StatefulSet概述
- 应用程序存在”有状态”和”无状态”两种类别,因为无状态类应用的Pod资源可按需增加,减少或重构,而不会对由其提供的服务产生除了并发响应能力之外的其他严重影响。Pod资源的常用控制中,Deployment、ReplicaSet和DaemonSet等常用于管理无状态的应用。但是实际情况下是,应用本身就是分布式的集群,各应用实例彼此之间存在着关联关系,甚至是次序,角色方面的相关性,其中的每个实例都有其自身的独特性而无法轻易由其他实例所取代
- 无状态应用程序客户端的每次连接均可独立的处理,一次请求和响应既构成一个完整的事务,它们不受已完成的连接或现有其他连接的影响,且意外中断或关闭时仅需重新建立连接即可,因而,无状态应用的Pod对象可以随时由其他同一模板创建的Pod平滑替代,这也正是deployment控制器编排应用的方式
- 有状态应用而言,客户端的每次连接都再先前事务的上下文中执行,并可能影会收到该上下文的影响,事务意外中断时其上下文和历史行为会被进程予以存储,从而能支持客户端恢复该连接。有状态应用对同一个客户端的请求处理应该始终由同一服务器进行。
- 在云原生应用的体系里有两组常用的近义词:第一组是
无状态(stateless)、牲畜(cattle)、无名(nameless)和可丢弃(disposable),他们都可用于表述无状态应用;另一组是有状态(stateful)、宠物(pet)、具名(having name)和不可丢弃(non-disposable) - ReplicaSet控制器可以用来管控无状态应用,例如,提供静态内容服务的Web服务器程序等,而对于有状态应用的管控,则是另一项专用控制器的任务-statefulSet
Stateful应用和stateless应用
- 应用程序与用户、设备、其他应用程序或外部组件进行通信时,根据其是否需要记录前一次或者多次通信中的相关事件信息以作为下一次通信的分类标准,可以将那些需要记录信息的应用程序状态称之为”有状态(stateful)”应用,而无须记录的则称为”无状态(stateless)”应用。在了解stateFul之前,我们需要先了解下状态和存储的关系。
- 状态是进程的时间属性。无状态意味着一个进程不必跟踪过去的交互操作,本质上说它是一个纯粹的功能性行为。对应的,有状态则意味着进程存储了以前交互过程的记录,并且可以基于它对新的请求进行响应。至于状态信息被保存在内存中,或者持久保存于磁盘上,则是另外一个问题。
- 存储是表达持久保存数据的方法,现如今通常是指机械磁盘或SSD设备。若进程仅需操作内存中的数据,则表示其无须进行磁盘I/O操作;如果产生了I/O操作,则通常意味着数据的只读访问或读写访问行为
如下图所示,将状态和存储这两个概念正交于坐标系中,则可以归结出如下几种应用程序类型。

- 象限A中是那些具有读写磁盘需求的有状态应用程序,如支持事务功能的各种RDBMS存储系统;另外各种分布式存储系统也是此类应用程序的典型,如
Redis Cluster、MongoDB、ZooKeeper和Cassandra等 - 象限B中包含两类应用程序:一类是那些具有读写磁盘雪球的无状态应用,如具有幂等性的文件上传服务;另外一类是仅需只读类I/O访问的无状态应用程序,例如,从外部存储加载静态资源以响应用户请求的web服务程序。
- 象限C中是无磁盘访问需求的无状态应用程序,如地里坐标转换器应用。
- 象限D中是无磁盘访问需求的有状态应用程序,如电子商城中的购物车系统。
- 不过,用户拥有位置应用程序的部分自由度,例如,使用购物车的电子商城系统中,一般需要确保购物车里的物品在整个会话期间均保持可用状态,因此它可能不允许使用纯内存的解决方案。另外,设计有状态应用程序时需要着重考虑的另一个方面是数据持久存储的位置,在应用程序所在的节点发生故障后依然需要确保数据可被访问的场景就需要一个外部的持久存储系统,否则使用节点本地存储卷即可。
StatefulSet控制器概述
- ReplicaSet控制器能够从一个预置的Pod模板中创建一个或多个Pod资源,除了主机名和IP地址等属性之外,这些Pod资源并没有本质上的区别,就连他们的名称也是使用同一种散列模式生成,具有很强的相似性。通常,每一个访问请求都会以与其他请求相隔离的方式被这类应用所处理,不分先后也无须关系它们是否存在关联关系,哪怕它们先后来自于同一个请求者。于是,任何一个Pod资源都可以被ReplicaSet控制器重构出的新版本所替代,管理员更多关注的也是它们的群体特征,而无须过于关注任何一个个体。提供静态内容服务的web服务器是这类应用的典型代表之一。
- 对应的,另一类应用程序在处理客户端请求时,对当前请求的处理需要以前一次或多次的请求为基础进行,新客户端发起的请求则会被其添加专用标识,以确保后续的请求可以被识别。电商或社交等一类web应用站点中的服务程序通常属于此类应用。另外还包含了以更强关联关系处理请求的应用,例如,RDBMS系统上处于同一个事务中的多个请求不但彼此之间存在关联性,而且还要以严格的顺序执行。这类应用一般需要记录请求链接的相关信息,即“状态”,有的甚至还需要持久保存由请求生成的数据,尤其是存储服务类的应用,运行于K8S系统上时需要用到持久存储卷。
- 若ReplicaSet控制器在Pod模板中包含了某PVC(Persistent Volume Claim)的引用,则由它创建的所有Pod资源都将共享此存储卷。PVC后端的PV访问模式配置为ReadOnlyMany或ReadWriteMany时,这些Pod资源中的容器应用挂载存储卷后也就有了相同的数据集。不过,大多数情况下是,一个集群系统的分布式应用中国,每个实例都有可能需要存储使用不同的数据集,或者各自拥有其专有的数据副本,例如,分布式文件系统GlusterFS和分布式存储文档Mongodb中的每个实例各自使用专用的数据集,分布式服务框架zookeeper以及主从复制集群中的redis的每个实例各自拥有其专用的数据副本。由于ReplicaSet控制器使用同一个模板生成Pod资源,显然,它无法实现为每个Pod资源创建专用的存储卷。别的可考虑方案中,自主式Pod资源没有自愈能力,而组织多个只负责生成一个Pod资源的ReplicaSet控制器则有规模扩展不便的尴尬。
- 进一步来说,除了要用到专用的持久存储卷之外,有些集群类的分布式应用实例在运行期间还存在角色上的差异,它们存在单向/双向的基于IP地址或主机名的引用关系,例如主从复制集群中的Mysql从节点对主节点的引用。这类应用实例,每一个都应当当作一个独立的个体对待。ReplicaSet对象控制下的Pod资源重构后,其名称和IP地址都存在变动的可能性,因此也无法适配此种场景之需。而statefulSet(有状态副本集)则是专门用来满足此类应用的控制器类型,尤其管控的每个Pod对象都有着固定的主机名和专用存储卷,即便重构后也能保持不变。
statefulset的特性
- kubernetes系统使用专用的StatefulSet控制器编排有状态应用。StatefulSet表示一组具有唯一持久身份和稳定主机名的Pod对象,任何指定该类型Pod的状态信息和其他弹性数据都存放在与该StatefulSet相关联的永久性磁盘存储空间中。
- StatefulSet皆在部署有状态应用和集群化应用,这些应用会将数据保存到永久性存储空间,它适合部署kafka、Mysql、Redis、ZooKeeper以及其他需要唯一持久身份和稳定主机名的应用
