1.常见的数据结构(了解):
常用的数据结构有:数组,栈,队列,链表,树,散列,堆,图等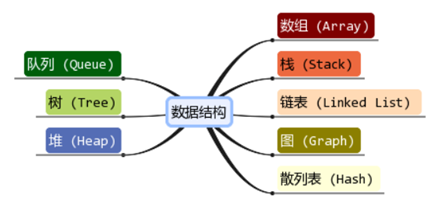
数组:是最常用的数据结构,长度固定,只能存储一种类型的数据 ,添加删除的操作慢。
栈:先进后出,是一种只能在一端进行插入和删除操作的特殊线性表。
队列:先进先出,是一种只能在一端进行插入,在另一端进行删除操作的特殊线性表。
链表:是非连续、非顺序的存储结构,其物理结构不能只表示数据元素的逻辑顺序,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。查询慢,增删快
树:是我们计算机中非常重要的一种数据结构,例如:二叉树、平衡树、红黑树、B树、B+树。
散列表(哈希表):根据键和值 (key和value) 直接进行访问的数据结构。
堆:看作是一棵完全二叉树的数组对象。
图:由一组顶点和一组能够将两个顶点相连的边组成的。
2.集合和数组的区别?(了解):
区别:数组长度固定 集合长度可变。
数组存储的是同一种数据类型的元素,可以存储基本数据类型,也可以存储引用数据类型;添加修改慢,查询快,没有方法可以用。
集合存储的都是对象,对象的数据类型可以不一致。对象较多的时候,使用集合来存储对象。方法较多,用起来方便。
3.ArrayList和linkedList的区别?
ArrayList底层是数组查询快。(常用)通过数组得索引进行搜索和读取。
LinkList是双链表结构,查询慢,添加删除快 。
List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式,它继承Collection。
List有两个重要的实现类:ArrayList和LinkedList
ArrayList: 可以看作是能够自动增长容量的数组
ArrayList:toArray方法返回一个数组
ArrayList:asList方法返回一个列表
ArrayList底层的实现是Array, 数组扩容实现
4. 说说ArrayList的特点:
ArrayList 是最常用的 List 实现类,底层是通过数组实现的,增删慢,查询快。
5. 说说LinkList的特点:
LinkedList 是用链表结构存储数据的,增删快,查询慢。另外,还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用 。
面试题6
1. List 和 Map、Set 的区别(必会):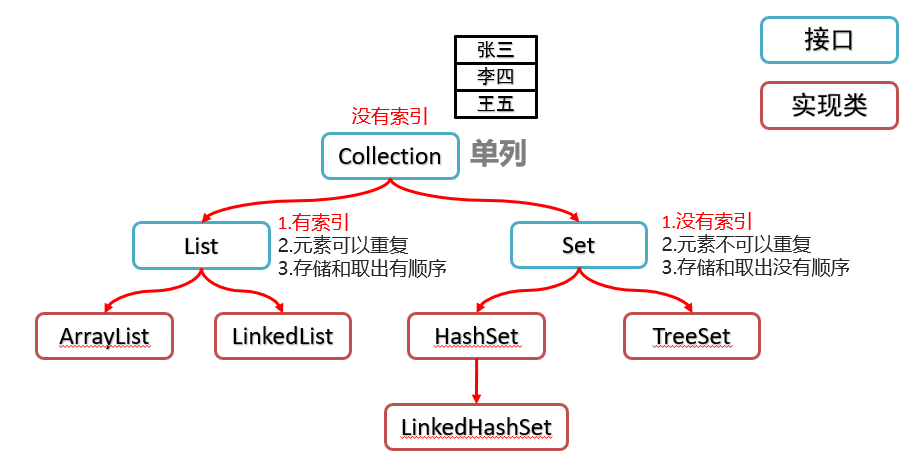
List系列集合特点:
①有索引
②元素可以重复
