- springcloud常用组件:
服务注册发现:Eureka\Nacos\Consul
服务远程调用:OpenFeign\Dubbo
服务链路监控:Ziplin.Sleuth
统一配置管理:SpringCloudConfig\Nacos
统一网关路由:SpringCloudGateway\Zuul
流控、降级、保护:Hystrix\Sentinel
- springboot的常用注解:
- @SpringBootApplication:启动类
- @EnableScheduling:开启定时任务
- @MapperScan:包扫描
- @RestController :类上的访问路径
- @RequestMapping:方法上的访问路径
- @GetMappping,@PostMapping, @PutMapping, @DeleteMapping 结合@RequestMapping使用, 是 Rest风格的, 指定更明确的子路径.
- @PathVariable:路径变量注解,用{}来定义url部分的变量名. @Service这个注解用来标记业务层的组件,我们会将业务逻辑处理的类都会加上这个注解交给spring容器。 事务的切面也会配置在这一层。当让 这个注解不是一定要用。有个泛指组件的注解,当我们不能确定具体作用的时候 可以用泛指组件的注解托付给spring容器 @Component和spring的注解功能一样, 注入到IOC容器中.
- @ControllerAdvice 和 @ExceptionHandler 配合完成统一异常拦截处理. 备注: 面试的时候记住6.7个即可~
- springmvc和springboot的关系
Spring包含了SpringMVC,而SpringBoot又包含了Spring或者说是在Spring的基础上做得一个扩展。
概述:spring mvc < spring < springboot的关系,但是Spring Boot既是对Spring的扩展,使开发、测试和部署更加方便,也增加了SpringBoot本身的一些功能,如:Sarter依赖、main函数启动入口、自动化配置等均使得SpringBoot优于Spring。
- 谈谈对spring的理解
Spring是一个开源容器框架,可以接管web层、业务层、dao层、持久层的组件,并可以配置各种bean,且能维护bean与bean之间的关系。其核心就是控制反转(IOC)和面向切面编程(AOP),简单的说就是一个分层的轻量级开源框架。
- Spring 容器的主要核心是:
1.Spring的两大核心是什么?
IOC: 控制反转
AOP:面向切面编程
DI:依赖注入
谈一谈你对IOC的理解?
IOC的意思是控制反转
- 把创建对象的控制权转移到Spring容器中,容器根据配置文件去创建实例和管理各个实例之间的依赖关系,对象与对象之间松散耦合,也利于功能的复用。
- 我们需要对象的时候, 直接从Spring容器中获取即可.
- Spring的配置文件中配置了类的字节码位置及信息, 容器生成的时候加载配置文件识别字节码信息, 通过反射创建类的对象.
Spring的IOC有三种注入方式 :构造器注入, setter方法注入, 注解注入。
谈一谈你对DI的理解?
DI的意思是依赖注入,在运行时依赖Ioc容器来动态注入对象所需要的外部资源。
谈一谈你对AOP的理解?(必会)
AOP面向切面编程,作为面向对象的一种补充,对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect).
