1.三层架构
表现层:web层(MVC是表现层的一个设计模式)
业务层:service层
持久层:dao层
2.三大框架和三层架构的关系
Hibernate框架:持久层框架
Struts2框架:表现层框架
Spring框架:综合类框架
7.ORM(Objcet Relational Mapping)
对象关系映射,就是建立实体类和数据库表的对应关系。
实现操作实体类对象就相当于操作数据库表
8.hibernate
它是一个轻量级,企业级,开源的ORM持久层框架,是可以操作数据库的框架。
框架:是一个架构
通常情况下,软件工程的持久层解决方法,一个为主一个为辅,两者并存(写SQL语句和不写SQL语句)
轻量级:指的是依赖的资源很少。(目前我们使用的阶段,只依赖log4j,c3p0连接池)
企业级:指的是在企业级应用中使用的比较多
开源的:开放的源代码
ORM的操作方式:建立对象关系映射,实现操作实体类就相当于操作数据库表
9.CRM
客户关系管理系统
10.编写映射配置文件(与表和javabean类建立关系)
(1)导入dtd约束:
hibernate-core-5.0.7.Final.jar下的org.hibernate包内的:
hibernate-mapping-3.0.dtd
代码实现:Hibernate项目 Domain包下Customer.hbm.xml
11. 编写主配置文件(与哪个数据库建立关系)
(1)导入dtd约束
hibernate-core-5.0.7.Final.jar下的org.hibernate包内的:
hibernate-configuration-3.0.dtd
(2)配置session-factory的信息:
在hibernate源码文件夹中project/ect/hibernate.properties查看
代码实现:Hibernate项目 src下hibernate.cfg.xml
12. 入门案例
需求:保存一个客户到数据库中
代码实现:Hibernate项目 Test.Demo01
13. hibernate的常用对象
(1)Configuration
启动、加载、管理配置文件信息
(2)SessionFactory(线程安全的,多并发不会引发数据紊乱)
使用原则:
一个应用应该只有一个SessionFactory,在应用加载时创建,应用卸载时销毁。
维护信息:
1、 连接数据库的信息
2、 Hibernate的基本配置
3、 映射文件的位置、映射文件中的配置
4、 一些预定义的sql语句
5、 Hibernate的二级缓存
方法:
openSession() : 每次都是生成一个新的Session
getCurrentSession() :
(3)Session(很重要)
负责操作数据库,必须掌握该对象操作数据库的方法。
概述:是应用程序与数据库之间的交互操作的一个单线程对象。
使用原则:一个线程只有一个Session对象。线程不安全的
方法:
save(Object entity) :保存一个实体到数据库中
update(Object entity) :更新一个实体
delete(Object entity) :删除一个实体
get(Class clazz,Serializable id) :
根据一个id查询一个实体。clazz表示要查询的实体类字节码。
id表示要查询的条件
beginTransaction() : 开启事务,并返回事务对象
(4)Transaction
负责提交和回滚事务。
14. Hibernate的CRUD操作
需求:实现增删改查操作。
代码实现:Hibernate项目 Test.Demo02
15. 配置c3p0连接池
在hibernate.cfg.xml设置
name=:hibernate.connection.provider_class
值:org.hibernate.connection.C3P0ConnectionProvider
