二叉树
二叉树
一. 二叉树定义
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
图3.1展示了一棵普通二叉树:

二. 二叉树性质
性质1
在二叉树的第i层至多有2个结点( i ≥ 1)
性质2
深度为k的二叉树至多有2-1个结点( k ≥ 1 )
性质3
对任何一个二叉树T,如果其终端结点数为n,度为2的节点数为n,则n=n+1.
性质4
具有n个结点的完全二叉树的深度为|logn|+1(|x|表示不大于x的最大整数)
性质5
如果对一颗有n个节点的完全二叉树(其深度为|logn|+1)的结点按层序编号(从第一个层到第|logn|+1层每层从左到右),对任意节点i (1 ≤ i ≤ n)有:
- 如果i=1,则结点i是二叉树的根,无双亲;如果i > 1,则其双亲是|i/2|
- 如果2i > n,则结点i无左孩子(结点i为叶子结点) ;否则其左孩子是结点2i
- 如果2i+1 > n,则结点i无右孩子;否则其右孩子为结点2i+1.
三、斜树、满二叉树、完全二叉树和二叉查找树
斜树
斜树:所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。

左斜树

右斜树
满二叉树
满二叉树:在一棵二叉树中。如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
满二叉树的特点有:
1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
2)非叶子结点的度一定是2。
3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。

完全二叉树
完全二叉树:对一颗具有n个结点的二叉树按层编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。

特点:
1)叶子结点只能出现在最下层和次下层。
2)最下层的叶子结点集中在树的左部。
3)倒数第二层若存在叶子结点,一定在右部连续位置。
4)如果结点度为1,则该结点只有左孩子,即没有右子树。
5)同样结点数目的二叉树,完全二叉树深度最小。
注:满二叉树一定是完全二叉树,但反过来不一定成立。
二叉查找树
定义:二叉查找树又被称为二叉搜索树。设x为二叉查找树中的一个结点,x结点包含关键字key,结点x的key值计为key[x]。如果y是x的左子树中的一个结点,则key[y]<=key[x];如果y是x的右子树的一个结点,则key[y]>=key[x]
在二叉查找树中:
(1)若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值。
(2)任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值。
(3)任意结点的左、右子树也分别为二叉查找树。
(4)没有键值相等的结点。
四. 二叉树的存储结构
顺序存储
二叉树的顺序存储结构就是使用一维数组存储二叉树中的结点,并且结点的存储位置,就是数组的下标索引。

所示的一棵完全二叉树采用顺序存储方式,如图3.7表示:

可以看出,当二叉树为完全二叉树时,结点数刚好填满数组。
那么当二叉树不为完全二叉树时,采用顺序存储形式如何呢?

其中浅色结点表示结点不存在。那么所示的二叉树的顺序存储结构:

其中,∧表示数组中此位置没有存储结点。此时可以发现,顺序存储结构中已经出现了空间浪费的情况。
那么对于所示的右斜树极端情况对应的顺序存储结构如图:

可以看出,对于这种右斜树极端情况,采用顺序存储的方式是十分浪费空间的。因此,顺序存储一般适用于完全二叉树。
二叉链表
既然顺序存储不能满足二叉树的存储需求,那么考虑采用链式存储。由二叉树定义可知,二叉树的每个结点最多有两个孩子。因此,可以将结点数据结构定义为一个数据和两个指针域。表示方式如图3.11所示:

定义结点代码:
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int v) {
value = v;
}
}
则所示的二叉树可以采用图表示。

图中采用一种链表结构存储二叉树,这种链表称为二叉链表。
五. 二叉树遍历
二叉树的遍历一个重点考查的知识点。
5.1 定义
二叉树的遍历是指从二叉树的根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点被访问一次,且仅被访问一次。
二叉树的访问次序可以分为四种:
前序遍历
中序遍历
后序遍历
层序遍历
5.2 前序遍历
前序遍历通俗的说就是从二叉树的根结点出发,当第一次到达结点时就输出结点数据,按照先向左在向右的方向访问。

