N倍的规模快速增长,从而给集群网络带来巨大的压力。因此,一般建议大规模的节点网络使用BGP路由反射器进行路由学习,处于冗余考虑,生产实践中应该部署多个BGP路由器反射器。而对于calico来说,BGP客户端程序除了作为客户端使用外,也可以配置为路由反射器
- Felix:Felix是运行于各节点上守护进程,它主要负责完成接口管理、路由规划、ACL规划和状态报告几个核心任务、从而为各端点(VM或container)生成连接机制
- 另外,Calico可将关键配置抽象成资源类型,并允许用户按需定义资源对象以完成系统配置,这些资源对象保存在datastore中,datastore可以是独立管理的etcd存储系统,也可以是kubernetes API封装的集群状态存储系统。calico专有的资源类型有十几种,包括IPPool(IP地址池)、NetworkPolicy(网络策略)、BGPConfiguretion(BGP配置参数)和FelixConfiguration(Felix配置参数)等。类似于kubernetes API资源的定义,这些资源的配置格式同样以json使用apiVersion、kind、metadata和spec等一级字段进行定义,并能够使用calicoctl客户端工具进行管理,也支持由kubelet借助CRD进行这类资源的管理
- 提示:以kubernetes API为datastore的部署场景中,calico还需要将这些资源类型相应定义为kubernetes的CRD
calico配置基础
- 与kubernetes集群整合时,Calico需要配置calico-node和calico-kube-controllers两个重要组件,各组件通过datastore读取与自身相关的资源定义完成配置。如下图所示
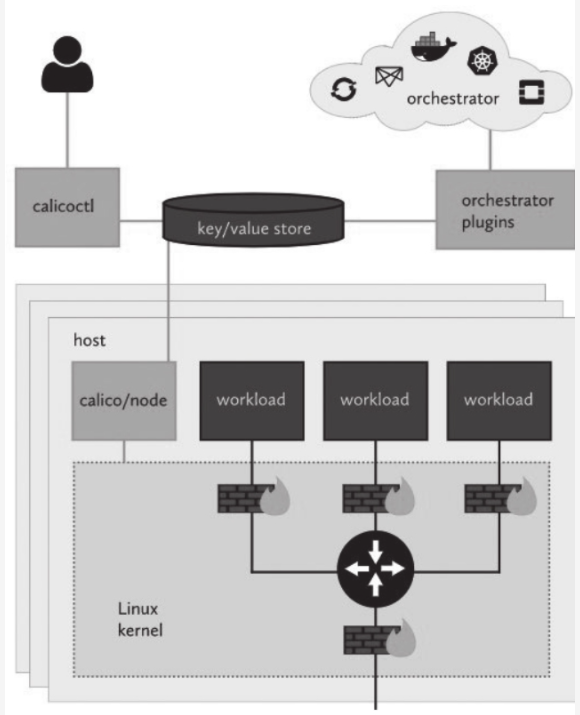
- calico/node: calico在kubernetes集群每个节点运行的节点代理,负责提供felix、bird4、bird6和confd等守护进程
- calico/kube-controllers:calico运行在kubernetes之上的自定义控制器,也是calico协同kubernetes的插件。
- calico有两种部署方式:一种是让calico/node独立运行在kubernetes集群之外,但calico/kube-controllers依然需要以Pod资源形式运行在集群之上;另外一种是以CNI插件方式配置calico,使calico完全托管运行在kubernetes集群之上,类似于前面曾经部署托管flannel网络插件的方式。对于后一种方式,calico提供了在线的部署清单,它分别为50节点及以下规模和50节点以上规模的kubernetes集群使用kubernetes API作为datastore提供了不同的配置清单,也为使用独立的etcd集群提供了专用配置清单。但这三种类型的配置清单种,Calico默认启用的是基于IPIP隧道的overlay网络,因而它会在流量上使用IPIP隧道而不是BGP路由。以下配置定义在部署清单中DaemonSet/calico-node资源的Pod模板中的calico-node容器之上
#设置再IPV4类型的地址池上启用的IP-IP及其类型,支持三种可用值
#Always(全局流量)
#Cross-SubNet(跨子网流量)
#Never
- name: CALICO_IPV4POOL_IPIP
value: "Always
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
# 是否在IPV4地址池上启用VXLAN隧道协议,取值及意义与flannel的VXLAN后端相同
# 但在全局流量启用VXLAN时将完全不再需要BGP网络,建议将相关的组件禁用
- 我们可以将环境变量CALICO_IPV4POOL_IPIP的值设置为Cross-SubNet(不区分大小写)来启用缓和网络模型,它将启用BGP路由网络,且仅会在跨节点子网的流量间启用隧道封装。想要启用VXLAN隧道,只需要把环境变量CALICO_IPV4POOL_VXLAN的值设置为Always或Corss-SubNet即可,但在全局流量上使用VXLAN隧道时建议将ConfigMap/Calico-node中calico-backend键的值设置为vxlan以禁用BIRD,并在DaemonSet/calico-node资源的Pod模型中禁用calico-node容器的存货探针和就绪探针对bird的检测,相关的配置要点如下
livenessProbe:
exec:
command:
- /bin/calico-node
- -felix-live
# - -bird-live
periodSeconds: 10
initialDelaySeconds: 10
failureThreshold: 6
timeoutSeconds: 10
readinessProbe:
exec:
command:
- /bin/calico-node
- -felix-ready
# - -bird-ready
periodSeconds: 10
timeoutSeconds: 10
- 需要注意的是,calico分配的地址池需要与kubernetes集群的Pod网络的定义保持一致。Pod网络通常由kubeadmin init初始化集群时使用—pod-network-cidr选项指定的,而calico在其默认的配置清单中默认使用192.168.0.0/16作为Pod网络,因而部署kubernetes集群时应该规划好要使用的网络地址,并设定此二者相匹配。对使用了flannel的10.244.0.0/16网络环境而言,可以修改资源清单中的定义,从而将其修改为其他网络地址。以下配置片段取自calico的部署清单,它定义在DaemonSet/calico-node资源的Pod模板中的calico-node容器之上
#IPV4地址池的定义,value值需要与kube-controller-manager的--cluster-network选项的值保持一致,以下环境变量默认处于注释状态
- name: CALICO_IPV4POOL_CIDR
value: "192.168.0.0/16"
#Calico默认以26位子网掩码切分地址池并将各子网配置给集群中的节点,若需要使用其他长度的掩码,则需要定义如下变量
- name: CALICO_IPV4POOL_BLOCK_SIZE
value: 24
#calico默认并不会从Node.Spec.PodCIDR中分配地址,但可通过将如下变量设置位true并结合host-local这一IPAM插件来强制从PodCIDR中分配地址
- name: USE_POD_CIDR
value: "false"
- 不过,目前版本的calico已经能够自动检测由kubeadm部署的kubernetes集群中的Pod网络,并自动将类似上面配置清单中CALICO_IPV4POOL_CIDR和CALICO_IPV4POOL_BLOCK_SIZE环境变量的值适配到该Pod网络,但是其他方式部署的kubernetes集群依然需要管理员自行检验这种适配机制是否能够满足需求
- 在地址分配方面,Calico在JSON格式的CNI插件配置文件中使用专有的calico-ipam插件,该插件并不会使用Node.Spec.PodCIDR中定义的子网作为本节点本地为Pod分配地址的地址池,而是根据Calico插件为各节点配置的地址池进行地址分配。若期望为节点真正使用地址池,吻合PodCIDR的定义,则需要将部署清单中DaemonSet/calico-node资源的Pod模板的calico-node容器的USE_POD_CIDR环境变量值设置为true,并修改ConfigMap/calico-config资源中cni_network_config键的plugins.ipam.type值为host-local,且使用podCIDR为子网,具体配置如下
"ipam": {
"type": "host-local"
"subnet": "usePodCidr"
},
IPIP隧道网络