16. 验证吃c3p0连接池是否配置成功
代码实现:Hibernate项目 Test.Demo03
17. 查询之get和load方法的异同
代码实现:Hibernate项目 Test.Demo04
get(Class clazz,Serializable id);
load(Class clazz,Serializable id);
共同之处:都是根据id查询一个实体
区别:
1. 查询的时机不一样
a) get查询时机:每次调用get方法时,马上发起查询。 立刻加载
b) load查询时机:每次需要使用查询结果时,发起查询。 延迟加载
改为“立即加载”的方式:
找到查询实体的映射配置文件,它的class标签上也有一个lazy属性。
true: 延迟加载
false:立即加载
2. 返回的结果不一样
a) get方法返回的对象是实体类类型
b) load方法返回的对象是实体类类型的代理对象。
18. 实体类的编写规范
应该遵循JavaBean的编写规范
Bean :在软件开发中指的是可重用的组件
JavaBean : 指的是用java语言编写的可重用组件。在我们的实际项目中:domain、service、dao都可以看成是JavaBean。
编写规范:
类都是public的
一般实现序列化接口
类成员都是私有的
私有类成员都有set/get方法
类都有默认无参构造函数
细节:
数据类型的选择问题:
基本类型和包装类,选择哪个? 包装类
19.hibernate的对象标识符:OID
1、JVM内存区分两个对象是否是同一个,靠的是内存的地址,只要地址不相同,就可以创建两个对象。
2、数据库中用于区分记录是否相同,靠的是主键,表中不允许出现相同主键的两条数据。
3、hibernate中把OID一直的对象,就认为是同一个对象,在同一个Session,不允许出现两个相同类型的对象的OID一致。
4、OID就是映射文件中对应数据库主键的属性。
20.hibernate的主键生成方式
native:根据底层数据库对自动生成表示符的能力来选择identity、sequence、hilo(高位运算法)三种生成器中的一种,适合跨数据库平台开发。适用于代理主键。
identity:采用底层数据库本身提供的主键标识符,条件是数据库支持自动增长数据类型。该生成器要求在数据库中把主键定义成为自增长类型。适用于代理主键。Oracle不支持。
sequence: hibernate根据底层数据库序列生成标识符。条件是数据库支持序列。适用于代理主键。
uuid: hibernate采用128位的UUID算法来生成标识符。这种策略并不流行,因为字符串类型的主键比整数类型的主键占用更多的数据库空间。适用于代理主键。
increment(一般不用) : 用于long、short或int类型,由hibernate自动以递增的方式生成唯一标识符,每次增量为1。只有当没有其它进程向同一张表中插入数据时才可以使用,不能在集群环境中使用,适用于代理主键。
多线程访问时,反应快的能成功插入,反应慢的会出现主键重复。
assigned : 由java程序自动生成标识符,如果不指定id元素的generator属性,则默认使用盖主键生成策略。适用于自然主键。
代理主键(逻辑主键):它的作用只是用于区分数据库中的记录的,不参与程序的业务逻辑。
自然主键(业务主键):它的作用不仅用于区分数据库中的记录的,还参与程序的业务逻辑。自然主键一般都设为有规律的。
21.hibernate的一级缓存
缓存:它就是内存中的临时数据。
为什么使用缓存?
减少和数据库交互的次数,从而提高查询效率。
什么样的数据适用于缓存,什么样的数据不适用于缓存?
适用缓存的数据:
经常查询的,并且不经常修改的。同时数据一旦出现问题,对最终结果影响不大的。
不适用缓存的数据:
不管是否经常查询,只要是经常修改的,都可以不用缓存。
