背景
问题
学校科研过程中会遇到需要使用服务器运行程序的情况,无论是类似普通台式机的工作站,还是放在机柜中的普通服务器、刀片服务器。
相信你在使用过程中也可能会遇到下面问题:
- 系统安装:逐个给每台服务器手动安装系统很累
- 系统重置:同上,要去机房
- 共享屏幕:一个人在屏幕前操作,那么另一个人就不能
- 依赖管理:一旦发生冲突便束手无策
- 资源浪费:一台服务器跑满甚至不够,但另一台仍然空闲
目标
本文是一篇在多台/单台 服务器/工作站 上搭建openstack私有云过程的指引,使用openstack提供的Iaas能力,达到资源池化、远程访问、操作简化、用户隔离的能力。
上面的问题并不都是通过openstack才能解决的,如共享屏幕的冲突,可以通过ssh远程访问解决。
本文以vmware虚拟化能力为基础,创建一台部署机、两台云宿主的实验环境。
TODO:最终效果
部署
物理硬件
- 部署或创建两个网络
- wan网络,连接进入后可以访问公网,一般需要拥有dhcp服务器或pppoe拨号能力
- 实验:可以创建nat网络,连接进入wan后dhcp即可拿到ip
- 实际:将实验室内网或校园网连入一台物理交换机/路由器lan口,通过dhcp或pppoe拨校园网ip
- lan网络,用于多台云宿主机间的通信
- 实验:可以创建自定义(custom)网络,手动取消提供dhcp服务
- 实际:使用一台物理交换机/路由器lan口,连入所有的云宿主机
- wan网络,连接进入后可以访问公网,一般需要拥有dhcp服务器或pppoe拨号能力
- 准备云宿主机服务器
- 底线:1c8G20G+20G + 1c4G20G+20G 配置的两台虚拟机或者服务器
- cpu核数(c)内存大小(G)硬盘1大小(G)硬盘2大小(G)
- 硬盘1硬盘2可以是两块独立硬盘,可以是同一块硬盘的两个分区
- 硬盘1作为系统盘
- 硬盘2留作云虚拟机存储
- 网络角色的(4G内存)云宿主机同时连接wan与lan网络
- 中控角色的(8G内存)云宿主机仅仅连接lan网络
- 若扩展至更多台云宿主机,也均只需连接lan网络
- 本文云宿主机均使用UEFI启动(vmware配置自行查询),只能使用BIOS的老机器会在操作系统安装部分有所不同,但不在本文的介绍范围内
- 底线:1c8G20G+20G + 1c4G20G+20G 配置的两台虚拟机或者服务器
- 准备部署机
- 部署机由于只有一台服务器,本实验选择手动安装一台centos7
- 物理环境可以选择笔记本安装centos7并配置取消休眠,或使用一台服务器作为部署机(有点浪费)
- 实验环境一台虚拟机即可
- 部署机同时连接wan与lan,临时作为网关的角色提供公网访问,同时部署dhcp、ansible等服务
- 准备镜像构建云服务器(可选)
- 香港最好
- 如果希望构建我没有构建,但你又需要的openstack服务的镜像,那么则必选
- 配置至少1c2G30G,操作系统用顺手的即可,推荐centos7
- 安装docker
操作系统
宿主机系统安装
部署机部分
云宿主机操作系统选择受到openstack的kolla-ansible项目的限制,不同的版本支持的操作系统版本号不同,如train版本支持centos7,但wallaby仅支持centos8-stream。
由于个人技术栈及稳定性考虑,选择centos作为主机操作系统;而具体版本的选择上,考虑读者会需要比较新的openstack功能,同时centos7至8stream版本变化频繁后续升级困难,因此选择部署最近的(211009)稳定版本wallaby,对应所需的centos8-stream继续由红帽维护相对稳定。
云宿主机的操作系统的安装方案大致有三条思路:
- 去机房挨个插U盘安装操作系统,手动配置安装过程(冻死)
- 使用ventoy制作系统启动盘,并使用kickstart安装脚本自动化安装过程(可以偶尔暖暖)
- 使用部署机运行PXE安装所需的服务,配置服务器以PXE启动,自动安装操作系统
前两条路不在此赘述,本文在这里介绍一种极简构建pxe服务的方法(相比较于cobbler),以下过程在部署机执行:
网络配置
- 禁用firewalld
systemctl disable firewalldsystemctl stop firewalld - 网络转发功能开启
echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf,后sysctl -p生效 - 利用iptables开启SNAT:
iptables -t nat -A POSTROUTING -s 192.168.123.0/24 -o ens37 -j MASQUERADE- ens37是位于wan的口网卡名
ip a add dev ens33 192.168.123.1/24,ens33是位于lan的网卡名dnsmasq
安装docker:
curl -L get.docker.com | bash -s -- --mirror Aliyunsystemctl start dockersystemctl enable docker
- 安装git、vim:
yum install -y git vim python3 python3-pip - 克隆代码:
git clone https://github.com/ohmyadd/pxe - 项目中dnsmasq.conf的内容如下:
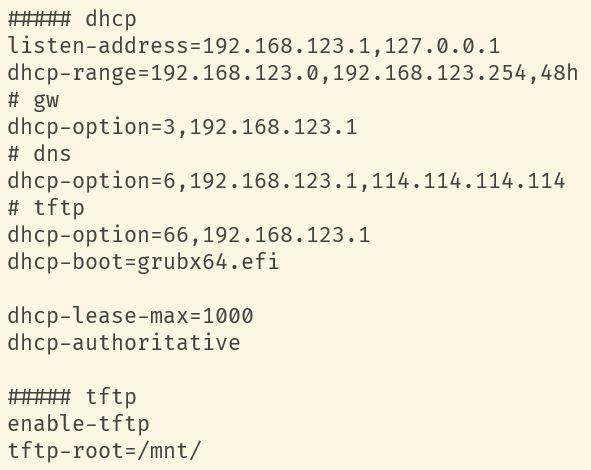
dhcp-range即是为lan网络配置的IP段,前面之所以禁掉vmware默认提供的dhcp服务,是为了避免与我们的部署机产生冲突。