- statefulset是Pod资源控制器的一种实现,用于部署和扩展有状态应用的Pod资源,确保它们的运行顺序以及每个Pod资源的唯一性。其与ReplicaSet控制器不同的是,虽然所有的Pod对象都基于同一个spec配置所创建,但statefulset需要为每个Pod维持一个唯一且固定的标识符,必要时还要为其创建专用的存储卷。statefulset主要适用于那些依赖于下列类型资源的应用程序:
- statefulset主要适用于那些依赖于下列类型资源的应用程序:
- 稳定且唯一的网络标识符
- 稳定且持久的存储
- 有序,优雅的部署和扩展
- 有序,优雅的删除和终止
- 有序而自动的滚动更新
- 一般来说,一个典型,完成可用的statefulSet通常由三个组件构成:
Headless Service,StatefulSet和volumeClaimTemplate。其中,Headless Service用于为Pod资源标识符生成可解析的DNS资源记录,StatefulSet用于管控Pod资源,volumeClaimTemplate则给予静态或动态的PV供给方式为Pod资源提供专有且固定的存储,虽然volumeClaimTemplate并不是强制需要,但是通常我们应该为一个statefuleset资源配置一个永久存储 - 对于一个拥有N个副本的
StatefulSet来说,其Pod对象会被有序创建,顺序依次是{0···N-1},删除则以相反的顺序进行。不过,,kubernetes 1.7及其之后的版本也支持并行管理Pod对象的策略。Pod资源的名称格式为${statefulset}-${ordinal},例如,名称为web的replicaset资源所生成的Pod对象的名称依次为web-0,web-1,web-2等,其域名后缀可由相关的headless类型的service资源给出,其格式为${service name}.${namespace}.svc.cluster.local,cluster.local是集群默认使用的域名 - Replicaset控制器会为每个VolumeClaim模板创建一个专用的pv,它会从模板中指定的storageclass中为每个PVC创建PV,如果未指定时将使用默认的StorageClass资源,而如果存储系统不支持动态PV供给,就需要管理员实现创建好满足需求的所有PV。删除Pod资源甚至是Replicaset可能感知器并不会删除与其相关的PV资源以确保数据的安全,PV资源需要用户手动删除。这意味着,Pod资源被重新调度至其他节点时,其PV及数据可复用。Pod名称,PVC,PV关系图如下:
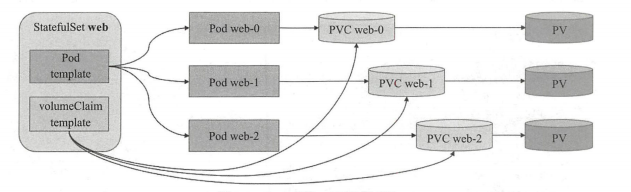
- StatefulSet也支持规模扩缩容操作,扩容意味着按索引顺序增加更多的Pod资源,而缩容则表示按逆序依次删除索引号最大的Pod资源直到规模数量满足目标设定值。执行扩容操作时,应用至某Pod对象之前必须确保其前面的每个Pod对象都已经就绪,反之,终止一个Pod对象时,必须事先确保它的后继者已经终止完成。考到到不少的有状态应用不支持规模的安全快速缩减,因此,Replicaset控制器不支持缩容时的并行操作,一次仅能终止一个Pod资源,以免导致数据错误。这通常也意味着,存在错误未修复的Pod资源时,replicaset控制器也会拒绝启动缩容操作。此外,缩容操作导致的Pod资源终止也不会删除与其相关的PV,以确保数据安全
- 多实例场景中,管理员需要独立表示每个客户端的固定映射关系。于是,有状态应用的编排模型也就必然要求控制器能独立识别每个Pod对象,确保每个Pod对象故障时的替代者仍能具有相同的标识且拥有先前实例持有的上下文,而这种上下文数据在先后实例间的传递通常需要借助每个Pod自身专用的存储卷完成
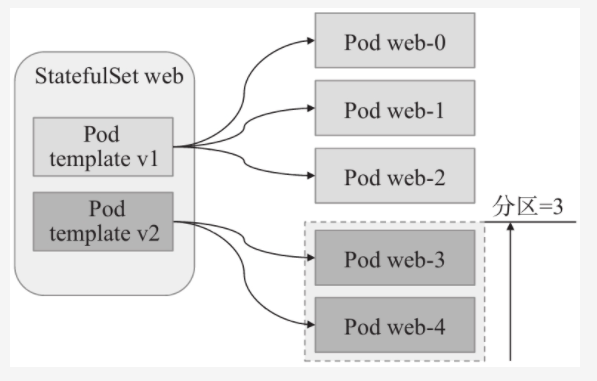
- kubernetes自1.7版本起还支持用户自定义更新策略,该版本兼容支持之前版本中的删除后更新(OnDelete)策略,以及新的滚动更新策略(Rolling Update)。OnDelete意味着不会自动更新Pod资源除非它被删除而激活重建操作。RollingUpdate是默认的更新策略,更新过程中,更新顺序与终止Pod资源的顺序相同,由索引号最大的开始,终止一个Pod对象并完成其更新后继续进行前一个。另外,RollingUpdate还支持分区(partition)机制,用户可以基于某个用于分区的索引号对Pod资源进行分区,所有大于等于此索引号的Pod对象会被滚动更新。而小于此索引号的则不会被更新,即便在此期间该范围内的某Pod对象被删除,它也一样会被基于旧版本的Pod模板重建。若给定的分区号大于副本数量,则意味着不存在大于此分区号的Pod资源索引号,因此,所有的Pod资源均不会被更新,这对于暂存发布,金丝雀发布或者分段发布来说,也是一个有用的设定
StatefulSet基础应用
- 如之前所描述的那样,一个完整的StatefulSet资源需要由三部分完成,
Headless Serice、StatefulSet和volumeClaimTemplate共同构成,StatefulSet资源规范中通过必选字段spec.serviceName指定关联的Headless类型的Service资源对象名称,但管理该Service是用户的责任,StatefulSet仅仅是依赖于它,而不会自动管理它。下面是statefulset资源的规范格式及简要说明 Headless Service: 用于为Pod资源标识符生成可解析的DNS资源记录statefulset: 用于管理Pod资源volumeClaimTemplate: 基于动态或者静态的PV供给方式为Pod提供专有且固定的存储
apiVersion: apps/v1 # API群组及版本kind: StatefulSet # 资源类型的特有标识metadata:name: <string> # z资源名称,在作用域当中需要唯一namespace: <string> # 名称空间; statefulset所在的名称空间spec:relicas: <integer> # 期望的Pod副本数,默认值为1selector: <object> # 标签选择器,需要与Pod模板中的标签匹配,必选字段template: <object> # Pod模板对象,必选字段revisionHistoryLimit: <integer> # 滚动更新历史记录数量,默认值为10updateStrategy: <object> # 滚动更新策略type: <string> # 滚动更新类型,可用值有Ondelete和RollingUpdate,默认值为RollingUpdaterollingUpdate: <Object> # 滚动更新参数,专门用于RollingUpdate类型partition: <integer> # 分区指示索引值,默认为0serviceName: <string> # 相关的Headless Service的名称,必选字段volumeClaimTemplates: <[]Obejct> # 存储卷申请模板apiVersion: <string> # PVC资源所属的API群组及版本,可省略kind: <string> # PVC资源类型表示,可省略metadata: <Object> # 卷申请模板的元数据spec: <object> # 期望的状态,可用的字段同PVCpodManagementPolicy: <string> # Pod的管理策略,默认的OrderedReady表示顺序创建并逆序删除
