聚簇索引
- 可以把相关数据保存在一起
- 数据访问更快,因为索引和数据保存在同一个树中
-
缺点
聚簇数据最大限度地提高了IO密集型应用的性能,如果数据全部在内存,那么聚簇索引就没有什么优势
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式
- 更新聚簇索引列的代价很高,因为会强制将每个被更新的行移动到新的位置
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临页分裂的问题
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候
非聚簇索引
非聚簇索引,又称为二级索引,虽然也是在B+Tree的每个分支节点上保存关键字,但是叶子节点不是保存的数据,而是保存的主键值。通过二级索引去查询数据会先查询到数据对应的主键,然后再根据主键查询到具体的数据行(如下图)。
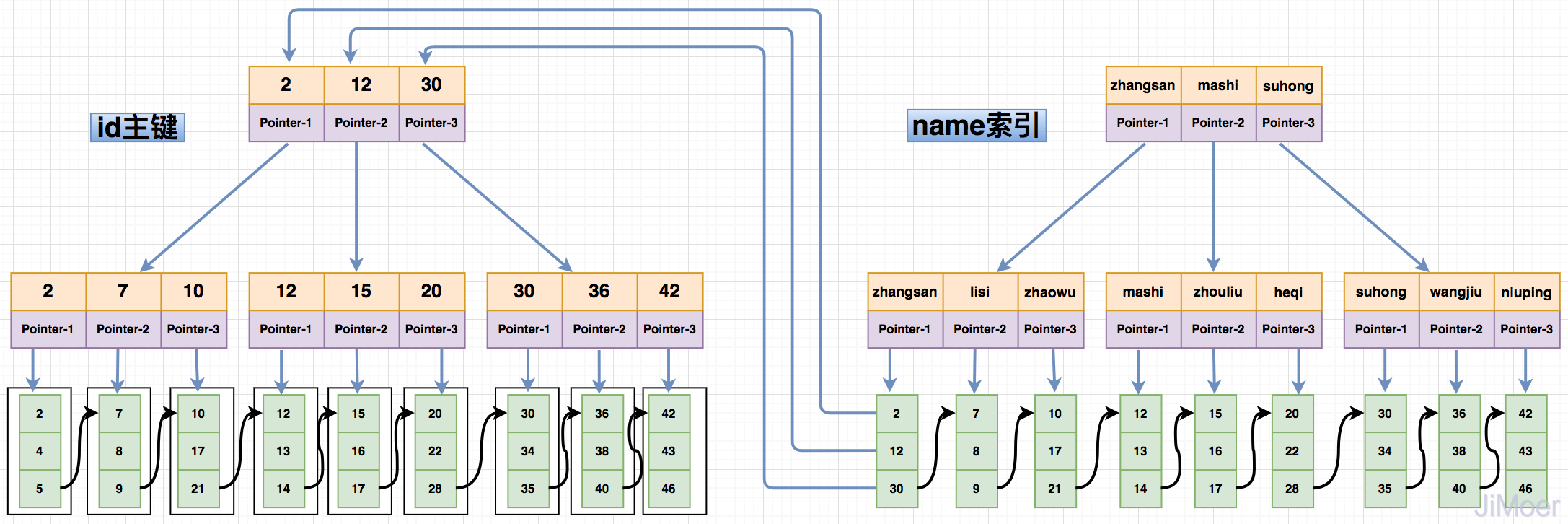
由于非聚簇索引的设计结构,导致了非聚簇索引在查询的时候要进行两次索引检索,这样设计的好处,可以保证了一旦发生数据迁移的时候,只需要更新主键索引即可,非聚簇索引并不用动,而且也规避了像MyISAM的索引那样存储物理地址,在数据迁移的时候的需要重新维护所有索引的问题。

若有收获,就点个赞吧
0 人点赞