- kubenet通过/etc/cni/net.d目录下的CNI配置文件加载要使用的网络插件来完成Pod网络配置,为了避免冲突,通常不应该也没必要同时提供多个CNI解决方案。因此,在部署calico之前,需要先移除此前使用的flannel插件,最便捷的方式是基于部署清单完成。
[root@kube-master-01 kubernetes]# kubectl delete -f kube-flannel.yml
- Calico3目前仅支持kubernetes1.8及其以上版本,并且它要求使用一个能够被各组件访问的键值存储系统,在kubernetes环境中,可以用的选择有etcd v3或kubernetes API数据存储。本次部署会使用kubernetes API作为calico的数据存储取代etcd,这也是最新稳定版calico 3中的推荐配置。若无需改动默认配置,则直接使用在线资源清单创建相关资源即可。这里我们为了吻合之前flannel的配置,需要自动设置Pod网络为10.244.0.0/16,切分子网时的掩码长度为24,并设置PodCIDR中为工作负载分配IP地址,但在全局流量上默认使用的网络模型是IPIP隧道,首先我们将资源清单下载至本地
curl https://docs.projectcalico.org/manifests/calico.yaml -O
- 提示,使用host-local IPAM插件时,Calico的部分功能将变的不可用。例如,以节点或名称空间为组,分别从不同地址池分配IP地址等
- 而后修改calico.yml文件,修改资源定义使得其符合flannel的使用习惯,具体设置方法可以参考前面的章节。配置完成后,使用如下命令将资源部署到集群之上即可
- 默认情况下,calico使用的镜像会从国外的站点进行下载,有些时候速度会特别慢,我们可以手动找一台比较快的机器将其下载到本地,上传到自己的镜像服务器,之后修改部署配置清单里面的镜像地址即可
[root@jenkins calico]# kubectl apply -f calico.yaml
- 该资源清单将calico的所有资源部署在kube-system名称空间之中,待calico-node与kube-controllers相关的Pod进入就绪状态之后即可验证和使用相应的网络功能
[root@jenkins calico]# kubectl get pods -n kube-system -o wide|awk '/^calico-(node|kube-controllers)/{print}'
calico-kube-controllers-6bcbb59b79-gbf4n 1/1 Running 0 6m38s 10.244.10.65 kube-node-01 <none> <none>
calico-node-brxjq 1/1 Running 0 6m37s 172.18.14.240 kube-node-01 <none> <none>
calico-node-btsbh 1/1 Running 0 6m37s 172.18.14.239 kube-node-02 <none> <none>
calico-node-dt76w 1/1 Running 0 6m38s 172.18.14.244 kube-master-01 <none> <none>
calico-node-k7777 1/1 Running 0 6m36s 172.18.14.237 kube-node-04 <none> <none>
calico-node-rhr7l 1/1 Running 0 6m36s 172.18.14.238 kube-node-03 <none> <none>
[root@jenkins calico]#
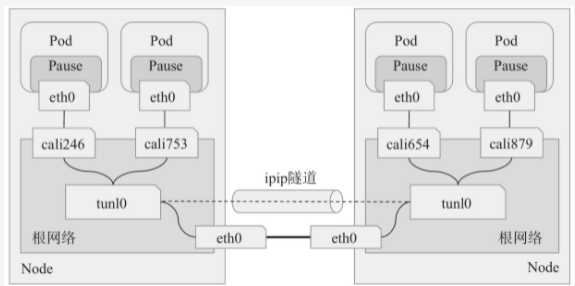
- 工作在IPIP模式下的Calico会在每个节点上创建一个tunl0接口作为隧道出入口来封装IPIP隧道报文。calico会为每一个Pod资源创建一对veth设备,其中一端作为Pod的网络接口,另一端(名称为cali为强追,后跟随机子串)留置在节点的根网络名称空间,它未使用风格模式,因而并未关联成为任何虚拟网桥设备的从接口。如下图所示
- ipip隧道网络仍需依赖于BGP维护节点间的可达性。部署完成后,Calico会通过BGP协议在每个节点上生成到达kubernetes集群中其它各节点的Pod子网路由信息。下面的路由条目截取自node-01主机,它们是各节点上的BIRD以点对点的方式(node-to-node mesh)向网络中的其他节点进行通告并学习其他节点的通告而得
[root@kube-node-01 ~]# ip route
default via 172.18.8.1 dev eth0
blackhole 10.244.10.64/26 proto bird
10.244.10.65 dev calicabfd016e11 scope link
10.244.10.66 dev cali206b7dc841d scope link
10.244.10.73 dev calif7c7bbacc1d scope link
10.244.10.74 dev cali629b8c67f54 scope link
10.244.10.76 dev calia8562f237aa scope link
10.244.10.77 dev cali2164f8cb049 scope link
10.244.15.192/26 via 172.18.14.237 dev tunl0 proto bird onlink
10.244.49.192/26 via 172.18.14.238 dev tunl0 proto bird onlink
10.244.201.64/26 via 172.18.14.244 dev tunl0 proto bird onlink
10.244.236.64/26 via 172.18.14.239 dev tunl0 proto bird onlink
169.254.0.0/16 dev eth0 scope link metric 1002
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.8.0/21 dev eth0 proto kernel scope link src 172.18.14.240
[root@kube-node-01 ~]#
- 对于创建的每个常规Pod资源,Calico CNI插件需要在节点的根网络名称空间中生成一个专用路由条目,用于确保以Pod IP为目标地址的报文能够经由相应的留置在根网络名称空间中的一端设备送达,相关的路由条目格式类似如下所示。这是因为calico没有在节点上为本地的所有Pod资源使用一个虚拟网桥进行报文转发所致。
[root@jenkins calico]# kubectl get pods -o wide -A
...
...
kubesphere-system ks-apiserver-b8cf7479c-bzp7l 1/1 Running 0 17m 10.244.10.66 kube-node-01 <none> <none>
...
...
# 在node01节点上查看相关的信息
[root@kube-node-01 ~]# ip route
...
...
# 到达10.244.10.66的报文经由cali206b7dc841d接口送达
10.244.10.66 dev cali206b7dc841d scope link
...
...
[root@kube-node-01 ~]#
# 查看kube-node-01上面是否存在这个接口
[root@kube-node-01 ~]# ifconfig
...
...
cali206b7dc841d: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1480
inet6 fe80::ecee:eeff:feee:eeee prefixlen 64 scopeid 0x20<link>
ether ee:ee:ee:ee:ee:ee txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
...
...
