排序
八排总结
- 冒泡排序: 两两相邻比较,逐渐将小值向上冒泡. O(n)
- 简单选择排序: 比较 2~n 的数确定最小的第一个,比较 3~n 的确定最小的第二个 O(n) 性能比上一个好一点
- 直接插入排序: 比较 n 和前一个(n-1)比较, 然后继续向前比较, 确定前 n 个有序 O(n) 性能比前两个好一点
- 希尔排序: 设定增量,跳跃式比较 增量为n/2 < O(n) 性能比前三个好 但是不稳定
- 堆排序: 构建顶堆 交换 构建顶堆 循环
- 归并排序:
- 快速排序:
一. 归并排序
1. 归并排序
- 整体是递归,左边排好序+右边排好序+merge让整体有序
- 让其整体有序的过程里用了排外序方法
- 利用master公式来求解时间复杂度4)当然可以用非递归实现

- 递归方法实现:
// 递归方法实现public static void mergeSort1(int[] arr) {if (arr == null || arr.length < 2) {return;}process(arr, 0, arr.length - 1);}// arr[L...R]范围上,请让这个范围上的数,有序!public static void process(int[] arr, int L, int R) {if (L == R) {return;}// int mid = (L + R) / 2int mid = L + ((R - L) >> 1);process(arr, L, mid);process(arr, mid + 1, R);merge(arr, L, mid, R);}public static void merge(int[] arr, int L, int M, int R) {int[] help = new int[R - L + 1];int i = 0;int p1 = L;int p2 = M + 1;while (p1 <= M && p2 <= R) {help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];}// 要么p1越界,要么p2越界// 不可能出现:共同越界while (p1 <= M) {help[i++] = arr[p1++];}while (p2 <= R) {help[i++] = arr[p2++];}for (i = 0; i < help.length; i++) {arr[L + i] = help[i];}}
时间复杂度:
%20%3D%20%202T%20(N%2F2)%20%2B%20O(N%5E1)%0A#card=math&code=T%28N%29%20%3D%20%202T%20%28N%2F2%29%20%2B%20O%28N%5E1%29%0A)
log2 == 1 **==>** 时间复杂度为: O(N * logN)
- 非递归方法实现
public static void mergeSort2(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int step = 1;
int N = arr.length;
while (step < N) {
int L = 0;
while (L < N) {
int M = 0;
if (N - L >= step) {
M = L + step - 1;
} else {
M = N - 1;
}
if (M == N - 1) {
break;
}
int R = 0;
if (N - 1 - M >= step) {
R = M + step;
} else {
R = N - 1;
}
merge(arr, L, M, R);
if (R == N - 1) {
break;
} else {
L = R + 1;
}
}
if (step > N / 2) {
break;
}
step *= 2;
}
}
public static void merge(int[] arr, int L, int M, int R) {
int[] help = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R) {
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
// 要么p1越界,要么p2越界
// 不可能出现:共同越界
while (p1 <= M) {
help[i++] = arr[p1++];
}
while (p2 <= R) {
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {
arr[L + i] = help[i];
}
}
时间复杂度:
步长为N
步长调整次数: logN
那么时间时间复杂度为: O(N*logN)
2. 深入理解
用例:
数组小和
在一个数组中,一个数左边比它小的数的总和,叫数的小和,所有数的小和累加起来,叫数组小和,求数组小和。
例子:[1,3,4,2,5]
1 左边比1小的数:没有
3 左边比3小的数: 1
4 左边比4小的数: 1、3
2 左边比2小的数: 1
5 左边比5小的数: 1、3、4、2
所以数组的小和为 1+1+3+1+1+3+4+2=16
流程:
右组的某个数比左组的大的有几个 == 左组的某个数在右组中有几个比它大,即右组的数就
1、左组去marge,返回小和
2、右组去marge,返回小和
3、左组和右组marge,返回小和
[1,3,4,2,5]
0,1,2,3,4
134为左组 25为右组
p1在0位置 p2在3位置
1 < 2 产生小和 从4的下标开始算有2个数大于1 所以小和为2个1 拷贝p1 p1++
help[1]
p1在1位置 p2在3位置
3 >(=) 2 不产生小和 拷贝p2 p2++
help[1,2]
p1在1位置 p2在4位置
3 < 5 产生小和 从5的下标开始算有1个数大于3 所以小和为1个3 拷贝p1 p1++
help[1,2,3]
p1在2位置 p2在4位置
4 < 5 产生小和 从5的下标开始算有1个数大于4 所以小和为1个4 拷贝p1 p1++
help[1,2,3,4]
注:
左组数小于右组的数,产生小和为右组下标开始数有n个数比左组大,即n*左组数为小和,拷贝左组的数到help数组,左组下标++
左组数大于等于右组的数,不产生小和,拷贝右组的数到help数组,右组下标++
4、整体返回小和
public static int SmallSum2(int[] arr) {
if (arr.length < 2 || arr == null) {
return 0;
}
return process(arr, 0, arr.length - 1);
}
public static int merge(int[] arr, int left, int mid, int right) {
int ans = 0;
int k = 0;
int[] help = new int[arr.length - 1];
int i = left;
int j = mid + 1;
while (i <= mid && j <= right) {
ans += arr[i] < arr[j] ? (right - j + 1) * arr[i] : 0;
help[k++] = arr[i] < arr[j] ? arr[i++] : arr[j++];
}
while (i <= mid) {
help[k++] = arr[i++];
}
while (j <= right) {
help[k++] = arr[j++];
}
return ans;
}
public static int process(int[] arr, int left, int right) {
if (left == right) {
return 0;
}