所示二叉树访问如下:
从根结点出发,则第一次到达结点A,故输出A;
继续向左访问,第一次访问结点B,故输出B;
按照同样规则,输出D,输出H;
当到达叶子结点H,返回到D,此时已经是第二次到达D,故不在输出D,进而向D右子树访问,D右子树不为空,则访问至I,第一次到达I,则输出I;
I为叶子结点,则返回到D,D左右子树已经访问完毕,则返回到B,进而到B右子树,第一次到达E,故输出E;
向E左子树,故输出J;
按照同样的访问规则,继续输出C、F、G;
二叉树的前序遍历输出为:
ABDHIEJCFG
5.3 中序遍历
中序遍历就是从二叉树的根结点出发,当第二次到达结点时就输出结点数据,按照先向左在向右的方向访问。
二叉树中序访问如下:
从根结点出发,则第一次到达结点A,不输出A,继续向左访问,第一次访问结点B,不输出B;继续到达D,H;
到达H,H左子树为空,则返回到H,此时第二次访问H,故输出H;
H右子树为空,则返回至D,此时第二次到达D,故输出D;
由D返回至B,第二次到达B,故输出B;
按照同样规则继续访问,输出J、E、A、F、C、G;
二叉树的中序遍历输出为:
HDIBJEAFCG
5.4 后序遍历
后序遍历就是从二叉树的根结点出发,当第三次到达结点时就输出结点数据,按照先向左在向右的方向访问。
二叉树后序访问如下:
从根结点出发,则第一次到达结点A,不输出A,继续向左访问,第一次访问结点B,不输出B;继续到达D,H;
到达H,H左子树为空,则返回到H,此时第二次访问H,不输出H;
H右子树为空,则返回至H,此时第三次到达H,故输出H;
由H返回至D,第二次到达D,不输出 D;
继续访问至I,I左右子树均为空,故第三次访问I时,输出I;
返回至D,此时第三次到达D,故输出D;
按照同样规则继续访问,输出J、E、B、F、G、C,A;
二叉树的后序遍历输出为:
HIDJEBFGCA
虽然二叉树的遍历过程看似繁琐,但是由于二叉树是一种递归定义的结构,故采用递归方式遍历二叉树的代码十分简单。
递归实现代码如下:
注意:已知前序和后序不能确定一颗二叉树
/*二叉树的前序遍历递归算法*/
public static void pre(Node head) {
if (head == null) {
return;
}
System.out.println(head.value);
pre(head.left);
pre(head.right);
}
/*二叉树的中序遍历递归算法*/
public static void in(Node head) {
if (head == null) {
return;
}
in(head.left);
System.out.println(head.value);
in(head.right);
}
/*二叉树的后序遍历递归算法*/
public static void pos(Node head) {
if (head == null) {
return;
}
pos(head.left);
pos(head.right);
System.out.println(head.value);
}
5.5 层次遍历
递归序列
public static void f(Node head) {
if (head == null) {
return;
}
// 1
f(head.left);
// 2
f(head.right);
// 3
}
层次遍历就是按照树的层次自上而下的遍历二叉树。针对图3.13所示二叉树的层次遍历结果为:
ABCDEFGHIJ
层次遍历的详细方法可以参考二叉树的按层遍历法。
5.6 遍历常考考点
对于二叉树的遍历有一类典型题型。
1)已知前序遍历序列和中序遍历序列,确定一棵二叉树。
例题:若一棵二叉树的前序遍历为ABCDEF,中序遍历为CBAEDF,请画出这棵二叉树。
分析:前序遍历第一个输出结点为根结点,故A为根结点。早中序遍历中根结点处于左右子树结点中间,故结点A的左子树中结点有CB,右子树中结点有EDF。

按照同样的分析方法,对A的左右子树进行划分,最后得出二叉树的形态如图所示:

2)已知后序遍历序列和中序遍历序列,确定一棵二叉树。
后序遍历中最后访问的为根结点,因此可以按照上述同样的方法,找到根结点后分成两棵子树,进而继续找到子树的根结点,一步步确定二叉树的形态。
注:已知前序遍历序列和后序遍历序列,不可以唯一确定一棵二叉树。
六. 二叉树查找
1. 递归方式:
/*
* (递归实现)查找"二叉树x"中键值为key的节点
*/
private BSTNode<T> search(BSTNode<T> x, T key) {
if (x==null)
return x;
int cmp = key.compareTo(x.key);
if (cmp < 0)
return search(x.left, key);
else if (cmp > 0)
return search(x.right, key);
else
return x;
}
public BSTNode<T> search(T key) {
return search(mRoot, key);
}
2. 非递归方式:
/*
* (非递归实现)查找"二叉树x"中键值为key的节点
*/
private BSTNode<T> iterativeSearch(BSTNode<T> x, T key) {
while (x!=null) {
int cmp = key.compareTo(x.key);
if (cmp < 0)
x = x.left;
else if (cmp > 0)
x = x.right;
else
return x;
}
return x;
}
public BSTNode<T> iterativeSearch(T key) {
return iterativeSearch(mRoot, key);
}
3. 查找最大值:
/*
* 查找最大结点:返回tree为根结点的二叉树的最大结点。
*/
private BSTNode<T> maximum(BSTNode<T> tree) {
if (tree == null)
return null;
while(tree.right != null)
tree = tree.right;
return tree;
}
public T maximum() {
BSTNode<T> p = maximum(mRoot);
if (p != null)
return p.key;
return null;
}
4.查找最小值:
/*
* 查找最小结点:返回tree为根结点的二叉树的最小结点。
*/
private BSTNode<T> minimum(BSTNode<T> tree) {
if (tree == null)
return null;
while(tree.left != null)
tree = tree.left;
return tree;
}
public T minimum() {
BSTNode<T> p = minimum(mRoot);
if (p != null)
return p.key;
return null;
}
5. 查找前驱节点:
节点的前驱:是该节点的左子树中的最大节点。
节点的后继:是该节点的右子树中的最小节点。
/*
* 找结点(x)的前驱结点。即,查找"二叉树中数据值小于该结点"的"最大结点"。
*/
public BSTNode<T> predecessor(BSTNode<T> x) {
// 如果x存在左孩子,则"x的前驱结点"为 "以其左孩子为根的子树的最大结点"。
if (x.left != null)
return maximum(x.left);
// 如果x没有左孩子。则x有以下两种可能:
// (01) x是"一个右孩子",则"x的前驱结点"为 "它的父结点"。
// (01) x是"一个左孩子",则查找"x的最低的父结点,并且该父结点要具有右孩子",找到的这个"最低的父结点"就是"x的前驱结点"。
BSTNode<T> y = x.parent;
while ((y!=null) && (x==y.left)) {
x = y;
y = y.parent;
}
return y;
}
6. 查找后继节点:
/*
* 找结点(x)的后继结点。即,查找"二叉树中数据值大于该结点"的"最小结点"。
*/
public BSTNode<T> successor(BSTNode<T> x) {
// 如果x存在右孩子,则"x的后继结点"为 "以其右孩子为根的子树的最小结点"。
if (x.right != null)
return minimum(x.right);
// 如果x没有右孩子。则x有以下两种可能:
// (01) x是"一个左孩子",则"x的后继结点"为 "它的父结点"。
// (02) x是"一个右孩子",则查找"x的最低的父结点,并且该父结点要具有左孩子",找到的这个"最低的父结点"就是"x的后继结点"。
BSTNode<T> y = x.parent;
while ((y!=null) && (x==y.right)) {
x = y;
y = y.parent;
}
return y;
}
7. 插入节点的代码
/*
* 将结点插入到二叉树中
*
* 参数说明:
* tree 二叉树的
* z 插入的结点
*/
private void insert(BSTree<T> bst, BSTNode<T> z) {
int cmp;
BSTNode<T> y = null;
BSTNode<T> x = bst.mRoot;
// 查找z的插入位置
while (x != null) {
y = x;
cmp = z.key.compareTo(x.key);
if (cmp < 0)
x = x.left;
else
x = x.right;
}
z.parent = y;
if (y==null)
bst.mRoot = z;
else {
cmp = z.key.compareTo(y.key);
if (cmp < 0)
y.left = z;
else
y.right = z;
}
}
/*
* 新建结点(key),并将其插入到二叉树中
*
* 参数说明:
* tree 二叉树的根结点
* key 插入结点的键值
*/
public void insert(T key) {
