upsert-kafka连接器sink,如果插入表的字段为空,报错抛异常,修改配置:
table.exec.sink.not-null-enforcer=drop
默认为error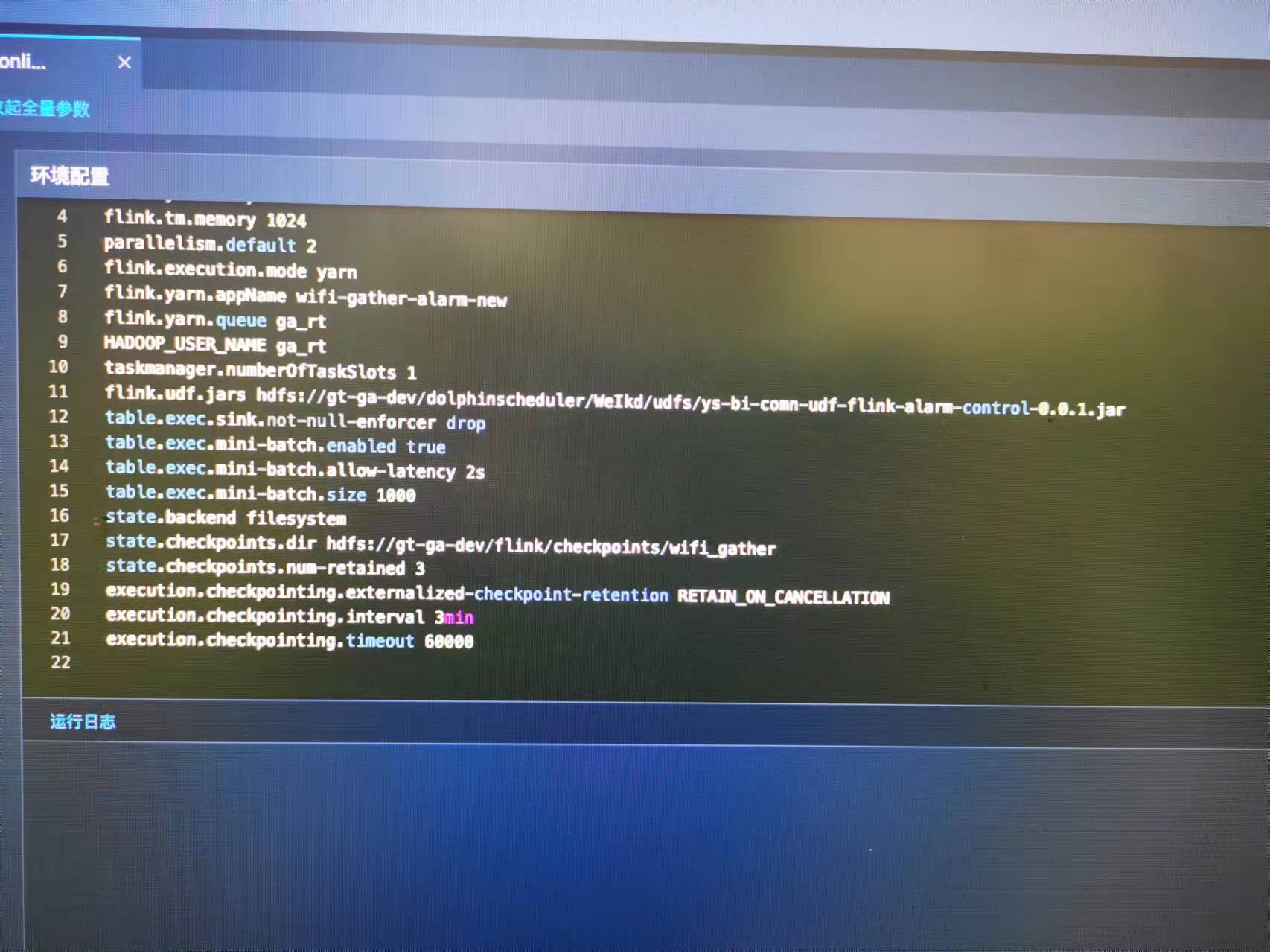
离线:
调度器.
