:::info
日期:2019 年 08 月 01 日
作者:Russ Cox
原文链接:https://go.dev/blog/experiment
:::
介绍
这是我上周在 GopherCon 2019 上演讲的博客文章版本。
点击查看【codepen】
我们都在通向 Go 2 的道路上,但我们没有人确切地知道这条路通向哪里,有时甚至不知道这条路会走向哪个方向。 这篇文章讨论了我们如何实际找到并遵循 Go 2 的路径。 这是流程的样子。
我们用现在的 Go 进行实验,以更好地理解它,了解哪些行得通,哪些行不通。 然后我们尝试可能的变化,以更好地理解它们,再次了解哪些有效,哪些无效。 根据我们从这些实验中学到的东西,我们进行了简化。 然后我们再次进行实验。 然后我们再次简化。 等等。 等等。
简化的四个 R
在这个过程中,我们可以通过四种主要的方式来简化编写 Go 程序的整体体验:重塑、重新定义、移除和限制。
通过重塑来简化
我们简化的第一种方法是将存在的事物重塑为一种新形式,最终使整体更简单。
我们编写的每个 Go 程序都是测试 Go 本身的实验。 在 Go 的早期,我们很快了解到编写像 addToList 函数这样的代码是很常见的:
func addToList(list []int, x int) []int {n := len(list)if n+1 > cap(list) {big := make([]int, n, (n+5)*2)copy(big, list)list = big}list = list[:n+1]list[n] = xreturn list}
我们会为字节片和字符串片等编写相同的代码。 我们的程序太复杂了,因为 Go 太简单了。
所以我们在我们的程序中采用了许多像 addToList 这样的函数,并将它们重组为 Go 本身提供的一个函数。 添加 append 使 Go 语言稍微复杂一些,但总的来说,它使编写 Go 程序的整体体验变得更简单,即使考虑到学习 append 的成本。
这是另一个例子。 对于 Go 1,我们查看了 Go 发行版中非常多的开发工具,并将它们重组为一个新命令。
5a 8g5g 8l5l cgo6a gobuild6cov gofix → go6g goinstall6l gomake6nm gopack8a govet
go 命令现在非常重要,以至于很容易忘记我们在没有它的情况下走了这么久以及涉及多少额外的工作。
我们向 Go 发行版添加了代码和复杂性,但总的来说我们简化了编写 Go 程序的体验。 新结构还为其他有趣的实验创造了空间,我们稍后会看到。
通过重新定义来简化
我们简化的第二种方法是重新定义我们已经拥有的功能,让它做更多的事情。 就像通过重塑来简化一样,通过重新定义来简化使程序更易于编写,但现在没有什么新东西可以学习了。
例如, append 最初定义为仅从切片读取。 附加到字节切片时,您可以附加来自另一个字节切片的字节,但不能附加来自字符串的字节。 我们重新定义了 append 以允许从字符串追加,而无需向语言添加任何新内容。
var b []bytevar more []byteb = append(b, more...) // okvar b []bytevar more stringb = append(b, more...) // ok later
通过删除来简化
我们简化的第三种方法是在功能不如我们预期有用或不重要时删除它。 删除功能意味着少一件事要学习,少一件事要修复错误,少一件事会分散注意力或使用不当。 当然,删除也会迫使用户更新现有程序,这可能会使它们变得更加复杂,以弥补删除的不足。 但总体结果仍然可以是编写 Go 程序的过程变得更简单。
一个例子是当我们从语言中删除非阻塞通道操作的布尔形式时:
ok := c <- x // before Go 1, was non-blocking sendx, ok := <-c // before Go 1, was non-blocking receive
这些操作也可以使用 select 来完成,这使得需要决定使用哪种表单变得混乱。 删除它们简化了语言,而不会降低其功能。
通过限制来简化
我们也可以通过限制允许的内容来简化。 从第一天起,Go 就限制了 Go 源文件的编码:它们必须是 UTF-8。 这种限制使每个尝试读取 Go 源文件的程序变得更简单。 这些程序不必担心以 Latin-1 或 UTF-16 或 UTF-7 或其他任何形式编码的 Go 源文件。
另一个重要的限制是程序格式化的 gofmt。 没有什么会拒绝未使用 gofmt 格式化的 Go 代码,但我们已经建立了一个约定,即重写 Go 程序的工具将它们保留为 gofmt 形式。 如果您也将程序保持在 gofmt 形式,那么这些重写器不会进行任何格式更改。 当您比较前后,您看到的唯一差异是真正的变化。 这种限制简化了程序重写器,并导致了 goimports、gorename 等许多成功的实验。
Go 发展进程
这种实验和简化的循环是我们过去十年所做工作的一个很好的模型。 但它有一个问题:它太简单了。 我们不能只进行实验和简化。
