背景
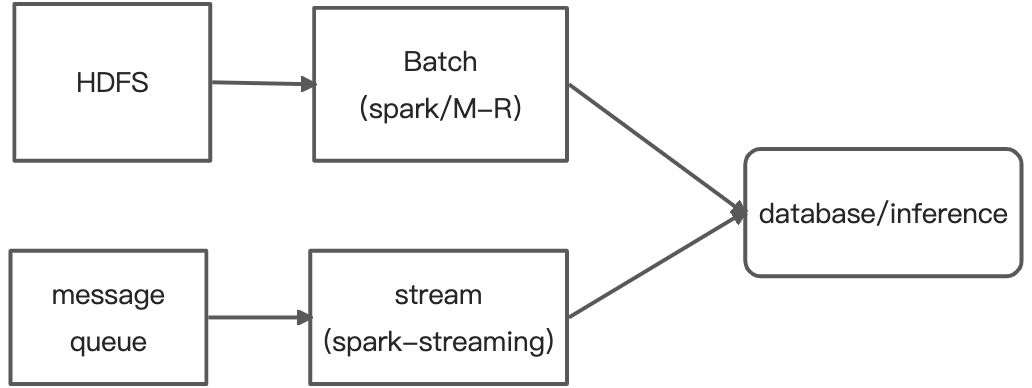
我们之前的数据处理流程如上图。可以看到实时和离线是分开的,离线数据处理主要是基于spark/m-r,实时数据处理主要是基于spark-streaming。
这就造成了以下痛点:同一个业务流程中需要同时维护多套环境、多套代码,许多共性不能复用,数据的一致性得不到保证。并且由于流批底层数据处理模型不一样,导致需要做大量的逻辑拼凑。不同地方基于spark/m-r代码做迁移部署难以保证效率和准确率,同时多个版本难以同时维护和快速开发上线。
支持流批一体的flik sql可以在很大程度上解决这个痛点,因此我们引入flink来解决这个问题。
在大数据处理过程中,对引擎优化极为关键,flinksql经过优化与之前执行效率有着明显差异。因此本文主要介绍我们在实际生产过程所做的一些优化。
优化
SOURCE端优化
实际生产中,使用的数据会被先推到kafka上,然后按照天、小时二级分区接到hive表中,然后用flinksql来进行离线分析。但是在实际使用的过程中,由于数据波动会造成落盘到分区的数据差异很大,如果处理数据的时间拉长到三个月以上会导致需要解析的目录和小文件特别多。而flinksql在source端针对这种情况没有提供很好的方案导致任务执行效率极差。
flink在向每个taskmanager分配所需读取的文件时,会对所有文件进行个遍历,然后将文件按照规则均匀分配给每一个tm。但如果存在大量目录、小文件,会导致这个过程极为漫长。一个月分区 ,在大概3024个目录、3024*2 个文件的情况下,任务提交时间长达10min 。而如果文件大小不均匀,flinksql没有针对大文件提供切割策略,造成分配到一些tm的文件特别大,出现很严重数据倾斜,一些tm执行时间需要很久,甚至造成内存溢出而导致任务失败。
如下图,任务使用一个月的数据21亿条左右,仅数据读取需要28min,整个任务执行长达40min,加上任务提交需要约10min,整个任务从提交到完成需要50min。这个执行效率是我们不能接受的。
对于上述问题,我们改变策略,不直接使用kafka接入的hive表。
对原始数据做一层优化:
1、定时对前一天的原始数据进行重分区;
2、通过设置并行度控制sink的数量从而控制生成文件的个数(可设置table.exec.hive.infer-source-parallelism=true,table.exec.hive.infer-source-parallelism.max=100两个参数增加source并行度);