- 在集群中可以尝试部署一些Pod资源完成集群网络连接测试。然后使用tcpdump进行抓包通信报文也可以分析IPIP隧道报文通信格式。需要注意的是,Calico CNI设置的tunl0接口的MTU默认为1440,这种设置主要是为适配Google的GCE环境,非GCE的物理环境中,其最佳值为1480。部署前,修改配置清单中
configmap/ccalico-config资源的veith_mtu的值为1480即可 - 另外,对于50各节点以上规模的集群来说,所有calico节点基于kubernetes API存储数据会给API Server带去不小的通信压力,解决办法是使用calico-typha进程将所有calico的通信集中起来,统一与API Server进行交互。calico为该应用场景提供了专用的在线配置清单
[https://docs.projectcalico.org/manifests/calico-typha.yaml](https://docs.projectcalico.org/manifests/calico-typha.yaml),它主要添加了Deployment/calico-typha和Service/calico-typha两个资源。需要自定义的话,基本评估标准是每个calico-typha Pod资源可承载100 ~ 200个(上限)Calico Node的连接请求,而整个集群中的calico-typha Pod资源总数尽量不要超过20个
客户端工具calicoctl
- Calico项目提供的专用客户端工具calicoctl能够直接与calico DataStore进行交互,用于管理calico系统抽象出的各种资源,通过资源管理实现查看、修改或配置calico系统特性。我们可以基于特定的Pod来提供calicoctl工具程序,也可以直接将相关的二进制程序部署在管理节点之上,例如管理员运行kubectl工具的主机等。我们直接在管理节点上下载官方提供的编译好的calicoctl文件,并将其保存在/usr/bin目录下面
- 需要注意的是,calico和calicoctl的版本应该相同
[root@jenkins calico]# wget https://github.com/projectcalico/calicoctl/releases/download/v3.21.0/calicoctl
[root@jenkins calico]# chmod a+x calicoctl
[root@jenkins calico]# mv calicoctl /usr/bin/
[root@jenkins calico]#
- Calico成功认证到Calico的数据存储系统(Datastore)上之后才能查看或进行各类管理操作,所需要的认证方式也就取决于Datastore的类型。以kubernetes API为数据存储时,calicoctl需要使用类似kubectl的认证信息完成认证,常用的实现方式有环境变量和配置文件两种。环境变量
DATASTORE_TYPE用于指定存储类型,而KUBECONFIG则用于指定配置文件kubeconfig的认证文件路径,例如下面命令格式运行calicoctl命令,测试读取calico系统的节点信息 - 在多集群环境中,如果你的kubeconfig具有多个集群上下文的文件,可以使用 calicoctl —context参数直接更改上下文。
[root@jenkins ~]# DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes -o wide
NAME ASN IPV4 IPV6
kube-master-01 (64512) 172.18.14.244/21
kube-node-01 (64512) 172.18.14.240/21
kube-node-02 (64512) 172.18.14.239/21
kube-node-03 (64512) 172.18.14.238/21
kube-node-04 (64512) 172.18.14.237/21
[root@jenkins ~]#
[root@jenkins ~]#
- 为了更方便的使用,我们也可以直接将认证信息等保存在配置文件中,calico默认加载的配置文件是
/etc/calico/calicoctl.cfg,配置信息以yaml格式进程组织,语法格式类似于kubernetes的资源配置清单
[root@jenkins ~]# mkdir -pv /etc/calico/
mkdir: created directory ‘/etc/calico/’
[root@jenkins ~]# cd /etc/calico/
[root@jenkins calico]# vim calicoctl.cfg
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "kubernetes"
kubeconfig: "~/.kube/config"
- kubeconfig除了默认的配置之外,也可以是用户自定义其他的kubeconfig配置文件的存放路径
- calicoctl 的通用语法格式是
calicoctl [options] <command> [<args>...]。它支持apply、delete、get、patch、replace、node和ipam等子命令,用别用于增、删、改、查相应的资源配置会打印相关状态信息等 - 例如下面的命令列出datastore中所有的ipPool资源对象。ippool是常用的资源类型之一,它代表当前calico系统可用的地址池资源。默认部署生成的地址池资源名称为default-ipv4-ippool
[root@jenkins ~]# calicoctl get ipPool
NAME CIDR SELECTOR
default-ipv4-ippool 10.244.0.0/16 all()
[root@jenkins ~]
- calicoctl同样支持资源的多种输出格式,例如yaml、json、wide、go-template喝custom-columns等,其功能完全类似kubectl中的用法。例如,下面的命令以yaml格式输出了默认地址池的详细定义
[root@jenkins ~]# calicoctl get ipPool default-ipv4-ippool -o yaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
creationTimestamp: "2021-11-11T07:36:20Z"
name: default-ipv4-ippool
resourceVersion: "25397587"
uid: e964e45a-7341-4526-baae-c836f6b23474
spec:
allowedUses:
- Workload
- Tunnel
blockSize: 26
cidr: 10.244.0.0/16
ipipMode: Always
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
[root@jenkins ~]#
- 我们可以将上面命令输出的结果保存于本地文件中,修改其特定属性值后,再重新应用(apply)到datastore从而完成配置更新,例如添加
disabled: true以禁用指定的地址池等;也可同时修改资源名称和特定属性值后再应用到datastore上创建新的资源 - 再如,下面的命令打印了地址池中相关地址块与IP地址的分配状态,包括地址池及各地址块中的IP总数、已分配数量和可用数量等
[root@jenkins ~]# calicoctl ipam show --show-blocks
+----------+------------------+-----------+------------+--------------+
| GROUPING | CIDR | IPS TOTAL | IPS IN USE | IPS FREE |
+----------+------------------+-----------+------------+--------------+
| IP Pool | 10.244.0.0/16 | 65536 | 28 (0%) | 65508 (100%) |
| Block | 10.244.10.64/26 | 64 | 11 (17%) | 53 (83%) |
| Block | 10.244.15.192/26 | 64 | 5 (8%) | 59 (92%) |
| Block | 10.244.201.64/26 | 64 | 2 (3%) | 62 (97%) |
| Block | 10.244.236.64/26 | 64 | 5 (8%) | 59 (92%) |
| Block | 10.244.49.192/26 | 64 | 5 (8%) | 59 (92%) |
+----------+------------------+-----------+------------+--------------+
[root@jenkins ~]#
- 另外,直接以etcd为datastore的场景中,calicoctl则要使用由etcd信任的ca所签发的数字证书认证到etcd,主流的配置方式同样有环境变量和配置文件两种。无论使用哪种datastore,calictoctl可执行的管理操作及相关命令的用法并无不同之处
BGP网络与BGP Reflector
- 一般来说,仅在那些不支持用户自定义BGP配置的网络中才会完成使用IPIP或VXLAN隧道网络,对于自主可控规模较大的网络环境,非常有必要启用BGP降低网络开销以提升传输性能。对于calico来说,修改ipPool属性相应的配置便可调整使用的网络类型。以此前部署的calico系统默认使用的地址池default-ipv4-ippool为例,获取该资源的配置清单并保存为本地文件,修改ipipMode(或vxlanMode)的属性值为CrossSubnet或Never边能启用直接路由网络
- 下面的配置清单示例(default-ipv4-ippool.yaml)将
spec.ipipMode的属性值从Never修改为CrossSubnet。表示仅在跨IP网络节点上的Pod间通信才使用IPIP隧道,同一网络节点上的Pod间通信则使用路由方式进行
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 10.244.0.0/16
ipipMode: CrossSubnet
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
- 将上面的配置清单使用
calicoctl apply -f default-ipv4-ippool.yaml命令重新应用到calico datastore上之后便可立即生效。但是,这种变动会影响现有的通信流量,不建议在生成环境中随意变动
[root@jenkins calico]# calicoctl apply -f default-ipv4-ippool.yaml
Successfully applied 1 'IPPool' resource(s)
[root@jenkins calico]#
- 应用完成之后,随后,等BGP信息传播完成后,节点将同一网络内其他节点相关的条目经由IPIP模型的tunl0接口传输,变为节点上的某物理接口,如eth0等。下面的路由信息片段截取自node01节点主机之上