我们必须发送结果。 我们必须使其可供使用。 当然,使用它可以进行更多的实验,并且可能会更加简化,并且过程会不断循环。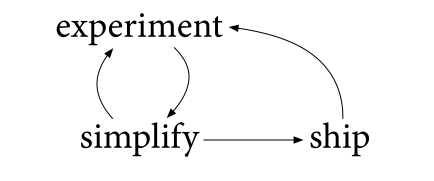
我们于 2009 年 11 月 10 日第一次向大家发布了 Go。然后,在你们的帮助下,我们于 2012 年 3 月一起发布了 Go 1。从那时起,我们已经发布了 12 个 Go 版本。 所有这些都是重要的里程碑,可以进行更多的实验,帮助我们更多地了解 Go,当然还可以使 Go 可用于生产。
当我们发布 Go 1 时,我们明确地将重点转移到使用 Go,以便在尝试涉及语言更改的任何更多简化之前更好地理解该版本的语言。 我们需要花时间进行实验,真正了解哪些有效,哪些无效。
当然,自 Go 1 以来,我们已经发布了 12 个版本,因此我们仍在试验、简化和交付。 但是我们专注于在不进行重大语言更改和不破坏现有 Go 程序的情况下简化 Go 开发的方法。 例如,Go 1.5 发布了第一个并发垃圾收集器,然后随后的版本对其进行了改进,通过消除暂停时间作为持续关注来简化 Go 开发。
在 2017 年的 Gophercon 大会上,我们宣布经过五年的试验,现在是时候考虑简化 Go 开发的重大变化了。 我们通向 Go 2 的路径与通向 Go 1 的路径完全相同:试验、简化和交付,朝着简化 Go 开发的总体目标迈进。
对于 Go 2,我们认为最重要的具体主题是错误处理、泛型和依赖关系。 从那时起,我们意识到另一个重要的主题是开发人员工具。
这篇文章的其余部分讨论了我们在每个领域的工作如何遵循这条道路。 在此过程中,我们将绕道而行,停下来检查 Go 1.13 中即将发布的错误处理的技术细节。
错误
当所有输入都有效且正确并且程序所依赖的任何内容都没有失败时,编写一个在所有情况下都以正确方式工作的程序已经足够困难了。 当您将错误添加到组合中时,编写一个无论出现什么问题都能以正确方式运行的程序更加困难。
作为考虑 Go 2 的一部分,我们想更好地了解 Go 是否可以帮助简化这项工作。
有两个不同的方面可以简化:错误值和错误语法。 我们将依次查看每一个,并通过我承诺的技术绕道重点关注 Go 1.13 错误值更改。
错误值
错误值必须从某处开始。 这是 os 包第一个版本的 Read 函数:
export func Read(fd int64, b *[]byte) (ret int64, errno int64) {r, e := syscall.read(fd, &b[0], int64(len(b)));return r, e}
还没有文件类型,也没有错误类型。 Read 和包中的其他函数直接从底层 Unix 系统调用返回一个 errno int64。
此代码于 2008 年 9 月 10 日下午 12:14 签入。 就像当时的一切一样,这是一个实验,代码变化很快。 两小时五分钟后,API 发生了变化:
export type Error struct { s string }func (e *Error) Print() { … } // to standard error!func (e *Error) String() string { … }export func Read(fd int64, b *[]byte) (ret int64, err *Error) {r, e := syscall.read(fd, &b[0], int64(len(b)));return r, ErrnoToError(e)}
这个新 API 引入了第一个错误类型。 错误包含一个字符串,可以返回该字符串并将其打印为标准错误。
这里的目的是在整数代码之外进行推广。 我们从过去的经验中知道,操作系统错误编号的表示方式太有限了,它可以简化程序,而不必将有关错误的所有细节硬塞到 64 位中。 过去使用错误字符串对我们来说效果很好,所以我们在这里做了同样的事情。 这个新 API 持续了七个月。
第二年 4 月,在更多使用接口的经验之后,我们决定通过使 os.Error 类型本身成为接口来进一步推广并允许用户定义的错误实现。 我们通过删除 Print 方法进行了简化。
两年后的 Go 1,根据 Roger Peppe 的建议,os.Error 成为内置错误类型,String 方法更名为 Error。 从那以后什么都没有改变。 但是我们已经编写了很多 Go 程序,因此我们已经尝试了很多如何最好地实现和使用错误。
错误是值
使错误成为一个简单的接口并允许许多不同的实现意味着我们可以使用整个 Go 语言来定义和检查错误。 我们喜欢说错误就是值,就像任何其他 Go 值一样。
这是一个例子。 在 Unix 上,尝试拨打网络连接以使用 connect 系统调用结束。 该系统调用返回一个 syscall.Errno,它是一个命名整数类型,表示系统调用错误号并实现错误接口:
package syscalltype Errno int64func (e Errno) Error() string { ... }const ECONNREFUSED = Errno(61)... err == ECONNREFUSED ...