③存储和取出有顺序
Set集合特点:
1.没有索引
2.元素不可以重复
3.存储和取出没有顺序
Set集合是根据hashcode来进行数据存储的
Map集合特点:
1.键不能重复,值可以重复
2.一个键对应一个值
3.存储数据是无序
2. List 和 Map、Set 的实现类(必会):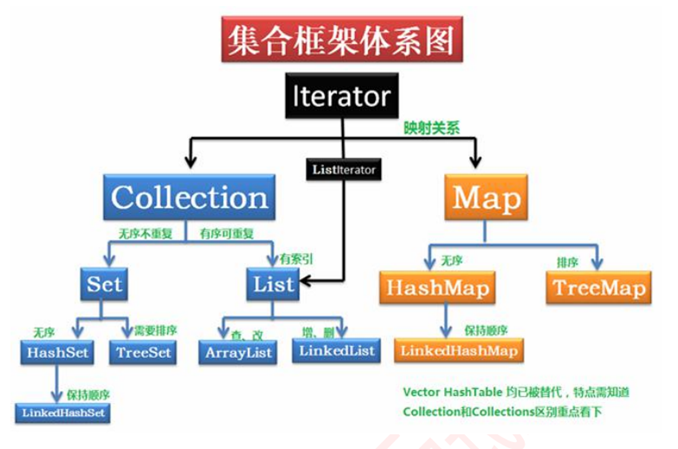
(1)Connection接口:
List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
LinkedList
优点: 底层数据结构是双链表,查询慢,增删快。
缺点: 线程不安全,效率高
Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
Map接口有四个实现类:
HashMap
基于 hash 表的 Map 接口实现,非线程安全,高效,支持 null 值和 null 键, 线程不安全。
HashTable
线程安全,低效,不支持 null 值和 null 键;
LinkedHashMap
线程不安全,是 HashMap 的一个子类,保存了记录的插入顺序;
TreeMap
能够把它保存的记录根据键排序,默认是键值的升序排序,线程不安全。
3. HashSet的底层原理
底层数据结构是哈希表。(无序,唯一)
哈希表边存放的是哈希值。 HashSet 存储元素的顺序并不是按照存入时的顺序(和 List 显然不同)而是按照哈希值来存的所以取数据也是按照哈希值取得。元素的哈希值是通过元素的hashcode 方法来获取的, HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法 如果 equls 结果为 true , HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素。
哈希值相同 equals 为 false 的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。 如图 1 表示 hashCode 值不相同的情况;
hashCode 值相同,但 equals 不相同的情况。 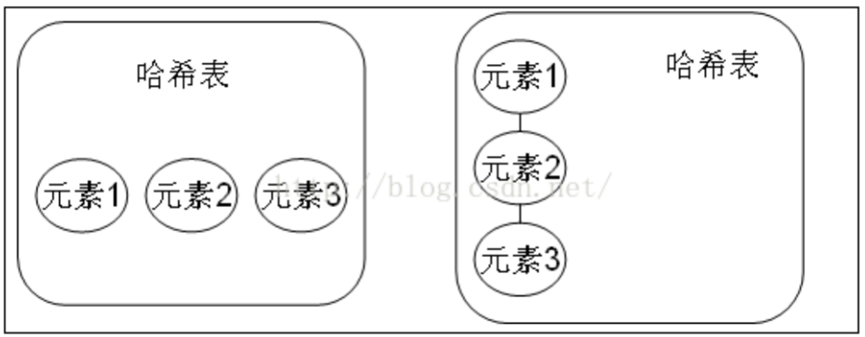
HashSet 通过 hashCode 值来确定元素在内存中的位置。 一个 hashCode 位置上可以存放多个元素。
4. 泛型常用特点:
使用泛型的好处:限定集合只能存储一种类型,避免了类型转换异常
5.Collection包结构,与Collections的区别?