int mid = left + ((right - left) >> 1);
return process(arr, left, mid) + process(arr, mid + 1, right) + merge(arr, left, mid, right);
}
剑指 Offer 51. 数组中的逆序对
算法流程:
merge_sort() 归并排序与逆序对统计:
终止条件: 当 指针越界时候,终止划分;
递归划分: 计算数组中点 m,递归划分左子数组
merge_sort(1, m)和右子数组merge_sort(m + 1, r);合并与逆序对统计:
暂存数组
nums闭区间[i,r]内的元素至辅助数组tmp;循环合并: 设置双指针
i , j分别指向左/右子数组的首元素;当
i = m + 1时: 代表左子数组已合并完,因此添加右子数组当前元素tmp[j],并执行j = j + 1;否则,当 j = r + 1 时: 代表右子数组已合并完,因此添加左子数组当前元素
tmp[i],并执行i = i + 1;否则,当
tmp[i] ≤ tmp[j]时: 添加左子数组当前元素tmp[i],并执行i = i + 1;否则(即
tmp[i] > tmp[j]时: 添加右子数组当前元素tmp[j],并执行j = j + 1;此时构成m−i+1个「逆序对」,统计添加至 res ;
返回值: 返回直至目前的逆序对总数 res ;
reversePairs() 主函数:
1. **初始化:** 辅助数组 `tmp` ,用于合并阶段暂存元素;
2. **返回值:** 执行归并排序 `merge_sort()` ,并返回逆序对总数即可;
public int reversePairs(int[] arr) {
if (arr == null || arr.length < 2) {
return 0;
}
return process(arr, 0, arr.length - 1);
}
// arr[L..R]既要排好序,也要求逆序对数量返回
// 所有merge时,产生的逆序对数量,累加,返回
// 左 排序 merge并产生逆序对数量
// 右 排序 merge并产生逆序对数量
public static int process(int[] arr, int l, int r) {
if (l == r) {
return 0;
}
// l < r
int mid = l + ((r - l) >> 1);
return process(arr, l, mid) + process(arr, mid + 1, r) + merge(arr, l, mid, r);
}
public static int merge(int[] arr, int L, int m, int r) {
int[] help = new int[r - L + 1];
int i = help.length - 1;
int p1 = m;
int p2 = r;
int res = 0;
while (p1 >= L && p2 > m) {
res += arr[p1] > arr[p2] ? (p2 - m) : 0;
help[i--] = arr[p1] > arr[p2] ? arr[p1--] : arr[p2--];
}
while (p1 >= L) {
help[i--] = arr[p1--];
}
while (p2 > m) {
help[i--] = arr[p2--];
}
for (i = 0; i < help.length; i++) {
arr[L + i] = help[i];
}
return res;
}
3. 总结通法
纠结每一个数左面或右边有几个数比它大或小的时候都用mergeSort改
二. 快排
快速排序过程
Partition 过程
给定一个数组arr, 和一个整数num. 请把小于等于num得数放在数组左边,大于num的数放在数组的右边.
要求 额外空间复杂度O(1) ,时间复杂度 O(N)
1. 引入: 将比划分值大的数放左边 小的放右边
思路:
1. 先确定最右面为`划分值 P` 设置`较小区 lessEqualR` 下标为 -1,
2. `当前数`如果小于 `划分值`, 要交换`当前数` 和 `较小区` 的下一个值,将`较小区`向右移一个位置,`当前数`后向移动一个位置
public static void splitNum1(int[] arr) {
int lessEqualR = -1;
int index = 0;
int N = arr.length;
while (index < N) {
if (arr[index] <= arr[N - 1]) {
swap(arr, ++lessEqualR, index++);
} else {
index++;
}
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
2. 升级
先设置
较小区下标为 -1, 确定最右面为划分值 P设置
较大区,包含最右面arr.length当前数如果小于划分值, 要交换当前数和较小区的下一个值,将较小区向右移一个位置,当前数后向移动一个位置当前数如果大于划分值, 要交换当前数和较大区的前一个值,将较大区向左移一个位置,当前数不动 ( 因为当前数交换完未比较 )交换完成后,将
划分值P和较大区的第一个交换,将划分值放到中间
public static void splitNum2(int[] arr) {
int N = arr.length;
int lessR = -1;
int moreL = N - 1;
int index = 0;
// arr[N-1]
while (index < moreL) { //index小于较大区的小边界
if (arr[index] < arr[N - 1]) {
swap(arr, ++lessR, index++);
} else if (arr[index] > arr[N - 1]) {
swap(arr, --moreL, index);
} else {
index++;
}
}
swap(arr, moreL, N - 1);
}
3. 分层
在 arr[L...R] 范围上,用 arr[R] 做划分值,返回等于区域的边界
public static int[] partition(int[] arr, int L, int R) {
int lessR = L - 1;
int moreL = R;
int index = L;
while (index < moreL) {
if (arr[index] < arr[R]) {
swap(arr, ++lessR, index++);
} else if (arr[index] > arr[R]) {
swap(arr, --moreL, index);
} else {
index++;
}
}
swap(arr, moreL, R);
return new int[] { lessR + 1, moreL };
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
// arr[L..R]上,以arr[R]位置的数做划分值
// <= X > X
// <= X X
public static int partition(int[] arr, int L, int R) {
if (L > R) {
return -1;
}
if (L == R) {
return L;
}
int lessEqual = L - 1;
int index = L;
while (index < R) {
if (arr[index] <= arr[R]) {
swap(arr, index, ++lessEqual);
}
index++;
}
swap(arr, ++lessEqual, R);
return lessEqual;
}
4. 思路