BSTNode<T> z=new BSTNode<T>(key,null,null,null);
// 如果新建结点失败,则返回。
if (z != null)
insert(this, z);
}
8. 删除节点的代码
删除节点分为几种情况:
1.删除的节点为叶子节点:直接删除。
2.删除的节点只存在左子树或右子树:删除节点的父节点直接指向子树节点。
3.删除的节点同时存在左子树和右子树:将删除节点的左子树的最右节点或右子树的最左节点替换删除节点,同时删除替换节点,再将删除节点指向子树节点。
private Node<T> remove(T data,Node<T> node)
{
if(data == null)
return node;
/**
* compare函数内部实现大致如下:
* ((comparable)data).compareTo(node.element);
* 比较需要删除的数据与当前节点的值的大小
*/
int result = compare(data,node.element);
//result<0:表示需要删除的节点在左子树。(二叉查找数的性质)
if(result<0)
node.left = remove(data,node.left);
else if(result>0)//在右子树
node.right = remove(data,node.right);
else if(node.left != null && node.right != null)//找到需要删除的节点且节点下有两个子节点
{
/**先找到需要删除的节点下,右子树中最小的节点
* 并将它的值赋给需要删除的节点。
* */
node.element = findMin(node.right).element;
//删除前面找到的最小的节点。
node.right = remove(node.right);
}
else//找到需要删除的节点且节点下有一个子节点(左或者右)
node = (node.left != null) ? node.left : node.right;
}
public void remove(T data)
{
this.remove(data,root);
}
// 递归
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
// 找到待删除的结点
if (root.val == key) {// 删除并调整
// 当前结点没有左子树,只有右子树,直接返回
if (root.left == null) return root.right;
// 当前结点没有右子树,只有左子树,自己返回
if (root.right == null) return root.left;
// 当前结点左右子树都不空时,
// 获取右子树中比当前结点大的最小的结点,
TreeNode minNode = successor(root.right);
// 则让右子树中最近的那个节点来接替自己
root.val = minNode.val;
// 调整右子树
root.right = deleteNode(root.right, minNode.val);
}
// 找待删除的结点,当前结点的值比删除值小,说明删除的结点在右边,所以去遍历右子树
else if (root.val < key) root.right = deleteNode(root.right,key);
// 找待删除的结点,当前结点的值比删除值大,说明删除的结点在左边,所以去遍历左子树
else if (root.val > key) root.left = deleteNode(root.left,key);
// 删除并调整完后,返回调整的树。
return root;
}
/*
比当前节点大的最小节点,简称后继节点.
*/
// 找右子树中最小的结点.
public TreeNode getMinOnRight(TreeNode node) {
// 找右子树中最小的结点,其实就是最左边的那个结点,依次遍历左子树到尾就找到了
while (node.left != null) node = node.left;
return node;
}
/*
// 找左子树中最大的结点
public int successor(TreeNode root) {
root = root.right;
while (root.left != null) root = root.left;
return root;
}
*/
9. 打印二叉查找树的代码:
/*
* 打印"二叉查找树"
*
* key -- 节点的键值
* direction -- 0,表示该节点是根节点;
* -1,表示该节点是它的父结点的左孩子;
* 1,表示该节点是它的父结点的右孩子。
*/
private void print(BSTNode<T> tree, T key, int direction) {
if(tree != null) {
if(direction==0) // tree是根节点
System.out.printf("%2d is root\n", tree.key);
else // tree是分支节点
System.out.printf("%2d is %2d's %6s child\n", tree.key, key, direction==1?"right" : "left");
print(tree.left, tree.key, -1);
print(tree.right,tree.key, 1);
}
}
public void print() {
if (mRoot != null)
print(mRoot, mRoot.key, 0);
}
10.销毁二叉查找树的代码:
/*
* 销毁二叉树
*/
private void destroy(BSTNode<T> tree) {
if (tree==null)
return ;
if (tree.left != null)
destroy(tree.left);
if (tree.right != null)
destroy(tree.right);
tree=null;
}
public void clear() {
destroy(mRoot);
mRoot = null;
}
平衡二叉树