主要配置
1、jobmanager.adaptive-scheduler.min-parallelism-increase
并行度扩增的最小增加值,默认1
2、jobmanager.adaptive-scheduler.resource-stabilization-timeout
资源稳定超时定义了如果可用资源少于所需但足够的资源,JobManager 将等待的时间。 一旦有足够的资源来运行作业,超时就会开始。 一旦此超时时间过去,作业将使用可用资源开始执行。如果 scheduler-mode 配置为 REACTIVE,此配置值将默认为 0,以便作业立即使用可用资源启动。默认10 s
对资源不足有效,资源充足直接获取资源执行
3、jobmanager.adaptive-scheduler.resource-wait-timeout
jobmanager.adaptive-scheduler.resource-wait-timeout=30min
JobManager 在作业提交或重新启动后等待获取所有必需资源的最长时间。 一旦过去,它将尝试以较低的并行度运行作业,或者如果无法获取最小数量的资源则失败。增加此值将使集群对临时资源短缺更具弹性(例如,有更多时间重新启动失败的 TaskManager)。设置负的持续时间将禁用资源超时:JobManager 将无限期地等待资源出现。如果 scheduler-mode 配置为 REACTIVE,此配置值将默认为负值以禁用资源超时。 默认5 min
4.2.其他可能相关的配置
1、slot.request.timeout=3600000
请求slot的超时时间,默认300000 dw:ms
2、slot.idle.timeout
slot空闲超时时间,默认50000 dw:ms
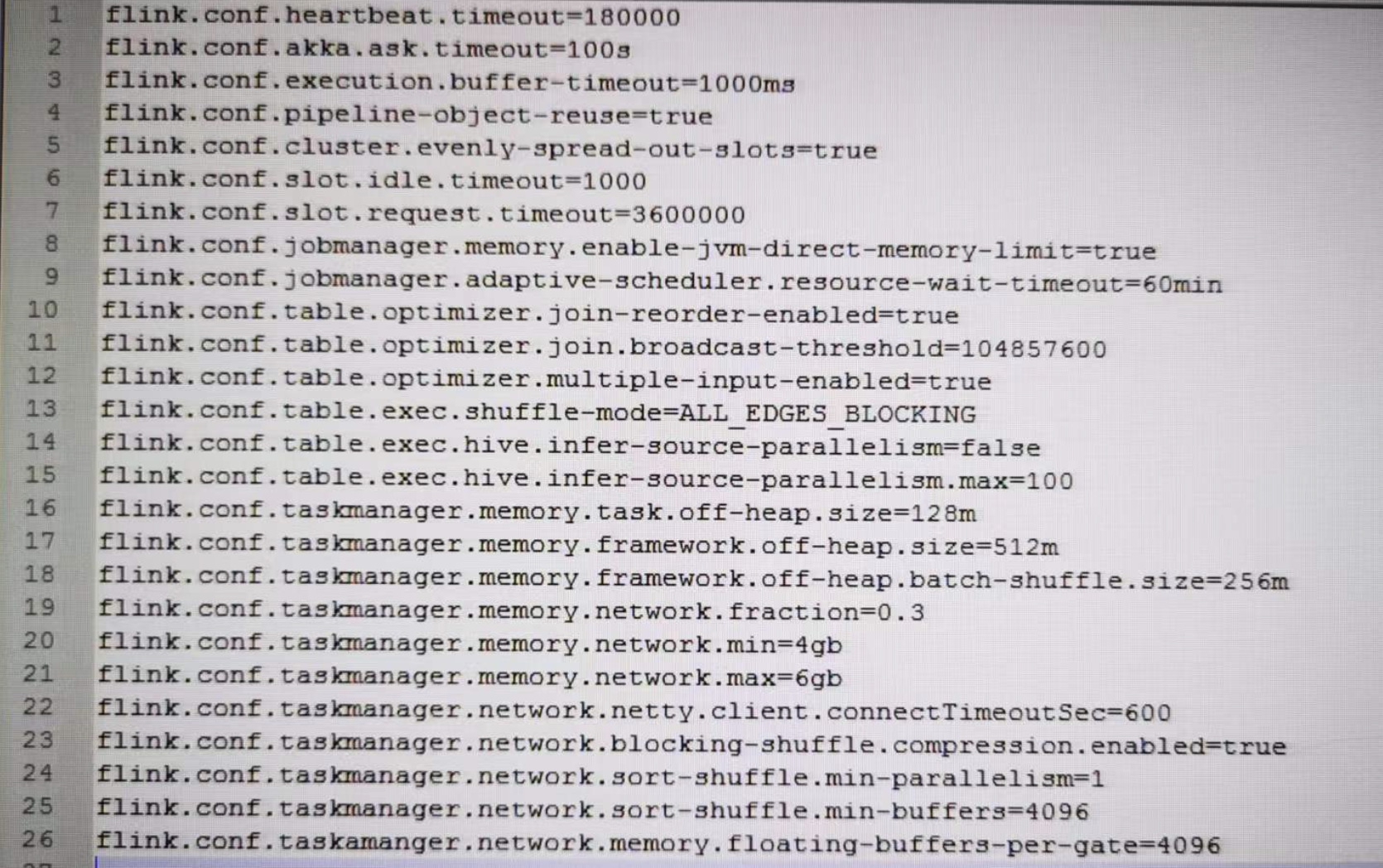
SORT
当使用sort blocking shuffle的时候有些配置需要适配:
- taskmanager.network.sort-shuffle.min-buffers: 配置该选项以控制数据写缓存大小。对于大规模的任务而言,你可能需要调大这个值,正常几百兆内存就足够了。因为这部分内存是从网络内存分配的,所以想要增大这个配置值,你可能还需要通过调整 taskmanager.memory.network.fraction,taskmanager.memory.network.min 和 taskmanager.memory.network.max 这几个参数来增大总的网络内存大小以避免出现 “Insufficient number of network buffers” 的错误。