快排 1.0 :每次排一个数
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
// arr[L...R]范围上,拿arr[R]做划分值,
// L....R < = >
public static int[] partition(int[] arr, int L, int R) {
int lessR = L - 1;
int moreL = R;
int index = L;
while (index < moreL) {
if (arr[index] < arr[R]) {
swap(arr, ++lessR, index++);
} else if (arr[index] > arr[R]) {
swap(arr, --moreL, index);
} else {
index++;
}
}
swap(arr, moreL, R);
return new int[] { lessR + 1, moreL };
}
public static void quickSort1(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
process(arr, 0, arr.length - 1);
}
public static void process(int[] arr, int L, int R) {
if (L >= R) {
return;
}
int[] equalE = partition(arr, L, R);
process(arr, L, equalE[0] - 1);
process(arr, equalE[1] + 1, R);
}
}
非递归方式
public static class Job {
public int L;
public int R;
public Job(int left, int right) {
L = left;
R = right;
}
}
public static void quickSort2(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
Stack<Job> stack = new Stack<>();
stack.push(new Job(0, arr.length - 1));
while (!stack.isEmpty()) {
Job cur = stack.pop();
int[] equals = partition(arr, cur.L, cur.R);
if (equals[0] > cur.L) { // 有< 区域
stack.push(new Job(cur.L, equals[0] - 1));
}
if (equals[1] < cur.R) { // 有 > 区域
stack.push(new Job(equals[1] + 1, cur.R));
}
}
}
快排 2.0 :每次排值相等的一组数
三. 选择排序
1. 思路
比较1 ~ n项大小,确定第一位。
比较2 ~ n项大小,确定第二位。
比较3 ~ n项大小,确定第三位。。。。。
需要比较 n - 1次。
2. 图解

3. 代码
public static void selectionSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
// 0 ~ n-1
// 1 ~ n-1
int n = arr.length;
for (int i = 0; i < n ; i++) {
int min = i;
for (int j = i + 1; j < n ; j++) {
min = arr[j] < arr[min] ? j : min;
}
swap(arr, i, min);
}
}
4. 优化 (设定一个哨兵)
public static void selectionSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
// 0 ~ N-1 找到最小值,在哪,放到0位置上
// 1 ~ n-1 找到最小值,在哪,放到1 位置上
// 2 ~ n-1 找到最小值,在哪,放到2 位置上
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < arr.length; j++) {
minIndex = arr[minIndex] < arr[j] ? minIndex : j;
}
if (i != minIndex)
swap(arr, i, minIndex);
}
}
swap:
public static void swap(int[] arr, int i, int j) {
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
}
四. 冒泡排序
1. 思路
比较 1,2 的大小 确定位置 小前大后。
比较 2,3 的大小 确定位置 小前大后。。。。。
比较 n -1 次,得到最后一位为最大值。
0 ~ n-1
0 ~ n-2 ….
0 ~ 1
以上步骤执行 n - 1 次,排序完成。
2. 图解

3. 代码
方式一
public static void bubbleSort(int[] arr) {
/*plan1*/
if (arr == null || arr.length < 2) {
return;
}
// 0 ~ n-1
// 0 ~ n-2
int n = arr.length;
for (int i = n - 1; i >= 0; i--) {
for (int j = 0; j < i; j++) {
if (arr[j + 1] < arr[j]) {
swap(arr, j, j + 1);
}
}
}
}
方式二
public static void bubbleSort02(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1);
}
}
}
}
4. 优化
加入flag 避免不必要的转换
// 升级
public static void bubbleSortPlus(int[] arr) {
Boolean flag = true;
if (arr == null || arr.length < 2) {
return;
}
for (int i = arr.length - 1; i > 0 && flag; i--) {
flag = false;
for (int j = 0; j < i; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1);
flag = true;
}
}
}
}
swap:
public static void swap(int[] arr, int i, int j) {
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
}
五. 插入排序
1. 思路
比较 0 ~ 1 中最大的,排序。
插入第三位,确定 0 ~ 2 的顺序。
插入第四位,确定 0 ~ 3 的顺序。。。。
插入第 n 位,确定 0 ~ n 的顺序
排序完成
2. 图解

