理解SVM
作者|OpenCV-Python Tutorials 编译|Vincent 来源|OpenCV-Python Tutorials
目标
在本章中,我们将重新识别手写数据集,但是使用SVM而不是kNN。
识别手写数字
在kNN中,我们直接使用像素强度作为特征向量。这次我们将使用定向梯度直方图(HOG)作为特征向量。
在这里,在找到HOG之前,我们使用其二阶矩对图像进行偏斜校正。因此,我们首先定义一个函数deskew(),该函数获取一个数字图像并将其校正。下面是deskew()函数:
def deskew(img):m = cv.moments(img)if abs(m['mu02']) < 1e-2:return img.copy()skew = m['mu11']/m['mu02']M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)return img
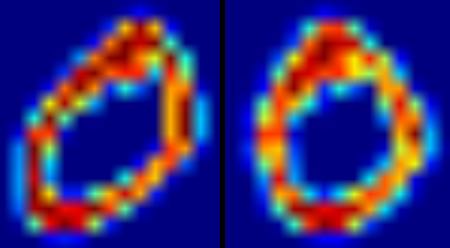
下图显示了应用于零图像的上偏移校正功能。左图像是原始图像,右图像是偏移校正后的图像。
接下来,我们必须找到每个单元格的HOG描述符。为此,我们找到了每个单元在X和Y方向上的Sobel导数。然后在每个像素处找到它们的大小和梯度方向。该梯度被量化为16个整数值。将此图像划分为四个子正方形。对于每个子正方形,计算权重大小方向的直方图(16个bin)。因此,每个子正方形为你提供了一个包含16个值的向量。(四个子正方形的)四个这样的向量共同为我们提供了一个包含64个值的特征向量。这是我们用于训练数据的特征向量。
def hog(img):gx = cv.Sobel(img, cv.CV_32F, 1, 0)gy = cv.Sobel(img, cv.CV_32F, 0, 1)mag, ang = cv.cartToPolar(gx, gy)bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]hist = np.hstack(hists) # hist is a 64 bit vectorreturn hist
最后,与前面的情况一样,我们首先将大数据集拆分为单个单元格。对于每个数字,保留250个单元用于训练数据,其余250个数据保留用于测试。完整的代码如下,你也可以从此处下载:
#!/usr/bin/env pythonimport cv2 as cvimport numpy as npSZ=20bin_n = 16 # Number of binsaffine_flags = cv.WARP_INVERSE_MAP|cv.INTER_LINEARdef deskew(img):m = cv.moments(img)if abs(m['mu02']) < 1e-2:return img.copy()skew = m['mu11']/m['mu02']M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)return imgdef hog(img):gx = cv.Sobel(img, cv.CV_32F, 1, 0)gy = cv.Sobel(img, cv.CV_32F, 0, 1)mag, ang = cv.cartToPolar(gx, gy)bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]hist = np.hstack(hists) # hist is a 64 bit vectorreturn histimg = cv.imread('digits.png',0)if img is None:raise Exception("we need the digits.png image from samples/data here !")cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]# First half is trainData, remaining is testDatatrain_cells = [ i[:50] for i in cells ]test_cells = [ i[50:] for i in cells]deskewed = [list(map(deskew,row)) for row in train_cells]hogdata = [list(map(hog,row)) for row in deskewed]trainData = np.float32(hogdata).reshape(-1,64)responses = np.repeat(np.arange(10),250)[:,np.newaxis]svm = cv.ml.SVM_create()svm.setKernel(cv.ml.SVM_LINEAR)svm.setType(cv.ml.SVM_C_SVC)svm.setC(2.67)svm.setGamma(5.383)svm.train(trainData, cv.ml.ROW_SAMPLE, responses)svm.save('svm_data.dat')deskewed = [list(map(deskew,row)) for row in test_cells]hogdata = [list(map(hog,row)) for row in deskewed]testData = np.float32(hogdata).reshape(-1,bin_n*4)result = svm.predict(testData)[1]mask = result==responsescorrect = np.count_nonzero(mask)print(correct*100.0/result.size)
这种特殊的方法给我们近94%的准确性。你可以为SVM的各种参数尝试不同的值,以检查是否可以实现更高的精度。或者,你可以阅读有关此领域的技术论文并尝试实施它们。
附加资源
- Histograms of Oriented Gradients Video:https://www.youtube.com/watch?v=0Zib1YEE4LU
练习
- OpenCV示例包含digits.py,它对上述方法进行了一些改进以得到改进的结果。它还包含参考资料。检查并了解它。

若有收获,就点个赞吧
0 人点赞
