第一天:基础知识(重点,内容最多)<br />1、mybatis是什么?<br /> (1)是一个持久层框架,是apache下的顶级项目。Mybatis托管到Goolecode下,再<br /> 后来托管到github下。<br />(2)Mybatis让程序将主要精力放在sql上,通过mybatis提供的映射方式,自由灵<br /> 活生成(半自动化,大部分需要程序员编写sql)满足需求的sql语句。<br /> (3)Mybatis可以将向preparedStatement中的输入参数自动进行输入映射,将查询<br /> 结果集灵活映射成java对象。(输出映射)<br /> <br />2、Mybatis内部流程介绍<br /> (1)SqlMapConfig.xml配置了数据源、事务等mybatis运行环境。<br /> (2)mapper.xml配置映射文件(配置sql语句)<br /> (3)SqlSessionFactory是会话工厂<br /> 作用:根据配置文件创建SqlSession<br /> (4)SqlSession是会话(接口,面向程序员的接口)<br /> 作用:操作数据库(发出sql增删改查)<br /> (5)Executor是执行器(接口,基本执行器,缓存执行器)<br /> 作用:SqlSession内部通过执行器操作数据库<br /> (6)mapped statement是底层封装对象<br /> 作用:对操作数据库存储封装,包括sql语句,输入参数类型,输出结果类型<br /> (7)mysql数据库<br /> <br />3、入门程序<br /> 需求:<br /> 1、根据用户id(主键)查询用户信息<br /> 2、根据用户名称模糊查询用户信息<br /> 3、添加用户<br /> 4、删除用户<br /> 5、更新用户<br /> 步骤:<br /> 第一步:创建java工程(略)<br /> 第二步:加入jar包(略)<br /> 第三步:创建配置文件<br /> (1)在工程下创建一个Source Folder:Config。<br />在Config内创建log4j.properties,SqlMapConfig.xml。<br /> (2)在Config文件夹下创建一个文件夹:sqlmap。里面放:Customer.xml<br />(3)log4j.properties导入mybatis的日志。<br /> ### 设置Logger输出级别和输出目的地 ###<br /> log4j.rootLogger=DEBUG,stdout<br /> 生产环境设置成info或error 在开发环境下日志级别要设置成DEBUG<br /> ### 把日志信息输出到控制台 ###<br /> log4j.appender.stdout=org.apache.log4j.ConsoleAppender<br /> log4j.appender.stdout.layout=org.apache.log4j.PatternLayout<br /> log4j.appender.logfile.layout.ConversionPattern=%5p [%t] - %m%n<br />(4)编写主配置文件SqlMapConfig.xml<br /> 实现:Mybatis_day01项目 Config/SqlMapConfig.xml<br />(5)编写映射文件Customer.xml<br /> 映射文件命名:XXX.xml(原始ibatis命名),mapper代理开发映射文<br /> 件名称叫xxxMapper.xml。 <br /> 标签:<mapper><br /> 属性:namespace 命名空间。<br /> 对sql进行分类化管理,也就是sql隔离。<br /> 注意:使用mapper代理方法开发,namespace有特殊重要的作用。<br /> <br /> 标签:<select><br /> 作用:标签内编写sql查询语句,通过该标签执行sql查询语句<br /> 例如:select * from cst_customer where id=#{id};<br /> 属性:id <br /> 1、通过id标识标签。<br /> 2、将sql语句封装到mappedStatement对象中,<br /> id也称为statement的id<br /> parameterType 指定输入参数的类型。<br /> resultType 指定的就是将单条记录所映射的java对象<br /> <br /> 标签:<insert><br /> 作用:标签内编写sql插入语句,通过该标签执行sql插入语句<br />属性:id <br /> 1、通过id标识标签。<br /> 2、将sql语句封装到mappedStatement对象中,<br /> id也称为statement的id<br /> parameterType 指定输入参数的类型。<br />当指定java对象类型时,#{}中指定对象的属性名,接收的<br />就是java对象的属性值,mybatis通过OGNL获取对象的属<br />性值。<br /> <br />占位符:#{}<br />#{id}:其中的id表示接受输入参数的名称。<br />1、如果输入参数是简单类型,参数名称可以任意。<br /> 2、如果输入参数是java对象类型,参数名称就与对象<br /> 属性名称一致。 <br />${}: 拼接sql串,将接受到参数的内容不加任何修饰拼接在sql中<br /> 1、接受的参数类型为简单类型,必须使用${value}<br /> 2、该符号容易引起sql注入。不建议使用。<br /> 第四步:编写代码<br /> (1)得到主配置文件的输入流<br /> String resource=”SqlMapConfig.xml”;<br /> InputStream in=Resources.getResourceAsStream(resource);<br /> (2)创建会话工厂(SqlSessionFactory)<br /> SqlSessionFactory fatory=new SqlSessionFactoryBuilder().build(in); <br /> (3)创建会话(SqlSession)<br /> SqlSession session=factory.openSession();<br /> <br />4、完成入门程序1<br />需求:根据用户id(主键)查询用户信息<br />代码实现:Mybatis_day01项目 Test.Demo01<br />方法:<br /> selectOne(String statement,Object parameter)<br />参数: <br />第一个参数:statemment的id。写法:namespace+id<br /> 第二个参数:输入参数的赋值 <br />返回值:Object<br /> <br />5、完成入门程序2<br />需求:根据客户名称模糊查询客户信息<br />代码实现:Mybatis_day01项目 Test.Demo02<br />方法:<br /> selectList(String statement,Object parameter)<br />参数:<br />第一个参数:statemment的id。写法:namespace+id<br /> 第二个参数:输入参数的赋值<br />返回值:List<E><br /> <br />5、完成入门程序3<br />需求:添加客户<br />代码实现:Mybatis_day01项目 Test.Demo03<br />方法:<br /> insert(String statement,Object parameter)<br />参数:<br />第一个参数:statemment的id。写法:namespace+id<br /> 第二个参数: 插入的对象名称<br />返回值:int 影响的条数<br /> <br />6、自增主键的返回<br />Mysql自增主键,执行insert提交之前自动生成一个自增主键。<br />通过Mysql函数获取到刚插入记录的自增主键:<br /> SELECT LAST_INSERT_ID() 该语句只适用于自增主键,在Insert语句之后使用。