3. 代码
方式一
public static void insertSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int n = arr.length;
for (int i = 0; i < n; i++) {
while (i - 1 >= 0 && arr[i - 1] > arr[i]) {
int temp = arr[i];
arr[i] = arr[i - 1];
arr[i - 1] = temp;
i--;
}
}
}
方式二: 虽然简单但是不推荐(插入一般都是从右往左的) 感觉不太对
public static void insertSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int n = arr.length;
for (int i = 1; i < n; i++) {
for (int j = 0; j < i; j++) {
if (arr[j] > arr[i]) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
}
方式三(优化)
public static void insertSort03(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int n = arr.length;
for (int end = 0; end < n; end++) {
for (int pre = end - 1; pre >= 0 && arr[pre] > arr[pre + 1]; pre--) {
int temp = arr[pre];
arr[pre] = arr[pre + 1];
arr[pre + 1] = temp;
}
}
}
三 四 五的时间复杂度都是n
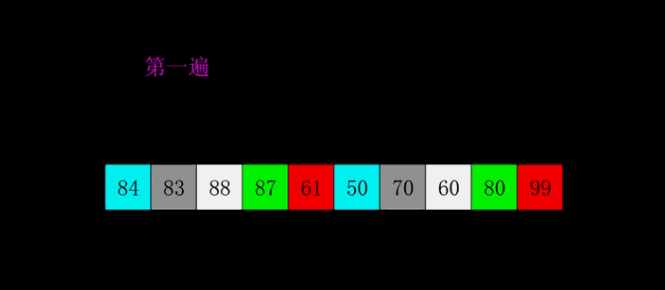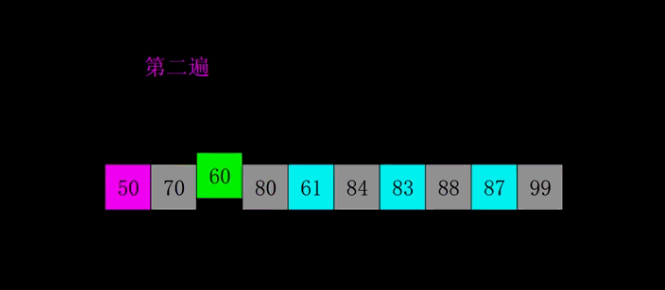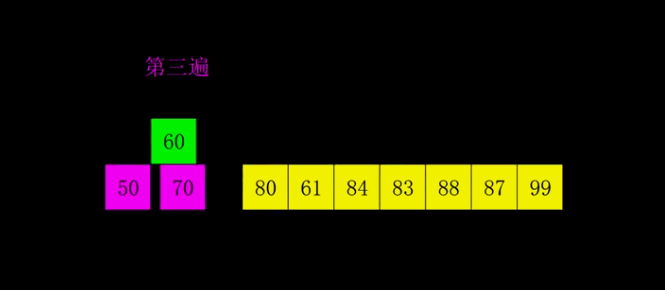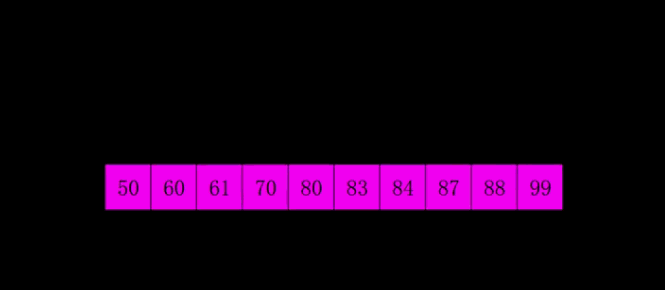
六. 希尔排序
1. 排序思想
希尔排序(Shell’s Sort)是插入排序的一种,是直接插入排序算法的一种更高版本的改进版本。
- 把记录按步长gap分组,对每组记录采用直接插入排序方法进行排序;
- 随着步长逐渐减小,所分成的组包含的记录越来越多;
当步长值减小到1时,整个数据合成一组,构成一组有序记录,完成排序;
2. 图解

3. 代码
/**
* 希尔排序演示
* @author Lvan
*/
public class ShellSort {
public static void main(String[] args) {
int[] arr = {5, 1, 7, 3, 1, 6, 9, 4};
shellSort(arr);
for (int i : arr) {
System.out.print(i + "\t");
}
}
private static void shellSort(int[] arr) {
//step:步长
for (int step = arr.length / 3 + 1; step > 0; step = step/3 + 1) {
//对一个步长区间进行比较 [step,arr.length]
for (int i = step; i < arr.length; i++) {
int value = arr[i];
int j;
//对步长区间中具体的元素进行比较
for (j = i - step; j >= 0 && arr[j] > value; j -= step) {
//j为左区间的取值,j+step为右区间与左区间的对应值。
arr[j + step] = arr[j];
}
//此时step为一个负数,[j + step]为左区间上的初始交换值
arr[j + step] = value;
}
}
}
}
七. 堆排序
1. 堆的定义
底层: 完全二叉树
堆是一个树形结构,其实堆的底层是一棵完全二叉树。而完全二叉树是一层一层按照进入的顺序排成的。按照这个特性,我们可以用数组来按照完全二叉树实现堆。
大根堆: 根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大顶堆。大顶堆要求根节点的关键字既大于或等于左子树的关键字值,又大于或等于右子树的关键字值。
小根堆: 根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者,称为小顶堆。小堆堆要求根节点的关键字既小于或等于左子树的关键字值,又小于或等于右子树的关键字值。