AOP使用的动态代理,就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调目标对象的方法。
- Spring Bean的生命周期:
1)调用构造函数(底层反射)@Component @Service @Controller;
2)属性注入(@Value @Autowired @ConfigurationProperties)
3)调用XXXAware接口(可选的)BeanNameAware BeanFactoryAware ApplicationContextAware(项目启动时全局初始化)
4)调用InitializingBean接口,调用afterPropertiesSet方法(某个技术启动时初始化)
5)调用Bean的init方法
6) 调用Bean的destroy方法(只有主动关闭ApplicationContext close方法)
spring的ioc、di、aop分别是什么,ioc和di有什么关系
什么是事务:
是为了解决数据安全操作提出的,事务控制实际上就是数据的安全访问。是数据库操作的最小单位,是作为单个逻辑工作单位执行的一系列操作;这些操作是作为一个整体一起向系统提交的,
要么都执行,要么都不执行;事务是一组不可再分割的操作集合(工作逻辑单位);
- 事务的四大特性和隔离级别:
四大特性:原子性、一致性、持久性、隔离性
隔离级别:
① isolationdefault:这是个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别。
② isolation_Read uncommitted:读未提交,允许另外一个事务可以看到这个事务未提交的数据。
③ isolation_Read committed:读已提交,保证一个事务修改的数据提交后才能被另一事务读取,而且能看到该事务对已有记录的更新。解决脏读问题
④ isolation Repeatable read:可重复读,保证一个事务修改的数据提交后才能被另一事务读取,但是不能看到该事务对已有记录的更新。行锁repeatable read
⑤ isolation_serializable:一个事务在执行的过程中完全看不到其他事务对数据库所做的更新。
- 悲观锁和乐观锁的区别和应用场景:
(1)悲观锁:顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 block 直到它拿到锁。 传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
(2)乐观锁: 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会 上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等 机制。 乐 观 锁 适 用 于 多 读 的 应 用 类 型 , 这 样 可 以 提 高 吞 吐 量 , 像 数 据 库 如 果 提 供 类 似 于 write_condition 机制的其实都是提供的乐观锁
- redis的数据类型,持久化方式:
- redis的数据类型: String 、 Hash、 List 、Set 、 Sorted Set