并且如果数据由于使用缓存,产生了异常数据,对最终结果影响很大,则不能使用。例如:股市的牌价,银行的汇率,商品的库存等等。
Hibernate的一级缓存:它指的是Session对象的缓存,一旦Session对象销毁了,则一级缓存也就消失了。
需求:证明一级缓存确实存在
代码测试: Hibernate项目 Test.Demo05
22.Hibernate的快照机制:
一旦Session对象销毁了,则快照区也就消失了。
代码测试:Hibernate项目 Test.Demo06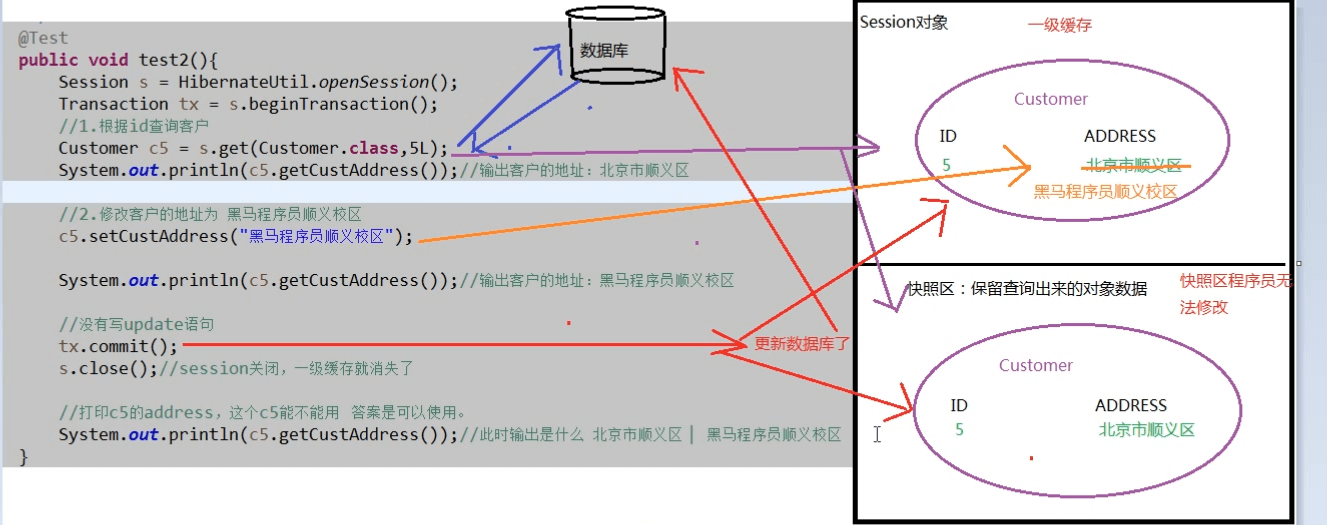
23.Hibernate中对象的状态
保存:瞬时状态——》持久化状态
更新:脱管状态——》持久化状态
查询:查询出来的对象都是持久化状态。一旦Session关闭,立刻变为脱管状态。
瞬时状态(临时状态)
标志:没有OID,和Session没有关系
持久化状态
1、标志:有OID,和Session有关系
2、只有持久化状态的对象,才会有一级缓存的概念。有一级缓存,查询时就不会和数据库打交道。
3、没有提交事务之前,数据库没有记录的。
脱管状态:脱离了Session的管理。
标志:有OID,和Session没有关系
删除状态:
标志:有OID,和Session有关系。同时已经调用了删除方法,即将从数据库把记录删除。但是事务还没有提交,此时的对象状态是删除状态。
方法:
close(): Session关闭,Session不可用
clear(): 清空缓存,Session还可以用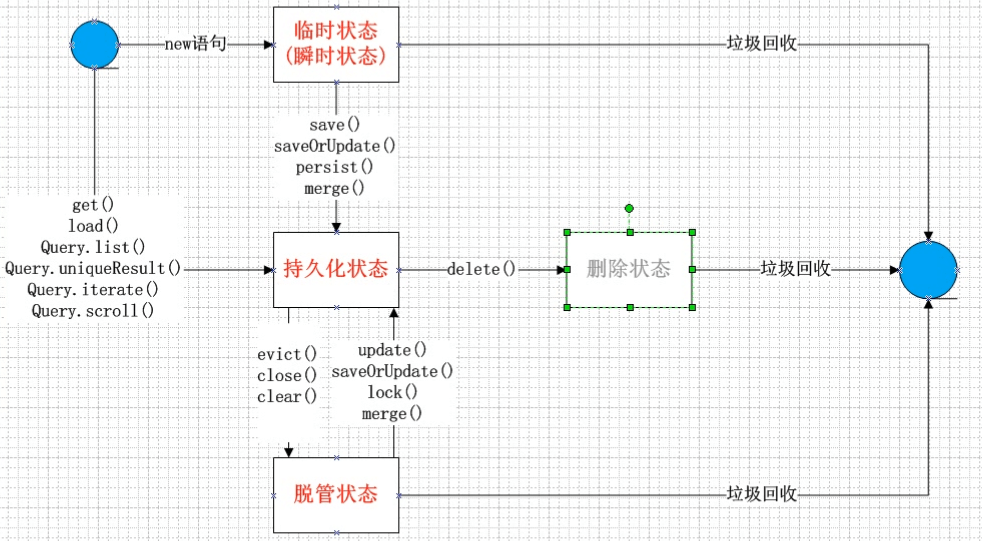
24.hibernate的事务控制
1、解决的问题:让Session对象也符合使用原则
Session对象的使用原则:一个线程只能有一个Session
2、把Session和线程绑定在一起的配置:
需求:验证Session和线程绑定的配置是否成功
代码实现:Hibernate项目 Test.Demo07
当我们把Session和线程绑定之后,hibernate就会在提交或者回滚事务之后,自动帮我们关闭Session。
25.hibernate中的查询方式
查询多条的方式,hibernate一共有5中查询方式。
? : 给参数占位符赋值时,从0开始。
1、OID查询:
根据id查询一个实体。
涉及的方法:get,load
2、SQL查询:
使用SQL语句查询数据库。
涉及的方法:
第一种:SQLQuery(不怎么用)
第二种:Session的doWork方法,可以拿到Connection
3、HQL查询:
使用HQL语句查询数据库,Query对象。
4、QBC查询:
使用Criteria对象查询数据库
5、对象导航查询:
当两个实体之间有关联关系时(关联关系可以是4种中的任意一种)
在31.(4)处有讲。
26.hibernate中的Query对象
它是hibernate中HQL查询方式。
A、 如何获取该对象
Session对象的方法
B、 涉及的方法
createQuery(String hql)
C、 方法中的参数含义
SQL:select from cst_customer; select cust_id from cst_customer;
HQL: from Customer select custId from Customer;
HQL语句,是把sql语句的表名换成类名,把字段名换成实体类中的属性名
D、 常用方法说明
返回查询结果集:List list=query.list();
给参数赋值:query.setParameter(int arg0,Object arg1);
query.setParameter(String arg0,Object arg1);
query.setString(int arg0,String arg1);
query.setString(String arg0,String arg1);