2. 堆的思想
将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根节点。将它移走(其实就是将其与对数组的末尾元素进行交换,此时末尾元素就是最大值),然后将剩下的 n-1 个序列重新构造成一个堆,这样就会得到n个元素中的次大值。如此反复执行,便能得到一个有序序列。
- 构建初始堆,将待排序列构成一个大顶堆(或者小顶堆),升序大顶堆,降序小顶堆;
- 将堆顶元素与堆尾元素交换,并断开(从待排序列中移除)堆尾元素。
- 重新构建堆。
- 重复2~3,直到待排序列中只剩下一个元素(堆顶元素)。
3. 图解

4. 代码
方法一
/**
* 堆排序演示
*
* @author Lvan
*/
public class HeapSort {
/**
* 创建堆,
* @param arr 待排序列
*/
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
// 创建堆
for (int i = (arr.length - 1) / 2; i >= 0; i--) {
// 从第一个非叶子结点从下至上,从右至左调整结构
heapify(arr, i, arr.length);
}
// 调整堆结构+交换堆顶元素与末尾元素
for (int i = arr.length - 1; i > 0; i--) {
// 将堆顶元素与末尾元素进行交换
swap(arr, 0, i);
// 重新对堆进行调整
heapify(arr, 0, i);
}
}
/**
* 调整堆
* @param arr 待排序列
* @param parent 父节点
* @param length 待排序列尾元素索引
*/
public static void heapify(int[] arr, int index, int heapSize) {
// 将temp作为父节点
int temp = arr[index];
int left = index * 2 + 1;
while (left < heapSize) {
int right = left + 1;
// 如果有右孩子结点,并且右孩子结点的值大于左孩子结点,则选取右孩子结点
if (right < heapSize && arr[left] < arr[right]) {
left++;
}
// 如果父结点的值已经大于孩子结点的值,则直接结束
if (temp >= arr[left]) {
break;
}
// 把孩子结点的值赋给父结点
arr[index] = arr[left];
// 选取孩子结点的左孩子结点,继续向下筛选
index = left;
left = 2 * index + 1;
}
arr[index] = temp;
}
//交换元素
public static void swap(int arr[], int left, int right) {
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
方法二
package zcy.basic.class06;
import java.util.Arrays;
import java.util.PriorityQueue;
public class Code03_HeapSort {
// 堆排序额外空间复杂度O(1)
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
// O(N*logN)
// for (int i = 0; i < arr.length; i++) { // O(N)
// heapInsert(arr, i); // O(logN)
// }
//如果只是构造根堆 不排序的话可以 将上面代码 优化到 O(N)
for (int i = arr.length - 1; i >= 0; i--) {
heapify(arr, i, arr.length);
}
int heapSize = arr.length;
swap(arr, 0, --heapSize);
// O(N*logN)
while (heapSize > 0) { // O(N)
heapify(arr, 0, heapSize); // O(logN)
swap(arr, 0, --heapSize); // O(1)
}
}
// arr[index]刚来的数,往上
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
// arr[index]位置的数,能否往下移动
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; // 左孩子的下标
while (left < heapSize) { // 下方还有孩子的时候
// 两个孩子中,谁的值大,把下标给largest
// 1)只有左孩子,left -> largest
// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest
// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largest
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
// 父和较大的孩子之间,谁的值大,把下标给largest
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
堆排序的额外空间复杂度为 O(1)
5. 总结
先让整个数组都变成大根堆结构,建立堆的过程:
- 从上到下的方法,时间复杂度为O(N*logN)
- 从下到上的方法,时间复杂度为O(N)
- 把堆的最大值和堆末位的值交换,然后减少堆的大小之后,再去调整调整人能够堆,一直周而复始,时间复杂度为O(N*logN)
- 堆的大小减成0之后排序完成
不基于比较的排序:桶排序思想
桶排序思想下的排序: 计数排序 & 基数排序
- 桶排序思想下的排序都是不基于比较的排序
- 时间复杂度O(N),额外空间负载度O(M)
- 应用范围有限,需要样本的数据情况满足桶的划分
一. 计数排序
01 计数排序算法概念
计数排序不是一个比较排序算法,该算法于1954年由 Harold H. Seward提出,通过计数将时间复杂度降到了O(N)。
02 基础版算法步骤
第一步:找出原数组中元素值最大的,记为max。
第二步:创建一个新数组count,其长度是max加1,其元素默认值都为0。
第三步:遍历原数组中的元素,以原数组中的元素作为count数组的索引,以原数组中的元素出现次数作为count数组的元素值。
第四步:创建结果数组result,起始索引index。
第五步:遍历count数组,找出其中元素值大于0的元素,将其对应的索引作为元素值填充到result数组中去,每处理一次,count中的该元素值减1,直到该元素值不大于0,依次处理count中剩下的元素。
第六步:返回结果数组result。
03 基础版代码实现