[root@kube-node-01 ~]# ip route
default via 172.18.8.1 dev eth0
blackhole 10.244.10.64/26 proto bird
10.244.10.77 dev cali2164f8cb049 scope link
10.244.10.78 dev cali629b8c67f54 scope link
10.244.10.79 dev calif7c7bbacc1d scope link
10.244.10.80 dev calia8562f237aa scope link
10.244.15.192/26 via 172.18.14.237 dev eth0 proto bird
10.244.49.192/26 via 172.18.14.238 dev eth0 proto bird
10.244.201.64/26 via 172.18.14.244 dev eth0 proto bird
10.244.236.64/26 via 172.18.14.239 dev eth0 proto bird
169.254.0.0/16 dev eth0 scope link metric 1002
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.8.0/21 dev eth0 proto kernel scope link src 172.18.14.240
[root@kube-node-01 ~]#
- 随后,可以在集群上部署一些Pod资源,然后使用tcpdump在节点主机的物理接口上进行抓包,通过分析抓包的流量报文可以显示出Pod之间直接基于底层网络完成了彼此间的通信
- 默认情况下,Calico的BGP网络工作在节点网格(node-to-node mesh)模型下,各节点间以对等方式广播路由,它仅适用于规模较小的集群环境。下面命令的结果显示的是便是当前节点要对等广播路由的其他节点,各节点打印的结果都会有所不同。随着节点数量的增多,这种对等广播的规模将以指数级别上升。
- 以下命令需要在calico节点上运行
[root@kube-master-01 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 172.18.14.240 | node-to-node mesh | up | 01:27:57 | Established |
| 172.18.14.239 | node-to-node mesh | up | 09:10:41 | Established |
| 172.18.14.238 | node-to-node mesh | up | 09:10:35 | Established |
| 172.18.14.237 | node-to-node mesh | up | 09:10:35 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
[root@kube-master-01 ~]#
- 中级集群环境应该使用全局对等BGP(global BGP peers)模型,通过在同一个二层网络中使用一个或一组BGP反射器构建BGP网络环境,大型集群环境甚至可以使用每节点对等BGP模型(per-node BGP peers),即分布式BGP反射器模型。calico的节点代理calico/node自身就能够充当BGP路由反射器,我们可以在kubernetes集群外部的专用主机上部署calico/node作为路由反射器,也可以在集群中选择专用的几个节点进行配置
- calico集群中的所有节点默认情况下都会相互建立连接,用于路由交互
[root@kube-master-01 ~]# ss -tan | grep 179
LISTEN 0 8 *:179 *:*
ESTAB 0 0 172.18.14.244:56874 172.18.14.240:179
ESTAB 0 0 172.18.14.244:37946 172.18.14.237:179
ESTAB 0 0 172.18.14.244:33336 172.18.14.238:179
ESTAB 0 0 172.18.14.244:43605 172.18.14.239:179
ESTAB 0 0 ::ffff:172.18.14.244:6443 ::ffff:172.18.14.240:17179
[root@kube-master-01 ~]#
- 通过上面的命令结果可以看到与
calico node status显示的结果是一样的,而其他节点也是同样的,这种情况下,如果节点数量越来越来越多,网络中的连接数就成倍的增加。而在100个节点左右就会遇到瓶颈麻烦。解决办法就是上面所说的把集群里面其中的节点当作路由反射器,然后其他节点只需要把这几个节点当作对等体建立连接即可。路由反射器会把传递过来的路由,再传递给其他节点来实现路由交互 以下是一个配置路由反射器的示例,出于测试目的,将集群的mster节点部署为集群中的路由反射器,来说明配置过程。通常来说,配置集群节点称为路由反射器大致有三个步骤:配置选定的Node作为BGP路由反射器、配置所有节点作为BGP对等节点(BGPPeer)向路由反射器发送路由信息,以及禁用节点网格
配置路由反射器
获取节点的ASN号
[root@jenkins ~]# calicoctl get nodes --output=wide
NAME ASN IPV4 IPV6
kube-master-01 (64512) 172.18.14.244/21
kube-node-01 (64512) 172.18.14.240/21
kube-node-02 (64512) 172.18.14.239/21
kube-node-03 (64512) 172.18.14.238/21
kube-node-04 (64512) 172.18.14.237/21
[root@jenkins ~]#
- 下面的配置清单示例(reflector-node.yaml)定义calico Node资源对象kube-master-01成为路由反射器,其中的
spec.bgp.routeReflectorClusterID字段以IP地址格式的值为BGP路由器集群提供标识符,而特地添加的route-reflector标签则于配置BGPPeer时筛选节点 - 清单编写完成之后将其应用到datastore之上
calicoctl apply -f reflector-node.yaml
apiVersion: projectcalico.org/v3
kind: Node
metadata:
labels:
route-reflector: true
name: kube-master-01
spec:
bgp:
asNumber: "64512"
ipv4Address: "172.18.14.244/21"
ipv4IPIPTunnelAddr: "10.244.0.1"
routeReflectorClusterID: "172.18.14.244"
配置BGP对等节点(BGPPeer)
同一BGP路由器集群中的各节点都需要成为Reflector的BGP对等节点以交换路由信息。k8s-master-01自身同样运行于Pod资源,因而它自身同样需要成为Reflector的BGP对等节点。下面的配置清单(bgppeer-demo.yaml)定义集群所有节点同符合标签选择器
route-reflector="true"节点(路由反射器)进行对等- 清单完成之后使用
calicoctl apply -f bgppeer-demo.yaml将其应用到Datastore之上,相关的”对等”关系便立即生效
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: bgppeer-demo
spec:
nodeSelector: all()
peerSelector: route-reflector=="true"
- 新的BGPPeer资源定义了并非node-to-node的对等关系,因而在路由反射器节点和其他节点所看到的结果相差较大,因为路由反射器同集群中的所有节点对等。但其他节点仅会同路由反射器节点对等。下面的命令运行在路由反射器之上,它已然能够与集群中的节点建立对等关系(自我对等的关系不会显示在命令结果中)
[root@kube-master-01 calico]# calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+---------------+-------+----------+-------------+
| 172.18.14.237 | node specific | up | 03:10:27 | Established |
| 172.18.14.238 | node specific | up | 03:10:27 | Established |
| 172.18.14.239 | node specific | up | 03:10:27 | Established |
| 172.18.14.240 | node specific | up | 03:10:27 | Established |
+---------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
[root@kube-master-01 calico]#
其中,输出结果中的PEER TYPE显示了对等通信的类型,常见的值有
node-to-node mesh,node specific,global等,node specific表示与特定的节点对等,而省略node和nodeSelector字段时出现的global则表述全局对等禁用节点网搁
下面的资源清单(default-bgpconfiguration.yaml)定义的BGPConfiguration/default资源是用于禁用这种BGP网格
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false
asNumber: 64512
[root@kube-master-01 calico]# calicoctl apply -f default-bgpconfiguration.yaml
Successfully applied 1 'BGPConfiguration' resource(s)
[root@kube-master-01 calico]#
[root@kube-master-01 calico]# calicoctl get bgpconfig
NAME LOGSEVERITY MESHENABLED ASNUMBER
default Info false 64512
[root@kube-master-01 calico]#
- 需要特别说明的是,禁用BGP网格的配置参数
nodeToNodeMeshEnabled,以及BGP会话中使用的默认AS号码仅能够定义在名为default的全局BGPConfiguration资源中 - 资源创建完成之后,随后,由BGPPeer/bgppeer-demo资源定义的各calico/node与BGP路由反射器对等关系便会生效。去他路由反射器,只需要添加
route-reflector标签就可以了
网络策略
