多项式的表示
举例:一元多项式及其运算
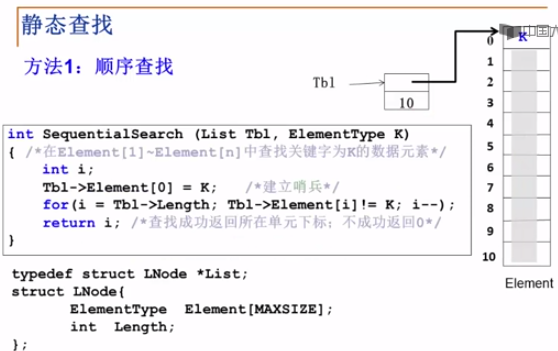
方法一:顺序存储结构直接表示
数组各分量对应多项式各项
问题:如何表示多项式
方法二:顺序存储结构表示非零项
按指数大小顺序存储
加法运算:从数组头开始,比较指数项大小,相同系数相加,不同则复制。
方法三:链表结构存储非零项
线性表:
同一个问题可以有不同的表示方法
有一类共性问题:有序线性序列的组织和管理
线性表:由同类型数据元素构成有序序列的线性结构
- 表中元素个数称为线性表的长度
- 线性表没有元素时,称为空表
- 表起始位置称表头,表结束位置称表尾

线性表的顺序存储实现
数组

注意:要有数据和表尾
- makeEmpty(): malloc一个空间,表尾指向-1
- Find(Type X,List L):遍历L,找到data == X的值,返回X所在下标
- insert(Type X,int i, List L):对i+1到last数值都向后移一位,第i位保存X
- Delete(int i, List L):对i+1到last数值都向前移一位,表尾-1
-
链表
注意:要有数据和指针
int Length(List PtrL):链表遍历求表长
- FindKth(int K,List PtrL):遍历查找第K个,返回其值
- Find(Type X,List PtrL):遍历L,找到data == X的值,返回X所在下标
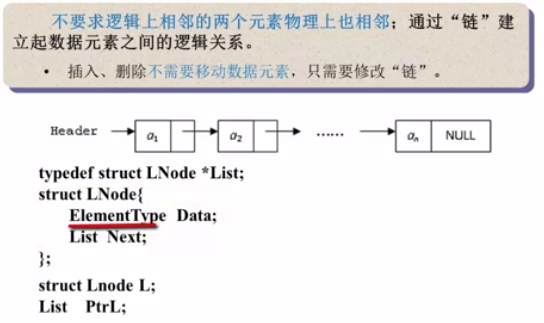
- insert(Type X,int i, List L):
- 构造一个新节点,用S指向
- 遍历找到链表的第i-1个节点,用p指向,如果在表头插入,则返回新链表的头指针
- 修改指针,插入结点
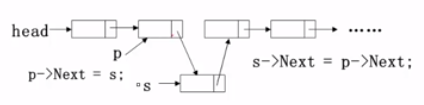
Delete(int i, List L)
问题:运算有优先级

- 后缀表达式:运算符号位于两个运算数后
- 使用堆栈
堆栈:具有一定操作约束的线性表,只在一端作插入,删除
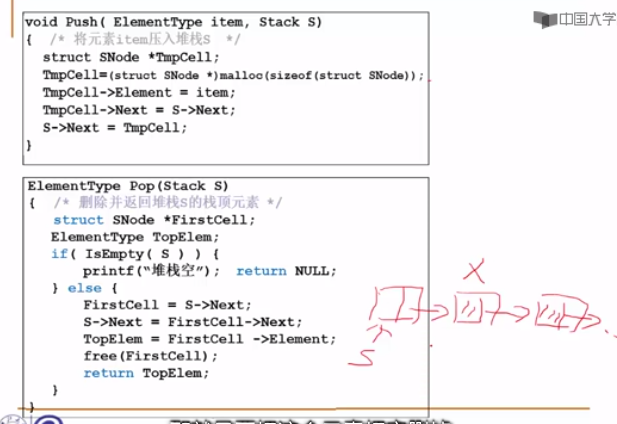
插入数据:入栈Push
删除数据:出栈Pop
后入先出:LIFO
C++ STL
c++中提供了stack容器,它是STL中的很有用的容器之一,其中元素遵循先进后出! stack类中包含以下几个成员函数:
empty() 堆栈为空则返回真 pop() 移除栈顶元素(不会返回栈顶元素的值) push() 在栈顶增加元素 size() 返回栈中元素数目 top() 返回栈顶元素
抽象数据类型描述