Collection是集合类的上级接口,子接口有 Set、List、LinkedList、ArrayList、Vector、Stack、Set。 Collections是集合类的一个帮助类,它包含有各种有关集合操作的静态多态方法,用于实现对各种集合的搜索、排序、线程安全化等操作。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
面试题7:
1.手写冒泡排序?(必会):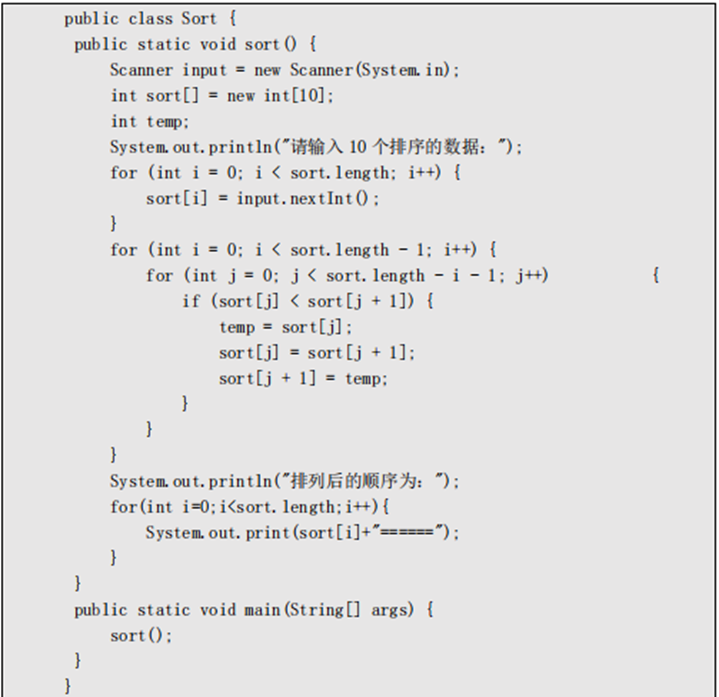
2. Hashmap的底层原理(高薪常问)【看答案】
HashMap在JDK1.8之前的实现方式 数组+链表,但在JDK1.8后对HashMap进行了底层优化,改为了由 数组+链表或者数值+红黑树实现,主要的目的是提高查找效率。
在链表长度大于8的时候,将链表就会变成红黑树,提高查询的效率。
3. Error与Exception区别?
相同点:都继承了Throwable类
不同点:
- Error:严重问题,通过代码无法处理。比如:电源断了。
- Exception:称为异常,它表示程序本身可以处理的问题。
4. Throw与thorws区别?
位置不同 :
1. throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的是异常对象。
功能不同:
2. throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式;
throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
3. throws 表示出现异常的一种可能性,并不一定会发生这些异常;
throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
4. 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异
常,真正的处理异常由函数的上层调用处理。
面试题8
1. 说一下 synchronized 底层实现原理?(高薪常问):
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性。
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
· 普通同步方法,锁是当前实例对象
· 静态同步方法,锁是当前类的class对象
· 同步方法块,锁是括号里面的对象
2. synchronized 和 Lock 有什么区别? (高薪常问):
首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可);
Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
3. 什么是线程?线程和进程的区别?(了解)
线程:是进程的一个实体,是 cpu 调度和分派的基本单位,是比进程更小的
可以独立运行的基本单位。
进程:具有一定独立功能的程序关于某个数据集合上的一次运行活动,是操作
系统进行资源分配和调度的一个独立单位。
特点:线程的划分尺度小于进程,这使多线程程序拥有高并发性,进程在运行
时各自内存单元相互独立,线程之间 内存共享,这使多线程编程可以拥有更好
的性能和用户体验。
4. 如何启动一个新线程、调用start和run方法的区别?(必会)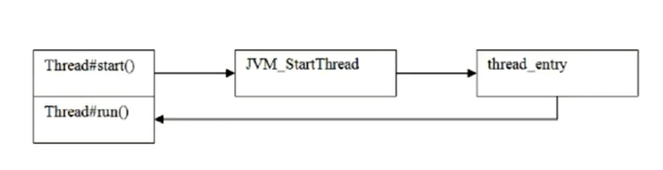
线程对象调用run方法不开启线程。仅是对象调用方法。
线程对象调用start开启线程,并让jvm调用run方法在开启的线程中执行
调用start方法可以启动线程,并且使得线程进入就绪状态,而run方法只是thread的一个普通方法,还是在主线程中执行。
5.线程相关的基本方法?(必会)
线程相关的基本方法有 wait,notify,notifyAll,sleep,join,yield 等
- wait等待时会释放锁 wait 方法一般用在同步方法或同步代码块中。
- notify: 唤醒正在等待的单个线程
- notifyAll : 唤醒正在等待的所有线程
- sleep:睡眠时不会释放锁