- 下面的配置清单示例中定义了一个名为demodb的Headless Service,以及一个同样名为demodb的StatefulSet资源,并且使用了存储卷申请模板,为Pod对象提供固定存储
- 下面是一个statefulset资源的配置清单示例。由于statefulset资源依赖于一个事先存在的Headless类型的Service资源,因此,首先定义了一个名称为
demodb的headless service资源,用于为关联到的每个Pod资源创建DNS资源记录。接着定义了一个volumeClaimTemplates(存储卷申请模板)从glusterfs存储类当中申请一个大小为2GB的专用存储,最后定义了一个名为demodb的statefulset资源,它通过Pod模板创建了两个Pod资源副本,并且使用Pod副本使用的是volumeClaimTemplates所定义的专用存储 - 事实上定义StatefulSet资源时,spec中必须要嵌套的字段为
serviceName和template,用于指定关联的Headless Service和需要使用的Pod模板,volumeClaimTemplates字段用于为Pod资源创建专有存储PVC模板,它可以内嵌使用的字段为persistenVolume-Claim资源的可用字段,对于statefulSet来说都为可选字段
apiVersion: apps/v1kind: Servicemetadata:name: demodbnamespace: defaultlabels:app: demodbspec:clusterIP: Noneports:- port: 9097name: demodbselector:app: demodb---apiVersion: apps/v1kind: StatefulSetmetadata:name: demodbnamespace: defaultspec:volumeClaimTemplates:- metadata:name: dataspec:accessModes: ["ReadWriteOnce"]storageClassName: glusterfsresources:requests:storage: 5GivolumeMode: Filesystemselector:matchLabels:app: demodbserviceName: demodbreplicas: 2template:metadata:labels:app: demodbspec:containers:- name: demodbimage: registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.1ports:- containerPort: 9907name: dbenv:- name: DEMODB_DATADIRvalue: /demodb/datalivenessProbe:initialDelaySeconds: 5periodSeconds: 10httpGet:path: /statusport: dbreadinessProbe:initialDelaySeconds: 15periodSeconds: 30httpGet:path: /status?level=fullport: dbvolumeMounts:- name: datamountPath: /demodb/data
- 资源清单配置完成之后即可创建资源
- 默认情况下,StatefulSet控制器以串行的方式创建各Pod副本,如果需要以并行方式创建和删除Pod资源,则可以设定
.spec.podManagementPolicy的值为Parallel,默认的值为OrderedReady。使用默认的顺序创建策略时可以使用kubectl get pods -l app=demodb -w -n default命令进行相关Pod资源的顺序生成的过程 - 等所有Pod创建完成之后,可以在StatefulSet资源的相关状态中查看到就绪信息
[root@jenkins prometheus]# kubectl get statefulset demodb -o wideNAME READY AGE CONTAINERS IMAGESdemodb 2/2 6m43s demodb registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.1[root@jenkins prometheus]#[root@jenkins demodb-statefulset]# kubectl apply -f demodb.yamlservice/demodb createdstatefulset.apps/demodb created[root@jenkins demodb-statefulset]#[root@jenkins demodb-statefulset]# kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESdemodb-0 1/1 Running 0 58s 10.244.2.6 kube-node-01 <none> <none>demodb-1 1/1 Running 0 40s 10.244.1.179 kube-node-02 <none> <none>[root@jenkins demodb-statefulset]#[root@jenkins demodb-statefulset]# kubectl describe svc demodbName: demodbNamespace: defaultLabels: app=demodbAnnotations: <none>Selector: app=demodbType: ClusterIPIP: NonePort: demodb 9097/TCPTargetPort: 9097/TCPEndpoints: 10.244.1.179:9097,10.244.2.6:9097Session Affinity: NoneEvents: <none>[root@jenkins demodb-statefulset]#
statefulSet资源标识符
- 前面有说,由StatefulSet创建的Pod资源拥有唯一且固定的资源标识符及存储卷,即便重新调度或者终止后重建,其名称也依然保持不变,并且之前存储的数据也不会丢失
- 上面的示例当中用到的demodb是一个用于测试的分布式键值存储系统,支持持久化存储,它由一个leader和一到多个followers组成,followers定期从leader查询并请求同步数据。Leader支持读写请求,而各followers节点仅支持只读操作,它们会把接收到的请求通过307响应码重定向给Leader节点。用于读写请求的URI分别为/get/KEY和/set/KEY,/status则用于输出状态,/status?level=full则能够以200响应码返回持有的键数量,否则就会响应500状态码
- 如之前所述,由StatefulSet资源创建的Pod对象拥有固定且唯一的标识符,它们基于唯一的索引序号及相关的StatefulSet对象的名称生成,格式为
<statefulset_name>-<ordinal index>,例如上面的信息中所显示的那样,由demodb-0和demodb-1两个Pod对象的名称即遵循该格式。事实上,这类Pod对象的主机名也与其资源名称相同,以demodb-0为例,下面的命令打出的主机名称正是Pod资源的名称标识