栈的顺序存储结构通常由一个一维数组和一个记录栈顶元素位置的变量组成‘
顺序存储实现
数组

- Push(Stack PtrS,Type item)
- 判断是否栈满
- Top+1,把值放在Top+1的位置
Pop(Stack PtrS)
注:表头在链表第一个元素的前面
- push(Type item, Stack S):
- malloc一块内存,赋值item,将第一个元素地址赋值给新节点
- 将表头指向新节点
- Pop(Stack S)
- 声明一个节点,将第一个元素赋值给该节点
- 将表头指向该节点的子结点
- 取出该节点内的值
- free该节点
- 返回取出的值
-
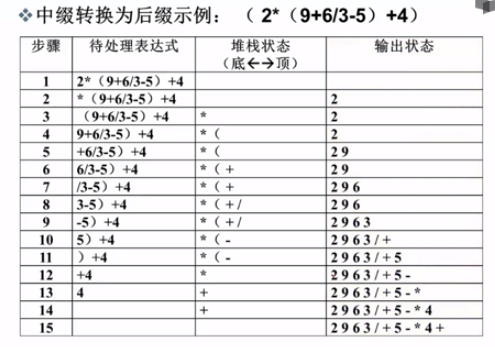
堆栈应用:表达式求值
基本策略:将中缀表达式转换为后缀表达式,然后求值
流程: 从头到尾读取中缀表达式的每个对象,对不同对象按不同的情况处理

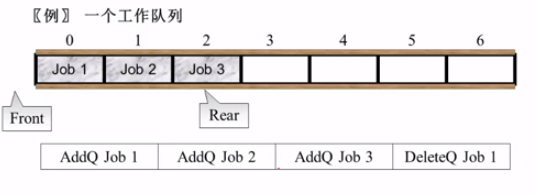
队列
重点:

- 队列头front:指向头一个元素的再前面一个,在删除的时候移动
- 队列尾rear:指向最后一个元素,在加入元素的时候移动
C++ STL
queue 操作
queue 和 stack 有一些成员函数相似,但在一些情况下,工作方式有些不同:
- front():返回 queue 中第一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。
- back():返回 queue 中最后一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。
- push(const T& obj):在 queue 的尾部添加一个元素的副本。这是通过调用底层容器的成员函数 push_back() 来完成的。
- push(T&& obj):以移动的方式在 queue 的尾部添加元素。这是通过调用底层容器的具有右值引用参数的成员函数 push_back() 来完成的。
- pop():删除 queue 中的第一个元素。
- size():返回 queue 中元素的个数。
- empty():如果 queue 中没有元素的话,返回 true。
- emplace():用传给 emplace() 的参数调用 T 的构造函数,在 queue 的尾部生成对象。
- swap(queue
&other_q):将当前 queue 中的元素和参数 queue 中的元素交换。它们需要包含相同类型的元素。也可以调用全局函数模板 swap() 来完成同样的操作。
queue模板定义了拷贝和移动版的 operator=(),对于所保存元素类型相同的 queue 对象,它们有一整套的比较运算符,这些运算符的工作方式和 stack 容器相同。
和 stack 一样,queue 也没有迭代器。访问元素的唯一方式是遍历容器内容,并移除访问过的每一个元素。例如:
std::deque<double> values {1.5, 2.5, 3.5, 4.5};std::queue<double> numbers(values);while (!numbers, empty()){std ::cout << numbers. front() << " "; // Output the 1st elementnumbers. pop(); // Delete the 1st element}std::cout << std::endl;
用循环列出 numbers 的内容,循环由 empty() 返回的值控制。调用 empty() 可以保证我们能够调用一个空队列的 ftont() 函数。如代码所示,为了访问 queue 中的全部元素,必须删除它们。如果不想删除容器中的元素,必须将它们复制到另一个容器中。如果一定要这么操作,我们可能需要换一个容器。
具有一定操作约束的线性表
插入和删除操作,只能在一端插入,另一端删除
顺序存储实现:数组实现