- join :等待其他线程终止
- yield:线程让步
面试题9
1. Hashmap和hashtable ConcurrentHashMap区别(高薪常问):
区别对比一(HashMap 和 HashTable 区别):
1、HashMap 是非线程安全的,HashTable 是线程安全的。
2、HashMap 的键和值都允许有 null 值存在,而 HashTable 则不行。
3、因为线程安全的问题,HashMap 效率比 HashTable 的要高。
4、Hashtable 是同步的,而 HashMap 不是。因此,HashMap 更适合于单线
程环境,而 Hashtable 适合于多线程环境。一般现在不建议用 HashTable, ①
是 HashTable 是遗留类,内部实现很多没优化和冗余。②即使在多线程环境下,
现在也有同步的 ConcurrentHashMap 替代,没有必要因为是多线程而用
HashTable。
区别对比二(HashTable 和 ConcurrentHashMap 区别):
HashTable 使用的是 Synchronized 关键字修饰,ConcurrentHashMap 是JDK1.7使用了锁分段技术来保证线程安全的。JDK1.8ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
2. synchronized 和 volatile 的区别是什么?(高薪常问):
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
3. 创建线程有几种方式(必会)
1.继承Thread类并重写 run 方法创建线程,实现简单但不可以继承其他类
2.实现Runnable接口并重写 run 方法。避免了单继承局限性,编程更加灵活,实现解耦。
3..实现 Callable接口并重写 call 方法,创建线程。可以获取线程执行结果的返回值,并且可以抛出异常。
4.使用线程池创建(使用java.util.concurrent.Executor接口)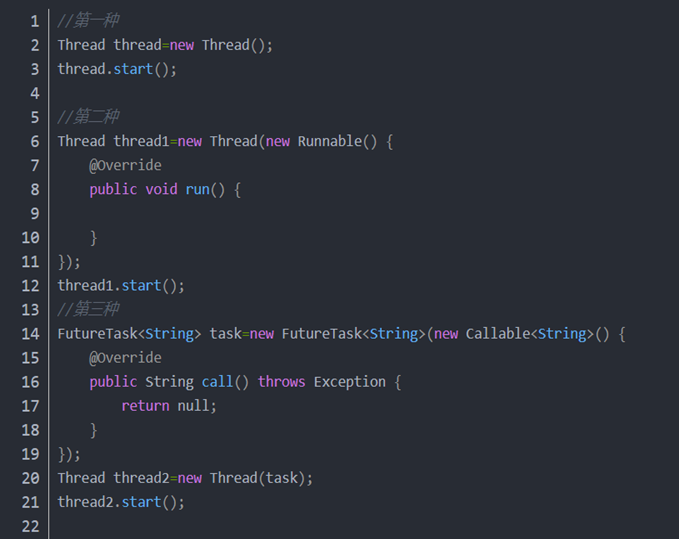
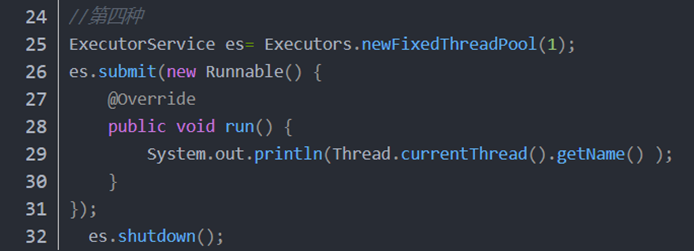
4. Runnable和Callable的区别?
主要区别
Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,支持泛型。
Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息。
5. wait()和sleep()的区别?(必会)
1. 来自不同的类
wait():来自Object类;
sleep():来自Thread类;
2.关于锁的释放:
wait():在等待的过程中会释放锁;
sleep():在等待的过程中不会释放锁
3.使用的范围:
wait():必须在同步代码块中使用;
sleep():可以在任何地方使用;
4.是否需要捕获异常
wait():不需要捕获异常;
sleep():需要捕获异常;
面试题10:
1. 为什么需要线程池(了解):
在实际使用中,线程是很占用系统资源的,如果对线程管理不完善的话很容易导致系统问题。因此,在大多数并发框架中都会使用线程池来管理线程,使用线程池管理线程主要有如下好处:
1、使用线程池可以重复利用已有的线程继续执行任务,避免线程在创建销毁时造成的消耗
2、由于没有线程创建和销毁时的消耗,可以提高系统响应速度
3、通过线程可以对线程进行合理的管理,根据系统的承受能力调整可运行线程数量的大小等
2. Java 中 IO 流?
Java 中 IO 流分为几种?
1. 按照流的流向分,可以分为输入流和输出流;
2. 按照操作单元划分,可以划分为字节流和字符流;
3. 按照流的角色划分为节点流和处理流。
Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
1. InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
2. OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
3. 字节流与字符流的区别?