- 网络策略是控制Pod资源组间以及与其他网络端点间如何进行通信的规范,它使用标签来分组Pod,并在该组Pod上定义规则来管控其流量,从而为kubernetes提供更为精细的流量控制以及租户隔离机制。NetworkPolicy资源是kubernetes API的一等公民,管理员或用户可使用NetworkPolicy这一标准资源类型按需定义网络访问控制策略
网络策略与配置基础
- kubernetes自身仅实现了NetworkPolicy API的规范,具体的策略实施要靠CNI网络插件来完成,例如,calico、antrea、canal和weave等,但flannel不支持。因而,仅在使用支持网络策略功能的网络插件时才能够生效自定义策略。实现了NetworkPolicy API的各网络插件都有其特定的策略实现方式,它们或依赖节点自身的某个组件,或借助Hypervisor的特性,也可能是网络自身的功能
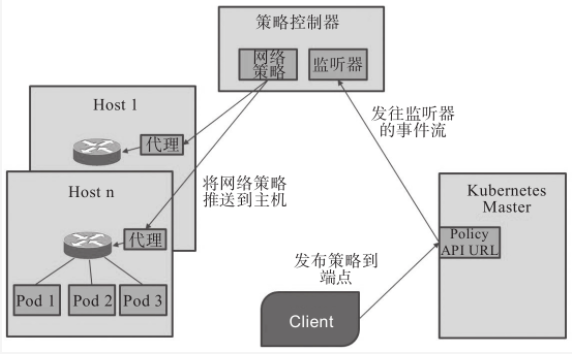
- calico的calico/kube-controllers是该项目中用于将用户定义的网络策略予以实现的组件,它主要依赖于在节点上构建iptables规则实现访问控制功能,如下图所示。其他支持网络策略的插件也有类似的将网络加以实现的”策略控制器”或”策略引擎”,它们通过API监听创建Pod时生成的新端点,并负责按需为其附加相关的网络策略
- 我们知道,kubernetes默认并未对Pod之上的流量作任何限制,Pod对象能够与集群上的其他任何Pod通信,也能够与集群外部的网络端点交互。NetworkPolicy是名称空间级别的资源,允许用户使用标签选择在筛选出的一组Pod对象上分别管理ingress和Egress流量。一旦将NetworkPolicy引入到名称空间中,则被标签选择器”选中”的Pod将被默认拒绝所有流量,而仅放行由特定的NetworkPolicy资源明确”允许”的流量。然而,未被任何NetworkPolicy资源的标签选择器选中的Pod对象的流量则不受影响
- 换句话说,NetworkPolicy就是定义在一组Pod资源上的Ingress规则或Egress规则,或二者的组合定义,具体生效的范围则由”策略类型(PolicyType)”进行指定。Ingress和Egress规则的基本要素如下图所示
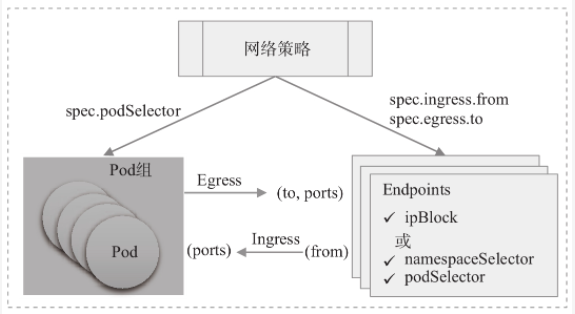
- 我们知道,NetworkPolicy是kubernetes API中标准的资源类型,它同样由apiVersion、kind、metadata和spec等字段进行定义。下面是一个基本配置框架和简要注释信息
apiVersion: networking.k8s.io/v1 #资源隶属的API群组及版本号
kind: NetworkPolict #资源类型的名称
metadata: #资源元数据
name: <string> #资源名称标识
namespace: <string> #networkpolicy是名称空间级别的资源
spec:
podSelector: <object> #当前规则生效的同一名称空间中的一组Pod对象,必选字段,空值表示当前名称空间中的所有Pod对象
policyType: <[]string> #Ingress表示生效Ingress字段,Egress表示生效Egress字段,同时提供表示二者均有效
ingress: <[]Object> #入站流量源端点对象列表,即白名单,空值表示"所有"
- from: <[]Object> # 具体的端点对象列表,空值表示所有合法端点
- ipBlock: <Object> # IP地址块范围内的端点
- namespaceSelector: <Object> #匹配的名称空间内的端点
- podSelector: <Object> #由Pod标签选择器匹配到的端点,空值表示"<none>"
ports: <[]Object> #具体的端口对象列表,空值表示所有合法端口
egress: <[]Object> #出站流量目标端点对象列表,即白名单,空值表示"所有"
- to: <[]Object> #具体的端点对象列表,空值表示所有的合法端点
ports: <[]Object> #具体的端口对象列表,空值表示所有合法端口
- 为了方便描述NetworkPolicy资源及其功能,我们会市场用到以下几个术语
- Pod组:由networkpolicy资源通过Pod标签选择器
spec.podSelector动态选出一组Pod资源集合,它们也是该网络策略规则管控的目标,可通过matchLabel或matchExpression类型的标签选择器选定 - Egress规则:出站流量的相关规则,负责管控由选定的Pod组发往其他网络端点的流量,可由流量的目标网络端点
spec.egress.to和端口spec.egress.ports来定义 - ingress规则:入站流量的相关规则,负责管控选定的Pod组所接收的流量,它能够由流量发出的源端点
spec.ingress.from和流量的目标端口spec.ingress.ports来定义 - 对端端点(to,from):与选定的Pod组交互的对端主机,它可以由CIRD格式的IP地址块(ipBlock)、网络名称空间选择器(namespaceSelector)来匹配名称空间内的所有Pod对象,甚至也可以是由Pod选择器(podSelector)在指定名称空间中选出的一组特定Pod对象等
- Pod组:由networkpolicy资源通过Pod标签选择器
- 在ingress规则中,由from指定的网络端点也成为”源端点”;而在egress规则中,网络端点也称为”目标端点”,它们使用to字段标识。对于未启用ingress或egress规则的Pod组,流量方向默认均为”允许”,即默认为非隔离状态。而一旦在
networkpolicy.spec中明确给出了ingress或egress字段,则它们的from或to字段的值就成了白名单列表;空值意味着选定所有端点,即允许相应方向上的所有流量通过,此时ingress和egress字段作用与未启用流量方向设置时相同 - ingress或egress规则的生效机制略复杂,以ingress为例,明确定义
spec.policyType为ingress,但却未定义spec.ingress字段,则它无法匹配任何流量,因而选出的Pod组将不接受任何端点的访问,而使用了空值的spec.ingress字段或spec.ingress.from字段,表示匹配所有合法端点,因而选出的Pod组可被任意端点访问。另一方面,即便egress规则拒绝了所有流量,但由ingress规则放行的请求流量的响应报文依然能够正常出站,它并不受限于egress规则的定义,反之亦然 - 尽管功能上日渐丰富,但NetworkPolicy资源仍然具有相当的局限性,例如它没有明确的拒绝规则、缺乏对选择器高级表达式的支持、不支持应用层规则,以及没有集群范围的网络策略等。为了解决这些限制,calico等提供了自由的策略CRD,包括NetworkPolicy和GlobalNetworkPolicy等,其中的NetworkPolicy CRD比kubernetes NetworkPolicy API提供了更强大的功能集,包括拒绝规则、规则解析以及应用层规则等,但相关的规则需要由calico创建
- Calico项目既能独立的为kubernetes集群提供网络插件和网络策略,也能与flannel结合在一起,由flannel提供网络解决方案,而calico仅用于提供网络策略,这种解决方案就是独立的canal项目。不过canal目前直接使用calico和flannel项目,代码本身并没有任何修改,因此canal仅是一种部署模式,用于安装和配置项目,从用户和编排系统的角度无缝的作为单一网络决绝方案协同工作。
管控入站流量
- 服务类型的Pod对象通常是流量请求的目标对象,但它们的服务未必应该公开给所有网络端点访问,这就有必要对他们的访问许可施加控制。在待管控流量Pod对象所处的名称空间创建一个NetworkPolicy对象,使用
spec.podSelector选中这组Pod,并在spec.ingress字段中嵌套管理规则,便能定向放行入站的访问流量 - ingress字段可嵌套使用的from和ports均为可选字段,空值意味着授权任意端点访问本地Pod组的任意端口,即放行所有入站流量。当仅定义了from字段时会隐含本地Pod组上的所有端口,而仅定义ports则隐含所有的源端点。from(源端点)和ports(目标端口)定义在同一个列表项中会隐含”逻辑与”关系,它匹配那些同时满足from和ports定义的入站流量
- ingress.from字段: from字段的值是一个对象列表,用于界定访问目标Pod组的一到多个流量来源,可嵌套使用ipBlock、namespaceSelector和podSelector这三个可选字段。这三个字段匹配Pod资源的方式各有不同,且ipBlock与另外两个字段互斥,而同时使用namespaceSelector和podSelector字段时隐含”逻辑与”关系,而多个列表项彼此间隐含”逻辑或”关系
- ipBlock: 根据IP地址或网络地址块匹配流量源端点。
- namespaceSelector: 使用标签选择器挑选名称空间,它将匹配由此标签选择器选出的相关名称空间内的所有Pod对象;空值表示所有的名称空间,即源端点可为集群上的任意Pod对象
- podSelector: 于networkpolicy资源所在的当前名称空间内基于标签选择器挑选Pod对象,空值表示挑选当前名称空间内的所有Pod对象;与namespaceSelector字段同时使用时,作用域为挑选出的名称空间,而非当前名称空间
- ingress.ports字段:ports字段的值也是一个对象列表,用于界定可被源端点访问的目标端口,它嵌套port和protocol来定义流量的目标端口,即由networkpolicy资源匹配到的当前名称空间内的Pod组上的端口
- port: 端口号或在container上定义的端口名称,未定义时匹配所有端口
- protocol: 传输层协议名称,TCP或UDP,默认为TCP
- ingress.from字段: from字段的值是一个对象列表,用于界定访问目标Pod组的一到多个流量来源,可嵌套使用ipBlock、namespaceSelector和podSelector这三个可选字段。这三个字段匹配Pod资源的方式各有不同,且ipBlock与另外两个字段互斥,而同时使用namespaceSelector和podSelector字段时隐含”逻辑与”关系,而多个列表项彼此间隐含”逻辑或”关系
- 下面是一个管控入站流量的示例,示例代码(netpol-frontend-youzi-ingress.yaml)中的networkpolicy资源将frontend名称空间中满足标签选择器app=youzi,env=prod的所有Pod对象定义为Pod组,通过ingress规则定义了该Pod组上入站流量规则
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: prod-www-youzi-com-ingress
namespace: frontend #网络策略生效的名称空间
spec:
podSelector: #定义本地Pod组的标签选择器
matchLabels:
app: youzi
env: prod
policyTypes: ["Ingress"] #仅Ingress(入站)规则生效
ingress:
- from: #规则1:可以访问Pod组上任意端口的流量源
- namespaceSelector: #流量源之一:指定名称空间中的所有端点