包括三部分:
- 数值
- 队列头front:指向头一个元素的再前面一个,在删除的时候移动
- 队列尾rear:指向最后一个元素,在加入元素的时候移动
队列的链式存储实现
采用单链表实现
表头可以做删除插入操作,表尾只能做插入操作,删除后不知道前面的节点在哪。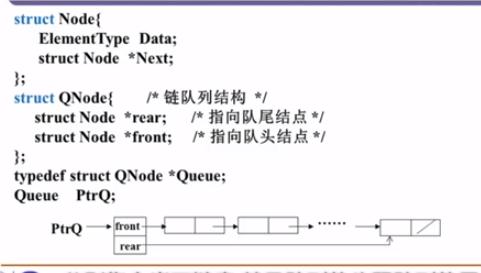
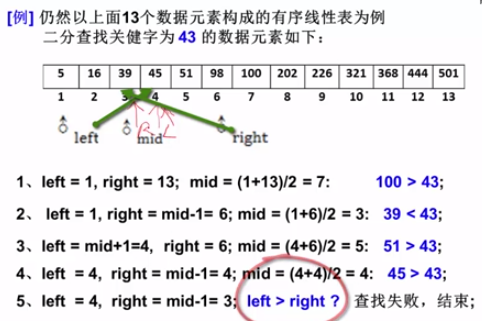
二分查找
- 必须以数组的形式存放
- 必须有序