[root@jenkins ~]# kubectl exec demodb-0 -- hostnamedemodb-0[root@jenkins ~]#
- 我们已经知道,Headless Service的DNS名称解析会由ClusterDNS以该Service对象关联各Pod对象的IP地址加以响应。而statefulset创建的各Pod对象的名称则以相关的Headless Service资源的DNS名称为后缀,具体格式为
$(pod_name).$(svc_name).$(namespace).svc.cluster.local,例如demodb-0和demodb-1的资源名称分别为demodb-0.demodb.default.svc.cluster.local和demodb-1.demodb.default.svc.cluster.local - 下面可以用一个新的专用客户端创建一个临时的Pod对象用于交互测试
[root@jenkins demodb-statefulset]# kubectl run client --image ikubernetes/admin-toolbox:v1.0 -ti --rm --command -- /bin/bashIf you dont see a command prompt, try pressing enter.[root@client /]$# 首先测试解析Pod的FQDN格式主机名称,它会返回相应的Pod对象的IP地址[root@client /]$ nslookup -query=A demodb-0.demodbServer: 10.96.0.10Address: 10.96.0.10#53Name: demodb-0.demodb.default.svc.cluster.localAddress: 10.244.2.6[root@client /]$[root@client /]$ nslookup -query=A demodb-1.demodbServer: 10.96.0.10Address: 10.96.0.10#53Name: demodb-1.demodb.default.svc.cluster.localAddress: 10.244.1.179[root@client /]$ nslookup -query=A demodbServer: 10.96.0.10Address: 10.96.0.10#53Name: demodb.default.svc.cluster.localAddress: 10.244.1.179Name: demodb.default.svc.cluster.localAddress: 10.244.2.6[root@client /]$
- headless service资源借助SRV记录来引用真正提供服务的后端Pod对象的主机名称,进行指向包含Pod IP地址的记录条目。此外,由statefulset控制器管控的Pod资源终止后会由控制器自动进行重建,虽然其IP地址存在变化的可能性,但它的名称标识在重建后会保持不变,例如,在另外一个终端中删除Pod资源demodb-1
[root@jenkins monitor]# kubectl delete pod demodb-1pod "demodb-1" deleted[root@jenkins monitor]## 在删除完成之后,Pod对象依然会被重新创建出来,且只有IP地址有过变化[root@jenkins monitor]# kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESclient 1/1 Running 0 10m 10.244.2.7 kube-node-01 <none> <none>demodb-0 1/1 Running 0 78m 10.244.2.6 kube-node-01 <none> <none>demodb-1 1/1 Running 0 50s 10.244.1.180 kube-node-02 <none> <none>[root@jenkins monitor]## 可以再次进行nslookup解析测试[root@client /]$ nslookup -query=A demodb-1.demodbServer: 10.96.0.10Address: 10.96.0.10#53Name: demodb-1.demodb.default.svc.cluster.localAddress: 10.244.1.180[root@client /]$
- 因此,当客户端尝试向statefulset资源的Pod成员发出访问请求时,应该针对headless service资源的CNAME
(demodb-1.demodb.default.svc.cluster.local)记录进行,它指向的SRV记录包含了当前处于就绪状态的Pod资源。当然,若在配置Pod模板时定义了Pod资源的livenessprobe和readinessprobe,考虑到名称标识固定不变,也可以让客户端直接向资源记录(demodb-1.demodb和demod-0.demodb)发出请求
statefulSet资源存储
- 前面的statefulSet资源中,控制器通过
volumeClaimTemplates为每个Pod副本自动创建并且关联一个PVC对象,他们分别绑定了一个动态供给的PV对象
[root@jenkins demodb-statefulset]# kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEdata-demodb-0 Bound pvc-6bdff764-8ef1-4b17-97ba-17a20426b610 5Gi RWO glusterfs 101mdata-demodb-1 Bound pvc-82c630a6-965d-456e-9c27-84bf71d060a7 5Gi RWO glusterfs 100m[root@jenkins demodb-statefulset]#
- pvc存储卷由Pod资源中的容器挂载到了
/demodb/data目录,下面直接使用之前创建的一个临时的交互Pod进行数据持久存储的测试 - 创建一个测试文件,将其存储到demodb存储服务以发起数据存储测试,我们知道CoreDNS默认以roundrobin的方式响应对同一个名称的解析请求,因而以名称方式发往demodb这一headless service的请求会被轮询的发到demodb-0和demodb-1之上
[root@client /]$ echo "kubernetes is statuefulset test" > /tmp/mydata[root@client /]$ curl -L -XPUT -T /tmp/mydata http://demodb:9907/set/mydataWRITE completed[root@client /]$
- 调度至从节点(demodb-1)的写请求会自动重定向给主节点(demodb-0),且主节点数据存储完成之后将自动同步至各个从节点; 我们可以从服务器请求读取数据,或者直接从demodb-1读取数据,以进行测试
WRITE completed[root@client /]$ curl http://demodb:9907/get/mydatakubernetes is statuefulset test[root@client /]$