listen-address是部署机在lan网络的网卡拥有的IP,部署机此时需要作为网关提供所有云宿主机的访问公网能力,因此配置监听123.1这个IP,别忘了通过ip addr add dev ethX 192.168.123.1/24手动为本机配置IP。
可以自行修改123.0/24网段为其他的内网网段。
dhcp-option中3号是向dhcp客户端下发默认网关配置,6号是下发DNS服务器的配置,66号配合dhcp-boot选项是下发PXE启动开始阶段的TFTP服务器配置。以PXE模式启动的云宿主机会在lan中进行dhcp请求,并读取使用上述配置,通过tftp(基于UDP的简单文件传输服务)从123.1(即部署机本机)下载grubx64.efi这个引导文件。
令人开心的是dnsmasq软件就可以提供tftp服务,通过配置enable-tftp以及tftp-root选项,设置了tftp的启动和根目录所对应在本机的绝对路径,由于dhcp客户端需要下载grubx64.efi引导,因此这个文件就需要存放在/mnt目录中。
修改dnsmasq.conf需要的前置知识为基础网络知识,如DHCP用途、二层交换、三层路由;以及dnsmasq软件配置相关知识。
grub2

pxe/boot文件夹中的grubx64.efi文件是我们提供给云宿主机的引导文件,这个引导文件会知晓当前的PXE启动状态,并读取TFTP服务器配置,在由详细到粗略爆破找到提供给他的grub.cfg配置文件(通过本机tcpdump抓UDP包即可看到),最终会查询并下载grub.cfg文件内容如上:
- 配置中只提供了一个grub选项,即centos8-stream的安装
- 安装所需的内核vmlinuz 以及临时文件系统initrd.img均从aliyun镜像站下载,这番操作借用了云宿主机能通过部署机访问公网的能力,无需在部署机下载这两个文件
- centos8.ks文件是centos系列的自动化安装配置文件,会被centos的anaconda(与著名科学计算项目重名)安装程序所读取,避免手动配置安装选项,如时区、分区方案等
修改grub.cfg文件需要操作系统启动基础知识,如BIOS与UEFI、grub2、内核与临时文件系统的作用
关于内核与临时文件系统的知识可以阅读我的《从UEFI到systemd》文章了解。
kickstart
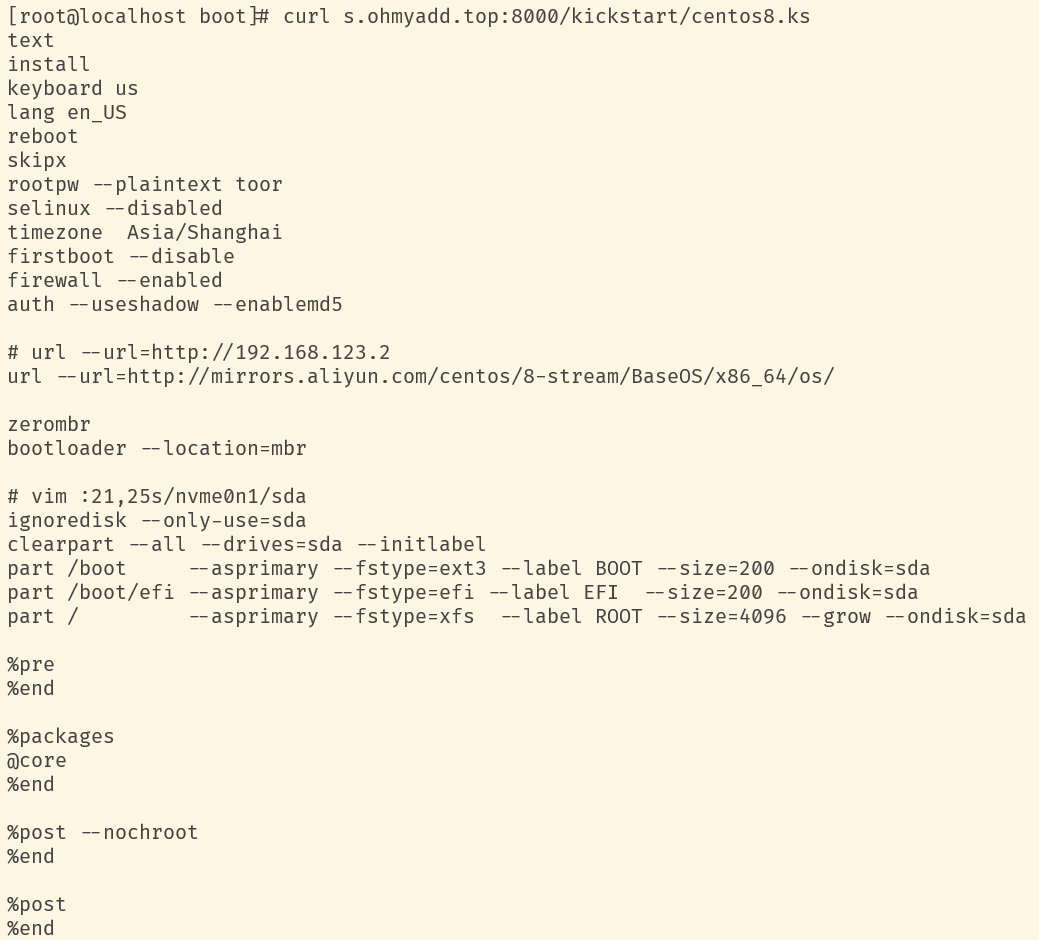
kickstart配置文件的内容如上,需要注意的有几点:
- 默认root密码为toor,明文写在这里,安装完成后注意修改
- url为centos安装使用的软件仓库repo,这里同样使用aliyun的镜像站
- zerombr、bootloader部分有些玄学,尽管我们使用的是UEFI,但这里还需要继续配置
- 分区部分记得修改自己的系统盘名,如将sda修改为nvme固态的名字,
- 不知道硬盘会命名为什么怎么办?U盘刷一个live模式的centos8-stream,然后让云宿主机从U盘启动,从而查看硬盘名
- 分区分为三部分:
- /boot分区用于存放系统内核、临时文件系统等文件
- /boot/efi分区存放引导文件,并label为EFI以便主板UEFI识别
- /最后根目录使用了剩余的所有空间
- 如果宿主机仅有一块硬盘,需要另外配置第四个分区,根目录即操作系统30G即可,剩余空间均可留给分区4
修改centos8.ks文件需要进行kickstart配置指令的检索、centos系统安装过程中的配置项的学习。
run
修改配置后可以运行dnsmasq容器,从而提供dhcp以及tftp服务:[root@localhost pxe]# docker run -d --name dhcp -v $(pwd)/dnsmasq.conf:/etc/dnsmasq.d/dnsmasq.conf -v $(pwd)/boot:/mnt --net=host registry.cn-beijing.aliyuncs.com/ohmyadd/dnsmasq:1.0.0
宿主机部分
通过
- 连接显示器Fx键进入UEFI启动选项菜单
- 或通过服务器BMC界面
使服务器UEFI以PXE选项启动,即可自动进入系统安装流程
宿主机系统配置
以root:toor账密手动登录至每台云宿主机,进行以下配置:
宿主机部分
编辑固定IP
vi /etc/sysconfig/network-scripts/ifcfg-ensXX
修改为
TYPE=EthernetDEVICE=ensXXONBOOT=yesBOOTPROTO=noneIPADDR=192.168.123.10NETMASK=255.255.255.0GATEWAY=192.168.123.1DEFROUTE=yesDOMAIN=cloud.localDNS1=114.114.114.114
BOOTPROTO为none表示配置静态IP;需要每台宿主机配置为相同段内的不同IP;DOMAIN表示为LAN网络内主机配置的域;为宿主机间域名互访做好铺垫;DNS使用114。
因为配置了固定IP,因此在完成配置后,就不再需要部署机提供dhcp服务获取IP了,后续安装完毕后部署机可以下线(网关功能后续会被网络角色宿主机替代)。
配置主机名
echo node10 > /etc/hostname
为每台宿主机配置独立的主机名,后续其他主机可以使用node10或node10.cloud.local访问本机。
配置hosts文件
vi /etc/hosts
添加以下条目
192.168.123.10 node10.cloud.local node10192.168.123.11 node11.cloud.local node11
为每台主机配置hosts文件,固定下来域名到IP的映射关系。
添加ssh公钥