<br />需求:添加客户后,返回自增主键<br />Customer.xml映射文件配置:<br /> 标签:<selectKey><br /> 使用:<insert>标签内<br /> 属性:<br />keyProperty : 将查询到的主键值设置到parameterType指定对象的哪个<br /> 属性<br />order :SELECT LAST_INSERT_ID()执行顺序,相对于insert语句<br />resultType :主键的类型 <br />代码实现:Mybatis_day01项目 Test.Demo03<br /> <br />7、非自增主键的返回(使用uuid())<br /> 使用mysql的uuid()函数生成主键,需要修改表中的id字段尾String类型,长度<br /> 设置成35位。<br /> 查询uuid的语句:SELECT uuid()<br /> Inset语句:insert语句中必须插入主键。<br /> 执行思路:<br /> 先通过uuid()查询到主键,将主键输入到sql语句中。<br /> 执行uuid()的顺序在insert之前。<br /> 需求:添加客户后,返回自增主键<br /> <br />8、完成入门程序4<br />需求:根据用户id(主键)删除用户<br />代码实现:Mybatis_day01项目 Test.Demo04<br />标签:<delete><br />作用:标签内编写sql插入语句,通过该标签执行sql插入语句<br />属性:id (也称为statement的id)<br />1、通过id标识标签。<br />2、将sql语句封装到mappedStatement对象中,<br />parameterType 指定输入参数的类型。<br />方法:<br /> delete(String statement,Object parameter)<br />参数:<br />第一个参数:statemment的id。写法:namespace+id<br /> 第二个参数:删除的对象的id值<br /> <br />8、完成入门程序5<br />需求:根据用户id(主键)更新用户信息<br />代码实现:Mybatis_day01项目 Test.Demo05<br />标签:<update><br />作用:标签内编写sql更新语句,通过该标签执行sql更新语句<br />属性:id (也称为statement的id)<br />1、通过id标识标签。<br />2、将sql语句封装到mappedStatement对象中,<br />parameterType 指定输入参数的类型。<br />方法:<br /> update(String statement,Object parameter)<br /> 创建一个更新对象,必须要设置用户的id。<br />参数:<br />第一个参数:statemment的id。写法:namespace+id<br /> 第二个参数:删除的对象的id值<br />9、mybatis和hibernate本质区别和应用场景<br /> Hibernate:是一个标准ORM框架(对象关系映射)。入门门槛较高,不需要程序员<br /> Sql语句,sql语句自动生成了。对sql语句进行优化、修改比较困难的<br /> 应用场景:适用与需求变化不多的中小型项目,比如:后台管理系统、erp、orm<br /> 、oa<br /> Mybatis:专注sql本身,需要程序员自己编写sql语句,sql修改、优化比较方便<br /> 。mybatis是一个不完全的ORM框架。虽然程序员自己写sql,mybatis<br /> 也可以实现映射(输入、输出映射)<br /> 应用场景:适用于需求变化比较多的项目,比如:互联网项目<br /> <br />企业进行技术选型,以低成本、高回报作为技术选型的原则,根据项目组的技术力<br />量进行选择。<br /> <br />10、SqlSession的应用场合<br /> A、SqlSessionFactoryBuilder<br /> 1、通过SqlSessionFactoryBuilder创建会话工厂SqlSessionFactory<br /> 2、将SqlSessionFactoryBuilder当成一个工具类使用即可,不需要使用单例模式<br /> 管理SqlSessionFactoryBuilder<br /> 3、在需要创建SqlSessionFactory时,只需要new一次SqlSessionFactoryBuilder即可<br /> B、SqlSessionFactory<br /> 1、通过SqlSessionFactory创建SqlSession,使用单例模式管理SqlSessionFactory(工厂一旦创建,使用一个实例)<br /> 2、将来mybatis和spring整合后,使用单例模式管理SqlSessionFactory<br /> C、SqlSession<br /> 1、SqlSession是一个面向用户(程序员)的接口。提供了很多操作数据库的方法:selectOne(返回单个对象)、selectList(返回单个或多个对象)...<br /> 2、SqlSession是线程不安全的,在SqlSession实现类中除了有接口中的方法(操作数据库的方法)还有数据域属性。<br /> 3、SqlSession最佳应用场合在方法体内(线程不安全的最佳应用场合都在方法体内,因为线程访问同一个方法都有不同的内存空间),定义成局部变量使用<br /> <br />11、mybatis开发dao方法<br />(1)原始dao开发方法(程序员需要写dao接口和dao接口的实现类)<br /> 1、创建Dao包,程序员需要Dao接口和Dao接口的实现类<br /> 2、需要向dao实现类中注入SqlSessionFactory,在方法体内通过<br /> SqlSessionFactory创建SqlSession<br /> 代码实现:Mybatis_day01项目 Dao包+Test.CustomerDaoImplTest<br /> 3、问题总结:<br /> (1)接口实现类方法中存在大量的重复代码。<br /> 设想将重复代码提取出来,减轻程序员的工作量。<br /> SqlSession sqlSession=sqlSessionFactory.openSession();<br /> sqlSession.commit();<br /> sqlSession.close();<br /> (2)调用SqlSession的方法时,将statement的id硬编码了。(第一个<br /> 参数)<br /> sqlSession.delete("test.deleteCustomer",id);<br /> (3)调用SqlSession的方法时,第二个参数是Object类型,可以传任何<br /> 类型,即使与形参类型不一致,在编译阶段也不会报错,不利于开发<br />(2)mapper代理方法(程序员只需要写mapper接口,相当于dao接口)<br /> 1、创建Mapper包,编写Mapper接口,不需要编写实现类<br /> (接口命名:xxxMapper.java)<br /> 需要遵循一些开发规范,mybatis就可以自动生成Mapper接口实现类的代理对象。<br /> 开发规范:<br /> 1、在xxMapper.xml中namespace等于Mapper接口地址<br /> <mapper namespace="Mapper.CustomerMapper"><br /> 2、Mapper接口中的方法名和xxMapper.xml中statement的id一致<br /> 3、Mapper接口中的方法形参类型和xxMapper.xml中的statement<br /> 的parameterType指定的类型一致<br /> 4、Mapper接口中的方法返回值类型和xxMapper.xml中的<br /> Statement的resultType指定的类型一致。