- taskmanager.memory.framework.off-heap.batch-shuffle.size: 配置该选项以控制数据读取缓存大小。对于大规模的任务而言,你可能需要调大这个值,正常几百兆内存就足够了。因为这部分内存是从框架堆外内存中切分出来的,所以想要增大这个配置值,你还需要通过调整 taskmanager.memory.framework.off-heap.size 来增大框架堆外内存以避免出现直接内存溢出的错误。
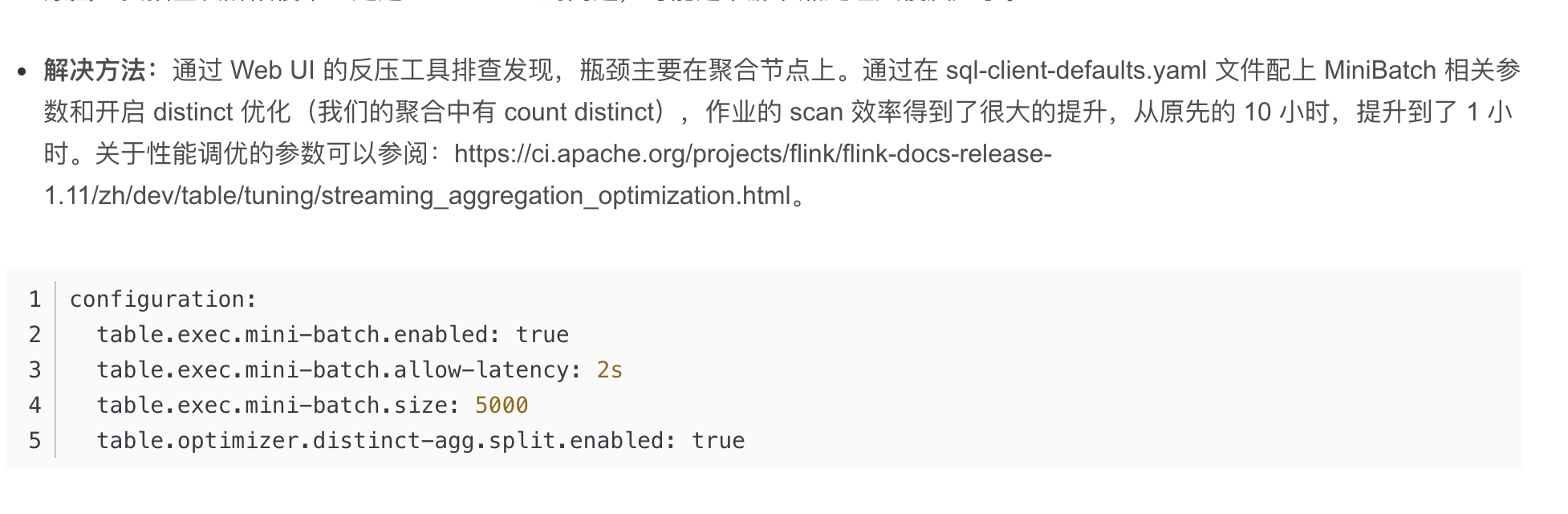
性能调优
- 下面这些建议可以帮助你实现更好的性能,这些对于大规模批作业尤其重要:
- 如果你使用机械硬盘作为存储设备,请总是使用 Sort Shuffle,因为这可以极大的提升稳定性和性能。从 1.15 开始,Sort Shuffle 已经成为默认实现,对于 1.14 以及更低版本,你需要通过将 taskmanager.network.sort-shuffle.min-parallelism 配置为 1 以手动开启 Sort Shuffle。
- 对于 Sort Shuffle 和 Hash Shuffle 两种实现,你都可以考虑开启 数据压缩 除非数据本身无法压缩。从 1.15 开启,数据压缩是默认开启的,对于 1.14 以及更低版本你需要手动开启。
- 当使用 Sort Shuffle 时,减少 独占网络缓冲区 并增加 流动网络缓冲区 有利于性能提升。对于 1.14 以及更高版本,建议将 taskmanager.network.memory.buffers-per-channel 设为 0 并且将 taskmanager.network.memory.floating-buffers-per-gate 设为一个较大的值 (比如,4096)。这有两个主要的好处:1) 首先这解耦了并发与网络内存使用量,对于大规模作业,这降低了遇到 “Insufficient number of network buffers” 错误的可能性;2) 网络缓冲区可以根据需求在不同的数据通道间共享流动,这可以提高了网络缓冲区的利用率,进而可以提高性能。