以字节为单位输入输出数据,字节流按照8位传输
以字符为单位输入输出数据,字符流按照16位传输
4. 常用io类有哪些?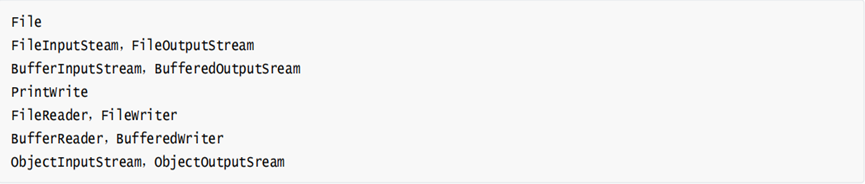
5. 二分查找算法
又叫折半查找,要求待查找的序列有序。每次取中间位置的值与待查关键字比较,如果中间位置的值比待查关键字大,则在前半部分循环这个查找的过程,如果中间位置的值比待查关键字小,则在后半部分循环这个查找的过程。直到查找到了为止,否则序列中没有待查的关键字。 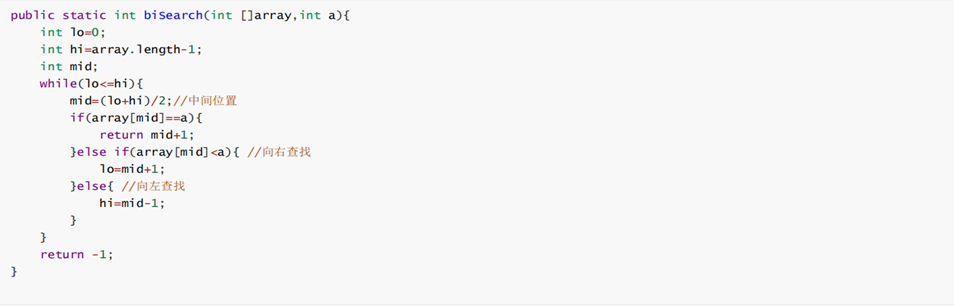
面试题11
1. jdk1.8的新特性(高薪常问):
1 Lambda 表达式
Lambda 允许把函数作为一个方法的参数。
2 方法引用
方法引用允许直接引用已有 Java 类或对象的方法或构造方法。
上例中我们将 System.out::println 方法作为静态方法来引用。
3 函数式接口
有且仅有一个抽象方法的接口叫做函数式接口,函数式接口可以被隐式转换为 Lambda 表达式。通常函数式接口
上会添加@FunctionalInterface 注解。
4 接口允许定义默认方法和静态方法
从 JDK8 开始,允许接口中存在一个或多个默认非抽象方法和静态方法。
5 Stream API
新添加的 Stream API(java.util.stream)把真正的函数式编程风格引入到 Java 中。这种风格将要处理的元素集
合看作一种流,流在管道中传输,并且可以在管道的节点上进行处理,比如筛选,排序,聚合等。

6 日期/时间类改进
之前的 JDK 自带的日期处理类非常不方便,我们处理的时候经常是使用的第三方工具包,比如 commons-lang
包等。不过 JDK8 出现之后这个改观了很多,比如日期时间的创建、比较、调整、格式化、时间间隔等。
这些类都在 java.time 包下,LocalDate/LocalTime/LocalDateTime。
7 Optional 类
Optional 类是一个可以为 null 的容器对象。如果值存在则 isPresent()方法会返回 true,调用 get()方法会返回该对象。 

8 Java8 Base64 实现
Java 8 内置了 Base64 编码的编码器和解码器。
2. 什么是java序列化,如何实现java序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
3. Java IO与 NIO的区别
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO 主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
面试题12
1.BIO、NIO、AIO 有什么区别?(高薪常问):
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