<br /> 总结:<br /> 以上开发规范主要是对下边的代码进行统一的生成:<br /> sqlSession.selectOne("test.findCustomerById",id);<br /> sqlSession.insert("test.insertCustomer",customer);<br /> 2、编写Mapper.xml映射文件(略)<br /> 3、在主配置文件SqlMapConfig.xml中加载映射文件<br /> <mapper resource="Mapper/CustomerMapper.xml"/> <br /> 4、获取SqlSession和代理对象。<br /> SqlSession sqlSession=sqlSessionFactory.openSession();<br />CustomerMapper customerMapper=sqlSession.getMapper<br />(CustomerMapper.class);<br /> 5、问题总结:<br /> (1)代理对象内部调用selectOne或selectList<br /> 如果Mapper方法返回单个对象,内部就是通过selectOne查询数据库<br /> 如果Mapper方法返回集合对象,内部就是通过selectList查询数据库<br /> (2)Mapper接口方法参数只有一个是否不利于开发?<br /> 系统框架中,dao层的代码是被业务层公用的。即使Mapper方法只 <br /> 有一个参数,可以使用包装类型的bean对象满足不同的业务需求。<br /> 注意:持久层方法的参数可以使用包装类型、map等,但是service<br /> 层的方法建议不要使用包装类型。 <br /> 代码实现:Mybatis_day01项目 Mapper包+Test.CustomerMapperTest<br /> <br />12、SqlMapConfig.xml<br /> Mybatis的全局配置文件SqlMapConfig.xml,配置内容如下:<br /> properties(属性)<br /> settings(全局配置参数)<br /> typeAliases(类型别名)<br /> typeHandlers(类型处理器)<br /> objectFactory(对象工厂)<br /> plugins(插件)<br /> environments(环境集合属性对象)<br /> environment(环境子属性对象)<br /> transactionManager(事务管理)<br /> dataSource(数据源)<br /> mappers(映射器)<br /> <br /> 1、properties(属性)<br /> (1)需求:<br /> 将数据库的连接参数单独配置在db.properties中,在SqlMapConfig.xml中<br /> 加载db.properties的属性值。<br /> (好处:SqlMapConfig.xml不用对数据库连接参数进行硬编码了。其它的<br /> xml文件可以引用该db.properties。)<br /> 实现:Mybatis_day01项目 Config/db.properties<br /> (2)SqlMapConfig.xml的配置:<br /> 1、加载properties文件<br /> 标签:<properties><br /> 属性:resource 指定properties文件的名称 <br /> <properties resource=”properties文件名”></properties><br /> 2、引用properties文件的属性值:<br /> ${属性名} <br />3、在<properties>标签内配置属性名和属性值<br /> 标签:<property><br /> (3)特性:<br /> 1、Mybatis将按照下面的顺序来加载属性:<br /> A、在properties元素体内定义的属性首先被读取<br /> B、然后读取properties元素中的resource或url加载的属性,它会<br /> 覆盖已读取的同名属性。<br /> C、最后读取parameterType传递的属性,它会覆盖已读取的同名属性<br /> <br /> (4)建议:<br /> 不要在properties标签体内添加任何属性值,只将属性值定义在<br /> properties文件中。 在properties文件中定义的属性名要有一定的特<br /> 殊性,如:XXX.xxx<br /> 2、settings(全局参数配置)<br /> Mybatis框架在运行时可以调整一些运行参数,比如:开启二级缓存、延迟加载<br /> 标签:<settings><br />3、typeAliases(类型别名,重点)<br /> 在映射文件中,定义很多的statement,statement需要parameterType指定输入参数的类型、需要resultType指定输出结果映射类型。<br /> 如果在指定类型时输入类型全路径,不方便开发,可以定义一些别名。可以针对parameterType或resultType指定的类型定义一些别名,在mapper.xml中使用别名,方便开发。<br /> (1)Mybatis默认支持的别名<br /> (2)自定义别名<br /> A、别名的定义<br /> 标签:<typeAliases><br /> 1、子标签:<typeAlias> (单个别名的定义)<br /> 属性:<br /> type :类型的路径<br /> alias :别名<br /> 2、子标签:<package> (批量别名的定义)<br /> 属性:<br /> name : 指定包名<br /> (Mybatis自动扫描包中的javabean类,自动定义<br />别名,别名就是类名,首字母大写或小写都行。)<br /> B、引用别名<br /> 直接在要使用别名的地方,填上即可。<br />4、typeHandlers(类型处理器)<br /> Mybatis中通过typeHandlers完成jdbc类型和java类型的转换。<br />通常情况下,Mybatis提供的类型处理器满足日常需要,不需要自定义。<br />5、mappers(映射配置)<br /> 标签:<mappers><br /> 子标签:<mapper> (加载单个映射文件)<br /> 属性:resource 指定映射文件 <br /> class 指定mapper接口的类路径 <br /> 要求:mapper接口的名称和mapper映射文件名称相同且放在<br /> 同一个目录中。<br /> <br /> 前提:mapper接口中的方法遵循mapper代理方法<br /> 子标签:<package> (批量加载映射文件)<br /> 属性:name <br />(指定mapper接口的包名,自动扫描包下所有mapper接口进行加载)<br /> 要求:mapper接口的名称和mapper映射文件名称相同且放在<br /> 同一个目录中。<br /> <br /> 前提:mapper接口中的方法遵循mapper代理方法<br /> <br />13、输入映射<br /> 通过parameterType指定输入参数类型,类型可以是简单类型、hashmap、javabean<br /> 的包装类型。<br /> (1)传递javabean的包装对象<br /> 1、需求:完成用户信息的综合查询,需要传入查询条件很复杂(可能包括<br />用户信息、其它信息、比如商品,订单的)<br /> 2、自定义javabean类<br /> A、针对上面的需求,建议使用自定义javabean,将复杂的查询条件包<br /> 进去。 <br /> B、简单的javabean对象:<br /> Vo : 视图层面的对象<br /> Po : 持久层对象<br /> Pojo :自定义对象<br /> 3、编写mapper.xml<br /> 在CustomerMapper.xml中定义客户信息综合查询(查询条件复杂,通<br />过高级查询进行复杂关联查询)。