- demodb的所有节点会将数据存储在/demodb/data目录下,每个键被映射为一个子目录,数据存储在该子目录下的content文件中
[root@jenkins demodb-statefulset]# kubectl exec demodb-0 -- cat /demodb/data/mydata/contentkubernetes is statuefulset test[root@jenkins demodb-statefulset]#
- 而各Pod对象的/demodb/data 目录挂载到一个由statefulset/demodb存储卷申请模板创建的PVC之上,每个PVC又绑定在由存储类glusterfs动态供给的pv之上。各PVC的名称由volumeClaimTemplate对象的名称与Pod对象的名称组合而成,格式为
$(volume-ClaimTemplate_name).$(Pod_name)
[root@jenkins demodb-statefulset]# kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEdata-demodb-0 Bound pvc-6bdff764-8ef1-4b17-97ba-17a20426b610 5Gi RWO glusterfs 101mdata-demodb-1 Bound pvc-82c630a6-965d-456e-9c27-84bf71d060a7 5Gi RWO glusterfs 100m[root@jenkins demodb-statefulset]#
- 为了验证数据的持久存储,我们删除一个Pod,并且他会自动重建
- 删除StatefulSet控制器的Pod,其存储不会被删除,除非用户或者管理员手动执行了删除操作。因此,在另外一个终端中删除Pod资源demodb-1,然后由statefulset资源进行重建,它依然会被关联到之前的PVC存储卷上,且存储卷的数据依旧可用
[root@client /]$ curl http://demodb-1.demodb:9907/get/mydatakubernetes is statuefulset test[root@client /]$# 新开一个终端,删除demodb-1[root@jenkins demodb-statefulset]# kubectl delete pod demodb-1pod "demodb-1" deleted[root@jenkins demodb-statefulset]##statefulset自动进行重建[root@jenkins demodb-statefulset]# kubectl get pods -l app=demodb -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESdemodb-0 1/1 Running 0 103m 10.244.2.6 kube-node-01 <none> <none>demodb-1 1/1 Running 0 39s 10.244.1.181 kube-node-02 <none> <none>[root@jenkins demodb-statefulset]## 再次进行访问测试[root@client /]$ nslookup demodb-1.demodbServer: 10.96.0.10Address: 10.96.0.10#53Name: demodb-1.demodb.default.svc.cluster.localAddress: 10.244.1.181[root@client /]$[root@client /]$ curl http://demodb-1.demodb:9907/get/mydatakubernetes is statuefulset test[root@client /]$
- StatefulSet资源作用域内的Pod资源因被节点驱逐,或因节点故障,应用规模锁绒被删除,甚至是手动误删除时,它挂载的存储卷申请模板创建的PVC卷并不会被删除。因而,经statefulset资源重建或规模扩容回原来的规模后,每个Pod资源对象依然有固定的标识符可关联到此前的PVC存储卷上
- 由此表明,重建的Pod资源会被重新调度至某个节点,此前的PVC资源会被分配至某个节点,这样就真正意义上实现了数据的持久化
StatefulSet资源扩缩容
- StatefulSet资源的扩缩容与Deployment类似,也是通过简单的修改relicaset资源的副本数量来改动其Pod副本数量,以达到扩缩容的效果
- 对于statefulset来说,
kubectl scale和kubectl path命令均可实现此功能,也可以使用kubectl edit命令直接修改其副本数,或者在修改配置文件之后,由kubectl apply命令重新声明 - 例如,下面的命令可以将demodb中的Pod副本数量扩展至5个
扩容
[root@jenkins demodb-statefulset]# kubectl scale statefulset demodb --replicas=5statefulset.apps/demodb scaled[root@jenkins demodb-statefulset]## 使用kubectl get pods -w 进行动态观察,可以看到statefulset的创建与Pod资源创建策略相同,默认为顺次进行,而且其名称中的序号也将以现有Pod资源的最后一个序号向后进行,若定义了存储卷申请模板,扩容操作所创建的每个Pod对象也会各自关联所需要的PVC存储卷[root@jenkins demodb-statefulset]# kubectl get pods -wNAME READY STATUS RESTARTS AGEdemodb-0 1/1 Running 0 4h17mdemodb-1 1/1 Running 0 18hdemodb-2 0/1 ContainerCreating 0 12sdemodb-2 0/1 Running 0 15sdemodb-2 1/1 Running 0 45sdemodb-3 0/1 Pending 0 0sdemodb-3 0/1 Pending 0 0sdemodb-3 0/1 Pending 0 7sdemodb-3 0/1 ContainerCreating 0 7sdemodb-3 0/1 Running 0 16sdemodb-3 1/1 Running 0 43sdemodb-4 0/1 Pending 0 0sdemodb-4 0/1 Pending 0 0sdemodb-4 0/1 Pending 0 7sdemodb-4 0/1 ContainerCreating 0 7sdemodb-4 0/1 Running 0 10sdemodb-4 1/1 Running 0 34s[root@jenkins demodb-statefulset]#
缩容
- 与扩容操作相对,执行缩容操作只需要将其副本数量调低即可
- 例如,使用下面的命令将statefulset资源demob的副本数量改为2个
[root@jenkins demodb-statefulset]# kubectl patch statefulset/demodb -p '{"spec":{"replicas":3}}'statefulset.apps/demodb patched[root@jenkins demodb-statefulset]#