2. 网络 7 层架构:
7 层模型主要包括:
1. 物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率 等。它的主要作用是传输比特流(就是由 1、0 转化为电流强弱来进行传输,到达目的地后在转化为1、0,也就是我们常说的模数转换与数模转换)。这一层的数据叫做比特。
2. 数据链路层:主要将从物理层接收的数据进行 MAC 地址(网卡的地址)的封装与解封装。常把这一层的数据叫做帧。在这一层工作的设备是交换机,数据通过交换机来传输。
3. 网络层:主要将从下层接收到的数据进行 IP 地址(例 192.168.0.1)的封装与解封装。在这一层工作的设备是路由器,常把这一层的数据叫做数据包。
4. 传输层:定义了一些传输数据的协议和端口号(WWW 端口 80 等),如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与 TCP 特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如 QQ 聊天数据就是通过这种方式传输的)。 主要是将从下层接收的数据进行分段进行传输,到达目的地址后在进行重组。常常把这一层数据叫做段。
5. 会话层:通过传输层(端口号:传输端口与接收端口)建立数据传输的通路。主要在你的系统之间发起会话或或者接受会话请求(设备之间需要互相认识可以是 IP 也可以是 MAC 或者是主机名)
6. 表示层:主要是进行对接收的数据进行解释、加密与解密、压缩与解压缩等(也就是把计算机能够识别的东西转换成人能够能识别的东西(如图片、声音等))
7. 应用层 主要是一些终端的应用,比如说FTP(各种文件下载),WEB(IE浏览),QQ之类的(你就把它理解成我们在电脑屏幕上可以看到的东西.就 是终端应用)。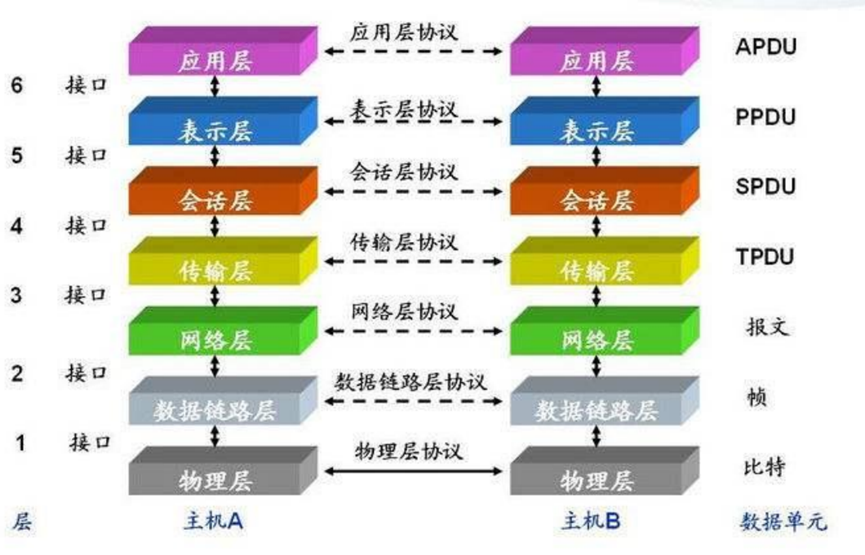
3.TCP 三次握手/四次挥手:
TCP 在传输之前会进行三次沟通,一般称为“三次握手”,传完数据断开的时候要进行四次沟通,一般称为“四次挥手”。
第一次握手:主机A发送位码为 syn=1,随机产生 seq number=1234567 的数据包到服务器,主机B由 SYN=1 知道,A 要求建立联机;
第二次握手:主机 B 收到请求后要确认联机信息,向 A 发 送 ack number=( 主 机 A 的seq+1),syn=1,ack=1,随机产生 seq=7654321 的包
1、第三次握手:主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码ack 是否为 1,若正确,主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认seq 值与 ack=1 则连接建立成功。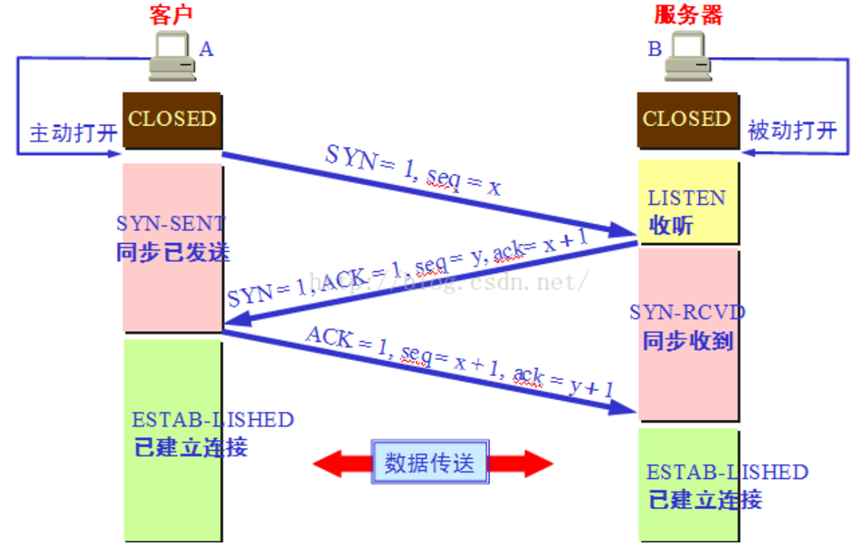