<br /><br /> 4、编写mapper.java中的方法(必须符合mapper代理开发)<br /> //综合查询<br /> public List<CustomerCustom> findCustomerList(CustomerQueryVo<br /> customerQueryVo) throws Exception;<br /> 5、编写测试代码<br /> <br /> <br />14、输出映射<br /> (1)resultType<br /> 1、返回javabean对象<br /> A、使用resultType进行输出映射时,只有查询出来的列名和对象中<br />的属性名一致时,该列才能映射成功。<br /> B、如果查询出来的列名和对象的属性名全部不一致时,不会返回对<br />象。<br /> C、如果查询出来的列名和对象的属性名有一个一致,就会返回对象<br /> 2、返回简单类型<br /> 案例:查询客户的列表总数<br /> 步骤:<br /> A、编写mapper.xml<br /> B、编写mapper.java<br /> //客户的列表总数查询<br /> public int findCustomerCount(CustomerQueryVo<br /> customerQueryVo) throws Exception;<br /> C、编写测试代码<br /> 3、小结<br /> A、查询出来的结果集只有一行且一列,这时可以使用简单类型进行映<br />射。<br /> B、不管输出的是单个对象还是一个列表(列表内含有多个对象),在<br /> mapper.xml中resultType指定的类型是一样的。而在mapper.java<br /> 中方法的返回值类型不一样。<br /> 输出单个对象时,方法返回值就是单个对象类型。<br /> 输出对象列表时,方法返回值就是List<对象> <br /> (2)resultMap <br /> Mybatis中使用resultMap完成高级输出结果映射。<br />如果查询出来的列名和对象的属性名不一致,通过定义一个resultMap对列<br />名和对象的属性名之间作一个映射关系 <br /> <br /> 需求:将下列的sql语句使用Customer类完成映射<br /> select cust_id id,cust_name name from cst_customer <br /> where cust_id=#{id}<br /> 1、编写mapper.xml<br /> 1、定义resultMap<br /> 标签:<resultMap><br /> 1、属性:<br /> type :映射的java对象类型。可以使用别名<br /> id : 对resultMap的唯一标识<br /> 2、子标签:<br /> (1)<id/> :指定查询列中的唯一标识,如果有多个<br /> 列组成唯一标识,配置多个id<br /> 属性:<br /> column :查询出来的列名<br /> property :type指定的javabean的属<br /> 性名<br /> (2)<result/> :对普通列的映射<br /> 属性:<br /> column :查询出来的列名<br /> property :type指定的javabean的属<br /> 性名<br /><br /> 2、使用resultMap作为statement的输出映射类型<br /> A、在同一个mapper文件中,引用定义的resultMap的id即<br />可。<br /> B、如果定义的resultMap在其它的mapper文件中,引用<br />resultMap时,前边要加入namespace。<br /> 2、编写mapper.java<br /> //使用resultMap作为输出映射<br /> public Customer findCustomerByIdResultMap(int id) throws <br /> Exception;<br /> 3、编写测试代码<br /> 和根据id查询用户是一样的。(此处略)<br />15、动态sql<br /> 概述:Mybatis核心就是对sql语句进行灵活操作,通过表达式进行判断,对sql进<br />行灵活拼接、组装。<br /> 需求1:客户信息综合查询列表和客户信息查询列表总数这两个statement的定义使<br /> 用动态sql。<br /> 1、对查询条件进行判断,如果输入参数不为空才进行查询条件拼接。<br /> A、编写mapper.xml<br /> 标签:<where> :可以自动去掉条件中的第一个and<br /><if><br /> 属性:test 判断条件<br />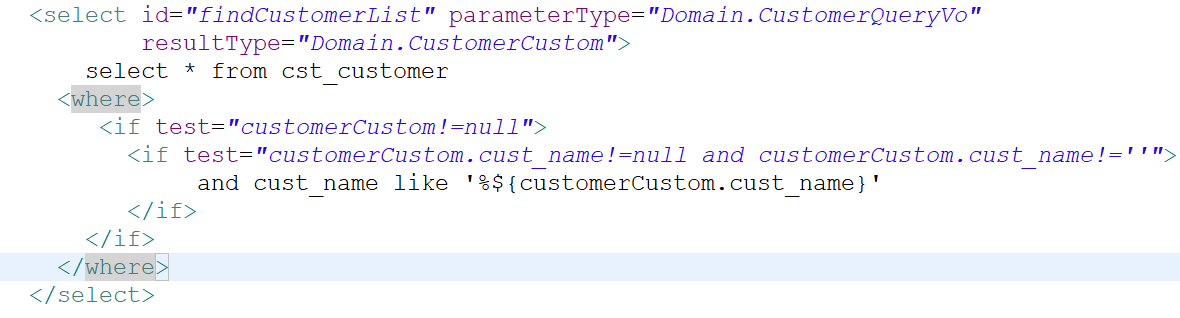<br /> B、编写mapper.java<br /> C、编写测试代码<br /><br /> 需求2:将上边实现的动态sql判断抽取出来,组成一个sql片段。其它的statement<br /> 中就可以引用该sql片段。<br /> 1、在mapper.xm中定义sql片段<br /> 标签:<sql><br /> 属性:id 唯一标识sql片段<br /> 注意事项:<br />(1)是基于单表来定义sql片段,这样的sql片段可重用性才高。<br />(2)在sql片段中不要包括<where>标签。<br /><br /> 2、在mapper.xml中的statement中引用sql片段<br /> 方法:在<where>标签中引用sql片段<br /> 标签:<include> 在<where>标签内使用<br /> 属性:refid 指定要引用的sql片段的id<br /> 如果sql片段不在同一个文件中,需要加入namespace。<br /><br /> 3、编写测试代码(同上,略)<br /> <br />需求3:在用户查询列表和查询总数的statement中增加多个id输入查询<br /> Sql语句如下:<br /> Select * from cst_customer where cust_id=1 or cust_id=10;<br /> Select * from cst_customer where cust_id in(1,10);<br /> 1、在输入参数类型中添加List<Integer> ids,用来传入多个id<br /> <br />2、 编写mapper.xml(需要修改sql片段)<br />标签:<foreach><br /> 属性:<br /> collection :指定输入对象中集合属性的变量名<br /> item :每次遍历生成对象中的变量名<br /> open :开始遍历时要拼接的字符串<br /> close :结束遍历时要拼接的字符串<br /> separator :两个变量中间需要拼接的字符串<br /><br />3、 编写mapper.java(略)<br />4、 编写测试代码<br /><br /> 第二天<br />1、数据库表之间的关系分析<br /> cst_customer 和 orders:<br /> cst_customer-->orders : 一个用户可以创建多个订单,一对多<br /> orders--> cst_customer : 一个订单只由一个用户创建,一对一<br /> <br /> orders 和 orderdetail:<br /> orders-->orderdetail : 一个订单可以包括多个订单明细,因为一个订单里可以<br /> 有多个商品,每个商品的购买信息在orderdetail记录<br /> 一对多<br /> orderdetail-->orders : 一个订单明细只能包括在一个订单中,一对一<br /> <br /> orderdetail 和 items:<br /> orderdetail-->items : 一个订单明细只对应一个商品信息,一对一<br /> items-->orderdetail : 一个商品可以包括在多个订单明细中,一对多<br /> <br /> orders 和 items:<br /> orders-->items : 一对多<br /> items-->orders : 一对多<br /> 所以:orders和 items是 多对多关系。