一、AVL的定义
https://blog.csdn.net/lishanleilixin/article/details/88538491
平衡二叉树:是一种特殊的二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1。从平衡二叉树的名字中可以看出来,它是一种高度平衡的二叉排序树。那么什么叫做高度平衡呢?意思就是要么它是一颗空树,要么它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度只差的绝对值绝对不超过1。
平衡因子:将二叉树上节点的左子树深度减去右子树深度的值称为平衡因子BF。则平衡二叉树上所有节点的平衡因子只可能是1,-1,0。
只要二叉树上有一个节点的平衡因子的绝对值大于1,那么该二叉树就是不平衡的。
最小不平衡子树:距离插入节点最近的,且平衡因子的绝对值大于1的节点为根的子树,我们称之为最小不平衡子树。
二、平衡二叉树实现原理
平衡二叉树构建的基本思想就是在构建二叉排序树的过程中,每当插入一个节点时,先检查是否因插入而破坏了树的平衡性,若是,找出最小不平衡树。在保持二叉排序树特性的前提下,调整最小不平衡子树中各节点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
旋转操作:
右旋:最小不平衡子树的BF和它的子树BF符号相同且最小不平衡子树的BF大于0
左旋:最小不平衡子树的BF和它的子树BF符号相同且最小不平衡子树的BF小于零
左右旋:最小不平衡子树的BF与它的子树的BF符号相反时且最小不平衡子树的BF大于0时,需要对节点先进行一次向左旋使得符号相同后,在向右旋转一次完成平衡操作。
右左旋:最小不平衡子树的BF与它的子树的BF符号相反时且最小不平衡子树的BF小于0时,需要对节点先进行一次向右旋转使得符号相同时,在向左旋转一次完成平衡操作。
1. 节点定义
static class Node{
Node parent;
Node leftChild;
Node rightChild;
int val;
public Node(Node parent, Node leftChild, Node rightChild,int val) {
super();
this.parent = parent;
this.leftChild = leftChild;
this.rightChild = rightChild;
this.val = val;
}
public Node(int val){
this(null,null,null,val);
}
public Node(Node node,int val){
this(node,null,null,val);
}
}
2. 右旋:
/**
* 在这种情况,因为A和B节点均没有右孩子节点,
* 所以不用考虑太多
* @param aNode 代表A节点
* @return
*/
public Node leftRotation(Node aNode){
if(aNode != null){
Node bNode = aNode.leftChild;// 先用一个变量来存储B节点
bNode.parent = aNode.parent;// 重新分配A节点的父节点指向
//判断A节点的父节点是否存在
if(aNode.parent != null){// A节点不是根节点
/**
* 分两种情况
* 1、A节点位于其父节点左边,则B节点也要位于左边
* 2、A节点位于其父节点右边,则B节点也要位于右边
*/
if(aNode.parent.leftChild == aNode){
aNode.parent.leftChild = bNode;
}else{
aNode.parent.rightChild = bNode;
}
}else{// 说明A节点是根节点,直接将B节点置为根节点
this.root = bNode;
}
bNode.rightChild = aNode;// 将B节点的右孩子置为A节点
aNode.parent = bNode;// 将A节点的父节点置为B节点
return bNode;// 返回旋转的节点
}
return null;
}
3. 左旋:
public Node leftRotation(Node node){
if(node != null){
Node rightChild = node.rightChild;
node.rightChild = rightChild.leftChild;
if(rightChild.leftChild != null){
rightChild.leftChild.parent = node;
}
rightChild.parent = node.parent;
if(node.parent == null){
this.root = rightChild;
}else if(node.parent.rightChild == node){
node.parent.rightChild = rightChild;
}else if(node.parent.leftChild == node){
node.parent.leftChild = rightChild;
}
rightChild.leftChild = node;
node.parent = rightChild;
}
return null;
}
至此,打破平衡后,经过一系列操作达到平衡,由以上可知,大致有以下四种操作情况
一、只需要经过一次右旋即可达到平衡
二、只需要经过一次左旋即可达到平衡
三、需先经过左旋,再经过右旋也可达到平衡
四、需先经过右旋,再经过左旋也可达到平衡
4. 插入元素代码:
public boolean put(int val){
return putVal(root,val);
}
private boolean putVal(Node node,int val){
if(node == null){// 初始化根节点
node = new Node(val);
root = node;
size++;
return true;
}
Node temp = node;
Node p;
int t;
/**
* 通过do while循环迭代获取最佳节点,
*/
do{
p = temp;
t = temp.val-val;
if(t > 0){
temp = temp.leftChild;
}else if(t < 0){
temp = temp.rightChild;
}else{
temp.val = val;
return false;
}
}while(temp != null);
Node newNode = new Node(p, val);
if(t > 0){
p.leftChild = newNode;
}else if(t < 0){
p.rightChild = newNode;
}
rebuild(p);// 使二叉树平衡的方法
size++;
return true;
}
5. 这段代码采用了从插入节点父节点进行向上回溯去查找失去平衡的节点:
private void rebuild(Node p){
while(p != null){
if(calcNodeBalanceValue(p) == 2){// 说明左子树高,需要右旋或者 先左旋后右旋
fixAfterInsertion(p,LEFT);// 调整操作
}else if(calcNodeBalanceValue(p) == -2){
fixAfterInsertion(p,RIGHT);
}
p = p.parent;
}
}
6. 计算该参数的左右子树高度之差的方法
private int calcNodeBalanceValue(Node node){
if(node != null){
return getHeightByNode(node);
}
return 0;
}
// 计算node节点的高度
public int getChildDepth(Node node){
if(node == null){
return 0;
}
return 1+Math.max(getChildDepth(node.leftChild),getChildDepth(node.rightChild));
}
public int getHeightByNode(Node node){
if(node == null){
return 0;
}
return getChildDepth(node.leftChild)-getChildDepth(node.rightChild);
}
7. 调整数结构:
/**
* 调整树结构,先后顺序需要换一下,先判断LR型和RL型进行二次旋转
* @param p