- 通过观察也可以发现statefulset资源缩容规模时终止Pod资源的默认策略也是以Pod顺序号逆序逐一进行,直到余下的数量满足目标为止
[root@jenkins demodb-statefulset]# kubectl get pods -w -l app=demodbNAME READY STATUS RESTARTS AGEdemodb-0 1/1 Running 0 4h25mdemodb-1 1/1 Running 0 18hdemodb-2 1/1 Running 0 8m13sdemodb-3 1/1 Running 0 43sdemodb-4 0/1 Terminating 0 20sdemodb-4 0/1 Terminating 0 30sdemodb-4 0/1 Terminating 0 30sdemodb-3 1/1 Terminating 0 53sdemodb-3 0/1 Terminating 0 54sdemodb-3 0/1 Terminating 0 55sdemodb-3 0/1 Terminating 0 55s
- 需要注意的是,因缩容操作而终止的Pod资源的存储卷并不会被删除,因此如果缩容规模后再将其扩容回来,此前的数据依然可用,且Pod资源名称也会保持不变
statefulset资源升级
- 如前所述,自kubernetes1.7版本起,statefulset资源支持自动更新机制,其更新字段由
spec.updateStrategy字段定义,默认为rollingUpdate,即滚动更新,另外一个可用策略为Ondelete,即删除Pod资源重建以完成更新,这也是kubernetes1.6及之前版本唯一可用的更新策略 - statefulset资源的更新机制可用于更新Pod中资源的容器镜像,标签,注解和系统资源配额等
滚动更新
- 滚动更新statefulSet控制器的Pod资源以逆序的形式从其最大索引编号的Pod资源逐一进行,滚动条件为当前循环更新中的各个Pod资源已经就绪。它在终止一个Pod资源、更新资源并在其就绪后启动下一个资源的更新,即索引号比当前号小1的Pod资源。对于主从复制的集群应用来说,这样也能保证主节点作用的Pod资源进行最后更新,确保兼容性。
- statefulset的默认更新策略为滚动更新,通过使用
kubectl describe statefulset NAME命令中的输出可以获取相关的信息
Name: demodbNamespace: defaultCreationTimestamp: Mon, 30 Aug 2021 18:19:02 +0800Selector: app=demodbLabels: <none>Annotations: <none>Replicas: 3 desired | 3 totalUpdate Strategy: RollingUpdatePartition: 0Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 FailedPod Template:
- 更新Pod中的容器镜像可以使用
kubectl set image命令进行,例如使用下面的命令可以将statefulset下的demodb的Pod镜像版本升级为v2
[root@jenkins demodb-statefulset]# kubectl set image statefulset/demodb demodb="registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2"statefulset.apps/demodb image updated[root@jenkins demodb-statefulset]#
- 可以看到类似如下命令中首先更新索引编号最大的Pod对象demodb-2,然后更新demodb-1,最后更新demodb-0
[root@jenkins demodb-statefulset]# kubectl get podsNAME READY STATUS RESTARTS AGEdemodb-0 1/1 Running 0 2m52sdemodb-1 1/1 Running 0 3m45sdemodb-2 0/1 Running 0 13s[root@jenkins demodb-statefulset]#[root@jenkins ~]# kubectl get pods -l app=demodb -wNAME READY STATUS RESTARTS AGEdemodb-0 1/1 Running 0 2m37sdemodb-1 1/1 Running 0 3m30sdemodb-2 0/1 Terminating 0 4m6sdemodb-2 0/1 Terminating 0 4m8sdemodb-2 0/1 Terminating 0 4m8sdemodb-2 0/1 Pending 0 0sdemodb-2 0/1 Pending 0 1sdemodb-2 0/1 ContainerCreating 0 1sdemodb-2 0/1 Running 0 3sdemodb-2 1/1 Running 0 36sdemodb-1 1/1 Terminating 0 4m8sdemodb-1 0/1 Terminating 0 4m10sdemodb-1 0/1 Terminating 0 4m11sdemodb-1 0/1 Terminating 0 4m11sdemodb-1 0/1 Pending 0 0sdemodb-1 0/1 Pending 0 0sdemodb-1 0/1 ContainerCreating 0 0sdemodb-1 0/1 Running 0 3sdemodb-1 1/1 Running 0 17sdemodb-0 1/1 Terminating 0 3m35sdemodb-0 0/1 Terminating 0 3m36sdemodb-0 0/1 Terminating 0 3m46sdemodb-0 0/1 Terminating 0 3m46sdemodb-0 0/1 Pending 0 0sdemodb-0 0/1 Pending 0 0sdemodb-0 0/1 ContainerCreating 0 0sdemodb-0 0/1 Running 0 3s[root@jenkins ~]#
- statefulset资源滚动更新过程中的状态同样可以使用
kubectl rollout history命令获取。更新完成后,我们可以使用如下命令,确认相关Pod对象使用的容器镜像是否已经变更为指定的新版本
[root@jenkins demodb-statefulset]# kubectl get pods -l app=demodb -o \> jsonpath='{range .items[*]}{.metadata.name}:{.spec.containers[0].image}{"\n"}{end}'demodb-0:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2demodb-1:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2demodb-2:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2[root@jenkins demodb-statefulset]#