matchExpressions:
- key: name
operator: In
values: [frontend, dev, ingress-nginx, kube-node-lease, kube-ops, kube-public, kube-system, kubesphere-controls-system, kubesphere-monitoring-federated, kubesphere-monitoring-system, kubesphere-system]
- ipBlock: #流量源之二:指定网络地址范围内的所有端点
cidr: 10.244.0.0/24
- from: #规则2:可以访问Pod组的80端口的流量源
- namespaceSelector: #流量源,除default名称空间之外的其他所有名称空间中的端点
matchExpressions:
- {key: name, operator: NotIn, values: [default]}
- ports:
- protocol: TCP
port: 80
- 将上面清单中的NetworkPolicy/prod-tax-test-ingress创建之前请确保名称空间是否存在,否则,需要事先创建它
[root@jenkins prod-www.youzi.com]# kubectl apply -f netpol-frontend-youzi-ingress.yaml
networkpolicy.networking.k8s.io/prod-tax-test-ingress created
[root@jenkins prod-www.youzi.com]#
- 随后,为了测试Ingress规则的访问控制效果,我们需要在frontend名称空间中创建出满足标签选择器需求的本地Pod资源,然后还需要创建一个service资源用于将应用暴露出去,这样方便测试。这边我已经创建好了,所以直接验证即可
[root@jenkins prod-www.youzi.com]# kubectl get pods -n frontend --show-labels
NAME READY STATUS RESTARTS AGE LABELS
www.youzi.com-748f8b8db5-8mtq4 1/1 Running 0 27m app=youzi,env=prod,pod-template-hash=748f8b8db5
www.youzi.com-748f8b8db5-q2jhf 1/1 Running 0 27m app=youzi,env=prod,pod-template-hash=748f8b8db5
www.youzi.com-748f8b8db5-vcvqz 1/1 Running 0 7m57s app=youzi,env=prod,pod-template-hash=748f8b8db5
www.youzi.com-748f8b8db5-wzqzz 1/1 Terminating 0 27m app=youzi,env=prod,pod-template-hash=748f8b8db5
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl get svc -n frontend --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
prod-www-youzi-com ClusterIP 10.97.21.198 <none> 80/TCP,443/TCP 27m svc=prod-youzi
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl describe svc prod-www-youzi-com -n frontend
Name: prod-www-youzi-com
Namespace: frontend
Labels: svc=prod-youzi
Annotations: <none>
Selector: app=youzi,env=prod
Type: ClusterIP
IP: 10.97.21.198
Port: http 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.15.197:80,10.244.236.82:80,10.244.49.199:80
Port: https 443/TCP
TargetPort: 443/TCP
Endpoints: 10.244.15.197:443,10.244.236.82:443,10.244.49.199:443
Session Affinity: None
Events: <none>
[root@jenkins prod-www.youzi.com]#
- 接下来我们仅对该服务的80端口的相关规则进行测试,首先在default名称空间对frontend名称空间中的service/prod-www.youzi.com发起访问请求,测试其是否会被拒绝。这里需要先确保default名称空间有name=default标签,否则需要事先为其设定该标签
# 提示:任何期望能够以标签选择器匹配的名称空间都需要事先规划好并完成标签的添加,例如示例中通过name键筛选的各种名称空间,如`rontend,dev,ingress-nginx,kube-node-lease,kube-ops,kube-public,kube-system,kubesphere-controls-system,kubesphere-monitoring-federated,kubesphere-monitoring-system,kubesphere-system,default`
[root@jenkins ~]# kubectl get ns --show-labels
NAME STATUS AGE LABELS
default Active 99d kubesphere.io/namespace=default,kubesphere.io/workspace=system-workspace,name=default
dev Active 65d kubesphere.io/namespace=dev,name=dev
frontend Active 93d kubesphere.io/namespace=frontend,name=frontend
ingress-nginx Active 83d app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx,kubesphere.io/namespace=ingress-nginx,name=ingress-nginx
kube-node-lease Active 99d kubesphere.io/namespace=kube-node-lease,kubesphere.io/workspace=system-workspace,name=kube-node-lease
kube-ops Active 46d kubesphere.io/namespace=kube-ops,name=kube-ops
kube-public Active 99d kubesphere.io/namespace=kube-public,kubesphere.io/workspace=system-workspace,name=kube-public
kube-system Active 99d kubesphere.io/namespace=kube-system,kubesphere.io/workspace=system-workspace,name=kube-system
kubesphere-controls-system Active 46d kubesphere.io/namespace=kubesphere-controls-system,kubesphere.io/workspace=system-workspace,name=kubesphere-controls-system
kubesphere-monitoring-federated Active 46d kubesphere.io/namespace=kubesphere-monitoring-federated,kubesphere.io/workspace=system-workspace,name=kubesphere-monitoring-federated
kubesphere-monitoring-system Active 46d kubesphere.io/namespace=kubesphere-monitoring-system,kubesphere.io/workspace=system-workspace,name=kubesphere-monitoring-system
kubesphere-system Active 46d kubesphere.io/namespace=kubesphere-system,kubesphere.io/workspace=system-workspace,name=kubesphere-system
[root@jenkins ~]#
[root@jenkins ~]#
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl label namespace/default name=default
namespace/default labeled
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl get ns default --show-labels
NAME STATUS AGE LABELS
default Active 99d kubesphere.io/namespace=default,kubesphere.io/workspace=system-workspace,name=default
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl run client-$RANDOM --image="ikubernetes/demoapp:v1.0" -n default --rm -it --command -- /bin/sh
If you don't see a command prompt, try pressing enter.
[root@client-2501 /]#
[root@client-22176 /]# curl --connect-timeout 5 http://prod-www-youzi-com.frontend.svc.cluster.local.
curl: (28) Connection timed out after 5001 milliseconds
[root@client-22176 /]#
- 通过上面最后的命令输出的结果可以看到,default名称空间中的Pod对象发往frontend名称空间特定Pod组的请求因未明确设置放行规则而被拒绝。接着,我们再换到未限定端口的名称空间列表中的某一个进行测试
[root@client-13208 /]# curl --connect-timeout 5 http://prod-www-youzi-com.frontend.svc.cluster.local.