ssh公私钥对自行创建mkdir /root/.sshcat key.pub >> /root/.ssh/authorized_keys
配置lvm卷
yum install lvm2pvcreate /dev/sdXpvcreate /dev/sdY…vgcreate cinder-volumes /dev/sdX /dev/sdY ...vi /etc/modules-load.d/lvm.conf
后续我们会配置openstack的cinder块存储服务使用本机名为cinder-volumes的lvm卷为虚拟机提供系统盘、数据盘等存储服务。target_core_modiscsi_target_modiscsi_tcpdm_thin_pool
lvm.conf中则配置了cinder所需要的iscsi块存储网络访问相关的内核模块的开机自动加载。
安装python
部署机部分
在本机hosts文件添加与其余宿主机相同的条目,即部署机也许能够通过node10或node10.cloud.local访问所有宿主机。
udev
镜像构建
本文将会以容器的形式,在宿主机上部署openstack各类组件,如nova计算组件、neutron网络组件。
有容器自然就需要进行构建对应的容器镜像,一切环境依赖只需安装在镜像中,他们之间、以及他们与本机不会产生依赖冲突,配置管理日志调试也方便许多。
openstack生态中有一个名为kolla的项目,目标就是快速build你所需的openstack组件镜像,与之配合的kolla-ansible项目,目标的则是在宿主机上具体跑起来这些镜像,kolla-ansible是后续部署调试章节的主角。
初次部署学习可以先跳过镜像构建,先使用我构建上传好的容器镜像,后续如果需要其他版本openstack或者openstack的其他组件,再回头进行镜像的构建。
镜像仓库
在build之前,我们需要有一个镜像仓库存储构建出来的镜像,docker官方的仓库上传和下载速度都很慢,现在docker公司没钱了,还多了很多的限制。因此建议使用国内容器厂商或国内云服务商的容器镜像服务,如阿里云:
开通容器镜像服务,使用个人免费版即可。
进入个人版,创建自己所需的命名空间名称。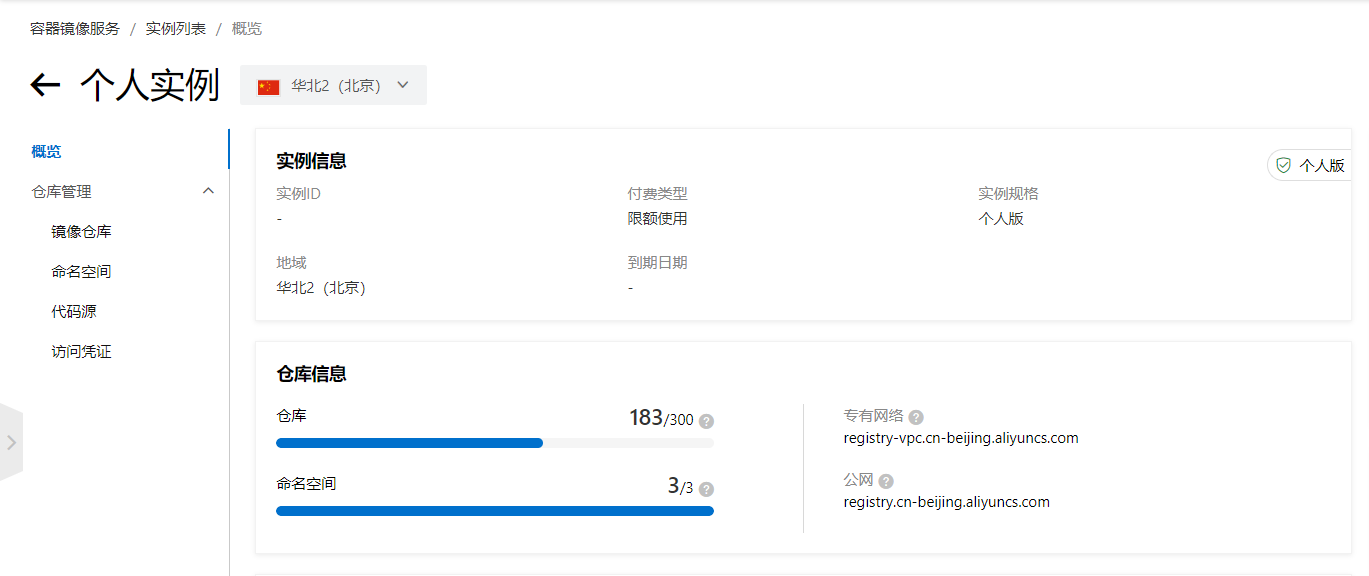
回到概览,上文选择合适的机房地域如北京,右下角得到对应的仓库url为registry.cn-beijing.aliyuncs.com。
最后在访问凭证部分设置仓库登录密码。
最终得到的效果是,我们能够在本地构建一个registry.cn-beijing.aliyuncs.com/kola/xxxx:latest镜像,并在认证后docker push至阿里云仓库,以供其他主机(云宿主机)下载。也就是镜像的构建与使用是分离的。
镜像构建
在构建机安装python3及python3-pip,然后通过pip3安装对应版本的kolla,版本号来源于openstack文档:https://releases.openstack.org/wallaby/index.html,在其中搜索能看到wallaby对应的kolla组件最新版为12.0.1,因此命令为pip3 install kolla==12.0.1。
如前文所述的操作系统要求https://docs.openstack.org/kolla/wallaby/support_matrix.html,openstack版本为wallaby,容器镜像我们选择centos8-stream为基础镜像。
首先我们在本机docker login登录阿里云容器服务,以便kolla命令后续push镜像:docker login registry.cn-beijing.aliyuncs.com -u adddd1000
构建命令为:kolla-build --push --base centos --base-tag stream8 --tag wallaby --openstack-release wallaby --namespace registry.cn-beijing.aliyuncs.com/kola chrony cron kolla-toolbox fluentd glance haproxy heat horizon keepalived keystone mariadb memcached neutron nova- placement openvswitch rabbitmq cinder iscsi
kolla-build会因—push参数随着镜像的逐个build完毕,将其push至对应的仓库,即registry.cn-beijing.aliyuncs.com/kola。如果push有问题,可以去掉push选项,后续手工push,如:for f in $(docker images -f=reference=registry.cn-beijing.aliyuncs.com/kola/*:train --format '{{.Repository}}:{{.Tag}}'); do docker push $f; done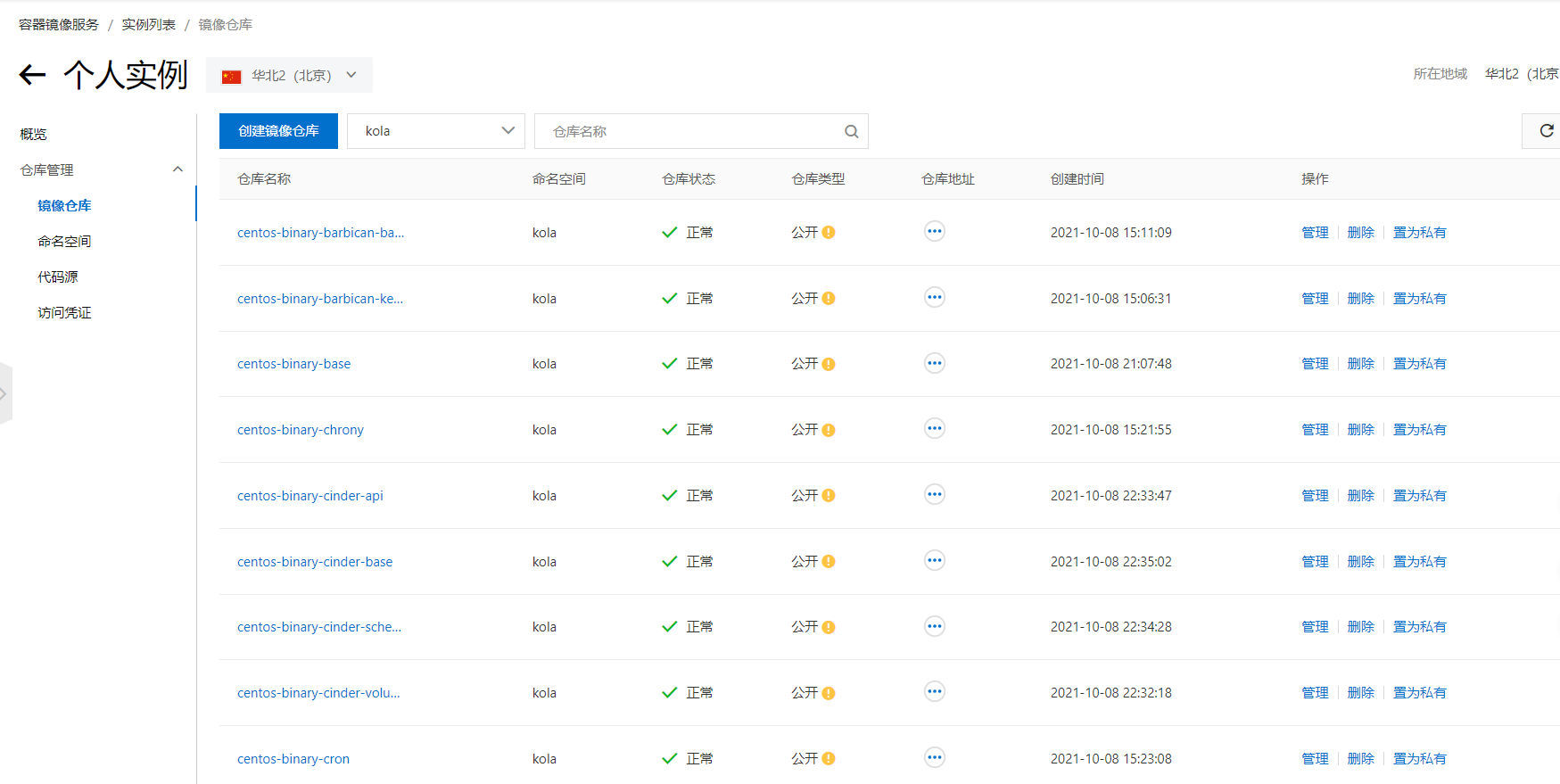
最终效果如图。
配置修改
本节开始进行kolla-ansible项目的安装和配置,kolla-ansible正如前文所述,是用于部署kolla项目构建的容器镜像的项目。
首先在部署机安装wallaby版本的kolla-ansible,版本号同样来自于官方文档:https://releases.openstack.org/wallaby/index.html
export LC_ALL=en_US.UTF-8pip3 install ansible==2.9.0pip3 install kolla-ansible==12.2.0