syscall 包还为主机操作系统定义的错误号定义了命名常量。 在这种情况下,在此系统上,ECONNREFUSED 的编号为 61。从函数中获取错误的代码可以使用普通值相等来测试错误是否为 ECONNREFUSED。
向上移动一个级别,在包 os 中,使用更大的错误结构报告任何系统调用失败,该结构记录除了错误之外还尝试了哪些操作。 有一些这样的结构。 这个 SyscallError 描述了一个错误,它调用了一个特定的系统调用,没有记录额外的信息:
package ostype SyscallError struct {Syscall stringErr error}func (e *SyscallError) Error() string {return e.Syscall + ": " + e.Err.Error()}
再上一层,在包 net 中,使用更大的错误结构报告任何网络故障,该结构记录周围网络操作的详细信息,例如拨号或侦听,以及涉及的网络和地址:
package nettype OpError struct {Op stringNet stringSource AddrAddr AddrErr error}func (e *OpError) Error() string { ... }
将这些放在一起,net.Dial 等操作返回的错误可以格式化为字符串,但它们也是结构化的 Go 数据值。 在这种情况下,错误是 net.OpError,它将上下文添加到 os.SyscallError,后者将上下文添加到 syscall.Errno:
c, err := net.Dial("tcp", "localhost:50001")// "dial tcp [::1]:50001: connect: connection refused"err is &net.OpError{Op: "dial",Net: "tcp",Addr: &net.TCPAddr{IP: ParseIP("::1"), Port: 50001},Err: &os.SyscallError{Syscall: "connect",Err: syscall.Errno(61), // == ECONNREFUSED},}
当我们说错误是值时,我们的意思是整个 Go 语言都可以定义它们,也意味着整个 Go 语言都可以检查它们。 这是包 net 中的一个示例。
事实证明,当您尝试使用套接字连接时,大多数情况下您会获得连接或连接被拒绝,但有时您会无缘无故地获得虚假的 EADDRNOTAVAIL。 Go 通过重试来保护用户程序免受这种故障模式的影响。 为此,它必须检查错误结构以找出内部的 syscall.Errno 是否为 EADDRNOTAVAIL。
这是代码:
func spuriousENOTAVAIL(err error) bool {if op, ok := err.(*OpError); ok {err = op.Err}if sys, ok := err.(*os.SyscallError); ok {err = sys.Err}return err == syscall.EADDRNOTAVAIL}
类型断言剥离了任何 net.OpError 包装。 然后第二种类型的断言剥离任何 os.SyscallError 包装。 然后该函数检查解包错误是否与 EADDRNOTAVAIL 相等。
我们从多年的经验中学到的,从这个 Go 错误实验中学到的是,能够定义错误接口的任意实现,让完整的 Go 语言可用于构造和解构错误,这是非常强大的, 并且不需要使用任何单一的实现。
这些属性——错误就是值,并且没有一个必需的错误实现——非常重要。 不强制执行一个错误实现使每个人都可以尝试错误可能提供的附加功能,从而产生许多包,例如 github.com/pkg/errors、gopkg.in/errgo.v2、github.com/hashicorp/errwrap、upspin .io/errors、github.com/spacemonkeygo/errors 等。
但是,不受约束的实验的一个问题是,作为客户端,您必须对可能遇到的所有可能实现的联合进行编程。 Go 2 似乎值得探索的一种简化是以商定的可选接口的形式定义常用功能的标准版本,以便不同的实现可以互操作。
Unwrap
这些包中最常添加的功能是一些可以调用的方法,可以从错误中移除上下文,返回内部的错误。 包对这个操作使用不同的名称和含义,有时它会删除一层上下文,而有时它会删除尽可能多的级别。
对于 Go 1.13,我们引入了一个约定,即向内部错误添加可移除上下文的错误实现应该实现一个 Unwrap 方法,该方法返回内部错误,展开上下文。 如果没有适合向调用者公开的内部错误,则错误不应该有 Unwrap 方法,或者 Unwrap 方法应该返回 nil。
// Go 1.13 optional method for error implementations.interface {// Unwrap removes one layer of context,// returning the inner error if any, or else nil.Unwrap() error}
调用这个可选方法的方法是调用辅助函数 errors.Unwrap,它处理错误本身为零或根本没有 Unwrap 方法等情况。
package errors// Unwrap returns the result of calling// the Unwrap method on err,// if err’s type defines an Unwrap method.// Otherwise, Unwrap returns nil.func Unwrap(err error) error
我们可以使用 Unwrap 方法编写一个更简单、更通用的spuriousENOTAVAIL 版本。 不是寻找特定的错误包装器实现,如 net.OpError 或 os.SyscallError,一般版本可以循环,调用 Unwrap 来删除上下文,直到它到达 EADDRNOTAVAIL 或没有错误剩余:
func spuriousENOTAVAIL(err error) bool {for err != nil {if err == syscall.EADDRNOTAVAIL {return true}err = errors.Unwrap(err)}return false}
然而,这个循环是如此常见,以至于 Go 1.13 定义了第二个函数,errors.Is,它反复解开错误寻找特定目标。 因此,我们可以通过对 errors.Is 的单个调用来替换整个循环:
func spuriousENOTAVAIL(err error) bool {return errors.Is(err, syscall.EADDRNOTAVAIL)}
在这一点上,我们可能甚至不会定义函数; 调用错误同样清晰且简单。直接在调用站点。
Go 1.13 还引入了一个函数 errors.As,它会解包直到找到特定的实现类型。
如果您想编写处理任意包装错误的代码,则 errors.Is 是错误相等性检查的包装感知版本:
err == target→errors.Is(err, target)
而 errors.As 是错误类型断言的包装感知版本:
target, ok := err.(*Type)if ok {...}→var target *Typeif errors.As(err, &target) {...}
解开还是不解开?