3、采用orc格式文件替代原始gz压缩text格式文件(flink会自动对ORC/Parquet格式且不包含List, Map, Struct, Union等复杂数据结构的hive表开启向量化读)。
flink默认不支持orc格式,除了依赖hive相关包hive-metastore和flink-connector-hive之外还需添加:
orc-core-1.5.6-nohive.jar
aircompressor-0.8.jar
libfb303-0.9.2.jar
orc-shims-1.5.6.jar
下图,优化前后数据对比

如图,优化后的数据执行效率对比。第一个source完成只需16min,任务完成用了28min。另外任务提交时间也控制在1min内整个任务执行时间只需约29min,性能极大提升。
UDF重用
在实际使用中,出现一些使用的udf的任务中,有些tm会一直卡到初始化阶段。经过排查发现flink sql在使用的过程中会出现以下情况,相同的udf即出现先LogicalProject中,又出现在where条件里,那么udf会进行多次调用。如果udf非常消耗cpu或者内存,那么多余的计算非常啊影响性能,甚至造成内存耗尽任务失败。为此我们希望把相关内容缓存起来,下次直接使用。(注意:请一定保证 LogicalProject 和 where 条件的 subtask chain 到一起)
主要分为两种情况:
1、在udf中有加载外部数据源(如本地数据或者hdfs文件)到内存中,udf多次加载会导致集合无限增大直到内存耗尽。针对这个问题,我们采用guava cache 将udf从外部数据源加载的数据一次性缓存起来,设置超时时间,防止多次调用加载到内存中直到内存耗尽。使用的时候如果缓存中存在则从缓存中读取,如果不存在则再加载一次到缓存中。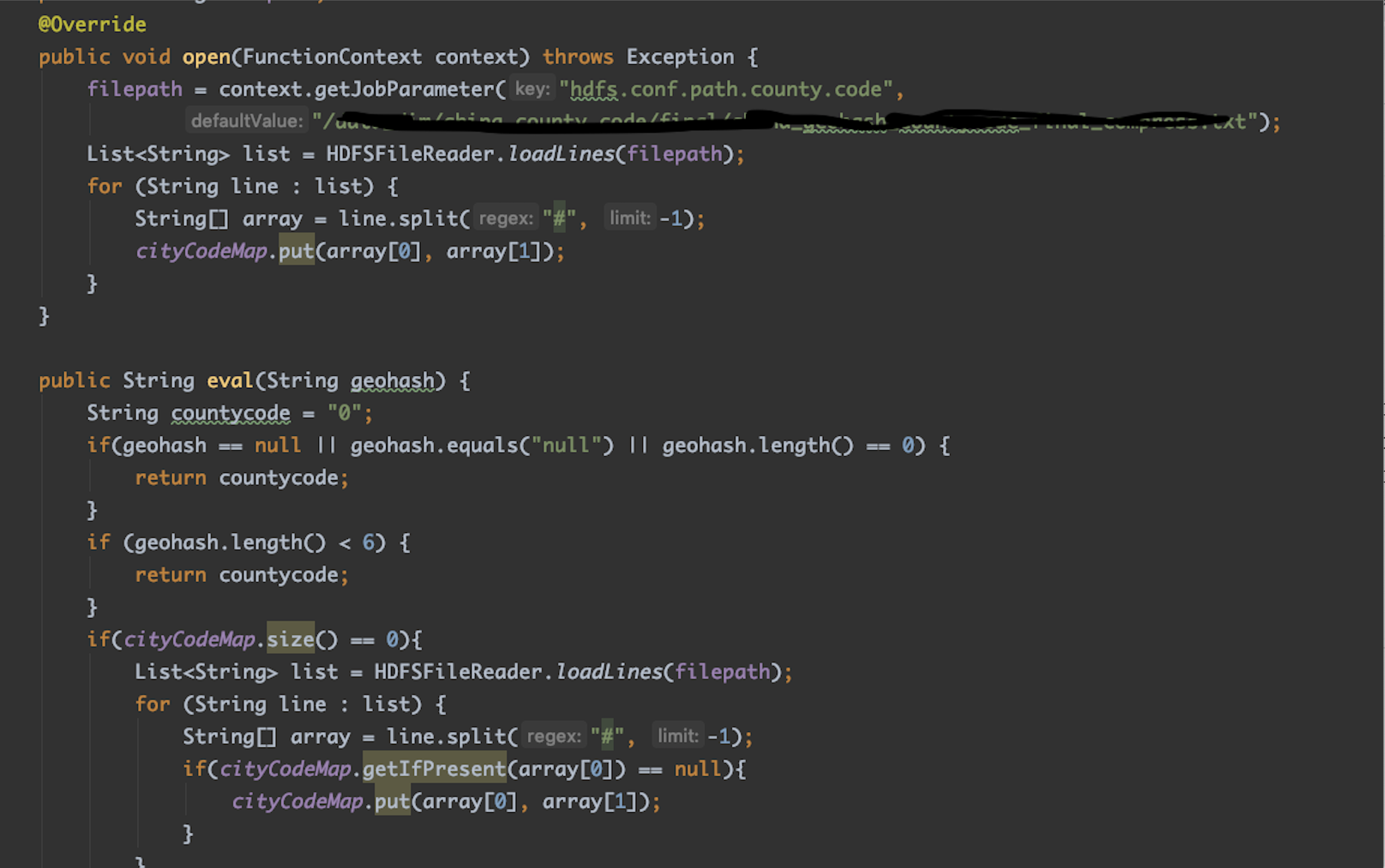
2、不涉及到外部数据源,只是消耗cpu或者内存,导致多余计算影响性能。这种情况使用guava cache 将 UDF 的结果缓存起来,之后调用的时候直接去cache 里面拿数据,最大可能的降低任务消耗。为了防止内存无限增大,选取的 cache 最好可以主动控制 size;至于 “超时时间”,建议可以配置一下,但是最好不要小于 UDF 先后调用的时间。
最后为了防止出现一些情况导致清理 cache 的逻辑走不到,一定要在 close 方法里将 cache 清掉。
SORT-SHUFFLE