- 持久化方式: Redis 提供了两种持久化的方式,分别是 RDB(Redis DataBase)和 AOF(Append Only File)。 RDB,简而言之,就是在不同的时间点,将 redis 存储的数据生成快照并存储到磁盘 等介质上。 AOF,则是换了一个角度来实现持久化,那就是将 redis 执行过的所有写指令记录下 来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现 数据恢复了。 RDB 和 AOF 两种方式也可以同时使用,在这种情况下,如果 redis 重启的话,则会 优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高
- redis缓存穿透、雪崩、击穿
- 缓存穿透:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大.
解决方法:
- 接口层增加校验,如用户鉴权校验;
- 从缓存取不到的数据,在数据库中也没有取到,这时可以在缓存中存储一个空值,这样可以防止攻击用户反复用同一个id暴力攻击。
- 缓存击穿:key对应的数据存在,但在redis中过期,此时若有⼤量并发请求过来,这些请求发现缓存过期⼀般都会从后端DB加载数据并回设到缓存,这个时候⼤并发的请求可能会瞬间把后端innoDB压垮。
解决方法:
- 设置热点数据永远不过期。
- 数据进行热加载在服务器启动的时候对热门数据进行读取,并存放到缓存中。
- 缓存雪崩:缓存雪崩是指缓存数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方法:
- 缓存数据的过期时间设置不同,防止同一时间大量数据过期现象发生。
设置热点数据永远不过期。
java的基本数据类型:
byte、 short、 int 、long、float、 double、 boolean、 char
arraylist和linkedlist
作用 :ArrayList和LinkedList都是实现了List接口的容器类,用于存储一系列的对象引用。他们都可以对元素的 增删改查进行操作。 对于ArrayList,它在集合的末尾删除或添加元素所用的时间是一致的,但是在列表中间的部分添加或删 除时所用时间就会大大增加。但是它在根据索引查找元素的时候速度很快。 对于LinkedList则相反,它在插入、删除集合中任何位置的元素所花费的时间都是一样的,但是它查询 一个元素的时候却比较慢。
区别: 1.ArrayList是实现了基于动态数组的数据结构,LinkedList是基于链表结构。
2.对于随机访问的get和set方法,ArrayList要优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。
缺点 :1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList而言,主 要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList 而言,这个开销是 统一的,分配一个内部Entry对象。 2.在ArrayList集合中添加或者删除一个元素时,当前索引后面的所有的元素都会被移动。而LinkedList集 合中添加或者删除一个元素的开销是固定的。 3.LinkedList集合不支持 高效的随机随机访问(RandomAccess),因为可能产生二次项的行为。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体 现在它的每一个元素都需要消耗相当的空间hashtable和hashmap区别:
- HashMap 是非线程安全的,HashTable 是线程安全的。
- HashMap 的键和值都允许有 null 值存在,而 HashTable 则不行。
- 因为线程安全的问题,HashMap 效率比 HashTable 的要高。