设置查询的开始记录索引:setFirstResult(int arg0);
设置每次查询的条数:setMaxResults(int arg0);
返回的结果集是单行单列时,取出结果集: query.uniqueResult()
代码测试:Hibernate项目 Test.Demo08
27.hibernate中的Criteria对象
HQL查询能实现的,使用Criteria查询也能实现,反之亦然。
但是在Hibernate官网上,推荐使用的是HQL查询方式。
概述:它是hibernate中的QBC查询方式
A、如何获取该对象?
session.createCriteria(Class clazz);
B、涉及对象的方法:
createCriteria(Class clazz);
C、参数的含义:
要查询的实体类的字节码
D、常用方法说明
(1)为参数添加条件:
criteria.add(Restrictions.eq(等于)/gt(大于)/ge(大于等于)/lt(小于)/le(小于等于)/like(像)/between(在..之间)(“属性名称”,”值”));
(2)添加排序条件:
desc :降序
criteria.addOrder(Order.desc(“属性名称”));
(3)
设置查询的开始记录索引:setFirstResult(int arg0);
设置每次查询的条数:setMaxResults(int arg0);
(4)设置使用的聚合函数:
Criteria.setProjection(Projection arg0);
参数的使用:
Projections.rowCount(); 等同于count()
根据某个字段计算总数:Projections.count(“属性名”);
(5)返回的结果集是单行单列时:criteria.uniqueResult();
E、DetachedCriteria对象,该对象的获取不需要Session,可以直接得到。我们使用此对象实现的查询,称之为离线查询。和criteria添加参数的方法是一样的。
代码测试:Hibernate项目 Test.Demo09
28.分页查询(此处使用的是HibernateTemplate对象)
(1)使用离线查询DetachedCriteria对象(简单的单表分页查询)
1、创建DetachedCriteria对象
DetachedCriteria dCriteria=DetachedCriteria.forClass(类名.class);
2、添加条件(以下方法综合使用)
(1)使用复合函数
dCriteria.setProjection(Projections.XXX());
(2)为实体类的属性添加值
dCriteria.add(Restrictions.eq(等于)/gt(大于)/ge(大于等于)/lt(小于)/le(小于等于)/like(像)/between(在..之间)(“属性名称”,”值”));
(3)添加排序条件(desc:降序)
dCriteria.addOrder(Order.desc(“属性名”));
3、开始查询
hibernateTemplate.findByCriteria(dCriteria,开始查询记录索引,每次查
询的个数);
(2)使用execute方法(复杂的多表关系分页查询)
1、编写PageHibernateCallback类实现HibernateCallback
2、熟练写出多表关系的HQL语句
多表查询的HQL语句,使用join关键字
例如:select count(*) from Product p where p.categorysecond.category.cid=? 查询的是:cid为某值时,p表中数据的总个数
例如:select p from Product p join p.categorysecond cs join cs.category
c where c.cid=?