- 增大总的网络内存。目前网络内存的大小是比较保守的。对于大规模作业,为了实现更好的性能,建议将 网络内存比例 增加至至少 0.2。为了使调整生效,你可能需要同时调整 网络内存大小下界 以及 网络内存大小上界。要获取更多信息,你可以参考这个 内存配置文档。
- 增大数据写出内存。像上面提到的那样,对于大规模作业,如果有充足的空闲内存,建议增大taskmanager.network.sort-shuffle.min-buffers 数据写出内存 大小到至少 (2 * 并发数)。注意:在你增大这个配置后,为避免出现 “Insufficient number of network buffers” 错误,你可能还需要增大总的网络内存大小。
- 增大数据读取内存。像上面提到的那样,对于大规模作业,建议增大 数据读取内存 taskmanager.memory.framework.off-heap.batch-shuffle.size 到一个较大的值 (比如,256M 或 512M)。因为这个内存是从框架的堆外内存切分出来的,因此你必须增加相同的内存大小到 taskmanager.memory.framework.off-heap.size 以避免出现直接内存溢出错误。
Buffer数量的推算规则是:
- 发送端ResultPartition分配的Buffer总数为ResultSubpartition的数量+1,且为了防止倾斜,每个ResultSubpartition可获得的Buffer数不能多于taskmanager.network.memory.max-buffers-per-channel(默认值10)。
- 接收端每个InputChannel独享(exclusive)的Buffer数为taskmanager.network.memory.buffers-per-channel(默认值2),InputGate可额外提供的浮动(floating)Buffer数为taskmanager.network.memory.floating-buffers-per-gate(默认值8)。
也就是说,如果一个作业的ExecutionGraph确定,那么我们可以用上述规则配合Tasks之间的DistributionPattern(POINTWISE / ALL_TO_ALL)估计网络缓存的需求量。

若有收获,就点个赞吧
0 人点赞