和其他分布式系统的批数据 sort-shuffle 实现类似,Flink 的整个 shuffle 过程分为几个重要的阶段,包括写数据到内存缓冲区、对内存缓冲区进行排序、将排好序的数据写出到文件以及从文件中读取 shuffle 数据并发送给下游。但是,与其他系统相比,Flink 的实现有一些根本性的不同,包括多段数据存储格式、省掉数据合并流程以及数据读取 IO 调度等
hash-shuffle(默认)
- 给每个下游输出单独文件
- 大量小文件
- 内存浪费,每个文件至少用1个buffer
- 下游数据读取产生大量随机I/O

sort-shuffle(默认未开启)
上游在输出数据时,会使用一个固定大小的缓冲区,其和并行度解耦,避免随着规模的增大而增大,所有的数据都写到缓冲区里,当缓冲区满的时候,会进行一次排序并写道一个单独的文件里,后面的数据还是基于此缓存继续写,继续写的一段会拼接到原来的文件后面。最后单个上游任务只会产生一个中间文件,由很多段组成,每一段都是一个有序结构。
- 先写缓冲区,把数据按照不同的下游分组,最后写入文件;
- 申请固定大小缓冲区,避免缓冲区随着规模增大而增大;
- 数据写入缓冲区,在缓冲区满的时候会对数据进行排序(合并分区),然后写入单独文件。后边数据接着写到文件后边。文件有多个段,每个段内有序。

一般的外排序是指会把这些断再做一次单独的merge,形成一个整体有序的文件,这样下游来读的时候会有更好的IO连续性,防止每一段每一个task要读取的数据段都很小。但是这种merge本身也是要消耗大量的IO资源的,有可能merge的时间带来的开销会远超下游顺序读带来的收益。
flink采取了另外一种方式,在下游来请求数据的时候,如下图,的3个下游都要来读取上有的中间文件,会有一个调度器对下游请求要读取的文件位置做一个排序,通过在上层增加IO调度的方式,来实现整个文件IO读取的连续性,防止在产生大量随机IO;


参数优化
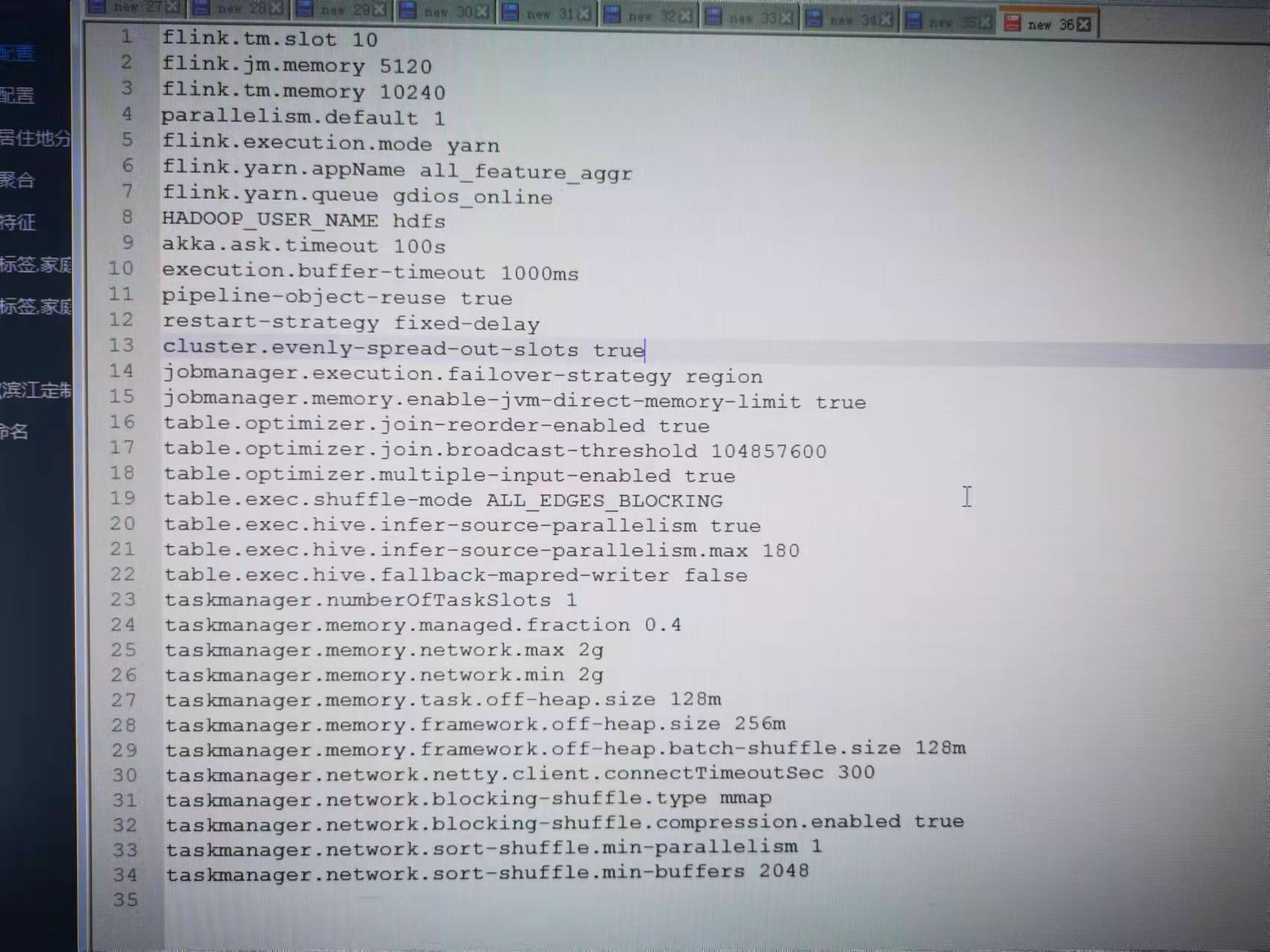
- taskmanager.network.sort-shuffle.min-parallelism。这个参数的含义是如果数据分区的个数(一个计算任务并发需要发送数据给几个下游计算节点)低于这个值,则走 hash-shuffle 的实现,如果高于这个值则启用 sort-shuffle。实际应用时,配置为 1,即使用 sort-shuffle。
- taskmanager.network.blocking-shuffle.compression.enabled。对于批处理作业,大部分场景下是建议开启spill文件压缩。