2、四次挥手
TCP 建立连接要进行三次握手,而断开连接要进行四次。这是由于 TCP 的半关闭造成的。因为 TCP 连接是全双工的(即数据可在两个方向上同时传递)所以进行关闭时每个方向上都要单独进行关闭。这个单方向的关闭就叫半关闭。当一方完成它的数据发送任务,就发送一个 FIN 来向另一方通告将要终止这个方向的连接。
1) 关闭客户端到服务器的连接:首先客户端 A 发送一个 FIN,用来关闭客户到服务器的数据传送,然后等待服务器的确认。其中终止标志位 FIN=1,序列号 seq=u
2) 服务器收到这个 FIN,它发回一个 ACK,确认号 ack 为收到的序号加 1。
3) 关闭服务器到客户端的连接:也是发送一个 FIN 给客户端。
4) 客户段收到 FIN 后,并发回一个 ACK 报文确认,并将确认序号 seq 设置为收到序号加 1。
首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。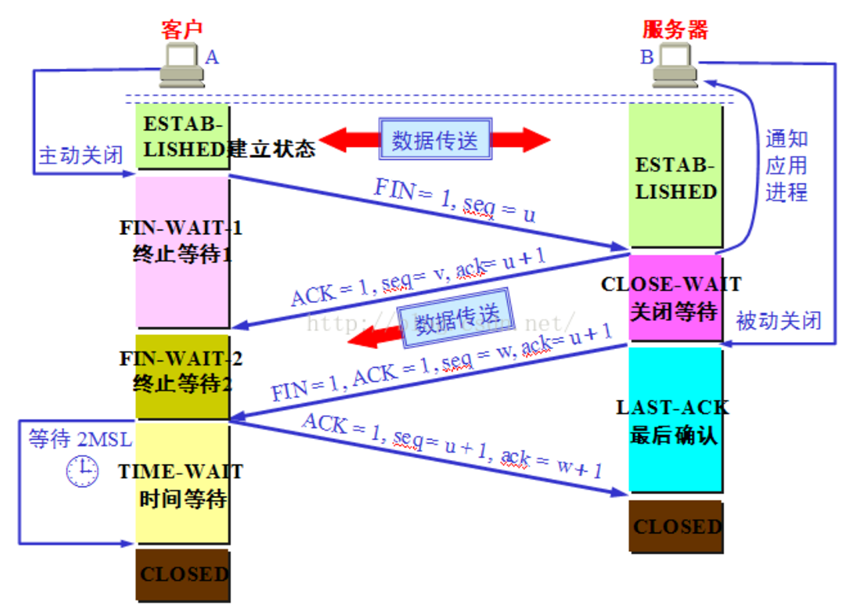
主机 A 发送 FIN 后,进入终止等待状态, 服务器 B 收到主机 A 连接释放报文段后,就立即给主机 A 发送确认,然后服务器 B 就进入 close-wait 状态,此时 TCP 服务器进程就通知高层应用进程,因而从 A 到 B 的连接就释放了。此时是“半关闭”状态。即 A 不可以发送给B,但是 B 可以发送给 A。此时,若 B 没有数据报要发送给 A 了,其应用进程就通知 TCP 释放连接,然后发送给 A 连接释放报文段,并等待确认。A 发送确认后,进入 time-wait,注意,此时 TCP 连接还没有释放掉,然后经过时间等待计时器设置的 2MSL 后,A 才进入到close 状态。
4. TCP 与 UDP 区别?
- UDP协议通信是不需要连接的,相当于我们生活中的寄快递,直接寄出即可。 (发送端和接收端)
- TCP协议通信是需要连接的,建立连接后以流的形式传输。相当于打电话。 (客户端和服务端)
面试题13
1.反射(了解)
在程序的运行过程中, 通过Class对象得到类中的信息(构造方法, 成员方法, 成员变量), 并操作他们,这种动态获取信息以及动态调用对象方法的功能称为Java语言的反射机制。非常规的手段操作对象。
2. 反射机制的优缺点?
优点:
1)运行时动态获取类的实例,提高灵活性;
2)与动态编译结合
缺点:
1)使用反射性能较低,需要解析字节码,将内存中的对象进行解析。
解决方案:
1、通过setAccessible(true)关闭JDK的安全检查来提升反射速度;
2、多次创建一个类的实例时,有缓存会快很多
3、Reflect ASM工具类,通过字节码生成的方式加快反射速度
相对不安全,破坏了封装性(因为通过反射可以获得私有方法和属性)
3. 获取 Class 对象有几种方法?