3、开始查询
hibernateTemplate.execute(new PageHibernateCallback
new Object[]{参数值1,参数值2,..},查询的开始记录索引,每次查询的个数));
28.数据库表的关系
一对一
一对多(多对一)
多对多
29.如何确立和实现数据库中的表关系
一对多的表关系在数据库中如何实现?
使用外键约束
我们一般习惯把一的一方称为主表,多的一方称为从表。
什么是外键?
从表中有一列,该列的取值除了null之外,只能来源于主表的主键。
默认情况下,外键的字段的值是可以重复的。
多对多的表关系在数据库中如何实现?
使用中间表
中间表只有两个主键,引用两个多对多表的主键。
不能有其它字段信息,至于中间表的主键,应该使用联合主键
任何一个多方的表和中间表去比较,都是一对多的关系。
一对一的表关系在数据库中如何实现?
第一种:
使用外键约束,唯一约束,非空约束。
它是把外键字段加了非空和唯一约束,从而实现了一对一。
第二种:
使用主键的方式
让从表的一个字段既是主键,又是外键
如何确立两张表之间的关系:
找外键。
此种方法能确立表关系中90%的情况,剩余的10%请听项目阶段的打断设计。
30.学习多表映射配置要遵循的步骤
1、确定2张表之间的关系
2、在数据库中实现2张表之间的关系建立
3、在实体类中描述出2个实体之间的关系
4、在映射配置文件中建立2个实体和2张表之间的关系
31.一对多关系映射配置和操作
例子:客户和联系人2张表
第一步:确定两张表之间的关系
一个客户可以包含多个联系人
多个联系人可以属于同一个客户
所以:客户和联系人之间的关系是一对多。
第二步:在数据库中实现2张表之间的关系建立
实现一对多的关系,靠的是外键。
客户表是主表,联系人表是从表
我们需要在联系人表中添加外键
第三步:在实体类中描述出2个实体之间的关系
主表实体类应该包含从表实体类的集合引用
从表的实体类应该包含主表实体类的对象引用
代码实现:Hibernate项目 Domain.LinkMan Domain.Customer
第四步:在映射配置文件中建立2个实体和2张表之间的关系
代码测试:Hibernate项目 hibernate.cfg.xml LinkMan.hbm.xml
(1)一对多关系映射的保存操作(增)
建立双向关联关系的原则:
先保存主表实体,再保存从表实体
代码测试:Hibernate项目 OnetoMany.Demo01
(2)一对多关系映射的更新操作(改)
需求:级联更新。创建新的联系人,查询一个已有的客户,建立新联系人和客户的双向关系,并更新客户。
说明:实则不改变客户信息,而是在数据库中添加了一条新的联系人记录,并与客户关联了起来。
代码测试:Hibernate项目 OnetoMany.Demo02
(3)一对多关系映射的删除操作(删)
1.删除从表数据,也就是单表操作
2.删除主表数据:
看有没有从表数据引用?
有引用:
(1) 在删除时,hibernate会把表中的外键置为null,然后再删除主表的数据
(2) 如果外键有非空约束,则hibernate不能更新外键字段为null,会报错
(3) 如果仍想删除,此时需要使用级联删除(要慎重使用),必须配置inverse的值为true,往cascade添加delete,用逗号隔开。
没有引用:就是直接删除主表数据,即单表删除操作。
需求:级联删除。删除有从表引用的主表数据。
说明:删除主表,同时也会删除引用了主表的从表数据
代码测试:Hibernate项目 OnetoMany.Demo03
(4)一对多关系映射的查询操作(查)
1、对象导航查询的使用:
当两个实体之间有关联关系时(关联关系可以是4种中的任意一种)
通过getXXX方法即可实现查询功能。(功能是由hibernate提供的)
例如:
customer.getLinkMans():得到当前客户下的所有联系人
linkman.getCustomer(): 得到当前联系人的所属客户
案例1:查询id为1的客户下所有的联系人
代码实现:Hibernate项目 OnetoMany.Demo04 test1()
案例2:查询id为5的联系人所属的客户
代码实现:Hibernate项目 OnetoMany.Demo04 test2()
2、对象导航查询的细节
(1)主表配置文件:(set标签)
只管查询关联的集合对象是否是延迟加载
lazy属性:
false:立即加载
true: 延时加载(默认值)
(2)从表配置文件:(many-to-one标签)