- Hashtable 是同步的,而 HashMap 不是。因此,HashMap 更适合于单线 程环境,而 Hashtable 适合于多线程环境。一般现在不建议用 HashTable, ① 是 HashTable 是遗留类,内部实现很多没优化和冗余。②即使在多线程环境下, 现在也有同步的 ConcurrentHashMap 替代,没有必要因为是多线程而用 HashTable
- jvm调优
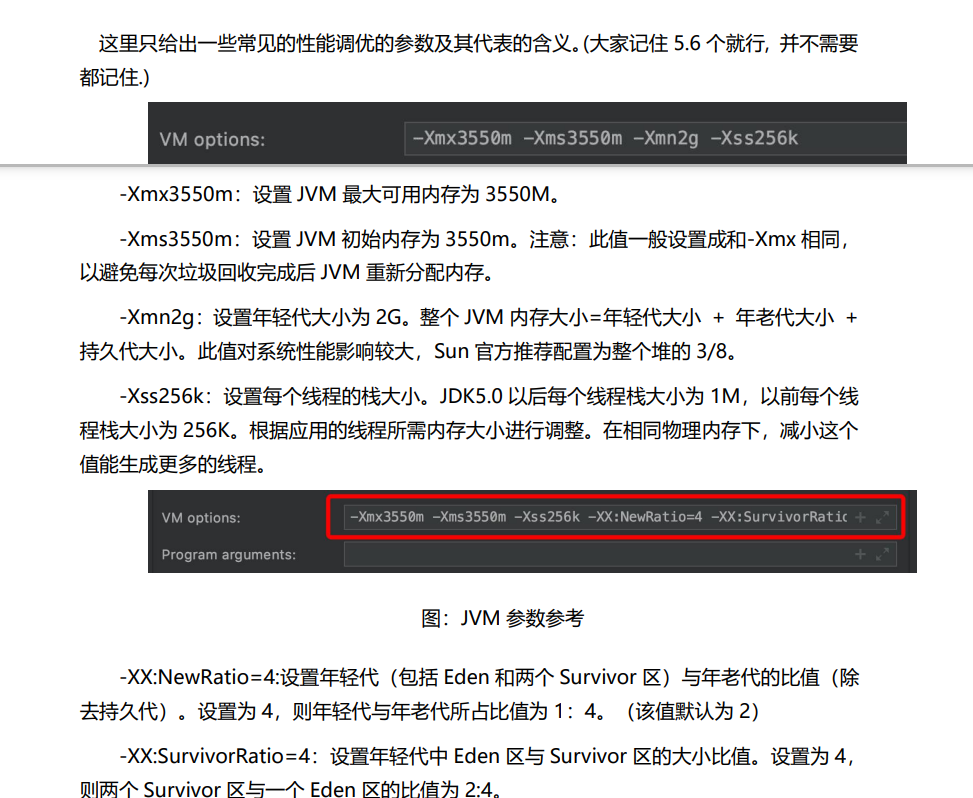
- jvm内存溢出
1、堆溢出
绝大部分的内存溢出属于堆溢出,原因是大量对象占用了堆空间,而这些对象持有强引用,无法回收。-Xmx参数指定堆空间大小小于对象大小时候,溢出自然而然的就发生了。
报错信息:java.lang.OutOfMemoryError: Java heap space
为了减少堆溢出错误,一方面可以使用-Xmx指定一个更大的堆空间。另外可以通过MAT或者VisualVM等工具,找到大量占用堆空间的对象,并在代码上合理优化。
2、直接内存溢出
在Java的NIO中,支持直接内存使用,也就是通过Java代码获取一块堆外内存,该内存是直接向操作系统申请的。直接内存申请速一般比堆内存慢,但是访问速度快于堆内存,因此对于那些可以复用经常访问的空间,使用直接内存可以提高系统的性能,但是由于该内存没有JVM托管,使用不当容易触发直接内存溢出,导致宕机。
-XX:+PrintGCDetails 输出GC详情
报错信息:java.lang.OutOfMemoryError: Direct buffer memory
直接内存不一定触发GC,触发直接内存使用量达到-XX:MaxDirectMemorySize的设置值。所以保证内存不溢出就需要合理的进行FullGC。或者设订一个系统可达的-XX:MaxDirectMemorySize值。通过显示的gc是可以回收直接内存的。在不使用-XX:MaxDirectMemorySize设置最大最直接内存空间的时候,默认情况最大可用直接内存等于-Xmx即堆空间的大小。
避免直接内存溢出:
1、合理的GC
2、设置系统容许的-XX:MaxDirectMemorySize
3、设置小的-Xmx
- 创建线程的方式
- 继承 Thread 类并重写 run 方法创建线程,实现简单但不可以继承其他类
- 实现 Runnable 接口并重写 run 方法。避免了单继承局限性,编程更加灵活,实现解耦。
- 实现 Callable 接口并重写 call 方法,创建线程。可以获取线程执行结果的返回 值,并且可以抛出异常。
- 使用线程池创建(使用 java.util.concurrent.Executor 接口)
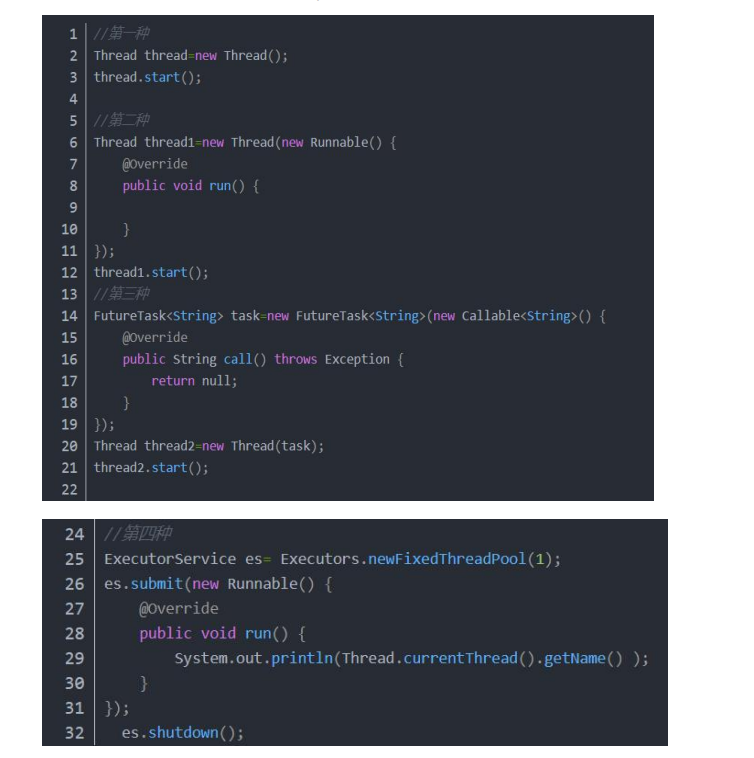
- 线程池有几种
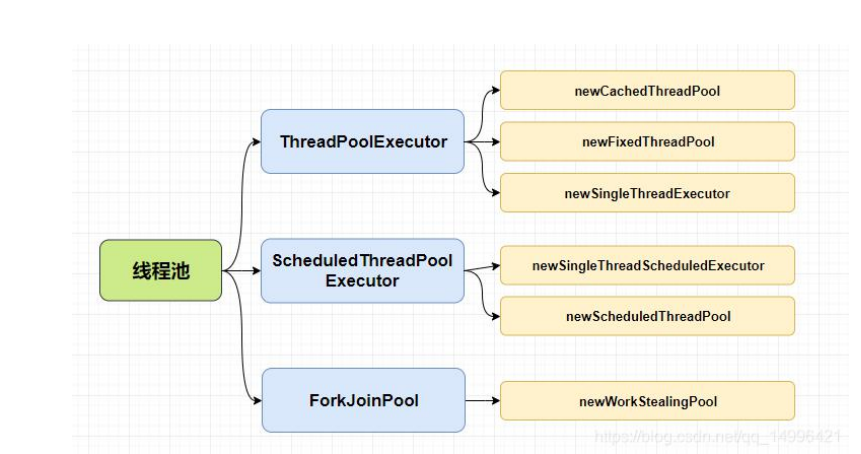
1. newCachedThreadPool:创建一个可进行缓存重复利用的线程池
2. newFixedThreadPool:创建一个可重用固定线程数的线程池,以共享的无 界队列方式来运行这些线程,线程池中的线程处于一定的量,可以很好的控制线程的并发量
3. newSingleThreadExecutor : 创 建 一 个 使 用 单 个 worker 线 程 的 Executor ,以无界队列方式来运行该线程。线程池中最多执行一个线程,之后提交的线程 将会排在队列中以此执行
4. newSingleThreadScheduledExecutor:创建一个单线程执行程序,它可 安排在给定延迟后运行命令或者定期执行