对象名.getClass() 类名.class
类名.class
Class.forName()
当我们获得了想要操作的类的 Class 对象后,可以通过 Class 类中的方法获取并查看该类中的方法和属性。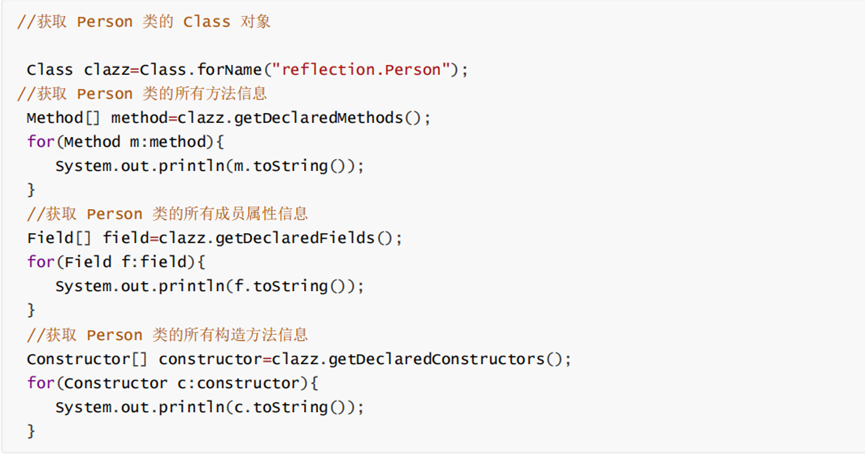
4. 4种标准元注解是哪四种?
元注解的作用是负责注解其他注解。 Java5.0 定义了 4 个标准的 meta-annotation 类型,它们被用来提供对其它 annotation 类型作说明。
@Target 修饰的对象范围
@Target说明了Annotation所修饰的对象范围:
1.types(类,接口、枚举、Annotation 类型)
2.field, 成员变量
3.method, 成员方法
4.parameter, 方法参数
5.constructor, 构造方法
6.local_variable, 局部变量
在 Annotation 类型的声明中使用了 target可更加明晰其修饰的目标
@Retention 定义 被保留的时间长短(生命周期)
Retention 定义了该 Annotation 被保留的时间长短:表示需要在什么级别保存注解信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效),取值(RetentionPoicy)由:
1. SOURCE:在源文件中有效(即源文件保留)
2. CLASS:在 class 文件中有效(即 class 保留)
3. RUNTIME:在运行时有效(即运行时保留) 
@Documented 描述-javadoc
@ Documented 用于描述其它类型的 annotation 应该被作为被标注的程序成员的公共 API,因此可以被例如 javadoc 此类的工具文档化。
@Inherited 阐述了某个被标注的类型是被继承的
@Inherited 元注解是一个标记注解,@Inherited 阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited 修饰的 annotation 类型被用于一个 class,则这个 annotation 将被用于该 class 的子类。
5. 注解是什么?
Annotation表示注解。注解是给编译器或JVM看的,编译器或JVM可以根据注解来完成对应的功能。
面试题14
1. Java的数据结构有那些?
1.线性表(ArrayList)
2.链表(LinkedList)
3.栈(Stack)
4.队列(Queue)
5.图(Map)
6.树(Tree)
2. Java语言有哪些特点?
1. 简单易学、有丰富的类库
2. 面向对象(Java最重要的特性,让程序耦合度更低,内聚性更高)
3. 与平台无关性(JVM是Java跨平台使用的根本)
4. 可靠安全
5. 支持多线程
3. 面向对象和面向过程的区别?
1. 面向过程:
一种较早的编程思想,是站着过程的角度思考问题,强调的是功能行为,功能的执行过程,即先后顺序,而每一个功能我们都使用函数(类似于方法)把这些步骤一步一步实现。使用的时候依次调用函数。
2. 面向对象:
一种基于面向过程的新编程思想,是站在对象的角度思考问题,我们把多个功能合理放到不同对象里,强调的是具备某些功能的对象。 具备某种功能的实体,称为对象。面向对象最小的程序单元是:类。面向对象更加符合常规的思维方式,稳定性好,可重用性强,易于开发大型软件产品,有良好的可维护性。
在软件工程上,面向对象可以使工程更加模块化,实现更低的耦合和更高的内聚。

若有收获,就点个赞吧
0 人点赞