- taskmanager.network.sort-shuffle.min-buffers。数据写缓冲区。SortMerge数据Shuffle,每个ResultPartition需要的网络缓冲区(Buffer)数。默认64,虽然64个网络Buffer已经可以支持任意规模的并发,但性能可能不是最好的。对于大并发的作业,通 过增大这个配置值,可以提高落盘数据的压缩率并且减少网络小包的数量,从而有利于提高Shuffle性能。推荐生产使用最少2048(2048*32kb=64m),通常对于大规模批处理数百M是足够的。另外,为了增大这个配置值, 你可能需要通过调整taskmanager.memory.network.fraction,taskmanager.memory.network.min和taskmanager.memory.network.max这三个参数来增大总的网络内存大小从而避免出现insufficient number of network buffers错误。(每个slot单独从network memory拿的)
- taskmanager.memory.framework.off-heap.batch-shuffle.size。数据读缓冲区。大小影响shuffle的执行,默认32m,大规模批处理作业要增大,比如128M或256M。数据读缓冲区从框架的 off-heap 内存中切分出来,如果要增大数据读缓冲区,可能还需要增大框架的 off-heap 内存(taskmanager.memory.framework.off-heap.size),以避免出现 direct 内存 OOM 错误。
- taskmanager.memory.task.off-heap.size。SortMerge数据Shuffle还需要使用一些JVM Direct Memory来进行Shuffle数据的写出与读取。所以,为了使 用SortMerge数据Shuffle你可能还需要通过增大这个配置值来为其来预留一些JVM Direct Memory。如果在你开启 SortMerge数据Shuffle之后出现了Direct Memory OOM的错误,你只需要继续加大上面的配置值来预留更多的Direct Memory 直到不再发生Direct Memory OOM的错误为止。
如下图,flink使用sort-shuffle与hash-shuffle效果对比

内存管理
flink 1.10对整个内存做了个大改版,与之前版本有较大差异,主要介绍下TaskManager内存。
flink TaskManager内存模型:
各部分内存解释:
如上图所示,
flink总内存 = Flink 内存 + JVM Metaspace (256m)+ JVM Overhead (计算为0.1 全局大小,结果必须在[192m, 1g]之间);