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@client-13208 /]#
[root@jenkins prod-www.youzi.com]# kubectl create ns prod
namespace/prod created
[root@jenkins prod-www.youzi.com]# kubectl run client-$RANDOM --image="ikubernetes/demoapp:v1.0" -n prod --rm -it --command -- /bin/sh
If you don't see a command prompt, try pressing enter.
[root@client-22632 /]# curl --connect-timeout 5 http://prod-www-youzi-com.frontend.svc.cluster.local.
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@client-22632 /]#
- 命令结果显示请求被允许通过,这完全符合我们的规则限定。
- 最后,在集群之外通过ingress-nginx想目标服务器发起请求,以测试非名称空间中端点的请求放行状态。直接在集群中随便找一个节点进行测试即可
[root@kube-master-01 ~]# curl --connect-timeout 5 http://10.244.10.97
curl: (28) Connection timed out after 5002 milliseconds
[root@kube-master-01 ~]#
- 因为没有任何规则可以匹配到集群外部的端点,因而请求会被拒绝。这也表明,在namespaceSelector中使用排除法时,最后的限定是集群上被排除的端点之外的其他端点。若要放行集群外部的端点,我们应该使用没有任何限制的流量源,例如
from: {}
管控出站流量
- 除非是在当前名称空间中即可完成所有目标功能,否则大多情况下,一个名称空间中的Pod资源总是有对外请求的需求,例如向CoreOS请求解析域名等。因此,通常应该将出站流量的默认策略设置为允许通过。但如果要对流量实施精细管理,仅放行有对外请求必要的Pod对象的出站流量,可以使用与Ingress规则相似的逻辑来定义Egress规则
networkpolicy.spec中嵌套的egress字段用于定义出站流量规则,就特定的Pod集合来说,出站流量一样默认处于放行状态,但只要有一个networkpolicy资源的标签选择器可以匹配到该Pod集合,则默认策略转为拒绝。与Ingress规则不同的之处在于,egress字段嵌套使用to和ports字段,前者用于定义本地Pod组的请求流量可发往的目标端点,其格式与逻辑都与ingress.from相同,后者同样用于限定访问的目标端口,不过是指被访问的对端端点上的服务端口- 下面配置清单示例(netpool-frontend-youzi-egress.yaml)的NetworkPolicy资源为标签选择器app=youzi,env=prod的Pod组通过Egress规则限制了可外发请求流量的白名单,它既能访问指定端点的特定服务端口
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: youzi-egress
namespace: frontend
spec:
policyTypes: ["Egress"] #仅Egress规则生效
egress:
- to: #规则一:仅生效于UDP协议的53号端口
ports:
- port: 53
protocol: UDP
- to: #规则二: 仅生效于TCP协议的6379端口
- podSelector: #流量目标:当前名称空间中匹配指定标签的Pod对象
matchLabels:
app: redis #访问redis数据存储访问
ports:
- port: 6379
protocol: TCP
- to: #规则三:仅生效于TCP协议的3306端口
- podSelector:
matchLabels:
app: Mysql
ports:
- port: 3306
protocol: TCP
- to: #规则四:仅生效于TCP协议的80和443端口
- podSelector:
matchLabels:
app: youzi
env: prod
ports:
- port: 80
protocol: TCP
- port: 443
protocol: TCP
podSelector: #定义本地Pod组的标签选择器
matchLabels:
app: youzi
env: prod
- 我们将上面的配置清单示例资源创建到集群上的frontend名称空间中,以便用于后续的测试操作
[root@jenkins prod-www.youzi.com]# kubectl apply -f netpol-frontend-youzi-egress.yaml
networkpolicy.networking.k8s.io/youzi-egress created
[root@jenkins prod-www.youzi.com]#
- 进入到POD里面对服务自身发起访问测试即可同时完成测试DNS名称解析服务请求组内youzi应用服务的请求结果状态
[root@jenkins prod-www.youzi.com]# kubectl get pods,svc -n frontend
NAME READY STATUS RESTARTS AGE
pod/www.youzi.com-748f8b8db5-l77bq 1/1 Running 0 2d12h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prod-www-youzi-com ClusterIP 10.99.162.86 <none> 80/TCP,443/TCP 2d16h
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl exec www.youzi.com-748f8b8db5-l77bq -n frontend -- curl -s http://prod-www-youzi-com.frontend.svc.cluster.local.
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@jenkins prod-www.youzi.com]#
- 通过上面的结果可以看出,访问本地的80及53端口是成功的,因为没有部署mysql和redis服务所以无法验证测试。
- 但是该组Pod无法访问Egress放行白名单之外的其他任何服务,例如访问
kube-ops名称空间中曾经部署的prometheus服务的9090端口最后结果就是因为请求超时而退出
[root@jenkins prod-www.youzi.com]# kubectl exec www.youzi.com-748f8b8db5-l77bq -n frontend -- curl -s --connect-timeout 5 http://prometheus.kube-ops.svc.cluster.local.:9090
command terminated with exit code 28
[root@jenkins prod-www.youzi.com]#
- 比如,假设我们想要访问
kube-ops名称空间的prometheus服务,可以在配置清单中添加如下规则
- to: #规则五:允许访问其他名称空间的9090端口
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: [frontend, dev, ingress-nginx, kube-node-lease, kube-ops, kube-public, kube-system, kubesphere-controls-system, kubesphere-monitoring-federated, kubesphere-monitoring-system, kubesphere-system]
ports:
- port: 9090
protocol: TCP
- 重新应用配置清单,再次测试访问是否能够成功访问prometheus服务
[root@jenkins prod-www.youzi.com]# kubectl apply -f netpol-frontend-youzi-egress.yaml
networkpolicy.networking.k8s.io/youzi-egress configured
[root@jenkins prod-www.youzi.com]#
[root@jenkins prod-www.youzi.com]# kubectl exec www.youzi.com-748f8b8db5-l77bq -n frontend -- curl -s --connect-timeout 5 http://prometheus.kube-ops.svc.cluster.local.:9090
<a href="/graph">Found</a>.