ansible.cfg
mkdir /etc/ansiblevi /etc/ansible/ansible.cfg
编辑为如下内容
[defaults]private_key_file = /root/ansible_config/kolla/keyhost_key_checking = Falseforks=20[ssh_connection]pipelining = truessh_args = -o ControlMaster=auto -o ControlPersist=60s -o PreferredAuthentications=publickey
private_key_file是前文生成的ssh私钥路径。
password.yml
接下来拷贝配置文件至etc目录 cp -r /usr/local/share/kolla-ansible/etc_examples/kolla/ /etc/kolla
随机生成openstack各组件的密码kolla-genpwd -p /etc/kolla/passwords.yml,注意其中的keystone_admin_password密码用于后续的web端登录。
globals.ymls
customize_etc_hosts: falsekolla_base_distro: "centos"openstack_release: "wallaby"ansible_python_interpreter: /usr/bin/python3# dockerdocker_yum_url: "http://mirrors.aliyun.com/docker-ce/linux/{{ ansible_distribution | lower }}"docker_registry: "registry.cn-beijing.aliyuncs.com"docker_namespace: "kola"# for openstack api socketkolla_internal_vip_address: "192.168.123.123"network_interface: "ens33"neutron_external_interface: ""neutron_bridge_name: "br-virt,br-jump,br-phys"# cinderenable_cinder: "yes"enable_cinder_backup: "no"enable_cinder_backend_lvm: "yes"glance_file_datadir_volume: "/data/glance/"
在/etc/kolla/globals.yml中添加如上内容:
- customize_etc_hosts禁止kolla-ansible修改宿主机hosts文件,我们已经配置好了
- 镜像和docker相关的配置看名字可以知道用途
- kolla_internal_vip_address是openstack各服务进行负载均衡的前端虚拟ip,写一个lan网段中的未被占用IP
- network_interface是宿主机lan网卡的名字,用于宿主机互访
- neutron_external_interface置为空
- neutron_bridge_name是我们后续会创建的三个external网络,按照顺序在openstack中分别叫做physnet123
- cinder配置如其名
- glance_file_datadir_volume指定了glance会将其管理的镜像文件存储路径
除了/etc/kolla/globals.yml,/usr/local/share/kolla-ansible/ansible/group_vars/all.yml中的配置项同样可以写在globals.yml中。
但是配置的前提是知道配置项的作用,一方面可以去官网文档查找,另一方面也可以去/usr/local/share/kolla-ansible/ansible/roles目录搜索对应的配置项内容,查看其作用效果,如grep -R glance_file_datadir_volume
hosts.cfg
拷贝配置文件至etc目录,cp /usr/local/share/kolla-ansible/ansible/inventory/multinode /etc/kolla/hosts.cfg
修改配置文件
# These initial groups are the only groups required to be modified. The# additional groups are for more control of the environment.[control]# These hostname must be resolvable from your deployment hostnode11# The above can also be specified as follows:#control[01:03] ansible_user=kolla# The network nodes are where your l3-agent and loadbalancers will run# This can be the same as a host in the control group[network]node10[compute]node1[0:1][monitoring]node11# When compute nodes and control nodes use different interfaces,# you need to comment out "api_interface" and other interfaces from the globals.yml# and specify like below:#compute01 neutron_external_interface=eth0 api_interface=em1 storage_interface=em1 tunnel_interface=em1[storage]node1[0:1]
hosts.cfg文件控制了openstack角色分别部署在哪些宿主机上,各角色对应了需要运行的各openstack组件,如网络角色对应neutron-api、openvswitch等组件。