Flink内存被划分成6部分:框架运行需要的Heap和Non Heap,默认都是128m;
任务需要的Heap和Non Heap(默认0), Heap是通过计算其他5部分内存,Flink内存剩余得到;
网络缓冲 (0.1 Flink内存,结果必须在[64mb, 1g]之间);
Flink管理内存:0.4 * Flink内存。
下表中列出了 Flink TaskManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
(Increase the total size of network memory. Currently, the default network memory size is pretty modest. For large scale jobs, it’s suggested to increase the total network memory fraction to at least 0.2 to achieve better performance. At the same time, you may also need to adjust the lower bound and upper bound of the network memory size, please refer to the memory configuration document for more information.)
结合下面一张内存图来计算一下flink各部分内存分配情况。
当前一个tm分配15G内存,
JVM Overhead默认0.1,100.1=1,需介于[192m, 1g]之间,即JVM Overhead为1G;
JVM Metaspace默认256M;
Network 默认为0.1,这里通过设置taskmanager.memory.network.min=2g,taskmanager.memory.network.max=2g将网络内存设置成固定2g;
Task Off-Heap默认为0,设置成128m,
Framework Off-Heap默认128m,设置成512m,其中256m给taskmanager.memory.framework.off-heap.batch-shuffle.size用于batch shuffle;
Managed Memory为(15g-1g-256m) 0.4=5.5g;
Task Heap为剩下的15g-1g-256m-2g-128m-512m-5.5g-128m=5.5g.