[root@jenkins prod-www.youzi.com]#
- 事实上,同一组Pod上的Ingress和Egress规则通常应该定义在同一个NetworkPolicy资源之上,我们前面只是为了分开说明用法而刻意放置在了不同的资源之上进行定义。另外,Ingress规则放行的请求响应报文不受Egress规则的限制,同理,Egress规则放行的出站请求而得到的入站响应报文也不受Ingress规则的限制
隔离名称空间
- 实践中,以名称空间分隔的多租户甚至是多项目的kubernetes集群上,通常应该设定彼此间的通信隔离,以提升系统整体安全性。但这些名称空间通常应该允许内部各Pod间的通信,以及允许来自集群上管理类应用专用名称空间的请求,包括kube-system,monitor,logs等。同时,这些名称空间通常会请求DNS服务,以及kubernetes的API等。下面的配置清单示例(net-default-frontend.yaml)为frontend名称空间创建了一个名为default-frontend-networkpolicy的NetworkPolicy资源
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-frontend-networkpolicy
namespace: frontend
spec:
policyTypes: #ingress和egress规则同时生效
- Ingress
- Egress
podSelector: {} #frontend名称空间的所有Pod资源都生效
ingress:
- from: #入站规则一:开放80和443端口
- namespaceSelector: #流量来源,来自指定名称空间的源端点
- key: name
operator: In
values: [frontend, dev, ingress-nginx, kube-node-lease, kube-ops, kube-public, kube-system, kubesphere-controls-system, kubesphere-monitoring-federated, kubesphere-monitoring-system, kubesphere-system, default]
ports:
- port: 80
protocol: TCP
- port: 443
protocol: TCP
egress:
- to: #出站规则一:允许访问任意外部端点的UDP协议的53端口
ports:
- port: 53
protocol: UDP
- to: #出站规则二:仅生效于TCP协议的443,80,9090端口
ports:
- port: 443
protocol: TCP
- port: 9090
protocol: TCP
- port: 80
protocol: TCP
- to: #出站规则三:仅生效于TCP协议的3306端口
- namespaceSelector: #流量目标,指定名称空间内的指定Pod对象
matchLabels:
app: mysql
podSelector:
matchLabels:
role: slave-node-01
role: slave-node-02
ports:
- port: 3306
protocol: TCP
- to: #出站规则四:仅生效于TCP协议的6379端口
- namespaceSelector: #流量目标:指定名称空间内的Pod对象
macthLabels:
app: redis
ports:
- port: 6379
protocol: TCP
- to: #出站规则五:生效所有端口
- namespaceSelector: #流量目标:当前名称空间中的所有端点
matchLabels:
name: fronrend
- 如果不希望完全放心当前名称空间中所有Pod对象彼此间的流量,可以从Ingress和Egress规则中将适配当前名称空间中的部分移除,而后由其他规则显式放行必要的内部流量
- 显然,每个名称空间都需要以当前名称空间为中心设置如上networkpolicy资源才能完成彼此间隔离,但kubernetes不支持集群级别的networkpolicy,因而只能逐个名称空间进行定义,且需要确保各名称空间中的用户不能轻易删除该networkpolicy资源
Calico的网络策略
- Calico支持GlobalNetworkPolicy和NetworkPolicy两种资源,前者用于定义集群全局网络策略,而后者大致可以看作kubernetes NetworkPolicy的一个超集
- GlobalNetworkPolicy支持使用selector、serviceAccountSelector或namespaceSelector来选定网络策略的生效范围,默认为all{},即集群上的所有端点。下面是一个配置清单示例(globalnetworkpolicy-demo.yaml)为非系统类名称定义了一个通用的网络策略
apiVerion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: global-networkpolicy
spec:
order: 0.0 #策略叠加时的应用次序,数字越小越先应用,冲突时,后者会覆盖前者
namespaceSelector: name not in {"kube-system", "kube-ops"} #策略应用目标为非指定名称空间中的所有端点,这里的意思就是只要不是{kube-system,kube-ops}
types: ["Ingress", "Egress"]
ingress: #入站流量规则
- action: Allow #白名单
source: #可由下面系统名称空间中每个源端点访问策略生效目标中端点的任意端口
namespaceSelector: name in {"kube-system", "kube-ops"}
egress: #出站流量规则
- action: Allow #允许所有
- 示例中,非系统名称空间中的Pod资源不允许非系统名称空间中的任何端点访问,包括同一名称空间中的其他端点。以frontend为例,指定的其他名称空间中的端点可以访问frontend内的任何端点,但frontend内的各端点彼此间并不能互相访问,也不能访问访问其他非系统名称空间的端点。但各名称空间内的出站流量不受任何限制。将上面的示例应用到系统之上,请确保引用的名称空间是否拥有对应的标签
[root@jenkins prod-www.youzi.com]# calicoctl apply -f globalnetworkpolicy-demo.yaml
Successfully applied 1 'GlobalNetworkPolicy' resource(s)
[root@jenkins prod-www.youzi.com]#
策略生效后,我们多方验证其访问控制效果。下面以frontend和kube-ops名称空间为例进行简单校验。我们需要先删除frontend名称空间下之前创建的所有NetworkPolicy资源,以精确测试全局网络策略的效果
测试DNS名称解析,成功完成
# 因为之前我已经删除掉了,所以这边返回没有资源
[root@jenkins prod-www.youzi.com]# kubectl delete networkpolicy --all -n frontend
No resources found
[root@jenkins prod-www.youzi.com]#
- 按照全局网络策略的定义,frontend名称空间的端点可以外网发送任何请求,包括请求kube-system中的coredns服务等,但这些网络端点彼此间无法访问,也不允许其他非系统名称空间中的端点访问
[root@jenkins prod-www.youzi.com]# kubectl run client-$RANDOM --image="ikubernetes/demoapp:v1.0" -n frontend --rm -it --command -- /bin/sh
If you don't see a command prompt, try pressing enter.
[root@client-21065 /]#
[root@client-21065 /]# host -t A prod-www-youzi-com.frontend.svc.cluster.local.
prod-www-youzi-com.frontend.svc.cluster.local has address 10.99.162.86
[root@client-21065 /]#
- 测试访问当前名称空间中的服务,失败。
[root@client-21065 /]# curl --connect-timeout 5 prod-www-youzi-com.frontend.svc.cluster.local.
curl: (28) Connection timed out after 5001 milliseconds
[root@client-21065 /]#
- 测试访问集群外部服务,成功
[root@client-21065 /]# curl www.baidu.com
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
[root@client-21065 /]#
另一方面,frontend名称空间中的各Pod允许接收指定的
kube-system,kube-ops名称空间中的任意端点发来的请求,并接受除此之外的其他名称空间中端点的访问请求。下面以kube-ops和default名称空间为例,使用其内部的端点想frontend名称空间中的demoapp服务进行请求测试在kube-ops名称空间起一个Pod客户端然后进行测试,访问成功
[root@jenkins prod-www.youzi.com]# kubectl run client-$RANDOM --image="ikubernetes/demoapp:v1.0" -n kube-ops -it --rm --command -- /bin/sh
If you don't see a command prompt, try pressing enter.
[root@client-26027 /]#
[root@client-26027 /]# curl prod-www-youzi-com.frontend.svc.cluster.local.
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@client-26027 /]#
- 在default名称空间起一个Pod客户端进行测试,访问失败
[root@jenkins prod-www.youzi.com]# kubectl run client-$RANDOM --image="ikubernetes/demoapp:v1.0" -n default -it --rm --command -- /bin/sh
If you don't see a command prompt, try pressing enter.
[root@client-15979 /]#
[root@client-15979 /]# curl --connect-timeout 5 prod-www-youzi-com.frontend.svc.cluster.local.
curl: (28) Connection timed out after 5000 milliseconds
[root@client-15979 /]#
- 定义好使用的全局网络策略,名称空间管理员便可按需使用NetworkPolicy资源组合定义本地入站流量的白名单,来设置端点的访问控制机制。GlobalNetworkPolicy和NetworkPolicy更详细的用法,请参考Calico的官方文档
- 另外部署calico时,GlobalNetworkPolicy和NetworkPolicy都以CRD的形式分别映射到了kubernetes API之上,只不过它们隶属于自定义的crd.projectcalico.org/v1这一API群组和版本,管理员可以使用该CRD来定义calico的全局网络策略和名称空间级别的网络策略,其格式和意义基本与原生格式相同
总结一下
- kubernetes的网络模型中包含容器间通信、Pod间通信、service与Pod间的通信,以及集群外部流量与Pod间通信这四种通信需求,其中Pod间通信由CNI或kubenet网络插件负责实现
- CNI网络插件主要由NetPlugin和IPAM两个API组成,前者用于让容器加入网络,后者用于为容器接口分配IP地址;容器虚拟网络的实现主要有overlay和Underlay两大类别
- CNI插件主流的第三方实现特别多,例如flannel、calico、weave等,用户需要根据自己的底层环境和所需要功能的以及期望的性能等维度进行评估与选择
- flannel支持host-gw、vxlan、udp、ipip和ipsec等后端,默认为vxlan
- calico也是最受欢迎的网络插件之一,它支持BGP、IPIP和VXLAN等容器网络,且额外提供了NetworkPolicy API的实现
- 网络策略能够给Pod间通信提供隔离机制,是kubernetes重要的安全基础设施,它支持Ingress和Egress两种类型的规则

若有收获,就点个赞吧
0 人点赞