只管查询的关联主表实体是否是立即加载
lazy属性:
false:立即加载
proxy: 是看load方法是延迟加载还是立即加载。load方法默认是延迟加载。
改为“立即加载”的方式:
找到查询实体的映射配置文件,它的class标签上也有一个lazy属性。
只管load方法是否是延迟加载
true: 延迟加载(默认值)
false:立即加载
no-proxy:
32.多对多关系映射配置和操作
例子:用户和角色
第一步:确定两张表之间的关系
一个用户可以有多个角色
一个角色可以赋予给多个用户
所以用户和角色之间是多对多关系
第二步:在数据库中实现两张表之间的关系建立
在数据库中实现多对多要靠中间表
中间表只能出现用户和角色主键
代码实现:Hibernate项目 Domain.SysUser Domain.SysRole
第三步:在实体类中描述两个实体之间的关系
各自包含对方一个集合引用(Set)
第四步:在映射配置文件中建立两个实体和两张表之间的关系
两张表分别和中间表相比较,都是一对多的关系。
中间表只有两个外键,引用两个主表的主键。
代码实现:Hibernate项目 SysRole.hbm.xml SysUser.hbm.xml
(1)多对多关系映射的保存操作(增)
例子: 创建2个用户和3个角色
让1号用户具备1号和2号角色
让2号用户具备2号和3号角色
保存用户和角色
需求1:正常的保存操作,即一个一个的保存
代码实现:Hibernate项目 ManyToMany.Demo01.test1()
需求2:级联保存
配置:保存哪个实体,就必须在哪个配置文件上配cascade=save-update
代码实现:Hibernate项目 ManyToMany.Demo01.test2() test3()
(2)多对多关系映射的删除操作(删)
注意:在开发中,多对多关系的级联删除是禁止使用的
因为:会将所有关联的数据,全部都给删除。
(3)多对多关系映射的更新操作(改)
与一对多关系的相同
(4)多对多关系映射的查询操作(查)
与一对多关系的相同
JPA(注解描述)
1.JPA的概念以及它和hibernate的规范
JPA:java persistence api java持久化规范
JPA原理:通过xml或注解来描述对象关系的映射,并将运行的实体对象持久化到数据库中
(1)Hibernate实现了jpa
(2)Hibernate有自己独立的操作数据库的方法,也有实现jpa规范来操作数据库的方法。
2. 需要导入的jar包
(1)hibernate-release-5.0.7.Final中的required文件夹内的所有jar包
(2)hibernate-release-5.0.7.Final中的jpa文件夹内的所有jar包
(3)hibernate-release-5.0.7.Final中的log4j文件夹内的所有jar包
(4)mysql-connector-java-5.1.38-bin.jar
3.编写主配置文件
(1)在src下创建一个Folder,名为:META-INF
(2)在META-INF内创建一个persistence.xml
(3)导入schema约束
hibernate-entitymanager-5.0.7.Final.jar下的org.hibernate.jpa包内的: persistence_2_0.xsd
(4)配置持久化单元,可以配置多个,但名称不能重复
name : 用于指定持久化单元名称
transaction-type :指定事务类型
JTA : java transaction api
RESOURCE_LOCAL : 本地代码事务
(5)JTA规范的提供商(可以不写)
(6)指定由JPA注解的实体类的位置(可以不写)
(7)连接数据库的相关配置
代码实现:Hibernate项目 META-INF.persistence.xml
4.编写实体类的注解映射配置
因为使用的是JPA规范,所以必须导入javax.persistence包
@Entity: 表明该类是一个实体类
@Table(name=“表名”) : 建立当前类与数据库表的对应关系
@Id :表明当前属性在数据库表中是主键
@Column(name=”字段名”) : 当前属性与数据库的字段相对应
@GeneratedValue(strategy=””/generator=””) : 指定主键的生成策略
strategy :使用JPA中提供的主键生成策略