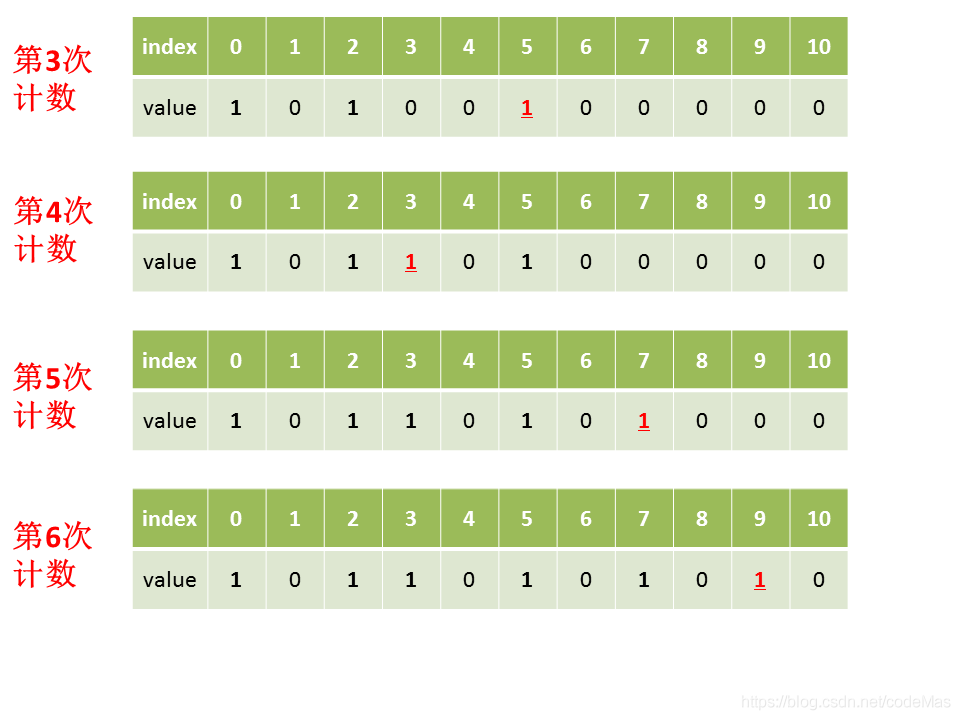

public int[] countSort(int[] A) {
// 找出数组A中的最大值
int max = Integer.MIN_VALUE;
for (int num : A) {
max = Math.max(max, num);
}
// 初始化计数数组count
int[] count = new int[max+1];
// 对计数数组各元素赋值
for (int num : A) {
count[num]++;
}
// 创建结果数组
int[] result = new int[A.length];
// 创建结果数组的起始索引
int index = 0;
// 遍历计数数组,将计数数组的索引填充到结果数组中
for (int i=0; i<count.length; i++) {
while (count[i]>0) {
result[index++] = i;
count[i]--;
}
}
// 返回结果数组
return result;
}
04 优化版
基础版能够解决一般的情况,但是它有一个缺陷,那就是存在空间浪费的问题。
比如一组数据{101,109,108,102,110,107,103},其中最大值为110,按照基础版的思路,我们需要创建一个长度为111的计数数组,但是我们可以发现,它前面的[0,100]的空间完全浪费了,那怎样优化呢?
将数组长度定为max-min+1,即不仅要找出最大值,还要找出最小值,根据两者的差来确定计数数组的长度。
public int[] countSort2(int[] A) {
// 找出数组A中的最大值、最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : A) {
max = Math.max(max, num);
min = Math.min(min, num);
}
// 初始化计数数组count
// 长度为最大值减最小值加1
int[] count = new int[max-min+1];
// 对计数数组各元素赋值
for (int num : A) {
// A中的元素要减去最小值,再作为新索引
count[num-min]++;
}
// 创建结果数组
int[] result = new int[A.length];
// 创建结果数组的起始索引
int index = 0;
// 遍历计数数组,将计数数组的索引填充到结果数组中
for (int i=0; i<count.length; i++) {
while (count[i]>0) {
// 再将减去的最小值补上
result[index++] = i+min;
count[i]--;
}
}
// 返回结果数组
return result;
}
05 进阶版步骤
以数组A = {101,109,107,103,108,102,103,110,107,103}为例。
第一步:找出数组中的最大值max、最小值min。
第二步:创建一个新数组count,其长度是max-min加1,其元素默认值都为0。
第三步:遍历原数组中的元素,以原数组中的元素作为count数组的索引,以原数组中的元素出现次数作为count数组的元素值。