<br /> <br /> cst_customer 和items:<br /> cst_custoemr-->items : 一对多<br /> items-->cst_customer : 一对多<br /> 所以:cst_customer 和 items是 多对多关系。<br /> <br />2、一对一查询<br /> 需求:查询订单信息,关联查询创建订单的用户信息<br /> (1)resultType<br /> A、编写sql语句<br /> 确定主查询表:订单表<br /> 确定查询的关联表:客户表<br /> 关联查询使用内连接?还是外连接?<br /> 由于orders表中有一个外键(cust_id),通过外键关联查询用户表<br /> 只能查询出一条记录,可以使用内连接。<br />SELECT orders.*,cst_customer.`cust_name`,cst_customer.`cust_phone`<br />FROM orders,cst_customer<br />WHERE orders.`cust_id`=cst_customer.`cust_id`<br /> B、创建javabean对象<br /> 将上面的sql查询的结果映射到javabean对象中,对象中必须包含所有<br /> 查询列名。<br /> 原始的Orders.java不能映射全部字段,需要创建新的javabean。<br />创建一个类继承包括查询字段较多一个类。 <br />B、编写mapper.xml<br /><br />C、编写mapper.java<br /> public List<OrdersCustom> findOrdersCustomer() throws Exception;<br />D、编写测试代码 <br /> (2)resultMap<br /> A、编写sql语句<br /> 同上<br /> B、编写mapper.xml<br /> 使用resultMap将查询结果中的订单信息映射到Orders对象中,在<br /> Orders类中添加customer属性,将关联出来的用户信息映射到Orders<br />对中的customer属性中。<br /> 需要向Orders类中添加customer属性:<br /> <br /> 1、定义resultMap<br /> (1)配置要映射的订单信息[主查询对象和主查询表](略)<br /> (2)配置映射的关联的用户信息(关联查询的对象和表)<br />标签:<association> 用于映射关联查询单个对象的信息<br /> 属性:<br />property :指定关联查询对象在主查询对象<br />中的属性名称<br /> javaType :关联查询对象的全限定类名<br /> 子标签:<br /> <id/> 指定关联查询用户的唯一标识<br /> 属性:<br /> column : 用来唯一标识关联查询表的列名<br /> property : 指定唯一标识关联查询表的<br />列名所对应的属性名称<br /><br />2、编写<select>标签语句<br /> <br /> C、编写mapper.java<br /> public List<Orders> findOrdersCustomerResultMap()<br />throws Exception;<br />D、编写测试代码 <br /> (3)resultType和resultMap实现一对一查询的小结<br /> 实现一对一查询查询:<br /> resultType :使用resultType实现较为简单,如果javabean对象没有<br /> 包括查询出来的列名,需要增加对应的属性,就可以完成<br /> 映射。<br /> 如果对查询结果没有特殊要求,建议使用resultType。<br /> resultMap : 需要单独定义resultMap,实现有点麻烦。如果对查询结<br /> 果有特殊的要求,使用resultMap可以完成将关联查询映<br /> 射到javabean类的属性中。<br /> resultMap可以实现延迟加载,resultType无法实现。<br /> <br />3、一对多查询<br /> 需求:查询订单及订单明细的信息<br /> A、编写sql语句<br /> 确定主查询表:订单表<br /> 确定关联查询表:订单明细表<br /> 在一对一的查询基础上添加订单明细表关联即可:<br /> SELECT<br />orders.*,cst_customer.`cust_name`,cst_customer.`cust_phone`,<br />orderdetail.`items_id`,orderdetail.`item_num`,<br />orderdetail.`orders_id`,orderdetail.`id` orderdetail_id<br />FROM orders,cst_customer ,orderdetail<br />WHERE orders.`cust_id`=cst_customer.`cust_id`<br />AND orderdetail.`orders_id`=orders.id <br /> B、分析<br /> 使用resultType将上边的查询结果映射到javabean中,订单信息是重复的。<br /> 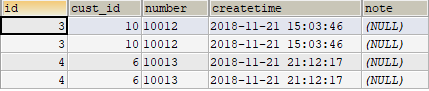<br /> C、要求<br /> 对Orders映射不能出现重复记录。<br /> 在Orders.java中添加List<Orderdetail> orderdetails属性。<br /> 最终会将订单信息映射到Orders类中,订单所对应的订单明细映射到Orders<br /> 类中的orderdetails属性中。<br /><br /> 映射成的orders记录数为2条(orders信息不重复)<br /> 每个Orders中的orderdetails属性存储了该订单所对应的订单明细。<br /> D、在Orders.java中添加List<Orderdetail> orderdetails属性<br />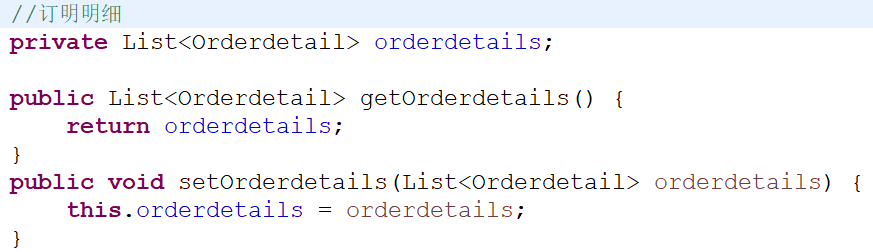<br /> E、编写mapper.xml<br />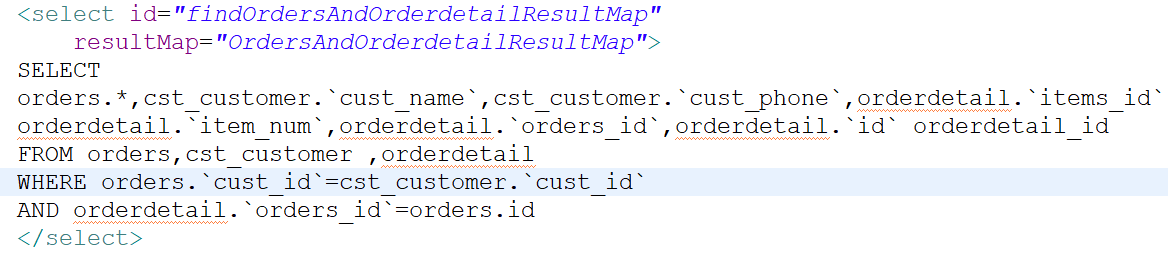<br /> F、定义resultMap<br /> (1)订单信息和用户信息(同上)<br /> 此处可以使用继承。<br /> <resultMap>的属性:<br /> extends : 继承resultMap<br /> (2)订单明细信息<br /> 一个订单关联查询到了多条订单明细,要使用<collection>进行映射。<br /> 标签:<collection> 对关联查询到的多条记录映射到集合对象中<br /> 属性:<br /> property : 对应关联查询到的多条记录映射到主查询对象<br />中对应的属性名称<br /> ofType : 指定映射到的集合属性的对象类型<br /> 子标签:<id> 指定关联查询订单明细的唯一标识<br /> 属性:<br /> column :指定关联查询对象的唯一标识<br /> property : 唯一标识在java对象中对应的属性名<br /> F、编写mapper.java<br /> public List<Orders> findOrdersAndOrderdetailResultMap()<br />throws Exception;<br /> G、编写测试代码<br /><br /> H、小结<br /> Mybatis使用resultMap的collection对关联查询的多条记录映射到一个<br /> List集合属性中。<br /> 使用resultType实现:<br /> 将订单明细映射到Orders类中的orderdetails属性中,需要自己处理,<br /> 使用双重循环遍历,去掉重复记录,将订单明细放在orderdetails中。