control控制角色运行keystone、mysql等管理相关组件,最好与network角色跑在不同主机,因此设置部署在node11;
network网络角色运行neutron网络相关管理功能,需要与wan网卡产生交互,因此跑在node10;
compute计算角色、storage存储角色两者都需要担任;
monitoring监控角色两者任意均可;
部署调试
在部署机执行:
进行宿主机基础软件环境的安装:kolla-ansible -i /etc/kolla/hosts.cfg --configdir /etc/kolla bootstrap-servers
部署前预检查:kolla-ansible -i /etc/kolla/hosts.cfg --configdir /etc/kolla prechecks
拉取镜像:kolla-ansible -i /etc/kolla/hosts.cfg --configdir /etc/kolla pull
真正部署:kolla-ansible -i /etc/kolla/hosts.cfg --configdir /etc/kolla deploy
确定安装完毕,访问123.123这个api的vip,会跳转到login的url:
[root@deploy kolla]# curl 192.168.123.123 -v* About to connect() to 192.168.123.123 port 80 (#0)* Trying 192.168.123.123...* Connected to 192.168.123.123 (192.168.123.123) port 80 (#0)> GET / HTTP/1.1> User-Agent: curl/7.29.0> Host: 192.168.123.123> Accept: */*>< HTTP/1.1 302 Found< Date: Wed, 13 Oct 2021 09:58:28 GMT< Server: Apache< Location: http://192.168.123.123/auth/login/?next=/< Content-Length: 0< X-Frame-Options: SAMEORIGIN< Vary: Accept-Language,Cookie< Content-Language: en< Content-Type: text/html; charset=utf-8<* Connection #0 to host 192.168.123.123 left intact
网络衔接
桥接网络
openstack默认希望能够直接管理一块连接到wan网络的网卡,这时候宿主机相当于失去了这块网卡,无法与wan网络通信。
是好处是后续的虚拟机可以桥接进去wan网络中,与wan网络中的其他物理机对等,用于作为互访的方式非常好。
这时候只需要将wan网卡添加进kolla-ansible配置文件中书写的br-virt网桥中即可,在网络角色宿主机执行:
docker exec -it openvswitch_vswitchd bashovs-vsctl add-port br-virt ensXX
NAT网络
有些时候我们希望网络角色宿主机继续保持与wan网络的通信,或者wan网络需要ppp拨号才能上网,这时候就需要设计搭建一层中间网络,对外通过macvlan虚拟网卡接入wan网络,然后dhcp或者ppp拿到IP进行通信,对内作为一个私网的网关,提供FORWARD+SNAT这样的网关转发能力。
docker-compose.yml:version: '2.4'networks:# macvlan模式的网络,父网卡为ens33即lan网卡,连入awanphys的网卡以及ens33均能保持与lan网络的通信awanphys:driver: macvlanname: awanphsyipam:config:- subnet: "100.64.0.0/24"gateway: "100.64.0.1"driver_opts:parent: ens33macvlan_mode: bridge# macvlan模式的网络,父网卡为ens37,即wan网卡,连入bwandhcp的网卡及ens37均能保持与wan网络的通信bwandhcp:driver: macvlanname: bwandhcpipam:config:- subnet: "100.64.1.0/24"gateway: "100.64.1.1"driver_opts:parent: ens37macvlan_mode: bridge# bridge模式网络,用于作为网关对内提供SNAT的公网访问功能clanvirt:driver: bridgename: clanvirtipam:config:- subnet: "100.64.10.0/30"gateway: "100.64.10.2"driver_opts:com.docker.network.bridge.name: lanvirt# bridge模式网络,用于作为网关对内提供SNAT的公网访问功能dlanjump:driver: bridgename: dlanjumpipam:config:- subnet: "100.64.11.0/30"gateway: "100.64.11.2"driver_opts:com.docker.network.bridge.name: lanjump# bridge模式网络,用于作为网关对内提供SNAT的lan网络访问功能elanphys:driver: bridgename: elanphysipam:config:- subnet: "100.64.12.0/30"gateway: "100.64.12.2"driver_opts:com.docker.network.bridge.name: lanphys# bridge网络,用于容器与网络角色宿主机间的通信,仅用于紧急管理通道zlaninte:driver: bridgename: zlaninteipam:config:- subnet: "100.64.30.0/24"gateway: "100.64.30.1"driver_opts:com.docker.network.bridge.name: laninteservices:virt:image: registry.cn-beijing.aliyuncs.com/ohmyadd/dhcppp:1.0.0dns: 114.114.114.114restart: alwaysprivileged: truecap_add: ["NET_ADMIN"]volumes:- /lib/modules:/lib/modules- ./conf.sh:/conf.sh- ./net.sh:/net.sh- ./cmd.sh:/cmd.shenvironment:DDNSCMD: '*/5 * * * * curl baidu.com -o /ddns.res'NETCMD: |ip r add 10.0.0.0/16 via 100.64.10.2;iptables -t nat -I POSTROUTING -m policy --pol ipsec --dir out -j ACCEPT;iptables -t nat -A POSTROUTING -s 10.0.0.0/16 -o $$OUTSIDE -j MASQUERADE;OUTSIDE: eth0networks:bwandhcp:clanvirt:zlaninte:jump:image: registry.cn-beijing.aliyuncs.com/ohmyadd/dhcppp:1.0.0dns: 114.114.114.114restart: alwaysprivileged: truecap_add: ["NET_ADMIN"]volumes:- /lib/modules:/lib/modules- ./conf.sh:/conf.sh- ./net.sh:/net.sh- ./cmd.sh:/cmd.shenvironment:DDNSCMD: '*/5 * * * * curl baidu.com -o /ddns.res'NETCMD: |ip r add 10.1.0.0/16 via 100.64.11.2;iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -o $$OUTSIDE -j MASQUERADE;iptables -t nat -A PREROUTING -i $$OUTSIDE -j DNAT --to-destination 100.64.11.2;OUTSIDE: eth0networks:bwandhcp:dlanjump:zlaninte:phys:image: registry.cn-beijing.aliyuncs.com/ohmyadd/dhcppp:1.0.0dns: 114.114.114.114restart: alwaysprivileged: truecap_add: ["NET_ADMIN"]volumes:- /lib/modules:/lib/modules- ./conf.sh:/conf.sh- ./net.sh:/net.sh- ./cmd.sh:/cmd.shenvironment:DDNSCMD: '*/5 * * * * curl baidu.com -o /ddns.res'NETCMD: |ip a add dev eth1 192.168.123.1/24 ;iptables -t nat -A POSTROUTING -s 192.168.123.0/24 -o $$OUTSIDE -j MASQUERADE ;iptables -t nat -A PREROUTING -i $$OUTSIDE -p tcp --dport 80 -j DNAT --to 192.168.123.233:80;iptables -t nat -A PREROUTING -i $$OUTSIDE -p tcp --dport 6080 -j DNAT --to 192.168.123.233:6080;iptables -t nat -A PREROUTING -i $$OUTSIDE -p tcp --dport 6784 -j DNAT --to 192.168.123.233:6784;iptables -t nat -A PREROUTING -i $$OUTSIDE -p tcp --dport 22 -j DNAT --to 192.0.30.1:22;iptables -t nat -A POSTROUTING -d 192.0.30.1 -p tcp --dport 22 -j SNAT --to 192.0.30.202;OUTSIDE: eth1networks:awanphys:bwandhcp:elanphys:zlaninte:
cmd.sh:crond/usr/sbin/sshd -D
cmd.sh先开启crond守护进程,然后拉起sshd服务进程
conf.sh:echo "root:$SSHPWD" | chpasswdecho "$SSHPUBKEY" > /root/.ssh/authorized_keysecho "$DDNSCMD" >> /etc/crontabs/root
conf.sh处理以env形式传入的配置参数
net.sh:ip route flush 0.0.0.0/0bash -c "$NETCMD"if [[ "x$OUTSIDE" != "x" ]]thendhclient $OUTSIDEif [[ "x$OUTSIDE" == "xppp0" ]]thenponfifi
net.sh执行env形式传入的NETCMD,然后根据OUTSIDE参数选择进行dhcp请求还是ppp拨号
[root@node10 exnet]# lscmd.sh conf.sh docker-compose.yml net.sh[root@node10 exnet]# pip3 install --upgrade pip[root@node10 exnet]# pip3 install docker-compose[root@node10 exnet]# docker-compose up -d
在网络角色宿主机安装docker-compose后,up启动所有容器
[root@node10 exnet]# docker exec -it openvswitch_vswitchd bash(openvswitch-vswitchd)[root@node10 /]# ovs-vsctl add-port br-virt lanvirt(openvswitch-vswitchd)[root@node10 /]# ovs-vsctl add-port br-jump lanjump(openvswitch-vswitchd)[root@node10 /]# ovs-vsctl add-port br-phys lanphys
将virt、jump、phys三个网关提供的内网对应的网桥网卡放入openstack管理的br-virt、br-jump、br-phys中。
virt、jump、phys这样的设计是为了后续的跳板机服务,也可以只创建容器负责ppp拨号以及SNAT以及DNAT,此时需要对docker-compose.yml进行删减
至此我们完成了openstack底层的事情,接下来就是利用openstack的功能,完成与我们的底层设计对接,从而为我们提供服务了。
运维
使用介绍
openstack的web管理界面horizon已经运行起来了,那么我们如何才能访问的到呢,工作机并没有lan网络的网卡,这时候可以使用正向代理技术:ssht -fNn -D 1082 root@192.168.111.132,111.132即是部署机的wan口IP。这时候为浏览器挂上socks5://127.0.0.1:1082代理,便可访问我们设置的vip了,即192.168.123.123。
这里用户名是admin,密码就是前文提到的password.yml中的keystone_admin_password
进来后左侧是菜单栏,右侧是菜单项中的详细内容,中文的翻译比较别扭,建议从头开始用英文语言界面,点击右上角的admin进入setttings进行设置:
假设这一个私有云仅由所属公司使用,那么左侧菜单栏中:
Project代表了公司里面的一个项目组,人员可以在不同的项目组拥有不同的权限,如管理、审计、使用等。
Admin菜单中包含了需要私有云运维人员进行配置的内容,代表着对云平台本身的管理。
Identity菜单基于RBAC对User、Group、Project、Roles等资源进行管理,openstack会依据其中设置进行3A访问控制。
具体identity部分比较简单,project是资源客体,user和user组成的group都是主体,在不同的project拥有不同的Role,依据Role的权限细则,主体对客体拥有不同的访问控制权限。新建一个Role可以指定他拥有哪些权限细则,如对虚拟机的删除权限。
Admin菜单是私有云运维人员的视角:
compute部分:
- hypervisors列出了集群中管理的宿主机,以及运行计算角色的宿主机的相关信息
- host aggregates是对众多运行计算角色的主机进行分组,比如头三台是部门一组使用,后四台是部门二组使用,这个功能就需要通过主机聚合功能来做。
- instance列出了当前运行的实例,即虚拟机
- flavor中可以对实例规格进行管理,实例规格即前文提到的如1c2g20g这样的服务器配置,有了flavor才能创建instance
- image是拉起虚拟机基于的镜像,镜像格式可以是qcow2、vmdk等等,谷歌搜索如centos+qcow2,官网会有很多做好的镜像以供下载使用
volume部分
- volume叫做卷,可以理解为虚拟机的一块硬盘,一个卷可以被挂载进虚拟机当作系统盘,也可以当作数据盘,甚至还可以挂载进多个虚拟机进行文件共享
- snapshot是对卷的快照,需要占用存储空间,可以在卷中数据不合适的时候,回滚到某个快照的时刻中的内容
- 剩余的内容我不太常用,可以看官网的介绍hhh
网络部分
- network代表了虚拟的二层网络,代表了一个二层广播域,位于不同宿主机上的虚拟机可以通过network进行跨宿主机通信,让虚拟机们认为彼此位于同一个网段。
