为什么不用B-Tree(平衡多叉树/Balance Tree–B-Tree)?
B树特点
- 所有键值分布在整颗树中
- 搜索有可能在非叶子结点结束,在关键字全集内做一次査找性能逼近二分査找
- 每个节点最多拥有m个子树
- 根节点至少有2个子树
- 分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
- 所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
B-Tree的索引格式
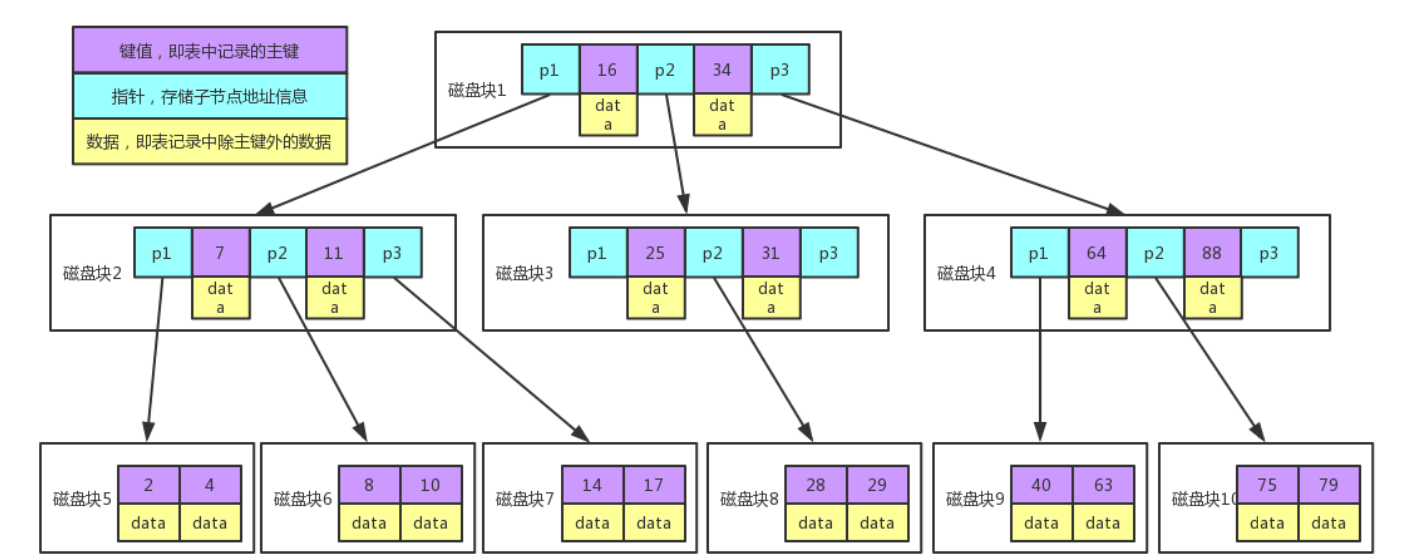
实例图说明
每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。
以根节点为例,关键字为16和34,P1指针指向的子树的数据范围为小于16,P2指针指向的子树的数据范围为16~34,P3指针指向的子树的数据范围为大于34。
查找关键字过程:
- 根据根节点找到磁盘块1,读入内存。【磁盘IO操作第1次】
- 比较关健字28在区间(16,34),找到磁盘块1的指针P2。
- 根据P2指针找到磁盘块3,读入内存。【磁盘IO操作第2次】
- 比较关键字28在区间(2531),找到磁盘块3的指针P2。
- 根据P2指针找到磁盘块8,读入内存。【磁盘IO操作第3次】
- 在磁盘块8中的关键字列表中找到关键字28。
缺点
- 每个节点都有key,同时也包含data,而每个page存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小(MySQL为了能更好的利用磁盘的IO能力,将操作页的大小设置为了16K,即每个节点的大小为16K,data放在节点上,key就存的少了)
- 当存储的数据量很大的时候会导致深度较大,增大查询时磁盘IO次数,进而影响查询性能