* @param type
*/
private void fixAfterInsertion(Node p, int type) {
// TODO Auto-generated method stub
if(type == 1){
final Node leftChild = p.leftChild;
if(calcNodeBalanceValue(leftChild) == -1){// 先左旋后右旋
leftRotation(leftChild);
}
rightRotation(p);
}else{
final Node rightChild = p.rightChild;
if(calcNodeBalanceValue(rightChild) == 1){// 先右旋后左旋
rightRotation(rightChild);
}
leftRotation(p);
}
}
8. 删除
private int calcNodeBalanceValue(Node node){
if(node != null){
return getHeightByNode(node);
}
return 0;
}
public void print(){
print(this.root);
}
public Node getNode(int val){
Node temp = root;
int t;
do{
t = temp.val-val;
if(t > 0){
temp = temp.leftChild;
}else if(t < 0){
temp = temp.rightChild;
}else{
return temp;
}
}while(temp != null);
return null;
}
public boolean delete(int val){
Node node = getNode(val);
if(node == null){
return false;
}
boolean flag = false;
Node p = null;
Node parent = node.parent;
Node leftChild = node.leftChild;
Node rightChild = node.rightChild;
//以下所有父节点为空的情况,则表明删除的节点是根节点
if(leftChild == null && rightChild == null){//没有子节点
if(parent != null){
if(parent.leftChild == node){
parent.leftChild = null;
}else if(parent.rightChild == node){
parent.rightChild = null;
}
}else{//不存在父节点,则表明删除节点为根节点
root = null;
}
p = parent;
node = null;
flag = true;
}else if(leftChild == null && rightChild != null){// 只有右节点
if(parent != null && parent.val > val){// 存在父节点,且node位置为父节点的左边
parent.leftChild = rightChild;
}else if(parent != null && parent.val < val){// 存在父节点,且node位置为父节点的右边
parent.rightChild = rightChild;
}else{
root = rightChild;
}
p = parent;
node = null;
flag = true;
}else if(leftChild != null && rightChild == null){// 只有左节点
if(parent != null && parent.val > val){// 存在父节点,且node位置为父节点的左边
parent.leftChild = leftChild;
}else if(parent != null && parent.val < val){// 存在父节点,且node位置为父节点的右边
parent.rightChild = leftChild;
}else{
root = leftChild;
}
p = parent;
flag = true;
}else if(leftChild != null && rightChild != null){// 两个子节点都存在
Node successor = getSuccessor(node);// 这种情况,一定存在后继节点
int temp = successor.val;
boolean delete = delete(temp);
if(delete){
node.val = temp;
}
p = successor;
successor = null;
flag = true;
}
if(flag){
rebuild(p);
}
return flag;
}
/**
* 找到node节点的后继节点
* 1、先判断该节点有没有右子树,如果有,则从右节点的左子树中寻找后继节点,没有则进行下一步
* 2、查找该节点的父节点,若该父节点的右节点等于该节点,则继续寻找父节点,
* 直至父节点为Null或找到不等于该节点的右节点。
* 理由,后继节点一定比该节点大,若存在右子树,则后继节点一定存在右子树中,这是第一步的理由
* 若不存在右子树,则也可能存在该节点的某个祖父节点(即该节点的父节点,或更上层父节点)的右子树中,
* 对其迭代查找,若有,则返回该节点,没有则返回null
* @param node
* @return
*/
private Node getSuccessor(Node node){
if(node.rightChild != null){
Node rightChild = node.rightChild;
while(rightChild.leftChild != null){
rightChild = rightChild.leftChild;
}
return rightChild;
}
Node parent = node.parent;
while(parent != null && (node == parent.rightChild)){
node = parent;
parent = parent.parent;
}
return parent;
}
9. 中序遍历
public void print(){
print(this.root);
}
private void print(Node node){
if(node != null){
print(node.leftChild);
System.out.println(node.val+",");
print(node.rightChild);
}
}
10. 层次遍历
/**
* 层次遍历
*/
public void printLeft(){
if(this.root == null){
return;
}
Queue<Node> queue = new LinkedList<>();
Node temp = null;
queue.add(root);
while(!queue.isEmpty()){
temp = queue.poll();
System.out.print("节点值:"+temp.val+",平衡值:"+calcNodeBalanceValue(temp)+"\n");
if(temp.leftChild != null){
queue.add(temp.leftChild);
}
if(temp.rightChild != null){
queue.add(temp.rightChild);
}
}
}
哈夫曼树
定义
哈夫曼树的学术定义为,带权路径长度最短的二叉树,即节点具有两个属性:
权值,可以看作节点表达出的数值大小,或者变换的表示为概率大小
路径,可以看作由根节点到达当前节点的分支数,左分支和右分支具有不同意义
带权路径长度即为权值与路径乘积的累加,所以哈夫曼树首先是一棵二叉树,其次通过调整二叉树节点位置,使得带权路径长度最小。
示例
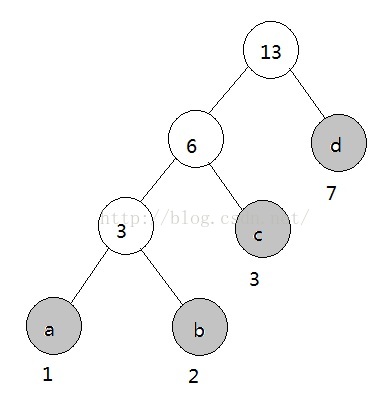
带权路径长度:WPL:1_3+2_3+3_2+7_1=22
上图示例中,灰色节点为给出的原始节点,白色节点为在根据灰色节点构造哈夫曼树时而产生的辅助节点。
由上例可得出哈夫曼树的构造过程:
当节点序列中的根节点数量多于一个时,从当前节点序列中选择两个权值最小的根节点,分别作为左右子节点,创建新的根节点,如选择1,2节点,创建节点3
从序列中删除上一步选择的两个根节点,将新创建的根节点加入序列