<br /> <br />4、多对多查询<br /> 需求:查询用户和用户购买的商品信息<br /> (1)编写sql语句<br /> 查询的主表:客户表<br /> 关联表:由于客户和商品没有直接关联,通过订单和订单明细进行关联。所以<br /> 关联表是:orders,orderdetail,items。<br /> SELECT<br />orders.*,cst_customer.`cust_name`,cst_customer.`cust_phone`,<br />orderdetail.`items_id`,orderdetail.`item_num`,<br />orderdetail.`orders_id`,orderdetail.`id` orderdetail_id,<br />items.`name` items_name,items.`price` items_price<br />FROM orders,cst_customer ,orderdetail,items<br />WHERE orders.`cust_id`=cst_customer.`cust_id`<br />AND orderdetail.`orders_id`=orders.id<br />AND items.`id`=orderdetail.`items_id`<br /> (2)映射思路<br /> 将客户信息映射到Customer中。<br /> A、在Customer类中添加订单列表属性List<Orders> orders,将用户创建的<br /> 订单映射到orders中<br /> B、 在Orders类中添加订单明细列表属性List<Orderdetail> orderdetails,<br /> 将订单明细映射到orderdetails<br /> C、在Orderdetail类中添加items属性,将订单明细所对应的商品映射到<br /> Items。<br /> (3)编写mapper.xml<br />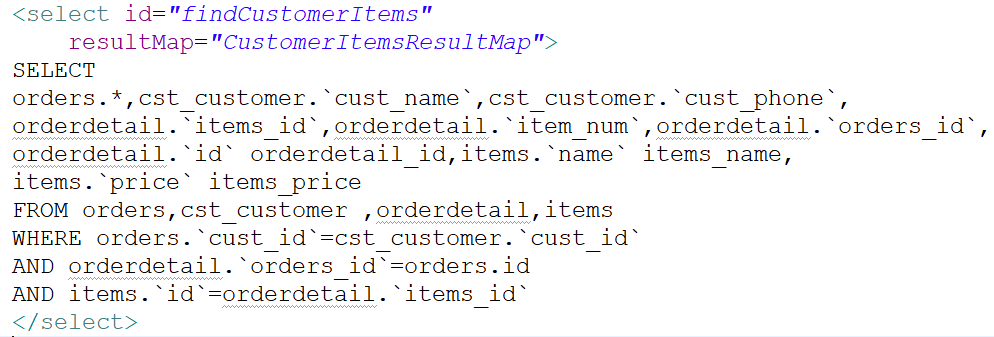<br /> (4)定义resultMap<br /> A、映射用户信息(略)<br /> B、映射订单信息(略)<br /> 一个用户有多个订单,使用collection映射。<br /> C、映射订单明细<br /> 一个订单包括多个订单明细,使用collection映射。<br /> 该collection标签使用在订单的collection内部。<br /><br /> D、映射商品信息<br /> 一个订单明细对应一个商品,使用association映射。<br /> 该<association>使用在订单明细的collection内部。<br /><br /> (5)编写mapper.java<br /> public List<Customer> findCustomerItems() throws Exception;<br />(6)编写测试代码 <br /> <br />5、延迟加载<br /> 概述:resultMap可以实现高级映射(使用association、collection实现一对一及一<br />对多映射),association、collection具备延迟加载功能。<br /> 需求:如果查询订单并且关联查询客户信息。如果先查询订单信息即可满足要求,当我<br /> 们需要查询客户信息时再查询客户信息,把对客户信息的按需查询称为延迟加载 优点:先从单表查询,需要时再从关联表去关联查询,大大提供数据库性能,因为查询<br /> 单表要比关联查询多张表速度要快。<br /> (1)使用association实现延迟加载<br /> 需求:查询订单并且关联查询客户信息<br /> A、编写mapper.xml<br /> 需要定义两个对应的statement<br /> 1、只查询订单信息<br /> Sql语句:Select * from orders<br /> (1)statement语句<br /><select id="findOrdersCustomerLazy"<br />resultMap="OrdersCustomerLazy"><br /> select * from orders<br /> </select><br /> (2)resultMap映射订单信息<br /><id column="id" property="id"/><br /> <result column="note" property="note"/><br /> <result column="cust_id" property="cust_id"/><br /> <result column="number" property="number"/><br /> <result column="createtime" property="createtime"/><br /> 在查询订单的statement中使用association去延迟加载下边的<br /> Statement(关联查询客户信息)<br />2、关联查询客户信息<br /> 通过上边查询到的订单信息中cust_id去关联查询客户信息<br /> (1)resultMap延迟加载客户信息<br /> 标签:<association><br /> 属性:<br /> select :指定延迟加载需要需要执行的statement的id<br /> 如果要引用的statement不在同一文件,需要在<br /> 前面加namespace<br /> column :主查询表中关联查询表的列名 <association property="customer"<br />javaType="Domain.Customer"<br />select="Mapper.CustomerMapper.findCustomerById" column="cust_id"><br /></association><br /><br /> B、编写mapper.java(略)<br /> C、配置延迟加载<br /> 在SqlMapConfig.xml中配置。(配置properties属性之后) <br /> D、编写测试代码<br /> 思路:<br /> 1、执行上边的mapper方法(FindOrdersCustomerLazy),内部去调<br /> 用对应statement的语句,只查询单表。<br /> 2、在程序中,去遍历查询到的Orders,当我们调用Orders中的<br /> getCustomer方法时,开始进行延迟加载。<br /> 3、延迟加载,去调用CustomerMapper.xml中findCustomerById这<br /> 个方法获取客户信息。<br /> F、总结:使用延迟加载,先去查询简单的sql(最好单表,也可以关联查询),<br /> 再去按需加载关联查询的其它信息(其它表)<br /> <br />6、查询缓存<br /> 作用:Mybatis提供查询缓存,用于减轻数据库压力,提供数据库性能<br /> 分类:一级缓存和二级缓存<br />概述:<br />(1)一级缓存是SqlSession级别的缓存<br />在操作数据库时需要构造SqlSession对象,在对象中有一个数据结构<br />(HashMap)不同的SqlSession之间的缓存区域(HashMap)是互不影响的。<br /> (2)二级缓存是mapper级别的缓存<br /> 多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可<br /> 以共用二级缓存,二级缓存是跨SqlSession的。<br /> <br />7、一级缓存<br />(1)工作原理<br /> A、第一次发起查询客户id为1的操作,先去找缓存中是否有id为1的客户信息,<br /> 如果没有,从数据库中查询客户信息。得到客户信息,将客户信息存入一级缓存<br /> 中。<br /> B、第二次发起查询客户id为1的操作,先去找缓存中是否有id为1的客户信息,<br /> 缓存中有,直接从缓存中获取客户信息。<br /> C、如果SqlSession去执行commit操作(插入、删除、更新),清空SqlSession中<br /> 的一级缓存。目的:为了让缓存中存储的都是最新的数据,避免出现脏读。