第四步:对count数组变形,新元素的值是前面元素累加之和的值,即count[i+1] = count[i+1] + count[i];。

第五步:创建结果数组result,长度和原始数组一样。
第六步:遍历原始数组中的元素,当前元素A[j]减去最小值min,作为索引,在计数数组中找到对应的元素值count[A[j]-min],再将count[A[j]-min]的值减去1,就是A[j]在结果数组result中的位置,做完上述这些操作,count[A[j]-min]自减1。
是不是对第四步和第六步有疑问?为什么要这样操作?
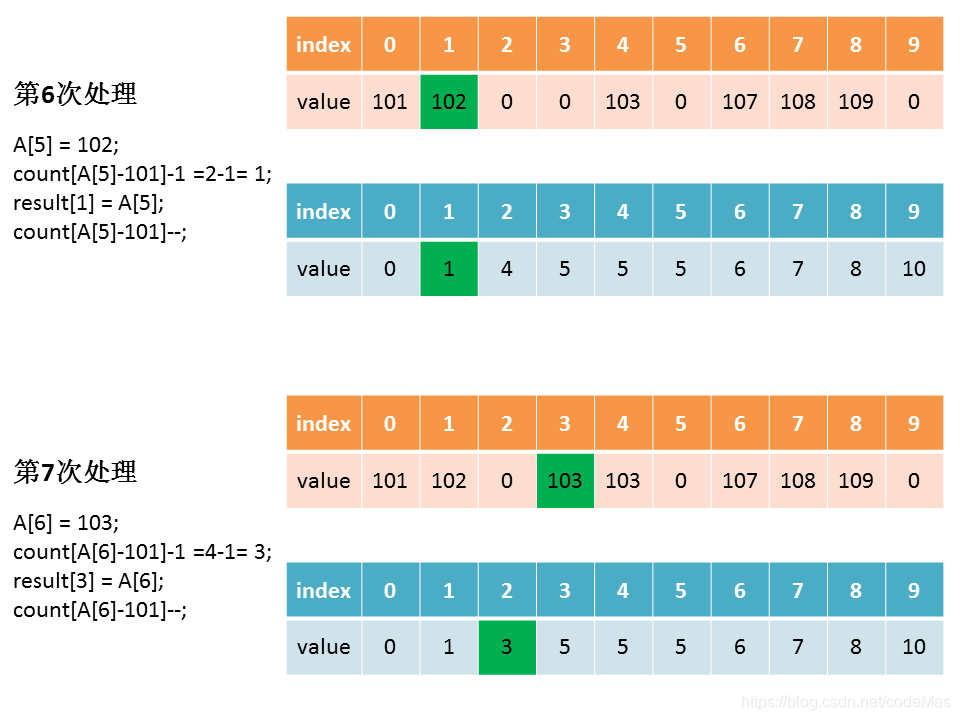
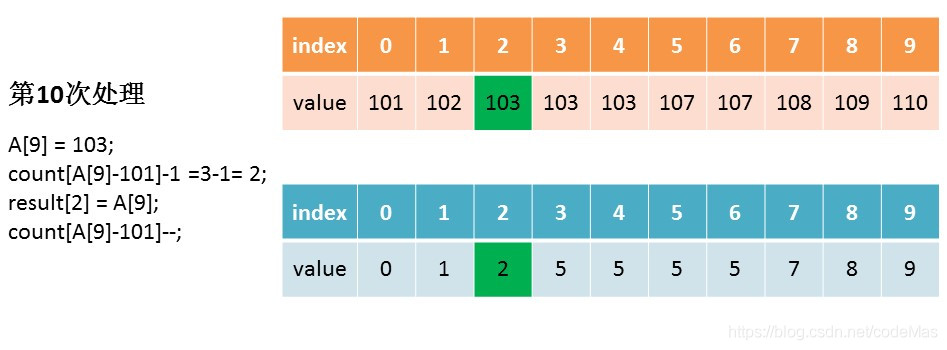
第四步操作,是让计数数组count存储的元素值,等于原始数组中相应整数的最终排序位置,即计算原始数组中的每个数字在结果数组中处于的位置。
比如索引值为9的count[9],它的元素值为10,而索引9对应的原始数组A中的元素为9+101=110(要补上最小值min,才能还原),即110在排序后的位置是第10位,即result[9] = 110,排完后count[9]的值需要减1,count[9]变为9。
再比如索引值为6的count[6],他的元素值为7,而索引6对应的原始数组A中的元素为6+101=107,即107在排序后的位置是第7位,即result[6] = 107,排完后count[6]的值需要减1,count[6]变为6。
如果索引值继续为6,在经过上一次的排序后,count[6]的值变成了6,即107在排序后的位置是第6位,即result[5] = 107,排完后count[6]的值需要减1,count[6]变为5。
至于第六步操作,就是为了找到A中的当前元素在结果数组result中排第几位,也就达到了排序的目的。
06 进阶版代码实现