为什么使用B+Tree?
B+Tree是在B-Tree的基础上做的一种优化,非叶子节点存储key,叶子节点存储key和数据,每个磁盘块可以包含更多的节点:
- 包含更多的节点的好处:
- 降低树的高度;
- 将数据范围变为多个区间,区间越多,数据检索越快;
- 叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高。(B+Tree的叶子节点是顺序排列的,并且相邻的两个叶子节点中具有顺序引用的关系,这样能更好的支持了范围查询。)
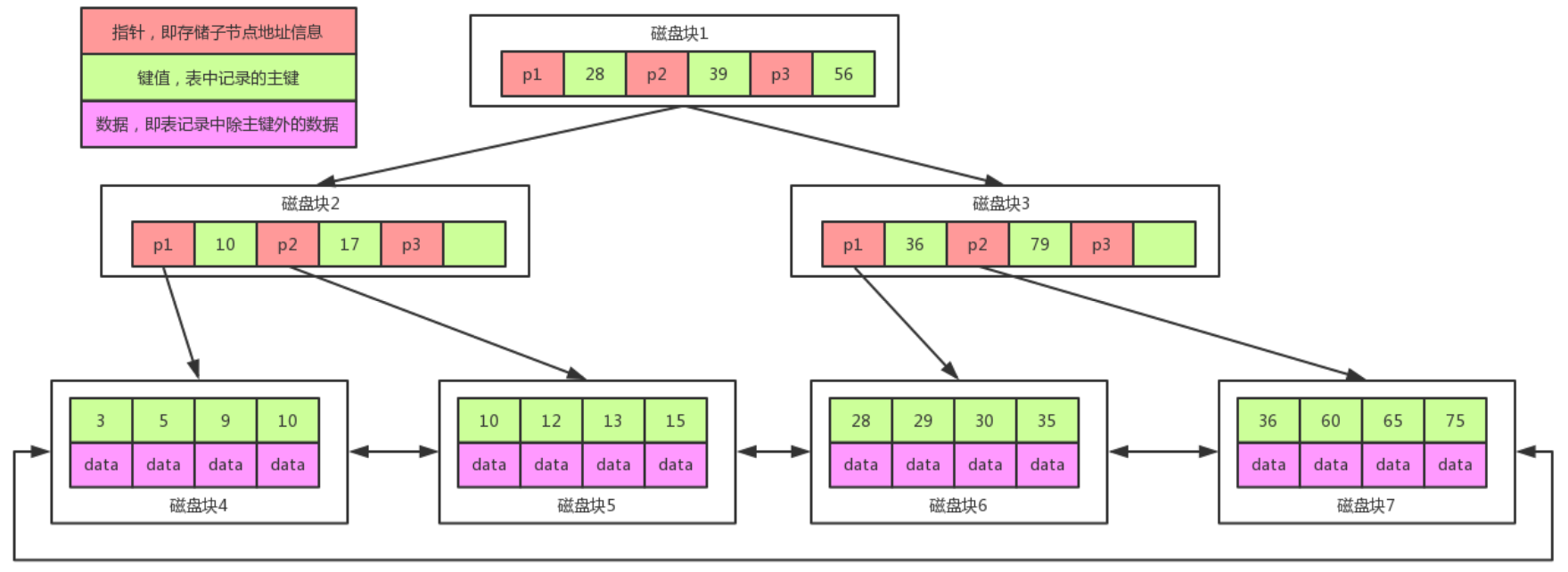
注意
在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种査找运算:
- 对于主键的范围査找和分页査找
- 从根节点开始,进行随机查找
问题:
如果此时要增加一个键值为14的数据,会怎么增加?
进行叶分裂,把磁盘块5分裂成两个,10&12一组,13&15一组,同时磁盘块2增加一个”13”的键值,磁盘块5再插入”14”,应该尽量减少叶分裂
**
为什么不常用Hash?

缺点:
- 利用hash存储的话需要将所有的数据文件添加到内存,比较耗费内存空间;
- 如果所有的査询都是单值査询,那么hash确实很快,但是在企业或者实际工作环境中范围査找的数据更多,而不是等值查询,因此hash就不太适合了
- 不能完全的保证,不产生Hash碰撞
为什么不用二叉树或者红黑树?

缺点:
无论是二叉树还是红黑树,都会因为树的深度过深而造成io次数变多,影响数据读取的效率
二叉树有个问题,就是在特殊情况下,它会退化成一个单向链表。这个时候,查询就相当于全表扫描;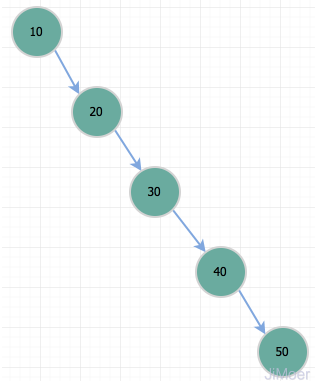

若有收获,就点个赞吧
0 人点赞