C++ STL 二分查找
1.头文件
include
2.使用方法
a.binary_search:查找某个元素是否出现。 a.函数模板:binary_search(arr[],arr[]+size , indx) b.参数说明:
arr[]: 数组首地址
size:数组元素个数
indx:需要查找的值 c.函数功能: 在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。 2.lower_bound:查找第一个大于或等于某个元素的位置。
a.函数模板:lower_bound(arr[],arr[]+size , indx):
b.参数说明:
arr[]: 数组首地址
size:数组元素个数
indx:需要查找的值
c.函数功能: 函数lower_bound()在first和last中的前闭后开区间进行二分查找,返回大于或等于val的第一个元素位置(注意是地址)。如果所有元素都小于val,则返回last的位置
d.举例如下:
一个数组number序列为:4,10,11,30,69,70,96,100.设要插入数字3,9,111.pos为要插入的位置的下标,则
/注意因为返回值是一个指针,所以减去数组的指针就是int变量了/
pos = lower_bound( number, number + 8, 3) - number,pos = 0.即number数组的下标为0的位置。
pos = lower_bound( number, number + 8, 9) - number, pos = 1,即number数组的下标为1的位置(即10所在的位置)。
pos = lower_bound( number, number + 8, 111) - number, pos = 8,即number数组的下标为8的位置(但下标上限为7,所以返回最后一个元素的下一个元素)。
e.注意:函数lower_bound()在first和last中的前闭后开区间进行二分查找,返回大于或等于val的第一个元素位置。如果所有元素都小于val,则返回last的位置,且last的位置是越界的! 返回查找元素的第一个可安插位置,也就是“元素值>=查找值”的第一个元素的位置 3.upper_bound:查找第一个大于某个元素的位置。
a.函数模板:upper_bound(arr[],arr[]+size , indx):
b.参数说明:
arr[]: 数组首地址
size:数组元素个数
indx:需要查找的值
c.函数功能:函数upper_bound()返回的在前闭后开区间查找的关键字的上界,返回大于val的第一个元素位置
例如:一个数组number序列1,2,2,4.upper_bound(2)后,返回的位置是3(下标)也就是4所在的位置,同样,如果插入元素大于数组中全部元素,返回的是last。(注意:数组下标越界)
返回查找元素的最后一个可安插位置,也就是“元素值>查找值”的第一个元素的位置 。
动态查找:树
集合中记录是动态变化的
- 有插入删除操作
定义
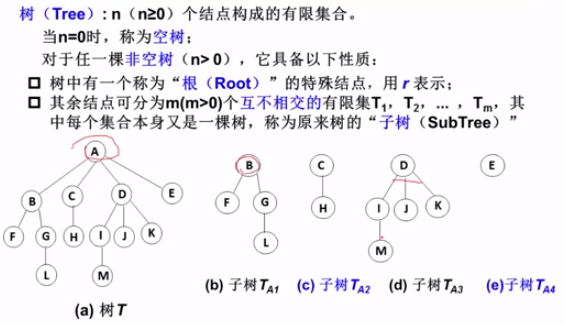
结点的度:结点的子树个数,二叉树度为2
树的度:树的所有结点中最大的度数
叶结点:度为0的点
父结点/子结点/兄弟结点
路径和路径的长度:边的个数为路径长度
祖先结点Ancestor
子孙结点Descendant
结点的层次level:根结点在1层
树的深度depth:所有结点中最大的层次是树的深度
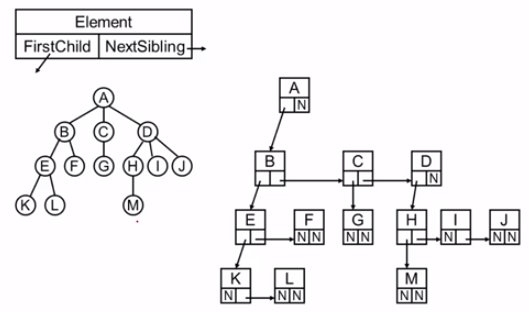
树的表示
- 儿子-兄弟表示法:二叉树,度为2的树
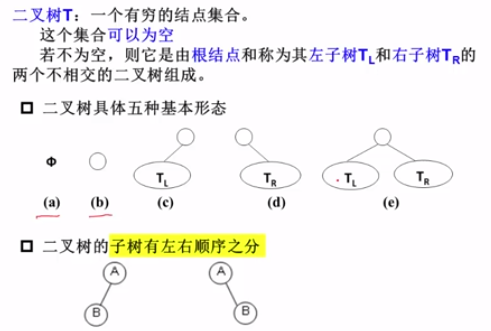
二叉树的定义
特殊二叉树:
第i层的最大结点数:

- 深度为k的二叉树最大结点总数

- 对任意非空二叉树,n0叶结点个数,n1度为1的节点个数,n2度为2的节点个数,则n0 = n2 + 1
二叉树的抽象数据类型定义
重点:
主要操作:遍历
遍历方法:先序遍历,中序遍历,后序遍历,层次遍历
二叉树的存储结构
二叉树的遍历
递归的方法使用堆栈先序遍历
根左右
中序遍历
左根右
后序遍历
左右根
二叉树的非递归遍历
使用堆栈的方法
二叉搜索/查找树
定义:非空左子树的所有键值小于其根节点的键值,非空右子树的所有键值大于其根节点的键值
操作

Position Find(Type X, BT BST)

Position FindMin(Type X, BT BST)

Position FindMax(Type X, BT BST)
从BST中找到最大值并返回,即最右边的结点,如上图
BT Insert(Type T, BT BST)
二叉搜索树的插入:找到元素应该插入的位置
BinTree Insert(ElementType X,BinTree BST){if(!BST){BST = malloc(sizeof(struct BinTree));// BinTree *node = new(BinTree);BST->Data = X;BST->right = BST->left = NULL;}else{if(X < BST->Data){BST = BST->left;}else if(X > BST->Data){BST = BST->right;}}return BST;}

若有收获,就点个赞吧
0 人点赞