重复执行以上两步,最终节点序列中剩余的一个节点即为最终的根节点。
哈夫曼编码 :
前缀编码 : 长短不等的编码,任意字符的编码都不是另一个字符的编码的前缀
题目
98. 验证二叉搜索树
- 给出左树的最大值
- 给出右树的最小值
- 如果root在最大值和最小值中间则为搜索树
===> 简化
- 给出左数的最大值和最小值
- 给出右树的最大值和最小值
- 更新最大值和最小值
- 分别进行左右子树的比较
- 整合比较
public static class Info {
public boolean isBST;
public int max;
public int min;
public Info(boolean is, int ma, int mi) {
isBST = is;
max = ma;
min = mi;
}
}
//法一:
public static Info process(TreeNode x) {
if (x == null) {
return null;
}
Info leftInfo = process(x.left);
Info rightInfo = process(x.right);
int max = x.val;
int min = x.val;
if (leftInfo != null) {
max = Math.max(leftInfo.max, max);
min = Math.min(leftInfo.min, min);
}
if (rightInfo != null) {
max = Math.max(rightInfo.max, max);
min = Math.min(rightInfo.min, min);
}
boolean isBST = true;
if (leftInfo != null && !leftInfo.isBST) {
isBST = false;
}
if (rightInfo != null && !rightInfo.isBST) {
isBST = false;
}
boolean leftMaxLessX = leftInfo == null ? true : (leftInfo.max < x.val);
boolean rightMinMoreX = rightInfo == null ? true : (rightInfo.min > x.val);
if (!(leftMaxLessX && rightMinMoreX)) {
isBST = false;
}
return new Info(isBST, max, min);
}
//法二:(反向)
public static Info process3(TreeNode x) {
if (x == null) {
return null;
}
Info leftInfo = process(x.left);
Info rightInfo = process(x.right);
int max = x.val;
int min = x.val;
if (leftInfo != null) {
max = Math.max(leftInfo.max, max);
min = Math.min(leftInfo.min, min);
}
if (rightInfo != null) {
max = Math.max(rightInfo.max, max);
min = Math.min(rightInfo.min, min);
}
boolean isBST = false;
boolean leftIsBst = leftInfo == null ? true : leftInfo.isBST;
boolean rightIsBst = rightInfo == null ? true : rightInfo.isBST;
boolean leftMaxLessX = leftInfo == null ? true : (leftInfo.max < x.val);
boolean rightMinMoreX = rightInfo == null ? true : (rightInfo.min > x.val);
if (leftIsBst && rightIsBst && leftMaxLessX && rightMinMoreX) {
isBST = true;
}
return new Info(isBST, max, min);
// hello idea
}
100. 相同的树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
if(p == null ^ q == null){
return false;
}
if(p == null && q == null){
return true;
}
return p.val == q.val && isSameTree(p.left , q.left) && isSameTree(p.right , q.right);
}
}
101. 对称二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSymmetric(TreeNode root) {
return isMirror(root,root);
}
public static boolean isMirror(TreeNode h1, TreeNode h2) {
if(h1 == null ^ h2 == null){
return false;
}
if(h1 == null && h2 == null){
return true;
}
return h1.val == h2.val &&
isMirror(h1.left , h2.right) &&
isMirror(h1.right, h2.left);
}
}
102. 二叉树的层序遍历
- 拿出此时队列的size size有多少,这步骤2执行多少次
- 弹出节点,左(先),右(再)
public class Code01_BinaryTreeLevelOrderTraversalII {
public static class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
TreeNode(int val) {
this.val = val;
}
}
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> ans = new LinkedList<>();
if (root == null) {
return ans;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
List<Integer> curAns = new LinkedList<>();
for (int i = 0; i < size; i++) {
TreeNode curNode = queue.poll();
curAns.add(curNode.val);
if (curNode.left != null) {
queue.add(curNode.left);
}
if (curNode.right != null) {
queue.add(curNode.right);
}
}
ans.add(curAns);
}
return ans;
}
}
104. 二叉树的最大深度
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root == null){
return 0;
}
return Math.max(maxDepth(root.left),maxDepth(root.right)) + 1;
}
}
105. 从前序与中序遍历序列构造二叉树
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
}
}
复杂度 O(n)
107. 二叉树的层序遍历 II
- 拿出此时队列的size size有多少,这步骤2执行多少次
- 弹出节点,左(先),右(再)
public class Code01_BinaryTreeLevelOrderTraversalII {
public static class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
TreeNode(int val) {
this.val = val;
}
}
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> ans = new LinkedList<>();