- 滚动更新过程不会影响相应的数据服务,此前的生成的数据键mydata及其数据在更新过程中同样可以访问,这在之前的演示当中得到过验证。但是,当更新demodb-0期间,写操作会有短暂的不可用的时间
暂存更新操作
- 所谓暂存更新操作是指,当用户需要设定一个更新操作时,但是又不希望他立即执行,这个时候就可以将更新操作予以暂存,待条件满足后再手动触发其执行更新。statefulset资源的分区更新机制则可以满足此项功能
- statefulset资源支持使用分区编号(
.spec.updateStrategy.rollingUpdate.partition字段值)将其Pod对象分为两个部分,仅那些索引号大于等于分区编号的Pod对象会被更新,默认的分区编号为0,因而滚动更新时,所有的Pod对象都是待更新目标。于是,在更新操作执行前,将partition字段的值改为Pod资源副本数量N(或大于该值)会使得所有的Pod资源(索引号区间为0到N-1)都不再处于可直接更新的分区之内,那么这之后设定的更新操作不会真正执行而是被”暂存”起来,直到降低分区编号至现有Pod资源索引号范围内,才开始触发真正的滚动更新操作 - 使用下面的命令进行测试滚动更新的暂存更新操作,需要将statefulset资源demobd的滚动更新分区值设置为大于或者等于Pod资源副本数,我这里设置为3
[root@jenkins demodb-statefulset]# kubectl patch statefulset/demodb -p \> '{"spec":{"updateStrategy":{"rollingUpdate":{"partition":3}}}}'statefulset.apps/demodb patched[root@jenkins demodb-statefulset]#
- 而后,更新statefulset控制器里demodb的Pod模板中的容器镜像为v0.3
[root@jenkins demodb-statefulset]# kubectl set image statefulset/demodb demodb="registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.3"statefulset.apps/demodb image updated[root@jenkins demodb-statefulset]#
- 接下来,我们验证各个Pod资源里面的容器镜像版本,可以发现并未执行更新操作,直接验证demodb-2
[root@jenkins demodb-statefulset]# kubectl get pods/demodb-2 -o jsonpath='{.spec.containers[0].image}'registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2[root@jenkins demodb-statefulset]#[root@jenkins demodb-statefulset]# kubectl get pods -l app=demodb -o jsonpath='{range .items[*]}{.metadata.name}:{.spec.containers[0].image}{"\n"}{end}'demodb-0:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2demodb-1:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2demodb-2:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2[root@jenkins demodb-statefulset]#
- 此时,如果我们删除了statefulset里面的Pod资源,它依然会基于旧版本镜像进行重建。
- 删除Pod资源,让其自动重建测试
[root@jenkins demodb-statefulset]# kubectl delete pod demodb-2pod "demodb-2" deleted[root@jenkins demodb-statefulset]# kubectl get podsNAME READY STATUS RESTARTS AGEdemodb-0 1/1 Running 0 26mdemodb-1 1/1 Running 0 27mdemodb-2 1/1 Running 0 49s[root@jenkins demodb-statefulset]#[root@jenkins demodb-statefulset]# kubectl get pods/demodb-2 -o jsonpath='{.spec.containers[0].image}'registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2[root@jenkins demodb-statefulset]#
- 查看demodb-2的镜像信息发现还是基于旧版本的镜像创建的一个新Pod。
- 由此可见,暂存状态的更新操作对所有的Pod资源均不会产生影响
金丝雀部署
- 将处于暂存状态的更新操作的partition定位于Pod资源的最大索引号,即可放出一只金丝雀,由其测试第一轮的更新操作,在确认无误之后通过修改partition属性的值更新其他的Pod对象是一种更为稳妥的更新操作
- 例如,我们将partition的分区号降为最大索引号2之后可以验证,这个时候只会更新demodb-2,使用如下命令可用于更改分区号之后,稍微等一段时间后执行更新操作
[root@jenkins demodb-statefulset]# kubectl patch statefulset/demodb -p \> '{"spec":{"updateStrategy":{"rollingUpdate":{"partition":2}}}}'statefulset.apps/demodb patched[root@jenkins demodb-statefulset]#[root@jenkins demodb-statefulset]# kubectl get pods -l app=demodb -o jsonpath='{range .items[*]}{.metadata.name}:{.spec.containers[0].image}{"\n"}{end}'demodb-0:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2demodb-1:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.2demodb-2:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.3[root@jenkins demodb-statefulset]#
- 此时,位于非更新区内其他的od资源依然不会被更新到新的镜像版本,即使他们被删除后重建也是如此