AUTO : 下面三个选一个,默认选“TABLE”
IDENTITY : mysql自增长
SEQUENCE : oracal自增长
TABLE :高低位算法
generator : 可以使用Hibernate的主键生成策略
代码实现:Hibernate项目 JPA.Customer
5.编写JPA的工具类
常用方法:
Persistence.createEntityManagerFactory(“持久化单元名称”);
返回类型:EntityManagerFactory
createEntityManager();
返回类型:EntityManager
引用此方法的类型:EntityManagerFactory
代码实现:Hibernate项目 Utils.JPAUtil
6.JPA的单表CRUD操作(增删改查)
常用方法:
添加:persist(Object arg0)
参数:要添加的实体类对象
修改:
1、直接使用实体类的set方法
实际上修改了一级缓存,快照没有改变,两者不一致。
提交事务后,就会更新数据库
2、merge(Object arg0)
合并,两个实体合并
参数:要修改的实体类对象
删除:remove(Object arg0)
参数:要删除的实体类对象
查询:
1、查询一个实体(立即加载)
find(Class clazz,Object arg0)
参数:要查询的实体类对象
2、查询一个实体(延迟加载)
GetReference(Class clazz,Object arg0)
3、查询所有数据
(1)获取Query对象:
createQuery(String jpql)
参数:表名换成类名,字段名换成属性名。
查询所有时,需要使用select 关键字。
select 别名 from 表名 别名;
(2)获取结果集:
返回所有结果:List getResultList();
返回一个结果:Object getSingleResult()
4、条件查询
给占位符赋值:
query.setParameter(int arg0,Object arg1);
参数1:占位符的位置 从1开始
参数2:条件值
代码实现:JPA项目 Test.Demo01
7. 一对多关系映射配置和操作
例子:客户和联系人两张表
一个客户可以有多个联系人,一个联系人只有一个客户
(1)映射配置的步骤:
代码实现:JPA项目 Domain.Customer Domain.LinkMan
1、Customer实体类:
OnetoMany : 建立一对多的关系,一的一方
属性:
1.targetEntity=多的一方的实体类名称.class
与哪个实体类建立关系
2. mappedBy=”从表实体类中主表实体的对象引用名称”
放弃维护权
OrderBy : 查询主表时,从表按照某一字段排序
属性:
value : 从表的数据库字段名。从表按照value值排序。
2、LinkMan实体类:
ManyToOne : 建立多对一的关系。多的一方
属性:
1.targetEntity=一的一方的实体类名称.class
与哪个实体类建立关系
JoinColumn : 添加外键字段
属性:
1.name=”外键字段名称”
指定从表中外键字段的名称
2.referenceColumnName=”主表的主键名称”
指定引用的主键名称
(2)一对多关系映射的保存操作(增)
例子:创建一个客户和一个联系人
建立客户和练习的双向关联关系
先保存客户,再保存联系人
代码实现:JPA项目 OneToMany.Demo01
(3)一对多关系映射的更新操作(改)
例子:创建一个联系人
查询id为3的客户
为这个客户分配分配联系人
更新客户
配置:级联操作哪个类?就在哪个属性上必须配置cascade
值:PERSIST 级联保存,更新
MERGE 级联更新
例如:级联操作LinkMan。就在Customer类的linkman属性上配置
cascade
案例1:级联更新。只需要设置客户和联系人的双向关联关系,不需要手动写更新的语句
代码实现 :JPA项目 OneToMany.Demo02.test1()
案例2: 级联更新。只需要设置联系人的客户是谁(单向关系)。需要写更新联系人的merge语句
代码实现 :JPA项目 OneToMany.Demo02.test2()
(4)一对多关系映射的删除操作(删)
1.删除从表数据,也就是单表操作
代码测试:JPA项目 OneToMany.Demo03.test1()
2.删除主表数据:
看有没有从表数据引用?