<br />(2)测试<br /> Mybatis默认支持一级缓存,不需要配置任何东西。<br /> 需求:按照上边的工作原理进行测试。<br /> 代码实现:Mybatis_day02项目 Test. OrdersMapperCustomTest.testCache1()<br />(3)实际应用<br /> 正式开发,是将mybatis和spring整合开发,事务控制是在service层中。<br /> (1)在Service层中的一个方法内<br />Service{<br /> //开始执行时,开启事务,创建SqlSession对象<br /> //第一次调用mapper的方法findCustomerById<br /> ... ...<br /> //第二次调用,从一级缓存中取数据<br /> //方法结束,SqlSession关闭<br />}<br /> (2)在Service层中的两个方法内<br /> Service{<br /> //开始执行时,开启事务,创建SqlSession对象<br /> //第一次调用mapper的方法findCustomerById<br /> ... ...<br />//方法结束,SqlSession关闭<br />}<br />Service{<br /> //开始执行时,开启事务,创建SqlSession对象<br /> //第二次调用mapper的方法findCustomerById<br /> ... ...<br />//方法结束,SqlSession关闭<br />}<br />如果是执行两次service调用查询相同的客户信息,不走一级缓存,因为<br />方法结束,SqlSession就关闭,一级缓存就会清空。<br /> <br />8、二级缓存<br />(1)原理:(SqlSession关闭后,才会将查询到的数据存入到二级缓存中)<br />1、sqlSession1去查询客户id为1的客户信息,查询到客户信息会将查询数<br /> 据存储到二级缓存中。<br /> 2、sqlSession3去执行相同mapper下的commit操作,就会清空该mapper二<br /> 级缓存。<br /> 3、sqlSession2去查询客户id为1的客户信息,去缓存中找是否存在数据,<br /> 如果存在直接从二级缓存中取出数据。<br />(2)区别:<br />1、二级缓存的范围更大,多个SqlSession可以共享一个mapper的二级缓存<br />2、其它的mapper也有自己的二级缓存,根据namespace区分的。即每一个<br />namespace的Mapper有一个二级缓存区域。<br /> 3、两个mapper的namespace如果相同,这两个mapper执行sql查询到数据<br /> 将存在相同的二级缓存区域中。 <br />(3)测试<br /> A、开启二级缓存<br /> Mybatis的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级<br />缓存的总开关,还要在具体的mapper.xml中开启二级缓存。<br /> 在SqlMapConfig.xml中配置:(可以不设置,默认值为true)<br /> <setting name=”cacheEnabled”value=”true”><br /> 在mapper.xml中配置:<br /><cache/><br /> B、相应的javabean类要实现序列化接口<br /> 为了将缓存数据取出执行反序列化操作。因为二级缓存数据的存储介质多种多<br /> 样,不一定在内存。<br /> C、编写测试方法<br /> 代码实现:Mybatis_day02项目 Test.OrdersMapperCustomTest.testCache2()<br />(4)参数<br /> A、禁用二级缓存<br /> 概述:在statement中设置useCache=false可以禁用当前select语句的二级<br />缓存,即每次查询都会发出sql语句,默认值是true,即该sql使用二级<br />缓存。<br /> 使用范围:每一个<select>标签<br />属性:useCache<br /> 总结:针对每次查询都需要最新数据的sql,就必须要禁用二级缓存。<br /> B、刷新缓存(清空缓存)<br /> 概述:在mapper的同一个namespace中,如果有其它insert、update、delete操<br />作数据后就需要刷新缓存,如果不执行刷新缓存就会出现脏读。<br />设置statement配置的flushCache=true,默认情况下为true即刷新缓存,<br />如果改成false则不会刷新,使用缓存时如果手动修改数据表中的数据就会<br />出现脏读。<br /> 总结:一般情况下,不需要修改该配置。<br /> <br />9、Mybatis整合ehcache<br /> Ehcache是一个分布式缓存框架。<br />(1)分布缓存<br /> 我们系统为了提供系统并发、性能,一般对系统进行分布式部署(集群部署方式)<br /> 对缓存数据进行集中管理(redis集群)<br /> 使用分布式缓存框架:redis、memcached、ehcache<br /> 不使用分布缓存,缓存的数据会在各自的服务器存储,不方便系统开发。所以要使<br /> 用分布式缓存对缓存数据进行集中管理。<br /> Mybatis无法实现分布式缓存,需要和其它分布式缓存框架进行整合。<br />(2)整合方法<br /> Mybatis提供了一个cache接口,如果要实现自己的缓存逻辑,实现cache接口即<br /> 可。<br /> Mybatis和ehcache整合,mybatis和ehcache整合包中提供了一个cache接口的<br /> 实现类<br /> Mybatis默认实现的cache类:PerpetualCache<br /> 标签:<cache><br /> 属性:type :<br />指定cache接口的实现类的类型 默认使用PerpetualCache类<br /> 要和ehcache整合,需要配置ehcache实现cache接口的类型<br />(3)加入ehcache包(略)<br />(4)整合ehcache<br /> 配置<cache/>的type属性为ehcache实现类即可。<br /> <cache type="org.mybatis.caches.ehcache.EhcacheCache"/><br />(5)加入ehcache的配置文件<br /> 第一步:在config路径下创建ehcache.xml<br /> 第二步:引入缓存配置文件<br /> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"<br /> xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"<br /> updateCheck="false"><br /> <diskStore path="I:\ehcache"/> <br /> <defaultCache<br /> maxElementsInMemory="1000"<br /> maxElementsOnDisk="1000000"<br /> eternal="false"<br /> timeToIdleSeconds="120"<br /> timeToLiveSeconds="120"<br /> diskExpiryThreadIntervalSeconds="120"<br /> memoryStoreEvictionPolicy="LRU"><br /> </defaultCache><br /></ehcache><br /> maxElementsInMemory:缓存最大个数。 eternal:对象是否永久有效,一但设置了,timeout将不起作用。 timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当<br />eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲<br />置时间无穷大。 timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介<br />于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默<br />认是0,也就是对象存活时间无穷大。 overflowToDisk:当内存中对象数量达到maxElementsInMemory时,Ehcache<br />将会对象写到磁盘中。 maxElementsOnDisk:硬盘最大缓存个数。 memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将<br />会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你<br />可以设置为FIFO(先进先出)或是LFU(较少使用)。 <br /> <br />10、二级缓存的应用场景<br /> 对于访问多的查询请求且用户对查询结果实时性要求不高,此时可以采用mybatis 的二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统<br /> 计分析sql、电话账单查询sql等。<br /> 实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,<br /> 根据数据变化频率设置缓存刷新间隔,比如设置为30分钟、60分<br /> 钟、24小时等,根据需求而定。<br /> <br />11、spring和mybatis整合<br /> (1)整合思路:<br /> 需要spring通过单例方式管理SqlSessionFactory<br /> Spring和Mybatis整合生成代理对象,使用SqlSessionFactory创建<br /> SqlSession。(spring和mybatis整合自动完成)<br /> 持久层的mapper都需要spring进行管理。 <br /> (2)整合环境<br /> A、jar包<br /> 1、Mybatis 3.2.7的jar包<br /> 2、Spring的jar包<br /> 3、Spring和Mybatis的整合包,以前ibatis和spring整合是由spring<br /> 官方提供,mybatis和spring整合由mybatis提供。<br /> B、在config下创建spring文件夹,在spring内创建applicationContext.xml<br /> (3)配置SqlSessionFactory和dbcp连接池<br /> 方法:在applicationContext.xml中配置,由spring来管理<br /><br /> (4)原始dao开发(和spring整合后)<br /> A、mapper.xml<br /> 在Config/sqlmap下创建对应javabean的映射配置文件<br /> 命名和类名相同<br /> <br /> 在SqlMapConfig.xml中加载mapper.xml<br /> B、对SqlMapConfig.xml进行修改<br /><br /> <br />C、编写dao接口和dao接口的实现类<br /> (1)dao接口<br /><br /> (2)dao接口的实现类<br /> dao接口的实现类去继承SqlSessionDaoSupport,dao接口的实<br /> 现类就不用声明SqlSessionFactory类型的变量。而是直接可以<br /> 通过getSqlSession()方法获取SqlSession。<br /> Spring管理dao接口的实现类,就不用自己关闭SqlSession,而<br /> 是由Spring自动关闭。<br /><br />(3)配置dao接口实现类的bean<br />dao接口的实现类需要注入SqlSessionFactory,通过spring注入。<br />此处使用xml方式配置dao接口。<br /> <!-- 原始dao --><br /> <bean id="customerDao" class="Dao.CustomerDaoImpl"><br /> <property name="sqlSessionFactory"<br />ref="sqlSessionFactory"></property><br /> </bean><br /> D、编写测试代码<br /><br /> (5)mapper代理开发(和Spring整合后)<br /> A、mapper.xml<br /> 在src/Mapper包内创建对应的映射文件mapper.xml<br /> 命名:类名Mapper.xml<br /> <br /> B、编写mapper.java(略)<br /> C、通过Spring来配置mapper的bean对象<br /> (1) 配置单个mapper接口<br /> bean标签的class:<br />org.mybatis.spring.mapper.MapperFactoryBean<br /> 作用:根据该mapper类可以生成代理对象<br /> bean标签的id:随意<br /> 需要配置两个成员变量:mapperInterface,sqlSessionFactory<br /> mapperInterface的value:对应的自定义mapper接口<br /> sqlSessionFactory的ref:sqlSessionFactory<br /> <br /> 此种配置的问题:需要针对每一个mapper进行单独的配置,麻烦<br /> (2)mapper的批量扫描<br /> 从Mapper包中扫描出mapper接口,自动创建代理对象并且在<br /> Spring容器中注册。<br />如果要扫描多个包,每个包之间用半角逗号隔开。 <br /> bean标签的class:<br /> org.mybatis.spring.mapper.MapperScannerConfigurer<br /> bean标签的id:不需要写上。自动扫描bean的id,id为mapper<br /> 类名(首字母小写)<br /> 需要配置成员变量:basePackage。sqlSessionFactoryBeanName<br /> basePackage : 指定mapper接口的包名,mapper.java和<br /> mapper.xml文件名保持一致,且在一个目<br /> 录中。SqlMapConfig.xml中的配置与这个<br /> 重复,可以删去。<br /> SqlSessioFactoryBeanName :value指定sqlSessionFactory<br />D、编写测试代码<br /><br /> <br />12、逆向工程<br /> 概述:mybatis需要程序员自己编写sql语句,mybatis官方提供逆向工程,可以针对<br /> 单表自动生成mybatis执行所需要的代码(mapper.xml,mapper.java,javabean)<br /> <br /> 企业实际开发中,常用的逆向工程方式:由数据库的表生成java代码<br /> (1)下载逆向工程<br /> 逆向工程就是一个工具。<br /> (2)使用方法(会用)<br /> A、运行逆向工程的几种方式<br /> 建议使用java程序来运行,不依赖开发工具。<br /> B、生成代码配置文件(xml文件)<br /> C、执行生成程序<br /> C、使用生成的代码<br /> 将生成的代码拷贝到自己的工程中去。不要在生成的代码乱加入其它代码。 Mapper.java中的方法:<br /> (1)updateByPrimaryKey(javabean对象)<br /> 对所有字段都更新,需要先查询出来再更新<br /> (2)updateByPrimaryKeySelective(javabean对象)<br /> 对传入字段不为空才更新,不需要先查询<br /> (3)selectByExample(Example对象)<br /> 自定义查询,通过criteria构造查询条件

若有收获,就点个赞吧
0 人点赞
