1.创建倒排列表,表示关键字出现的网站序号,次数,位置信息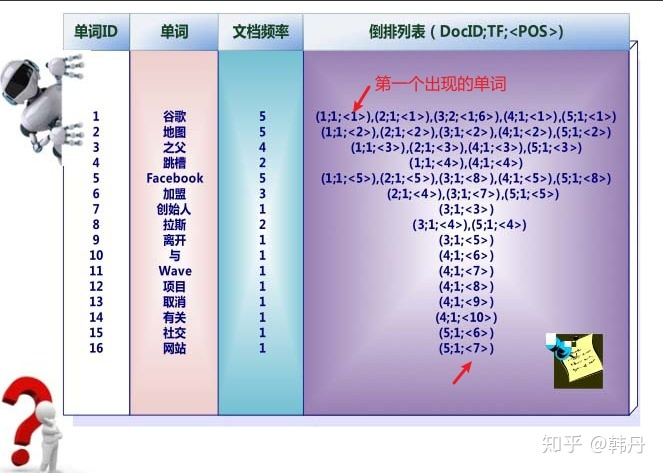
2.建立类似hashmap哈希表数据结构,防止冲突表,将关键字转化为编号储存在内存中(链表+数组,过长使用红黑树,b树),文档数量庞大,使用做差方式建立差值表
3.读取文档
两次遍历法
第一遍,扫描文档集合,找到文档数量N, 文档集合内所包含的不同单词数M,和每个单词出现的频率DF(如下图),以及一些别的必要信息,这些东西所占内存加起来,得到需要开辟的内存空间,

同时这个空间是以单词为单位划分,比如“谷歌”一词有5篇文档,
排序法
现在我们只用固定大小的内存,如何从上图中的倒排列表得知每个单词对应的文章集合所需要的内存空间有多少呢?
我们需要解析文档,构造(单词ID,文档ID,单词频率)三元组,然后进行排序,按单词ID,文档ID,单词频率先后排,最后如果规定的内存满了,就将这些三元组通通写入一个临时文件A中

为什么要这样呢?想想看,如果我们最后拿到了一个(单词A,文档A,单词频率),我们就可以很轻松的知道一个单词对应哪个文档,和对应的频率,
也就是一个三元组告诉我们单词A对应的文档A,另一个三元组告诉我们单词A对应文档B……,这些三元组加起来我们就知道了单词A对应的文档集合,就可以知道他需要多少内存空间来填补这些文档了
可能解析50个文档后规定的内存就满了,然后把这些三元组们写入磁盘临时文件A,就可以再读下一篇50个文档了,注意,词典是不断增加的,比如前50个文档只有上面7个单词,后50个文档可能出现了别的单词,此时要插入词典中,词典一直在内存
这样,只用固定大小的内存就可以50一批的解析完所有文档,写入了一个个的临时文件A,B,C,D,再将这些临时文件合并,就是把他们分别读入内存中的缓冲区,合成最终索引后再写入磁盘,这样通过最终索引就知道有哪些单词对应多少文档,还有频率,然后根据这些开辟内存空间读取进入内存返回给你即可
第一遍主要就是确定要开辟多大的内存空间来显示文档
第二遍扫描,就是边扫描,匹配对应的文档编号(三元组中的第一个数),载入内存
出处:
作者:韩丹
链接:https://zhuanlan.zhihu.com/p/139041529
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