public int[] countSort3(int[] A) {
// 找出数组A中的最大值、最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : A) {
max = Math.max(max, num);
min = Math.min(min, num);
}
// 初始化计数数组count
// 长度为最大值减最小值加1
int[] count = new int[max-min+1];
// 对计数数组各元素赋值
for (int num : A) {
// A中的元素要减去最小值,再作为新索引
count[num-min]++;
}
// 计数数组变形,新元素的值是前面元素累加之和的值
for (int i=1; i<count.length; i++) {
count[i] += count[i-1];
}
// 创建结果数组
int[] result = new int[A.length];
// 遍历A中的元素,填充到结果数组中去
for (int j=0; j<A.length; j++) {
result[count[A[j]-min]-1] = A[j];
count[A[j]-min]--;
}
return result;
}
07 进阶版的延伸之一
如果我们想要原始数组中的相同元素按照本来的顺序的排列,那该怎么处理呢?
依旧以上一个数组{101,109,107,103,108,102,103,110,107,103}为例,其中有两个107,我们要实现第二个107在排序后依旧排在第一个107的后面,可以在第六步的时候,做下变动就可以实现,用倒序的方式遍历原始数组,即从后往前遍历A数组。
从后往前遍历,第一次遇到107(A[8])时,107-101 = 6,count[6] = 7,即第二个107要排在第7位,即result[6] = 107,排序后count[6] = 6。
继续往前,第二次遇到107(A[2])时,107-101 = 6,count[6] = 6,即第一个107要排在第6位,即result[5] = 107,排序后count[6] = 5。
public int[] countSort4(int[] A) {
// 找出数组A中的最大值、最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : A) {
max = Math.max(max, num);
min = Math.min(min, num);
}
// 初始化计数数组count
// 长度为最大值减最小值加1
int[] count = new int[max-min+1];
// 对计数数组各元素赋值
for (int num : A) {
// A中的元素要减去最小值,再作为新索引
count[num-min]++;
}
// 计数数组变形,新元素的值是前面元素累加之和的值
for (int i=1; i<count.length; i++) {
count[i] += count[i-1];
}
// 创建结果数组
int[] result = new int[A.length];
// 遍历A中的元素,填充到结果数组中去,从后往前遍历
for (int j=A.length-1; j>=0; j--) {
result[count[A[j]-min]-1] = A[j];
count[A[j]-min]--;
}
return result;
}
08 进阶版的延伸之二
既然从后往前遍历原始数组的元素可以保证其原始排序,那么从前往后可不可以达到相同的效果?
答案时可以的。
第一步:找出数组中的最大值max、最小值min。
第二步:创建一个新数组count,其长度是max-min加1再加1,其元素默认值都为0。
第三步:遍历原数组中的元素,以原数组中的元素作为count数组的索引,以原数组中的元素出现次数作为count数组的元素值。
第四步:对count数组变形,新元素的值是前面元素累加之和的值,即count[i+1] = count[i+1] + count[i];。
第五步:创建结果数组result,长度和原始数组一样。
第六步:从前往后遍历原始数组中的元素,当前元素A[j]减去最小值min,作为索引,在计数数组中找到对应的元素值count[A[j]-min],就是A[j]在结果数组result中的位置,做完上述这些操作,count[A[j]-min]自增加1。
依旧以上一个数组{101,109,107,103,108,102,103,110,107,103}为例,其中有两个107,我们要实现第一个107在排序后依旧排在第二个107的前面。
此时计数数组count为{0, 1, 2, 5, 5, 5, 5, 7, 8, 9, 10},从前往后遍历原始数组A中的元素。
第一次遇到107(A[2])时,107-101 = 6,count[6] = 5,即第一个107在结果数组中的索引为5,即result[5] = 107,排序后count[6] = 6。
第二次遇到107(A[8])时,107-101 = 6,count[6] = 6,即第二个107在结果数组中的索引为6,即result[6] = 107,排序后count[6] = 7。
public int[] countSort5(int[] A) {
// 找出数组A中的最大值、最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : A) {
max = Math.max(max, num);
min = Math.min(min, num);
}
// 初始化计数数组count
// 长度为最大值减最小值加1,再加1
int[] count = new int[(max-min+1)+1];
// 对计数数组各元素赋值,count[0]永远为0
for (int num : A) {
// A中的元素要减去最小值再加上1,再作为新索引
count[num-min+1]++;
}
// 计数数组变形,新元素的值是前面元素累加之和的值
for (int i=1; i<count.length; i++) {
count[i] += count[i-1];
}
// 创建结果数组
int[] result = new int[A.length];
// 遍历A中的元素,填充到结果数组中去,从前往后遍历
for (int j=0; j<A.length; j++) {
// 如果后面遇到相同的元素,在前面元素的基础上往后排
// 如此就保证了原始数组中相同元素的原始排序
result[count[A[j]-min]] = A[j];
count[A[j]-min]++;
}
return result;
}
09 小结
以上就是计数排序算法的全部内容了,虽然它可以将排序算法的时间复杂度降低到O(N),但是有两个前提需要满足:一是需要排序的元素必须是整数,二是排序元素的取值要在一定范围内,并且比较集中。只有这两个条件都满足,才能最大程度发挥计数排序的优势。
二. 基数排序
1. 概念
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:
- 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。
- 然后,从最低位开始,依次进行一次排序。
- 这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
ps:基数排序只可以应用于整数。
2. 具体过程如图所示:

3. 实现
// only for no-negative value
public static void radixSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
radixSort(arr, 0, arr.length - 1, maxbits(arr));
}
//找到数组中最大的数
public static int maxbits(int[] arr) {
//max初始化为整数最小值
int max = Integer.MIN_VALUE;
//遍历数组 找到数组最大值max
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
//位数指针
int res = 0;
//除以10每有一位位数加一
while (max != 0) {
res++;
max /= 10;
}
return res;
}
// arr[L..R]排序 , 最大值的十进制位数digit
public static void radixSort(int[] arr, int L, int R, int digit) {
final int radix = 10;
int i = 0, j = 0;
// 有多少个数准备多少个辅助空间
int[] help = new int[R - L + 1];
for (int d = 1; d <= digit; d++) { // 有多少位就进出几次
// 10个空间
// count[0] 当前位(d位)是0的数字有多少个
// count[1] 当前位(d位)是(0和1)的数字有多少个
// count[2] 当前位(d位)是(0、1和2)的数字有多少个
// count[i] 当前位(d位)是(0~i)的数字有多少个
int[] count = new int[radix]; // count[0..9]
for (i = L; i <= R; i++) {
// 103 1 3
// 209 1 9
j = getDigit(arr[i], d);
count[j]++;
}
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
for (i = R; i >= L; i--) {
j = getDigit(arr[i], d);
help[count[j] - 1] = arr[i];
count[j]--;
}
for (i = L, j = 0; i <= R; i++, j++) {
arr[i] = help[j];
}
}
}
public static int getDigit(int x, int d) {
return ((x / ((int) Math.pow(10, d - 1))) % 10);
}

若有收获,就点个赞吧
0 人点赞