是否可以解包错误是 API 决定,与是否导出结构字段是 API 决定一样。 有时向调用代码公开该细节是合适的,有时则不然。 如果是,则实施 Unwrap。 如果不是,请不要实现 Unwrap。
到现在为止, fmt.Errorf 还没有向调用者检查公开以 %v 格式化的底层错误。 也就是说, fmt.Errorf 的结果无法解包。 考虑这个例子:
// errors.Unwrap(err2) == nil// err1 is not available (same as earlier Go versions)err2 := fmt.Errorf("connect: %v", err1)
如果将 err2 返回给调用者,则该调用者永远无法打开 err2 并访问 err1。 我们在 Go 1.13 中保留了该属性。
当您确实希望允许解包 fmt.Errorf 的结果时,我们还添加了一个新的打印动词 %w,其格式类似于 %v,需要一个错误值参数,并使产生的错误的 Unwrap 方法返回该参数。 在我们的示例中,假设我们将 %v 替换为 %w:
// errors.Unwrap(err4) == err3// (%w is new in Go 1.13)err4 := fmt.Errorf("connect: %w", err3)
现在,如果将 err4 返回给调用者,则调用者可以使用 Unwrap 来检索 err3。
需要注意的是,像“永远使用 %v(或永远不实施 Unwrap)”或“永远使用 %w(或永远实施 Unwrap)”这样的绝对规则与像“永远不导出结构域”或“永远实施 Unwrap”这样的绝对规则一样错误。 导出结构字段。” 相反,正确的决定取决于调用者是否应该能够检查并依赖于使用 %w 或实现 Unwrap 公开的附加信息。
作为这一点的说明,标准库中已经有导出 Err 字段的每个错误包装类型现在也有一个返回该字段的 Unwrap 方法,但具有未导出错误字段的实现没有,并且 fmt.Errorf 的现有用法与 %v 仍然使用 %v,而不是 %w。
错误值打印(已放弃)
随着 Unwrap 的设计草案,我们还发布了一个可选方法的设计草案,用于更丰富的错误打印,包括堆栈帧信息和对本地化、翻译错误的支持。
// Optional method for error implementationstype Formatter interface {Format(p Printer) (next error)}// Interface passed to Formattype Printer interface {Print(args ...interface{})Printf(format string, args ...interface{})Detail() bool}
这个不像Unwrap那么简单,这里就不赘述了。 当我们在冬天与 Go 社区讨论设计时,我们了解到设计不够简单。 实现单个错误类型太难了,而且对现有程序的帮助也不够。 总的来说,它并没有简化 Go 开发。
由于这次社区讨论,我们放弃了这种印刷设计。
错误语法
那是错误值。 让我们简要地看一下错误语法,这是另一个被放弃的实验。
这是标准库中 compress/lzw/writer.go 中的一些代码:
// Write the savedCode if valid.if e.savedCode != invalidCode {if err := e.write(e, e.savedCode); err != nil {return err}if err := e.incHi(); err != nil && err != errOutOfCodes {return err}}// Write the eof code.eof := uint32(1)<<e.litWidth + 1if err := e.write(e, eof); err != nil {return err}
乍一看,这段代码大约是错误检查的一半。 读到这里,我的眼睛一亮。 而且我们知道编写和阅读乏味的代码很容易被误读,这使它成为难以发现的错误的好地方。 例如,这三个错误检查中的一个与其他错误检查不同,在快速浏览时很容易错过这一事实。 如果您正在调试此代码,需要多长时间才能注意到这一点?