if (root == null) {
return ans;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
List<Integer> curAns = new LinkedList<>();
for (int i = 0; i < size; i++) {
TreeNode curNode = queue.poll();
curAns.add(curNode.val);
if (curNode.left != null) {
queue.add(curNode.left);
}
if (curNode.right != null) {
queue.add(curNode.right);
}
}
ans.add(0, curAns);
}
return ans;
}
}
tips:
使用linkedlist(双端队列)来替代栈的功能 : 速度快 (好像也并不是很快,甚至有点慢)
Stack<Integer> stack = new Stack<>();
stack.add(1);
stack.add(2);
stack.add(3);
while (!stack.isEmpty()){
System.out.println(stack.pop());
}
LinkedList<Integer> s =new LinkedList<>();
s.addLast(1);
s.addLast(2);
s.addLast(3);
while (!stack.isEmpty()){
System.out.println(s.pollLast());
}
但是如果已知长度的时候使用数组替代是最快的:
int[] sta = new int[100];
int index = 0;
sta[index++] = 1;
sta[index++] = 2;
sta[index++] = 3;
System.out.println(sta[--index]);
System.out.println(sta[--index]);
System.out.println(sta[--index]);
tips: .isEmpty()使用示例
过去初学JAVA判断集合是否为空时:
if (collection != null && collection.size() > 0) { ...}
现在判断集合是否为空:
if (collection != null && !collection.isEmpty()){ ...}
注意:
String的isEmpty()方法,在String为null的时候,会出现空指针错误
因为,”” 和 new String(),会有占位符,也就是创建了对象,而null的时候,String 不会创建占位符。————–更通俗的说就是:”” 和new String() 的时候,String是有长度的,而null没有长度。
112. 路径总和
- 如果是叶节点
- 如果不是叶节点
- 递归
public static boolean isSum = false;
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root == null) {
return false;
}
isSum = false;
process(root, 0, targetSum);
return isSum;
}
public static void process(TreeNode root, int preSum, int targetSum) {
// 如果是叶节点
if (root.left == null && root.right == null) {
// 这时候要比较isSum
if (targetSum == root.val + preSum) {
isSum = true;
}
return;
}
// 如果不是叶节点
preSum += root.val;
if (root.left != null) {
process(root.right, preSum, targetSum);
}
if (root.right != null) {
process(root.left, preSum, targetSum);
}
}
113. 路径总和 II
- 如果是叶节点
- 如果不是叶节点
- 递归
public class Code04_PathSumII {
// 测试链接:https://leetcode.com/problems/path-sum-ii
public static class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
TreeNode(int val) {
this.val = val;
}
}
public static List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> ans = new ArrayList<>();
if (root == null) {
return ans;
}
ArrayList<Integer> path = new ArrayList<>();
process(root, path, 0, sum, ans);
return ans;
}
public static void process(TreeNode x, List<Integer> path, int preSum, int sum, List<List<Integer>> ans) {
if (x.left == null && x.right == null) {
if (preSum + x.val == sum) {
path.add(x.val);
ans.add(copy(path));
path.remove(path.size() - 1);
}
return;
}
// x 非叶节点
path.add(x.val);
preSum += x.val;
if (x.left != null) {
process(x.left, path, preSum, sum, ans);
}
if (x.right != null) {
process(x.right, path, preSum, sum, ans);
}
path.remove(path.size() - 1);
}
public static List<Integer> copy(List<Integer> path) {
List<Integer> ans = new ArrayList<>();
for (Integer num : path) {
ans.add(num);
}
return ans;
}
}
剑指 Offer 55 - II. 平衡二叉树
- 左树是平衡的
- 右树是平衡的
- 左数和右树高度绝对值相差 <= 1
public class Code02_BalancedBinaryTree {
public static class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
TreeNode(int val) {
this.val = val;
}
}
//创建Info对象
public static class Info {
public boolean isBalance;
public int height;
public Info(boolean isBalance, int height) {
this.isBalance = isBalance;
this.height = height;
}
}
//递归实现判断平衡
public Info process(TreeNode root) {
if (root == null) {
return new Info(true, 0);
}
Info leftInfo = process(root.left);
Info rightInfo = process(root.right);
int height = Math.max(leftInfo.height, rightInfo.height) + 1;
boolean isBalance = leftInfo.isBalance && rightInfo.isBalance && Math.abs(leftInfo.height - rightInfo.height) < 2;
return new Info(isBalance, height);
}
//调用递归
public boolean isBalanced(TreeNode root) {
return process(root).isBalance;
}
}

若有收获,就点个赞吧
0 人点赞