5. newScheduledThreadPool:创建一个线程池,它可安排在给定延迟后运行 命令或者定期的执行
6. newWorkStealingPool:创建一个带并行级别的线程池,并行级别决定了 同一时刻最多有多少个线程在执行,如不传并行级别参数,将默认为当前系统的 CPU 个
- mysql的引擎有几种
innoDB 、MyISAM 、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等,其中InnoDB和BDB提供事务安全表,其他存储引擎是非事务安全表。
常用的innoDB,MYISAM MEMORY MERGE NDB
1.MyISAM 存储引擎 主要特点: MySQL5.5 版本之前的默认存储引擎 支持表级锁(表级锁是 MySQL 中锁定粒度最大的一种锁,表示对当前操作的整张表加锁); 不支持事务,外键。 适用场景:对事务的完整性没有要求,或以 select、insert 为主的应用基本都可以选用 MYISAM。在 Web、数据仓库中应用广泛。 特点: 1、不支持事务、外键 2、每个 myisam 在磁盘上存储为 3 个文件,文件名和表名相同,扩展名分别是 .frm ———-存储表定义 .MYD ————MYData,存储数据 .MYI ————MYIndex,存储索引
2.InnoDB 存储引擎 主要特点: MySQL5.5 版本之后的默认存储引擎; 支持事务; 支持行级锁(行级锁是 Mysql 中锁定粒度最细的一种锁,表示只针对当前操作的行进行加 锁); 支持聚集索引方式存储数据
项目中有没有设计表,都有哪些字段
sql优化
- 根据业务场景建立复合索引只查询业务需要的字段,如果这些字段被索引覆盖,将极 大的提高查询效率.
- 多表连接的字段上需要建立索引,这样可以极大提高表连接的效率.
- where 条件字段上需要建立索引, 但 Where 条件上不要使用运算函数,以免索引失效.
- 排序字段上, 因为排序效率低, 添加索引能提高查询效率.
- 优化 insert 语句: 批量列插入数据要比单个列插入数据效率高.
- 优化 order by 语句: 在使用 order by 语句时, 不要使用 select *, select 后面要查有 43 索引的列, 如果一条 sql 语句中对多个列进行排序, 在业务允许情况下, 尽量同时用升 序或同时用降序.
- 优化 group by 语句: 在我们对某一个字段进行分组的时候, Mysql 默认就进行了排序, 但是排序并不是我们业务所需的, 额外的排序会降低效率. 所以在用的时候可以禁止 排序, 使用 order by null 禁用. select age, count(*) from emp group by age order by null
- 尽量避免子查询, 可以将子查询优化为 join 多表连接查询
- eureka和nacos的区别
Nacos与eureka的共同点:
都支持服务注册和服务拉取
都支持服务提供者心跳方式做健康检测
Nacos与Eureka的区别:
1.Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
2.临时实例心跳不正常会被剔除,非临时实例则不会被剔除
3.Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
4.Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
- 项目中用到什么设计模式,单例有几种??