在去年的 Gophercon 上,我们展示了一个由关键字 check 标记的新控制流结构的设计草案。 Check 使用函数调用或表达式的错误结果。 如果错误非零,则检查返回该错误。 否则,检查将评估为调用的其他结果。 我们可以使用 check 来简化 lzw 代码:
// Write the savedCode if valid.if e.savedCode != invalidCode {check e.write(e, e.savedCode)if err := e.incHi(); err != errOutOfCodes {check err}}// Write the eof code.eof := uint32(1)<<e.litWidth + 1check e.write(e, eof)
这个版本的相同代码使用了检查,它删除了四行代码,更重要的是强调了对 e.incHi 的调用允许返回 errOutOfCodes。
也许最重要的是,该设计还允许定义错误处理程序块,以便在以后的检查失败时运行。 这将使您只需编写一次共享上下文添加代码,就像在此代码段中一样:
handle err {err = fmt.Errorf("closing writer: %w", err)}// Write the savedCode if valid.if e.savedCode != invalidCode {check e.write(e, e.savedCode)if err := e.incHi(); err != errOutOfCodes {check err}}// Write the eof code.eof := uint32(1)<<e.litWidth + 1check e.write(e, eof)
本质上,check 是编写 if 语句的一种简短方式,handle 类似于 defer,但仅用于错误返回路径。 与其他语言中的异常相比,这种设计保留了 Go 的重要属性,即每个潜在的失败调用都在代码中明确标记,现在使用 check 关键字而不是 if err != nil。
这种设计的最大问题是句柄与 defer 重叠太多,并且以令人困惑的方式重叠。
5 月,我们发布了一个包含三个简化的新设计:为了避免与 defer 混淆,该设计放弃了句柄,转而使用 defer; 为了匹配 Rust 和 Swift 中的类似想法,设计更名为 check 以尝试; 为了允许像 gofmt 这样的现有解析器可以识别的方式进行实验,它将检查(现在尝试)从关键字更改为内置函数。
现在相同的代码如下所示:
defer errd.Wrapf(&err, "closing writer")// Write the savedCode if valid.if e.savedCode != invalidCode {try(e.write(e, e.savedCode))if err := e.incHi(); err != errOutOfCodes {try(err)}}// Write the eof code.eof := uint32(1)<<e.litWidth + 1try(e.write(e, eof))
我们在 6 月的大部分时间里都在 GitHub 上公开讨论这个提议。
检查或尝试的基本思想是缩短每次错误检查时重复的语法数量,特别是从视图中删除 return 语句,保持错误检查明确并更好地突出有趣的变化。 然而,在公开反馈讨论中提出的一个有趣的观点是,如果没有明确的 if 语句和 return,就没有地方可以放置调试打印,也没有地方可以放置断点,也没有代码可以在代码覆盖率结果中显示为未执行。 我们所追求的好处是以让这些情况变得更加复杂为代价的。 总而言之,从这一点以及其他方面考虑,总体结果是否会更简单的 Go 开发并不清楚,因此我们放弃了这个实验。
这就是错误处理的一切,这是今年的主要焦点之一。
泛型
现在讨论一些争议较小的东西:泛型。
我们为 Go 2 确定的第二个大主题是某种编写带有类型参数的代码的方法。 这将允许编写通用数据结构并编写适用于任何类型的切片、任何类型的通道或任何类型的映射的通用函数。 例如,这是一个通用的通道过滤器:
// Filter copies values from c to the returned channel,// passing along only those values satisfying f.func Filter(type value)(f func(value) bool, c <-chan value) <-chan value {out := make(chan value)go func() {for v := range c {if f(v) {out <- v}}close(out)}()return out}
自从 Go 开始工作以来,我们一直在考虑泛型,我们在 2010 年编写并拒绝了我们的第一个具体设计。到 2013 年底,我们编写并拒绝了另外三个设计。四个被放弃的实验,但没有失败的实验,我们从 他们,就像我们从检查和尝试中学到的一样。 每一次,我们都了解到通往 Go 2 的道路并不在那个确切的方向上,我们注意到其他可能值得探索的方向。 但是到 2013 年,我们决定需要关注其他问题,因此我们将整个主题搁置了几年。
去年我们再次开始探索和试验,并在去年夏天的 Gophercon 上展示了基于合同理念的新设计。 我们继续进行实验和简化,并且一直在与编程语言理论专家合作以更好地理解设计。
总的来说,我希望我们朝着一个好的方向前进,朝着简化 Go 开发的设计迈进。 即便如此,我们也可能会发现这种设计也行不通。 我们可能不得不放弃这个实验并根据我们学到的东西调整我们的路径。 我们会发现的。
在 Gophercon 2019 上,Ian Lance Taylor 谈到了为什么我们可能想要向 Go 添加泛型,并简要预览了最新的设计草案。 有关详细信息,请参阅他的博客文章“为什么使用泛型?”
