C语言的扩展:
关注性能
- 与底层硬件紧密结合:JAVA/python关注易用性,C/C++关注性能.由于底层硬件标准不一致,关注易用性的语言通过统一标准来无视底层标准
- 对象生命周期的精确控制:C#自动销毁对象(易用性),C++生成/销毁都要控制,及时释放资源(性能)
- zero-overhead abstraction:
- 不需要为没有使用的语言特性付出成本:eg:虚函数,
- JAVA在即使没有使用虚函数的时候也会有虚函数特性的成本付出
- JAVA无法控制创建对象在堆or栈上实例化。堆上实例化寻址操作更复杂
- 使用了一些语言特性不等于付出运行期成本
- consteval(c++ 20特性)编译期得到函数结果,运行期直接使用结果,节省运行期成本
- 不需要为没有使用的语言特性付出成本:eg:虚函数,
- 一系列不断演进的标准集合:
- C++98/03,C++11,C++14,C++17,C++20
- 语言本身的改进
- Memory Model:多线程
- Lambda Expression:
- 标准库的改进
- type_traits/ranges
- auto_ptr(删除)
C++标准的工业界实现
三种编程范式:面向过程,面向对象,泛型
- 函数重载,异常处理,引用
编写程序时要注重
- 性能
- 标准:替代特定平台的头文件
C++的开发环境与相关工具
工具
- /usr/bin/time:
- valgrind:是否有内存泄漏
- cppreference:C++百科全书,标准分析及举例
- Comliler explorer:
- 直接生成汇编代码
- 不同颜色:汇编语句对应源代码
- 选择编译器
- 缺点:只能贴一段代码,不适用多文件
- C++ insights
-
C++的编译/链接模型
分块处理
将多个源文件分别编译为目标文件(分块),再将目标文件链接生成可执行程序。
修改一个源文件只重新生成该源文件对应的目标文件。便于系统修改升级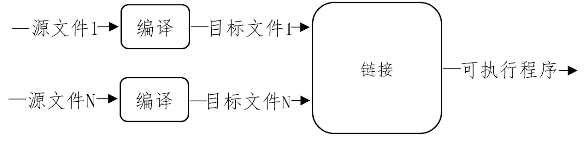
简单加工模型
由分块处理衍生出的概念

定义/声明:分块处理时,当不同的文件同时使用一个变量,需要区分出变量的定义和声明。如,在目标文件1定义了这个变量,目标文件2~N使用了这个变量(不能重复定义),编译的时候目标文件2要给一个声明,告诉编译器在其他文件这个变量有定义,在链接的时候查找目标文件1的定义。
- 头文件/源文件:多个目标文件2~N引用同一个变量,都要有声明,为了方便书写,不重复声明,将所有声明写在头文件,然后在目标文件2~N中包含头文件
- 头文件中也可能包含定义=========有一种bug,头文件中包含定义,然后报重复定义的错误,如何解决?
翻译单元:把源文件+相关头文件(直接/简介)- 应忽略的预处理语句(宏等)。编译期处理翻译单元
代码处理流程:
ifndef HEAD_2 //(注意:宏名不要重名)#define HEAD_2
….
#endif
- #param once
- 编译:把翻译单元变成汇编代码,xx.i->xx.s
- 编译优化
- 优点:提升执行速度
- 缺点:优化后程序无法执行断点,不方便调试
- debug优化较少,release引入更多的编译优化
- 增量编译 VS 全部编译:
- 增量编译:源文件和目标文件都有构造时间,当更新源文件,其构造时间比目标文件新,则在编译的时候只对更新后的源文件进行编译。若修改头文件,需要重新编译相应的源文件,但有些编译器不能完成此操作,需要全部编译。
- 编译优化
- 汇编:把汇编代码生成目标文件(机器码),xx.s->xx.o
- 链接:关联目标文件,生成可执行文件,合并多个目标文件,关联声明与定义,xx.o->xx.exe
- 链接种类:
- 内部链接:只在翻译单元内部可见
- 外部链接:在不同的翻译单元均可见
- 无链接:
- 链接错误:找不到定义,有东西只有声明没有定义。
- 预处理,编译,链接都可能出错,编译可能产生警告,错误,都要重视。
- 链接种类:

若有收获,就点个赞吧
0 人点赞