工厂模式、单例模式、代理模式、模板模式、观察者模式、建造者模式
饿汉式:在创建单例对象的时候就已经创建好了,线程安全
懒汉式:在需要该对象的时候进行创建,非线程安全
双检锁:线程安全,延迟初始化
- SpringMVC的执行流程
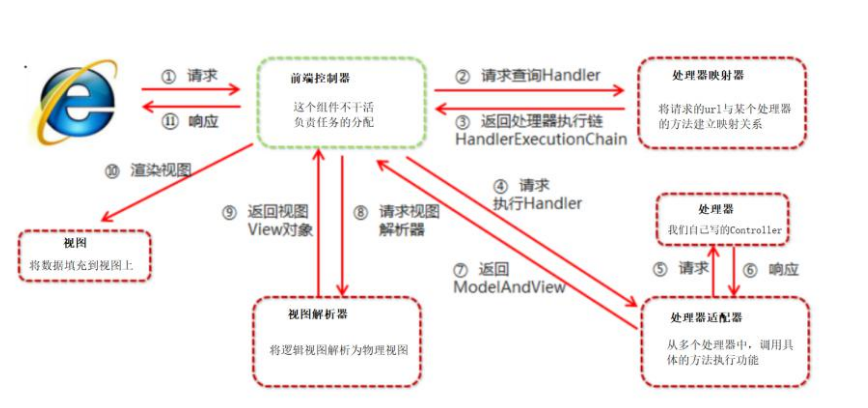
用户发送请求给前端的控制器,前端控制器接收到请求后调用处理器的映射器,处理器的映射器找到具体的处理器,生成处理器的对象及处理器的拦截器并返回给前端的控制器,前端控制器在调用处理器的适配器,处理器的适配器自己去定义一个处理器类,处理器类得到参数进行处理并返回结果给处理器的适配器,处理器的适配器将得到的结果返回给前端的控制器,前端的控制器将ModelAndView传给视图解析器,视图解析器(ViewReslover)将得到的参数从逻辑视图转换为物理视图并返回给前端控制器(DispatcherServlet),前端控制器调用物理视图进行渲染并返回。
mybatis的$和#
{} 是占位符,预编译处理,${}是字符串替换。
Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号,调用 PreparedStatement 的 set 方法来赋值; Mybatis 在处理${}时,就是把${}替换成变量的值。 使用#{}可以有效的防止 SQL 注入,提高系统安全性为什么要用es,es的倒排索引是什么
- 为什么使用es:解决了海量数据存储问题、单点故障问题
- es的倒排索引是什么:首先将文档按语义进行分词,形成倒排索引库,主要由词条和文档id构成。当进行搜索的时候,将搜索的内容进行分词,根据词条所在文档的id。再根据文档id获得文档对象存入结果集。
- rabbitmq/rocketmq、kafka的了解
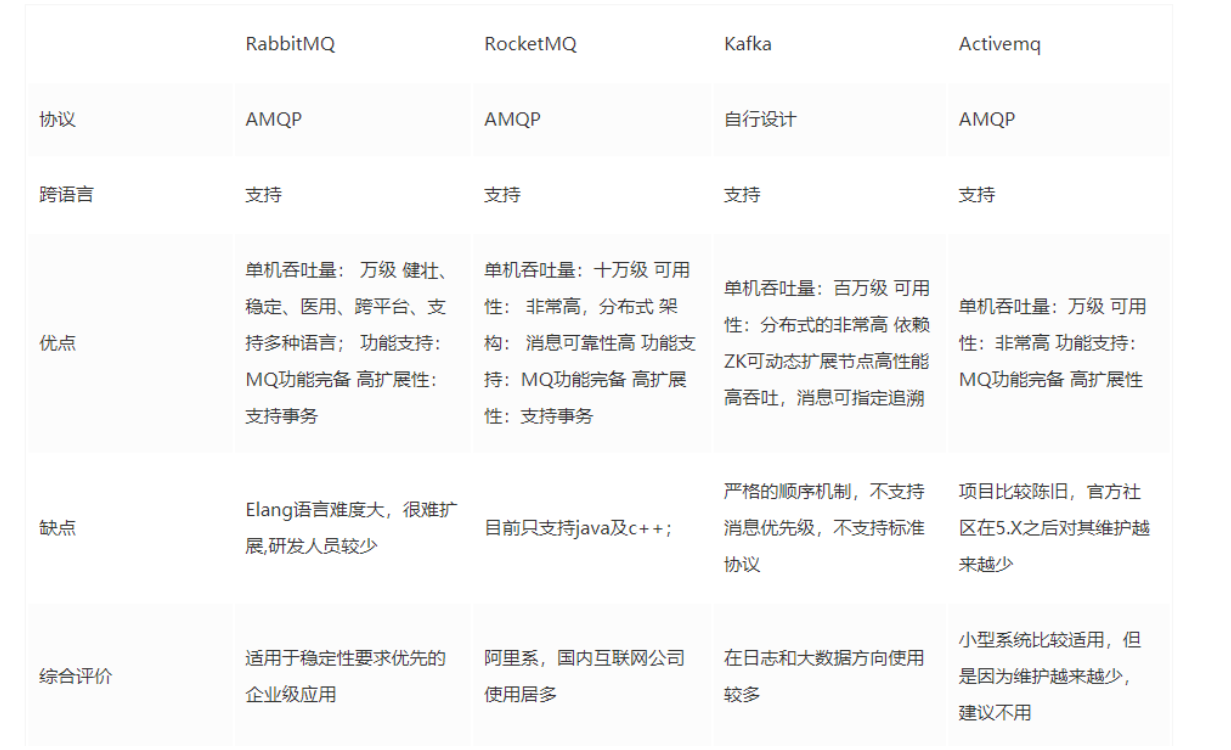
RabbitMQ:
优势:
1)支持语言非常广
2)稳定性很好,采用Erlang语言开发
3)吞吐量不算低,万级
4)拥有丰富的消息发送模式(简单,工作,路由,发布订阅,主题)
缺点:
1)采用Erlang,太小众,研究源码很难
RocketMQ:
优势:1)有多种语法支持(Java和C++)
2)稳定好
3)吞吐量达到十万级
缺点:
1)应该在国内阿里系公司使用
Kafka:
优势:
1)高吞吐量,百万级
2)稳定性好,采用zookeeper进行注册
3)可以应用在大数据数据处理领域(Kafka Stream)