依赖
我们为 Go 2 确定的第三个大主题是依赖管理。
2010 年,我们发布了一个名为 goinstall 的工具,我们称之为“包安装实验”。 它下载了依赖项并将它们存储在你的 Go 分发树中,在 GOROOT 中。
当我们对 goinstall 进行试验时,我们了解到 Go 发行版和已安装的包应该分开保存,这样就可以在不丢失所有 Go 包的情况下更改为新的 Go 发行版。 因此,在 2011 年,我们引入了 GOPATH,这是一个环境变量,用于指定在主要 Go 发行版中找不到的包的位置。
添加 GOPATH 为 Go 包创建了更多位置,但通过将 Go 发行版与 Go 库分开,简化了整体 Go 开发。
兼容性
goinstall 实验有意省略了包版本控制的明确概念。 相反,goinstall 总是下载最新的副本。 我们这样做是为了我们可以专注于软件包安装的其他设计问题。
Goinstall 成为 Go get 的一部分,作为 Go 1 的一部分。当人们询问版本时,我们鼓励他们通过创建其他工具进行试验,他们确实做到了。 我们鼓励包 AUTHORS 为他们的用户提供与我们为 Go 1 库所做的相同的向后兼容性。 引用 Go 常见问题解答:
“供公众使用的软件包应该在发展过程中尽量保持向后兼容性。
如果需要不同的功能,请添加新名称而不是更改旧名称。
如果需要完全中断,请使用新的导入路径创建一个新包。”
这个约定通过限制作者可以做的事情来简化使用包的整体体验:避免对 API 的破坏性更改; 给新功能一个新名字; 并为全新的包装设计提供新的导入路径。
当然,人们一直在试验。 最有趣的实验之一是由古斯塔沃·尼迈耶 (Gustavo Niemeyer) 发起的。 他创建了一个名为 gopkg.in 的 Git 重定向器,它为不同的 API 版本提供了不同的导入路径,以帮助包作者遵循为新包设计提供新导入路径的约定。
例如,GitHub 存储库 go-yaml/yaml 中的 Go 源代码在 v1 和 v2 语义版本标签中具有不同的 API。 gopkg.in 服务器为它们提供不同的导入路径 gopkg.in/yaml.v1 和 gopkg.in/yaml.v2。
提供向后兼容性的约定,以便可以使用较新版本的包代替旧版本,这使得 go get 的非常简单的规则——“始终下载最新副本”——即使在今天也能很好地工作。
版本控制和供应商
但是在生产环境中,您需要更精确地了解依赖版本,以使构建可重现。
许多人尝试了应该是什么样子,构建满足他们需求的工具,包括 Keith Rarick 的 goven (2012) 和 Godep (2013)、Matt Butcher 的 glide (2014) 和 Dave Cheney 的 gb (2015)。 所有这些工具都使用您将依赖包复制到您自己的源代码控制存储库中的模型。 用于使这些包可用于导入的确切机制各不相同,但它们都比看起来更复杂。
经过社区范围的讨论,我们采纳了 Keith Rarick 的提议,为引用没有 GOPATH 技巧的复制依赖项添加明确支持。 这是通过重塑来简化的:就像 addToList 和 append 一样,这些工具已经实现了这个概念,但它比实际需要的更笨拙。 添加对供应商目录的明确支持使这些使用总体上更简单。
在 go 命令中发送供应商目录导致了对供应商本身的更多实验,我们意识到我们引入了一些问题。 最严重的是我们失去了包裹的唯一性。 之前,在任何给定的构建过程中,导入路径可能会出现在许多不同的包中,并且所有导入都指向同一个目标。 现在有了 vendoring,不同包中的相同导入路径可能会引用包的不同 vendored 副本,所有这些副本都将出现在最终生成的二进制文件中。
当时,我们没有这个属性的名称:包唯一性。 这就是 GOPATH 模型的工作方式。 直到它消失,我们才完全欣赏它。
这里有一个与检查和尝试错误语法建议相似的地方。 在那种情况下,我们依赖可见 return 语句的工作方式,直到我们考虑删除它时才意识到它的存在。
当我们添加供应商目录支持时,有许多不同的工具来管理依赖项。 我们认为,关于供应商目录格式和供应商元数据的明确协议将允许各种工具进行互操作,就像关于 Go 程序如何存储在文本文件中的协议一样,Go 编译器、文本编辑器和诸如 goimports 和 gorename。
结果证明这是天真的乐观。 销售工具都在微妙的语义方式上有所不同。 互操作需要更改它们以就语义达成一致,这可能会破坏它们各自的用户。 收敛没有发生。