- 这个时候demodb-2就像是一只”金丝雀”,在安然度过一定时长的测试时间之后,我们便可以继续其他Pod资源的更新操作。如果后续待更新的Pod资源数量比较少,我们则可以直接将partition的字段值设置为0,从而让statefulset逆序完成后续所有Pod资源的更新操作。如果待更新的Pod资源比较多时,也可以将Pod资源以线性或指数级增长的方式来分阶段完成更新操作,操作过程也仅仅是分多次修改partition字段值
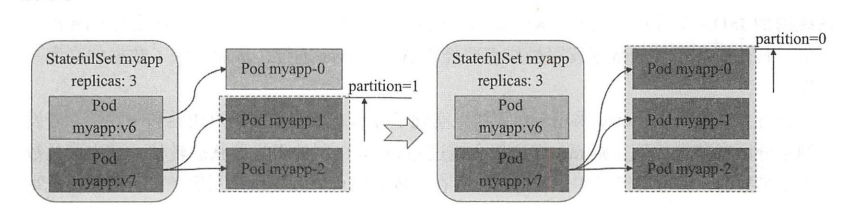
- 例如我们将partition的值改为1或者0完成剩余的Pod的更新操作
[root@jenkins demodb-statefulset]# kubectl patch statefulset/demodb -p '{"spec":{"updateStrategy":{"rollingUpdate":{"partition":0}}}}'statefulset.apps/demodb patched[root@jenkins demodb-statefulset]#[root@jenkins demodb-statefulset]# kubectl get pods -l app=demodb -o jsonpath='{range .items[*]}{.metadata.name}:{.spec.containers[0].image}{"\n"}{end}'demodb-0:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.3demodb-1:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.3demodb-2:registry.cn-hangzhou.aliyuncs.com/jiangyida/demodb:v0.3[root@jenkins demodb-statefulset]#
statefulset的局限性
- 应用于生产环境的分布式有状态应用的各实例间的关系并非像本篇文章示例中的demo那样简单,他们在拓扑上通常是基于复杂分布式协议的成员关系,例如zookeeper集群成员基于ZAB协议的leader/Follower关系以及etcd集群成员基于Raft协议的对等(peer)关系等。这些分布式有状态应用的内生拓扑结构存在区别,对持久存储的依赖需求也有所不同,并且集群成员的增加、减少以及在故障后的恢复操作通常都会依赖一系列复杂且精细的步骤才能完成,于是statefulset控制器无法为其封装统一、标准的管理操作。于是,用户就不得不配置某个特定的有状态应用,在其yaml配置清单中通过”复杂的运维代码”手动编写相关的运维逻辑,例如下面的这段代码便是以statefulset资源来编排etcd应用时,在其Pod模板中编写的仅实现了简单功能的运维代码。这看上去即奇怪又低效—-每个用户不得不学习相关的运维只是并重复”造轮子”,而statefulset对此却爱莫能助
command:- "/bin/sh"- "ecs"-|IP=$(hostname -i)PEERS=""for i in $(seq 0 $((${CLUSTER_SIZE} - 1)));doPEERS="${PEERS}${PEERS:+,}${SET_NAME}-${i}=http://${SET_NAME}-${i}.${SET_NAME}:2380"done# start etcd if cluster in already initialized the `--initial-*` options will be ignoredexec etcd --name $(HOSTNAME) \--listen-peer-urls http://${IP}:2380 \--listen-client-urls http://${IP}:2379,http://127.0.0.1:2379 \--advertise-client-urls http://${HOSTNAME}.${SET_NAME}:2379 \--initial-advertise-client-peer-urls http://${HOSTNAME}.${SET_NAME}:2380 \--initial-cluster-token etcd-cluster-1--initial-cluster ${PEERS}--initial-clustr-state new--data-dir /var/run/etcd/default.etcd
- 面对这种情况,CoreOS为kubernetes引入了一个称谓
Operator的新概念和新组建,它借助CRD(Customed Resource Definition)创建自定义资源类型来完整描述某个有状态应用集群,并创建相应的自定义控制器来编排这些自定义资源类型所创建的各个资源对象。简单来说,operator就是一个开发规范和SDK,它合理的利用kubernetes API的CRD功能扩展出二级抽象,又巧妙的回归到kubernetes的控制器逻辑,从而提供了一个有状态应用的实现接口,用户可以利用它开发专用于管理某个特定有状态应用的运维控制器,并按需回馈给社区 - 目前,Operator社区中涌现了大量的特定实例,例如coreos/etcd-operator、oracl/mysql-operator和jenkinsci/jenkins-operator等,有些分布式应用的可用Operator实现甚至不止一种。operator官方维护着etcd、rook、prometheus和vault几个operator,并通过https://github.com/operator-framework/awesome-operators维护着主流的operator项目列表。这意味着,在kubernetes系统部署分布式有状态应用的常用方式是operator,而非自定义statefulset资源
其他话题
- 同其他类型的Pod控制器资源类似,statefulset也支持级联或非级联的删除操作,默认的删除类型为级联删除,即同事删除statefulset和相关的Pod资源。若要执行非级联删除,为删除命令使用
--cascade=false选项即可 - 另外,statefulset控制器管理Pod资源的策略除了默认的OrderedReady(顺次创建及逆序删除)之外,还支持并行的创建和删除操作,即同事创建所有的Pod资源及同时删除所有的Pod资源,完成这一点,只需要将
spec.podManagementPolicy字段值设置为Parallel即可,不过对于有角色之分的分布式应用来说,为了保证数据安全可靠,建议使用默认策略,除非数据完整性是可以不用考虑在内的因素 - 之前说了,不同的有状态应用运维操作过程差别巨大,因此statefulset控制器本身几乎无法为此种类型的应用提供完善的通用管理机制,现实中的各种有状态应用通常是使用专有的自定义控制器专门封装特定的运维操作流程,这些自定义控制器也被统称为
operator
总结
- 有状态用相比较于无状态应用来说,在管理上有着特有的复杂之处,甚至不同的有状态应用管理方式也各不相同,在部署的时候需要精心组织
- statefulset依赖于Headless Service资源为其Pod资源创建DNS资源记录
- 每个Pod资源均拥有唯一且固定的名称,并且需要由DNS解析
- Pod资源中的应用需要依赖于PVC和PV来提供持久存储的能力
- 支持扩容和缩容,但是具体的实现方式需要依赖于应用自身
- 支持自动更新,默认的更新策略为滚动更新

若有收获,就点个赞吧
0 人点赞