有引用:
(1) 在删除时,hibernate会把表中的外键置为null,然后再删除主表的数据
代码测试:JPA项目 OneToMany.Demo03.test2()
(2) 如果外键有非空约束,则hibernate不能更新外键字段为null,会报错
(3) 如果仍想删除,此时需要使用级联删除(要慎重使用),必须配置inverse的值为true,往cascade添加delete,用逗号隔开。
代码测试:JPA项目 OneToMany.Demo03.test3()
没有引用:就是直接删除主表数据,即单表删除操作。
代码测试:JPA项目 OneToMany.Demo03.test4()
(5)一对多关系映射的查询操作(查)
find(): 默认是立即加载
对象导航查询:get方法。默认是延迟加载。使用时才去查询。
配置:fetch属性 (不能修改getReference方法)
EAGER : 立即加载。
设置后,只有一条查询语句。使用了left outer join
LAZY : 延迟加载。
案例1:查询id为3的客户,和客户的所有联系人
代码实现:JPA项目 OneToMany.Demo04.test1()
案例2:查询id为2的联系人,和它所属的客户
代码实现:JPA项目 OneToMany.Demo04.test2()
8. 多对多关系映射配置和操作
例子:用户和角色两张表
一个用户可以有多个角色
一个角色可以赋予给多个用户
所以用户和角色之间是多对多关系
(1)映射配置的步骤:
代码实现:JPA项目 Domain.SysRole Domain.SysUser
1、SysRole实体类:
在JPA中使用Hibernate的主键生成策略:
@GenericGenerator : 声明一个主键生成器
包 :org.hibernate.annotations.GenericGenerator
属性 :
name : 给生成器取个名字
strategy : 指定hibernate中的主键生成策略
@GeneratedValue : 指定主键的生成策略
属性 :
generator : 指定生成器的名称
JoinTable : 添加中间表
属性:
1.name=”中间表的名称”
指定中间表的名称
2.joinColumns=”字段名”
当前实体在中间表的外键字段
类型:JoinColumn[]
@JoinColumn :注解类型
属性:
name : 中间的主键名称
referencedColumnName :
引用多对多表中的主键名称
3.inverseJoinColumns=””
另一个实体在中间表的外键字段
类型:JoinColumn[]
@JoinColumn :注解类型
属性:
name : 中间的主键名称
referencedColumnName :
引用多对多表中的主键名称
2、SysUser实体类:
ManyToMany : 建立多对多的关系
属性:
mappedBy=”另一个实体类中对象引用名称”
放弃维护权利。
(哪个类设置了该属性,就不用在设置中间表的信息)
(2)多对多关系映射的保存操作(增)
例子:创建2个用户
创建3个角色
让1号用户具备1号和2号角色
让2号用户具备2号和3号角色
保存用户和角色
案例1:正常的保存操作,即一个一个的保存
代码实现:JPA项目 ManyToMany.Demo01.test1()
案例2:级联保存
说明:只需要保存一个用户,所有与之有关联的角色和用户都保存了。
配置:两个实体类都要配置cascade=CascadeType.PERSIST
代码实现:JPA项目 ManyToMany.Demo01.test2()
(3)多对多关系映射的删除操作(增)
多对多关系的级联删除,在hibernate和jpa中都不让配置。
案例:级联删除
说明:只需要删除一个用户,所有与之有关联的用户和角色都删除了。
配置:两个实体类都要配置cascade=CascadeType.ALL
代码实现:JPA项目 ManyToMany.Demo02
9.jpa中使用c3p0连接池
在persistence.xml设置
name=:hibernate.connection.provider_class
值:org.hibernate.connection.C3P0ConnectionProvider
案例:验证c3p0连接池是否配置成功
常用方法:
1、Session session=em.unwrap(Session.class);
将em转化为Session类型
2、Session.doWork(new Work(){
public void execute(Connection conn) throws SQLException{
System.out.println(conn.getClass().getName());
}
});
代码实现:JPA项目 Test.Demo02
10.把EntityManager和线程绑定
1、想要通过配置来绑定,不自己写代码,要通过spring加持。
2、想要只通过JPA,必须发布到web应用中,web服务器必须支持jpa
3.自己写代码
代码实现; JPA项目 Utils.JPAUtil
总结
1、最重要的是:映射配置。(jpa注解,xml)
注解用的比较多。
2、对象状态。
3、方法使用熟练
4、配置时可以使用jpa注解,操作时使用hibernate的方法。
例子:对Customer类进行单表操作
(1)在Customer类中进行JPA的注解
(2)src下的hibernate.cfg.xml进行数据库的配置。
特殊:映射文件的配置:
案例1:对数据库进行添加操作
代码实现:JPAandHibernate项目 Test.Dmeo01
案例2:对数据库进行查询操作
代码实现:JPAandHibernate项目 Test.Dmeo02
案例3:对数据库进行更新操作
代码实现:JPAandHibernate项目 Test.Dmeo03
案例4:对数据库进行删除操作
代码实现:JPAandHibernate项目 Test.Dmeo04

若有收获,就点个赞吧
0 人点赞