Dep
在 2016 年的 Gophercon,我们开始努力定义一个工具来管理依赖项。 作为这项工作的一部分,我们对许多不同类型的用户进行了调查,以了解他们在依赖管理方面的需求,并且一个团队开始开发一个新工具,它成为了 dep。
Dep 旨在能够替换所有现有的依赖管理工具。 目标是通过将现有的不同工具重塑为单一工具来简化。 它部分实现了这一点。 通过在项目树的顶部只有一个供应商目录,Dep 还为其用户恢复了包的唯一性。
但是 dep 也引入了一个严重的问题,我们花了一段时间才完全理解。 问题是 dep 接受了 glide 的设计选择,以支持和鼓励对给定包的不兼容更改,而无需更改导入路径。
这是一个例子。 假设您正在构建自己的程序,并且需要一个配置文件,因此您使用流行的 Go YAML 包的第 2 版: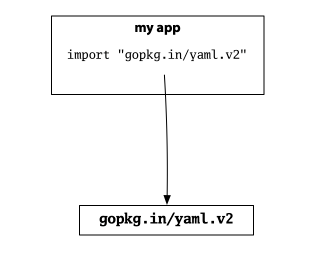
现在假设您的程序导入了 Kubernetes 客户端。 事实证明,Kubernetes 广泛使用 YAML,并且它使用相同流行软件包的第 1 版: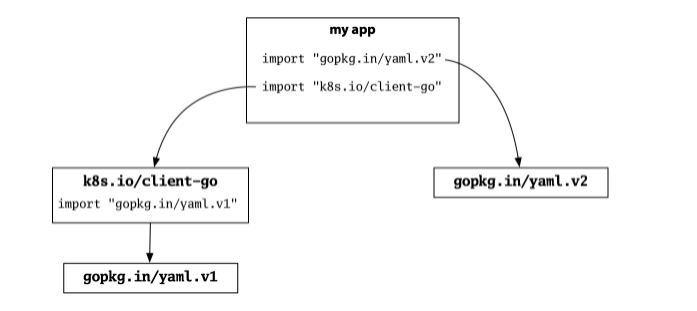
版本 1 和版本 2 具有不兼容的 API,但它们也具有不同的导入路径,因此对于给定导入的含义没有歧义。 Kubernetes 获得版本 1,您的配置解析器获得版本 2,一切正常。
Dep 放弃了这种模式。 yaml 包的版本 1 和版本 2 现在具有相同的导入路径,从而产生冲突。 对两个不兼容的版本使用相同的导入路径,再加上包的唯一性,就无法构建之前可以构建的程序: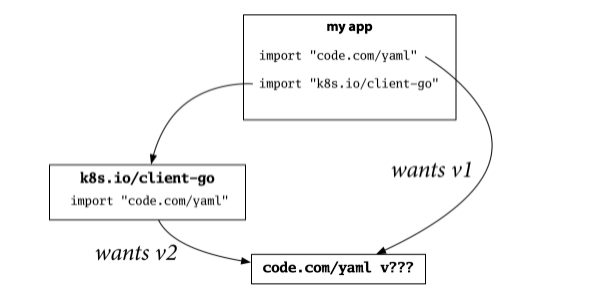
我们花了一段时间才理解这个问题,因为我们一直在应用“新 API 意味着新的导入路径”约定,以至于我们认为这是理所当然的。 dep 实验帮助我们更好地理解了这个约定,我们给它起了个名字:导入兼容性规则:
“如果旧包和新包具有相同的导入路径,则新包必须向后兼容旧包。”
Go Modules
我们采用了 dep 实验中运行良好的部分,以及我们从运行不良中了解到的部分,并尝试了一种名为 vgo 的新设计。 在 vgo 中,包遵循导入兼容性规则,因此我们可以提供包的唯一性,但仍然不会像我们刚刚看到的那样破坏构建。 这也让我们简化了设计的其他部分。
除了恢复导入兼容性规则之外,vgo 设计的另一个重要部分是为一组包的概念命名,并允许该分组与源代码存储库边界分开。 一组 Go 包的名称是一个模块,所以我们现在将系统称为 Go 模块。
Go 模块现在与 go 命令集成,这根本不需要复制供应商目录。
用 Go 模块替换
Go 模块结束了 GOPATH 作为全局命名空间。 将现有的 Go 使用和工具转换为模块的几乎所有艰苦工作都是由这种变化引起的,从远离 GOPATH。
GOPATH 的基本思想是 GOPATH 目录树是正在使用的版本的全局事实来源,并且当您在目录之间移动时,使用的版本不会改变。 但是全局 GOPATH 模式与每个项目可重复构建的生产需求直接冲突,这本身在许多重要方面简化了 Go 开发和部署体验。
每个项目的可重现构建意味着当您在项目 A 的检出中工作时,您将获得与项目 A 的其他开发人员在该提交时获得的相同的一组依赖项版本,如 go.mod 文件所定义。 当您切换到项目 B 的检出工作时,现在您将获得该项目选择的依赖项版本,与项目 B 的其他开发人员获得的版本相同。 但那些可能与项目 A 不同。当您从项目 A 移动到项目 B 时,更改依赖项版本集对于保持您的开发与 A 和 B 上的其他开发人员的开发同步是必要的。不可能有 不再是单一的全局 GOPATH。
采用模块的大部分复杂性直接来自于一个全局 GOPATH 的丢失。 包的源代码在哪里? 以前,答案仅取决于您的 GOPATH 环境变量,大多数人很少更改该变量。 现在,答案取决于您正在从事的项目,这可能经常发生变化。 为了这个新约定,一切都需要更新。
大多数开发工具使用 go/build 包来查找和加载 Go 源代码。 我们一直保持该包的工作,但 API 没有预料到模块,我们为避免 API 更改而添加的变通方法比我们想要的要慢。 我们已经发布了一个替代版本,golang.org/x/tools/go/packages。 开发人员工具现在应该使用它。 它同时支持 GOPATH 和 Go 模块,使用起来更快更方便。 在一两个版本中,我们可能会将其移动到标准库中,但目前 golang.org/x/tools/go/packages 已经稳定并可供使用。