其他
TaskManager 容错
在我们实际生产中有可能会有程序的错误、网络的抖动、硬件的故障等问题造成 TaskManager 无法连接,甚至直接挂掉。我们在日志中常见的就是 TaskManagerLost 这样的报错。对于这种情况需要进行作业重启,在重启的过程中需要重新申请资源和重启 TaskManager 进程,这种性能消耗代价是非常高昂的。
能够支持在 Flink 集群当中始终持有少量的冗余的 TaskManager,这些冗余的 TaskManager 可以用于在单点故障的时候快速的去恢复,而不需要等待一个重新的资源申请的过程。
通过配置 slotmanager.redundant-taskmanager-num 可以实现冗余 TaskManager。这里所谓的冗余 TaskManager 并不是完完全全有两个 TaskManager 是空负载运行的,而是说相比于我所需要的总共的资源数量,会多出两个 TaskManager。
任务可能是相对比较均匀的分布在上面,在能够在利用空闲 TaskManager 的同时,也能够达到一个相对比较好的负载。 一旦发生故障的时候,可以去先把任务快速的调度到现有的还存活的 TaskManager 当中,然后再去进行新一轮的资源申请。
任务平铺分布
问题描述:
调度不均的问题,可能部分 tm 放的任务很满,有的则放的比较松散。
假设一个任务拓扑逻辑为:Vertex A(p=2)->Vertex B(p=4)->Vertex C(p=2)。
基于slot共享和本地数据传输优先的划分策略,划分为四个ExecutionSlotSharingGroup:{A1,B1,C1}、{A2,B2,C2}、{B3}、{B4},
如果资源配置将每个Taskmanager划分为2个Slot,就可能出现以下分配:
当前Slot划分是平均划分内存,对cpu没有做限制。上诉分配会导致节点负载不均衡,若A、C Task计算资源耗费较多,TaskManager1将会成为计算的瓶颈,理想情况下我们希望分配方式是:
通过参数 cluster.evenly-spread-out-slots,这样的参数能够控制它,去进行一个相对比较均衡的调度。
(注意:
在standalone模式下,在这种模式下因为事先定义好了有多少个 TaskManager,每个 TaskManager 上有多少 slot,才能更好达到一个均衡的效果。
在yarn模式下,tm的个数是根据任务动态计算出来的,tm的注册有先后顺序,因此并不能达到一个很好的效果。
可以尝试条大resourcemanager.taskmanager-timeout,默认30s,即当前任务执行完成之后tm释放的时间。如果一个工作流分为多个任务,第一个任务可能会出现不均衡,如果后面的任务能在timeout时间内提交,能部分达到一个均衡的目的。
)
其他一些参数
这些参数没有一一进行测试,大家有兴趣可以试试
- table.optimizer.join-reorder-enabled = true:需要手动打开,目前各大引擎的 JoinReorder 少有默认打开的,在统计信息比较完善时,是可以打开的,一般来说 reorder 错误的情况是比较少见的。
- table.optimizer.join.broadcast-threshold = 10_1024_1024:从默认值 1MB 可以适当调大。
- taskmanager.network.blocking-shuffle.type = mmap:默认file,Shuffle read 使用 mmap 的方式,直接靠系统来管理内存,是比较方便的形式。注意mmap 的内存使用量不受配置的内存限制的影响,但一些资源框架(如 yarn)会跟踪此内存使用量并在内存超过某个阈值时终止容器。
- cluster.evenly-spread-out-slots = true:在调度 Task 时均匀调度到每个 TaskManager 中,这有利于使用所有资源。
- jobmanager.execution.failover-strategy = region:默认全局重试,需打开 region 重试才能 enable 单点的 failover。
- restart-strategy = fixed-delay:重试策略需要手动设置,默认是不重试的。
- table.exec.shuffle-mode=ALL_EDGES_BLOCKING,默认为ALL_EDGES_BLOCKING,表示所有的边都会用 blocking shuffle,不过大家可以试一下 POINTWISE_EDGES_PIPELINED,表示 forward 和 rescale edges 会自动开始 pipeline 模式。
- taskmanager.numberOfTaskSlots:slot数量。需要注意:
- 在yarn模式使用的时候会受到yarn.scheduler.maximum-allocation-vcores值的影响。
- 此处指定的slot数量如果超过yarn的maximum-allocation-vcores,flink启动会报错。
- 在yarn模式,flink启动的task manager个数可以参照如下计算公式:num_of_manager = ceil(parallelism / slot) 即并行度除以slot个数,结果向上取整。
parallelism设置造成数据倾斜
需要合理设置任务tm的slot数量和每一个任务的parallelism。具体个数需要根据内存和cpu cores来判断,通常单个slot的managed memory 能分配到300 - 800MB,单个task heap memory能分配到300-500M 足够。network memory默认比例flink 进程内存的0.1,但批处理场景下还有一部分会划分给taskmanager.network.sort-shuffle.min-buffers,而这部分内存不是将其除以slot数量均匀分配的,因此网络内存太小可能会造成内存不足,根据日志增加这部分内存直至不报错为止。
当任务有多个source,且任务链较长的时候,parallelism设置不合理会导致一部分tm连续执行多个任务,而一部分tm执行较少任务而出现数据倾斜,从而导致内存溢出。
MR/hive on TEZ对比
简单做个比较两个数据集做分区排序按小时去重,然后union。

若有收获,就点个赞吧
0 人点赞