缺点:
1)依赖zookeeper进行注册
spring中@Autowired和@Resource的区别
@Resource 只能放在属性上,表示先按照属性名匹配 IOC 容器中对象 id 给属性注入值若没有 成功,会继续根据当前属性的类型匹配 IOC 容器中同类型对象来注入值 若指定了 name 属性@Resource(name = “对象 id”),则只能按照对象 id 注入值。
@Autowird 放在属性上:表示先按照类型给属性注入值如果 IOC 容器中存在多个与属性同类 型的对象,则会按照属性名注入值 也可以配合@Qualifier(“IOC 容器中对象 id”)注解直接按照名称注入值。 放在方法上:表示自动执行当前方法,如果方法有参数,会自动从 IOC 容器中寻 找同类型的对象给参数传值 也可以在参数上添加@Qualifier(“IOC 容器中对象 id”)注解按照名称寻找对象给 参数传值。
@Qualifier 使用场景: @Qualifier(“IOC 容器中对象 id”)可以配合@Autowird 一起使用, 表示根据指定 的 idmysql索引数据结构,为什么用的是b+树不用红黑树
B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。所以从Mysql(Inoodb)的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系型数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。
那么Mysql如何衡量查询效率呢?– 磁盘IO次数。 B-树/B+树 的特点就是每层节点数目非常多,层数很少,目的就是为了减少磁盘IO次数,但是B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。这是优点之一。另一个优点是: B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。在数据库中基于范围的查询是非常de频繁的,而B树不支持这样的遍历操作
红黑树基本都是存储在内存中才会使用的数据结构。在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B树可以有多个子女,从几十到上千,可以降低树的高度。
30.SpringBoot自动装配:


若有收获,就点个赞吧
0 人点赞