Go 模块代理
模块简化 Go 开发的方法之一是将一组包的概念与存储它们的底层源代码控制存储库分开。
当我们与 Go 用户讨论依赖项时,几乎每个在他们公司使用 Go 的人都询问如何通过他们自己的服务器路由 go get 包获取,以更好地控制可以使用哪些代码。 甚至开源开发人员也担心依赖项会意外消失或更改,从而破坏他们的构建。 在模块之前,用户曾尝试复杂的解决方案来解决这些问题,包括拦截 go 命令运行的版本控制命令。
Go 模块设计可以很容易地引入可以请求特定模块版本的模块代理的想法。
公司现在可以轻松地运行他们自己的模块代理,自定义规则允许什么以及缓存副本的存储位置。 开源雅典项目就构建了这样一个代理,Aaron Schlesinger 在 Gophercon 2019 上发表了演讲。(当视频可用时,我们将在此处添加链接。)
对于个人开发人员和开源团队, 谷歌的 Go 团队推出了一个代理,作为所有开源 Go 包的公共镜像,Go 1.13 将在模块模式下默认使用该代理。 Katie Hockman 在 Gophercon 2019 上发表了关于这个系统的演讲。
Go Modules Status
Go 1.11 引入了模块作为实验性的选择加入预览。 我们不断尝试和简化。 Go 1.12 带来了改进,Go 1.13 将带来更多改进。
模块现在处于我们相信它们将为大多数用户服务的地步,但我们还没有准备好关闭 GOPATH。 我们将继续试验、简化和修改。
我们充分认识到 Go 用户社区围绕 GOPATH 建立了近十年的经验、工具和工作流程,将所有这些转换为 Go 模块还需要一段时间。
但同样,我们认为模块现在对大多数用户来说都可以很好地工作,我鼓励您在 Go 1.13 发布时查看一下。
作为一个数据点,Kubernetes 项目有很多依赖项,他们已经迁移到使用 Go 模块来管理它们。 你可能也可以。 如果你不能,请通过提交错误报告告诉我们什么对你不起作用或什么太复杂,我们将进行试验和简化。
工具
错误处理、泛型和依赖管理至少需要几年时间,我们现在将专注于它们。 错误处理接近完成,模块将在此之后,然后可能是泛型。
但是假设我们期待几年后,当我们完成实验和简化并发布错误处理、模块和泛型时。 然后呢? 未来很难预测,但我认为一旦这三款产品出货,那可能标志着一个新的重大变化的平静期的开始。 那时我们的重点可能会转向使用改进的工具简化 Go 开发。
一些工具工作已经在进行中,所以这篇文章通过查看来结束。
虽然我们帮助更新了所有 Go 社区的现有工具以了解 Go 模块,但我们注意到拥有大量开发帮助工具,每个工具都只做一个小工作,并不能很好地为用户服务。 单个工具很难组合,调用速度太慢,使用起来又太不同。
我们开始努力将最常用的开发助手统一到一个工具中,现在称为 gopls(发音为“go, please”)。 Gopls 使用语言服务器协议 LSP,并与任何支持 LSP 的集成开发环境或文本编辑器一起工作,这在这一点上基本上是一切。
Gopls 标志着 Go 项目的重点扩展,从提供类似编译器的独立命令行工具(如 go vet 或 gorename)到还提供完整的 IDE 服务。 Rebecca Stambler 在 Gophercon 2019 上发表了关于 gopls 和 IDE 的更多详细信息。(当视频可用时,我们将在此处添加一个链接。)
在 gopls 之后,我们还有一些想法以可扩展的方式恢复 go fix 和 make go 兽医更有帮助。
尾声
所以这是通往 Go 2 的道路。我们将进行试验和简化。 并进行实验和简化。 和船。 并进行实验和简化。 然后再做一遍。 它可能看起来甚至感觉就像路径在绕圈子。 但是每次我们进行实验和简化时,我们都会更多地了解 Go 2 应该是什么样子,并向它更进一步。 即使像 try 或我们的前四个泛型设计或 dep 这样被放弃的实验也不会浪费时间。 它们帮助我们在发货之前了解需要简化的内容,并且在某些情况下,它们帮助我们更好地理解我们认为理所当然的东西。
到了某个时候,我们会意识到我们已经进行了足够多的实验、足够的简化和足够的发布,我们将拥有 Go 2。
感谢 Go 社区中的所有人帮助我们进行实验、简化、发布并在这条道路上找到我们的道路 .

若有收获,就点个赞吧
0 人点赞