- router是三层虚拟路由,一方面可以连接多个network进行他们之前的数据包路由,更重要的是需要router连接external类型的netowrk(对应前文的br-virt等)和普通的network,打通虚拟机与物理世界物理网络的通信
- floating IP功能,能够将router位于external类型的网卡上的IP收到的数据包DNAT至普通虚拟network中的某个内网IP上,达到wan网络中其他主机访问wan网络中的某个IP(floating ip),便是访问某个虚拟机的效果
- RBAC是管理,哪些项目对哪些虚拟网络有哪些权限
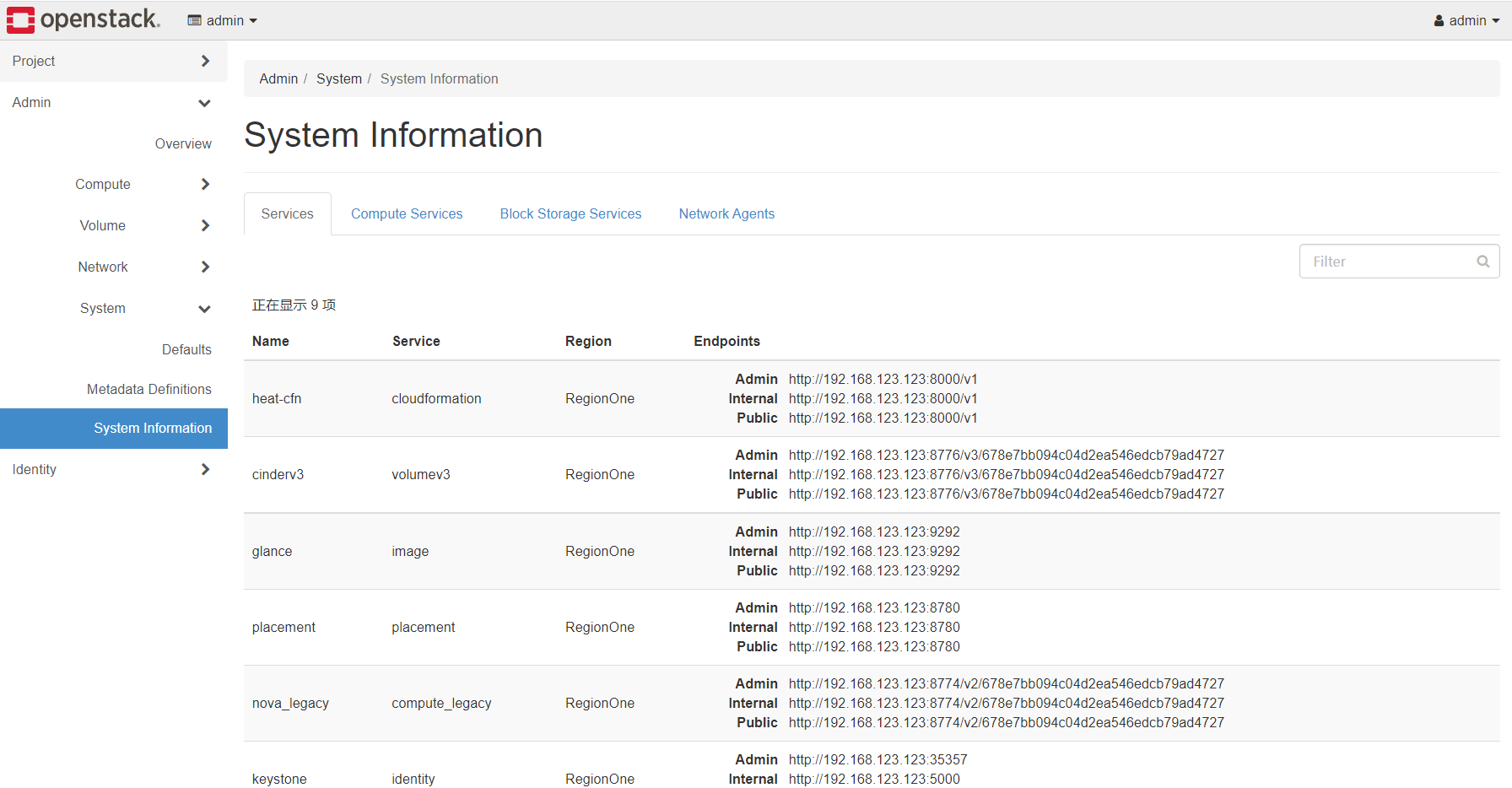
最后system菜单是一些系统配额、API对应的URL等信息。
虚拟网络
本节主要工作在Admin菜单的network二级菜单下,创建与衔接网络对应的虚拟external网络、虚拟router、虚拟普通网络等资源,以便后续创建的虚拟机与外部的双向访问:
桥接网络
如果在网络衔接部分决定要走桥接路线,已经把wan网卡放进了br-virt网桥中,这时候我们需要创建这些东西:
在networks中点击创建network: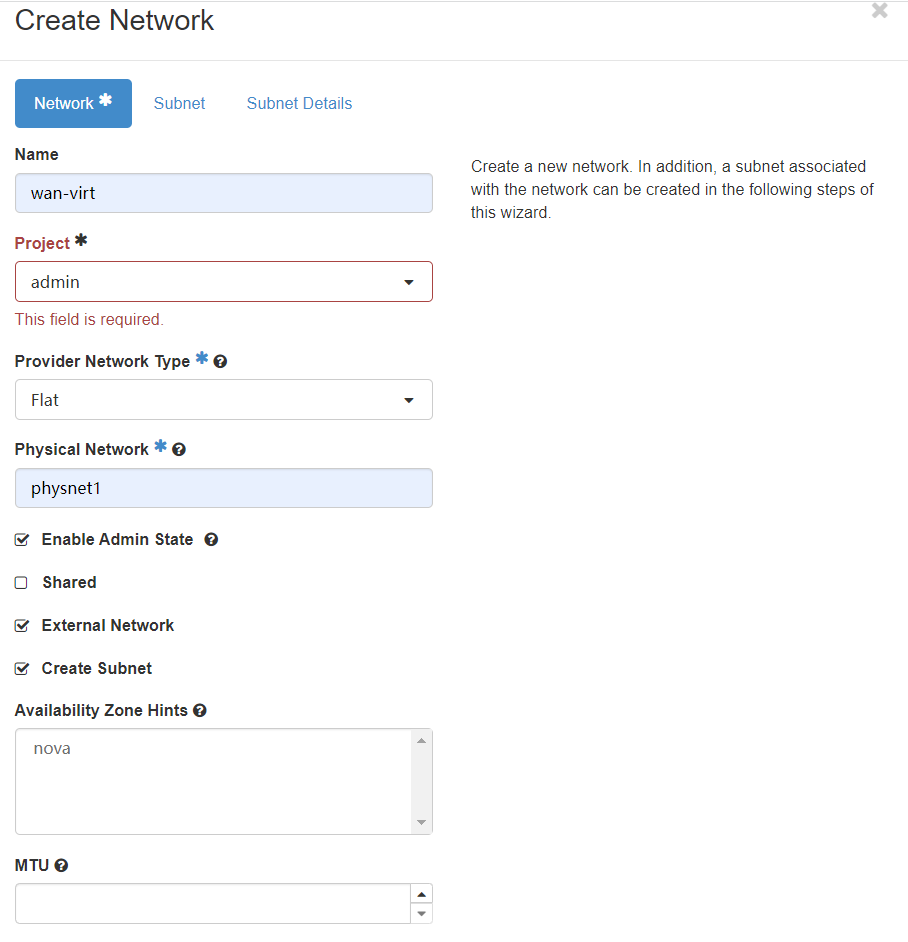
按照如上填写:
- 名称为wan-virt为了简单方便
- project代表network所属project,这里填写admin这个project,因为external类型网络是需要运维管理员进行管理的
- type的FLAT和external netowrk的勾选代表了这是一个external类型的网络
- physical network中的physnet1如前文所述,是globals.yml中bridge中的第一个,即br-virt
- wan-virt这个external虚拟二层网络,映射到了物理的br-virt这个网桥中的二层网络,而我们已经将wan网卡放入br-vrit这个网桥,因此wan网络与br-virt构成了二层的级联关系,同属一个大二层。
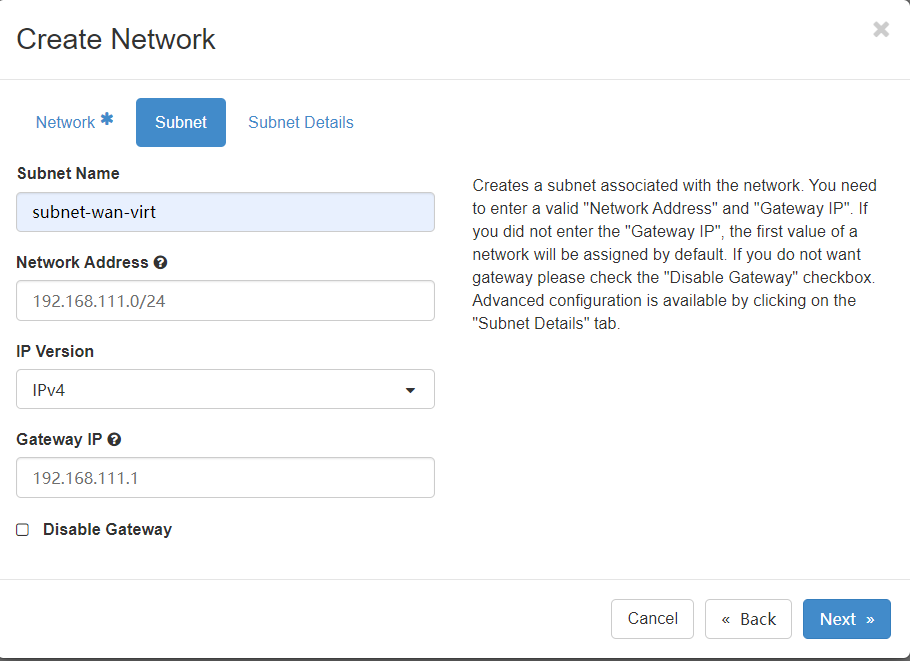
subnet配置也需要如实填写wan网络中的网段、网关信息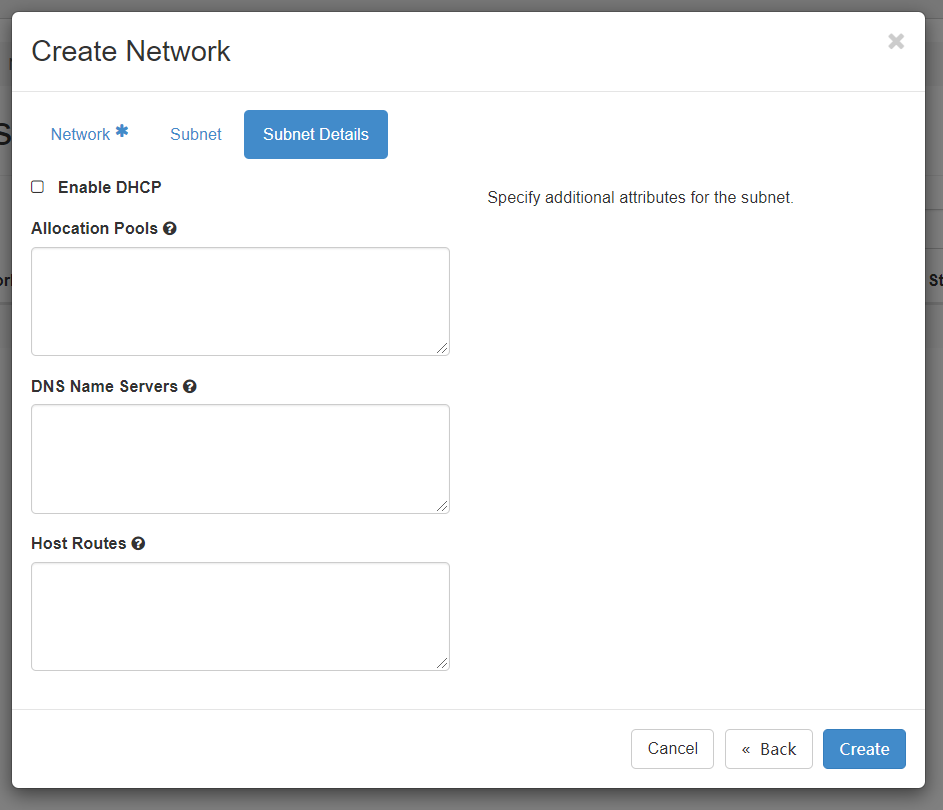
details中需要禁用openstack提供的dhcp服务,allocation pools是subnet中的一部分IP,比如openstack仅允许使用192.168.111.0/24的前50个IP。dns和host route可以不填。
最终点击create按钮,反馈创建成功。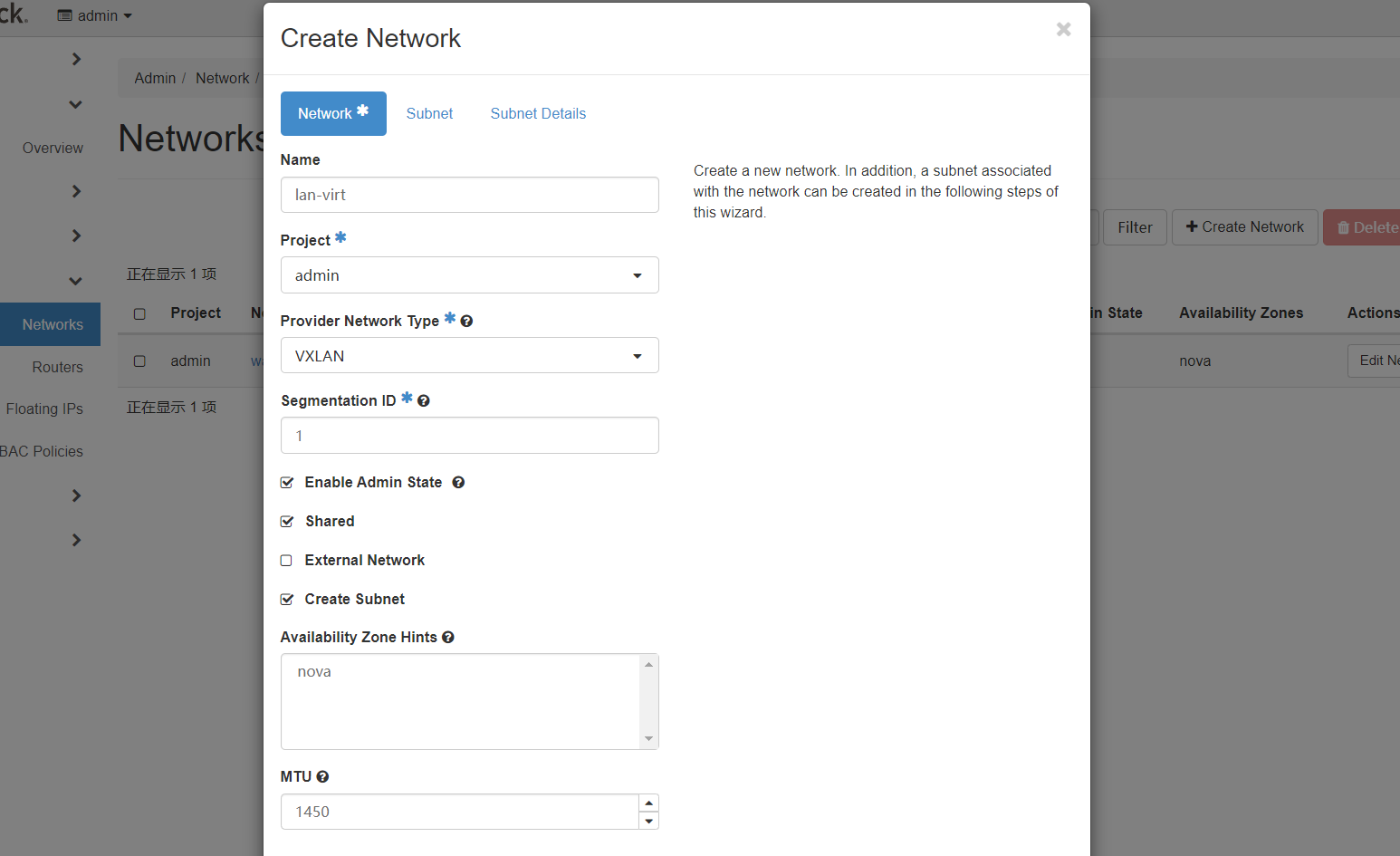
接下来再次创建一个普通的二层网络:
- project同样选择admin,但是此时勾选shared,代表其他project也可以使用virt这个虚拟网络
- type选择vxlan,segmentationID填入一个不重复的数字,最大16777215,不同的网络间这个ID不能重复(这个ID用于跨宿主机网络通信时底层的隧道协议的唯一标识)
- MTU部分填写1450,比正常的1500要小,因为虚拟机之前的通信需要通过宿主机之前的隧道协议实现,隧道协议的头部占用了50个字节。如果不填写的话,可能造成虚拟机无法下载大文件等涉及到大数据包的异常情况。
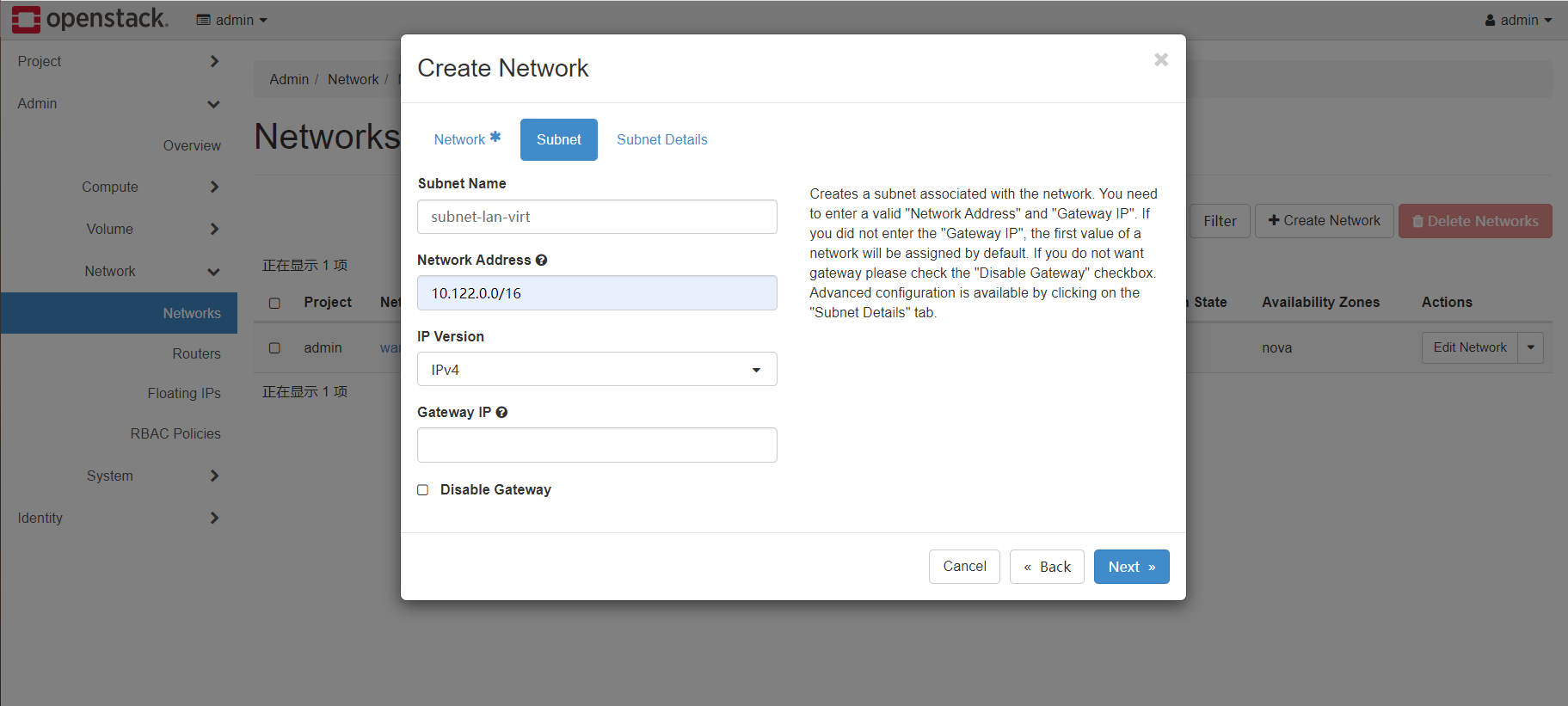
subnet部分可以填写任意的内网网段,gateway默认选择网段的第一个IP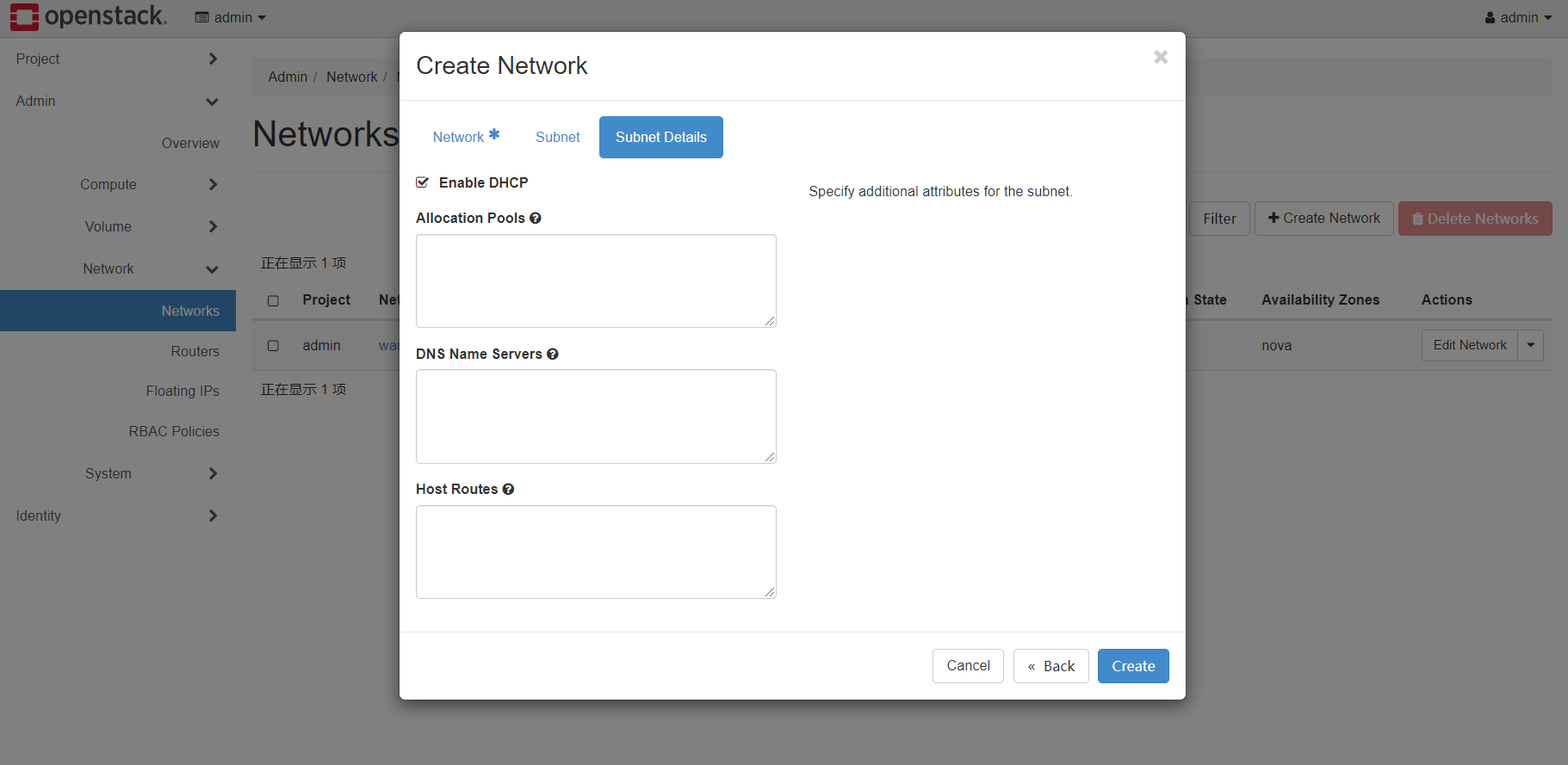
details部分
- 此时需要开启dhcp服务,因为虚拟机需要依次获取IP地址
- allocation pool与前文同理
- dns是通过dhcp服务下发给虚拟机的dns服务器配置,如114
- host route是通过dhcp下发给虚拟机的主机路由条目
最终点击create完成创建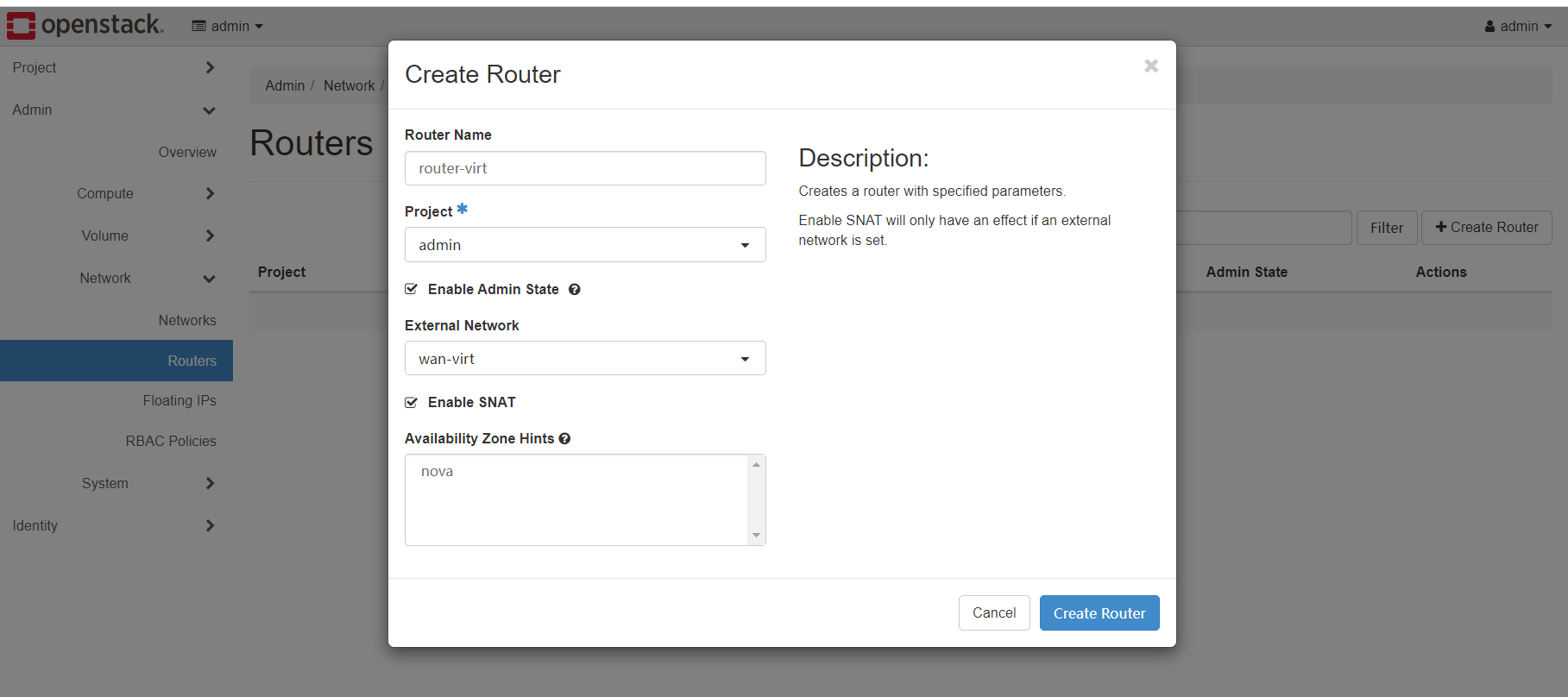
接下来来到routers部分,创建一个新的router,他的作用是连接wan-virt和lan-virt
创建成功后,点击router-virt的名字的链接后,进入interface的设置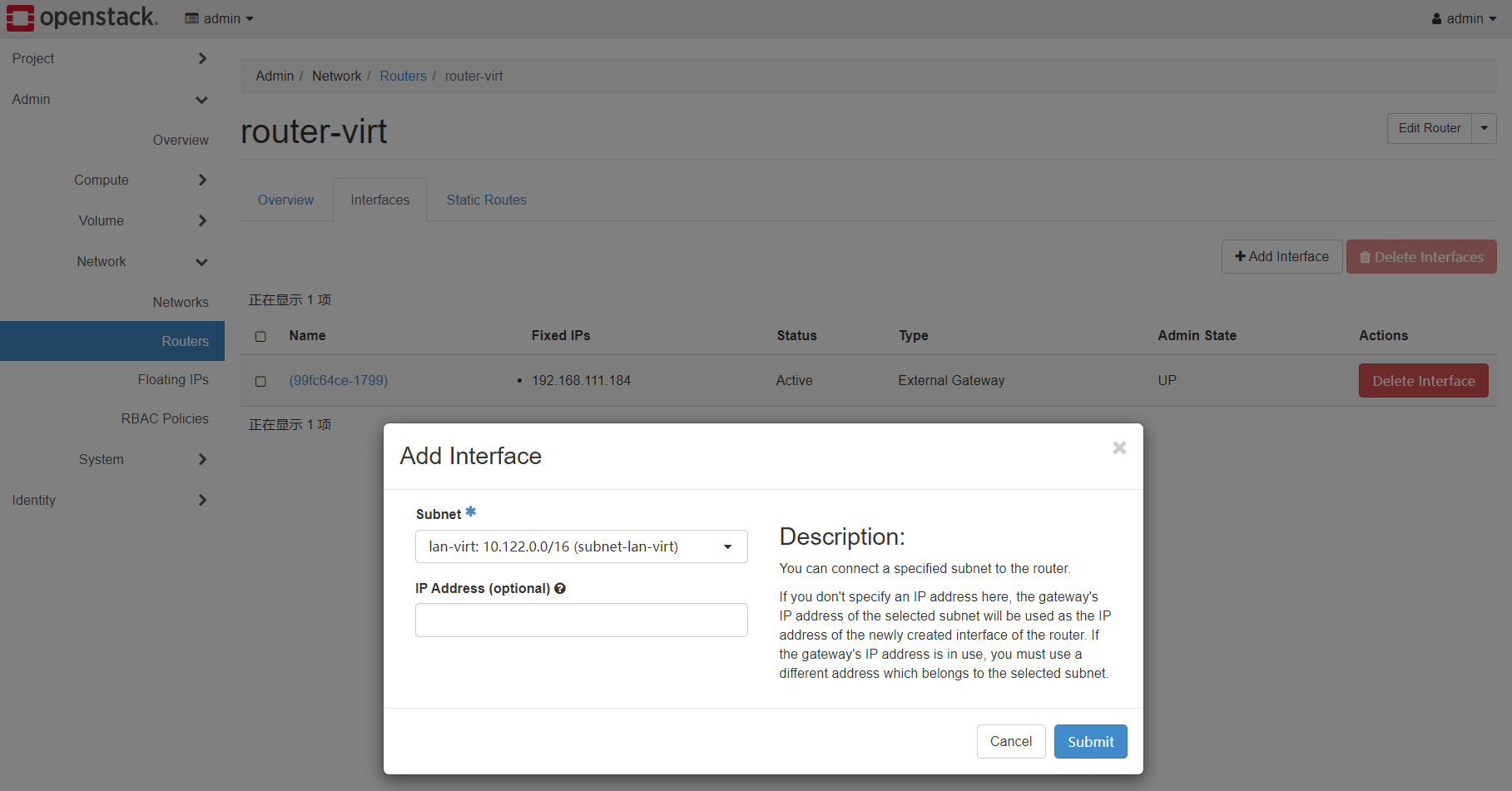
刚刚router-virt已经连接到了wan-virt,我们还需要手动连接到lan-virt,点击add interface,subnet选择lan-virt。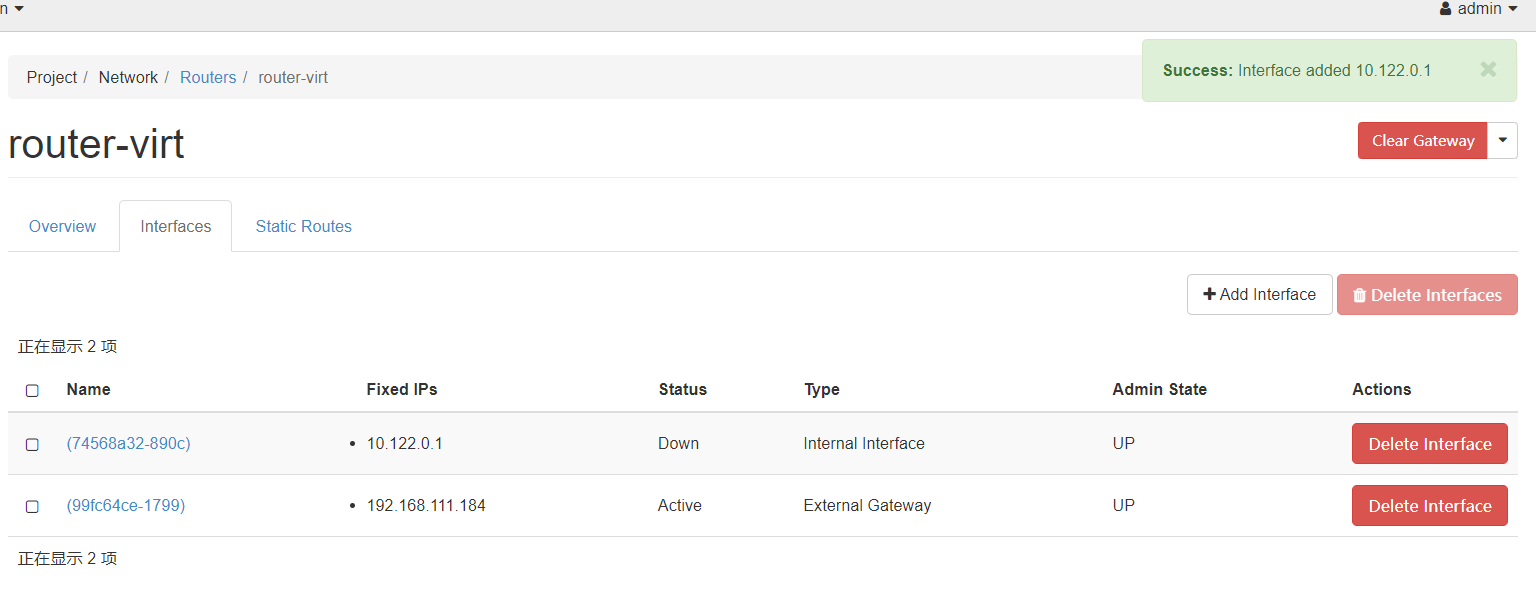
submit后添加成功。
NAT网络
延续网络衔接部分NAT网络的设计,此时需要创建三组虚拟网络资源:
- wan-virt(external, 100.64.10.0/30)、router-virt、lan-virt
- wan-jump(external, 100.64.11.0/30)、router-jump、lan-jump
- wan-phys(external, 100.64.12.0/30)、router-phys、lan-phys
- wan-xxx网络网关都默认为网段第一个IP,即100.64.10.0/30中的100.64.10.1
- lan网络的subnet同样任意设置内网网段
- 创建过程与桥接网络的手动创建过程相同,注意ID的唯一性
创建实例
准备工作
创建flavor实例规格,以1c2g为例,root disk大小的20G并不代表最后系统盘大小,仅用于判断是否足够大拉起对应镜像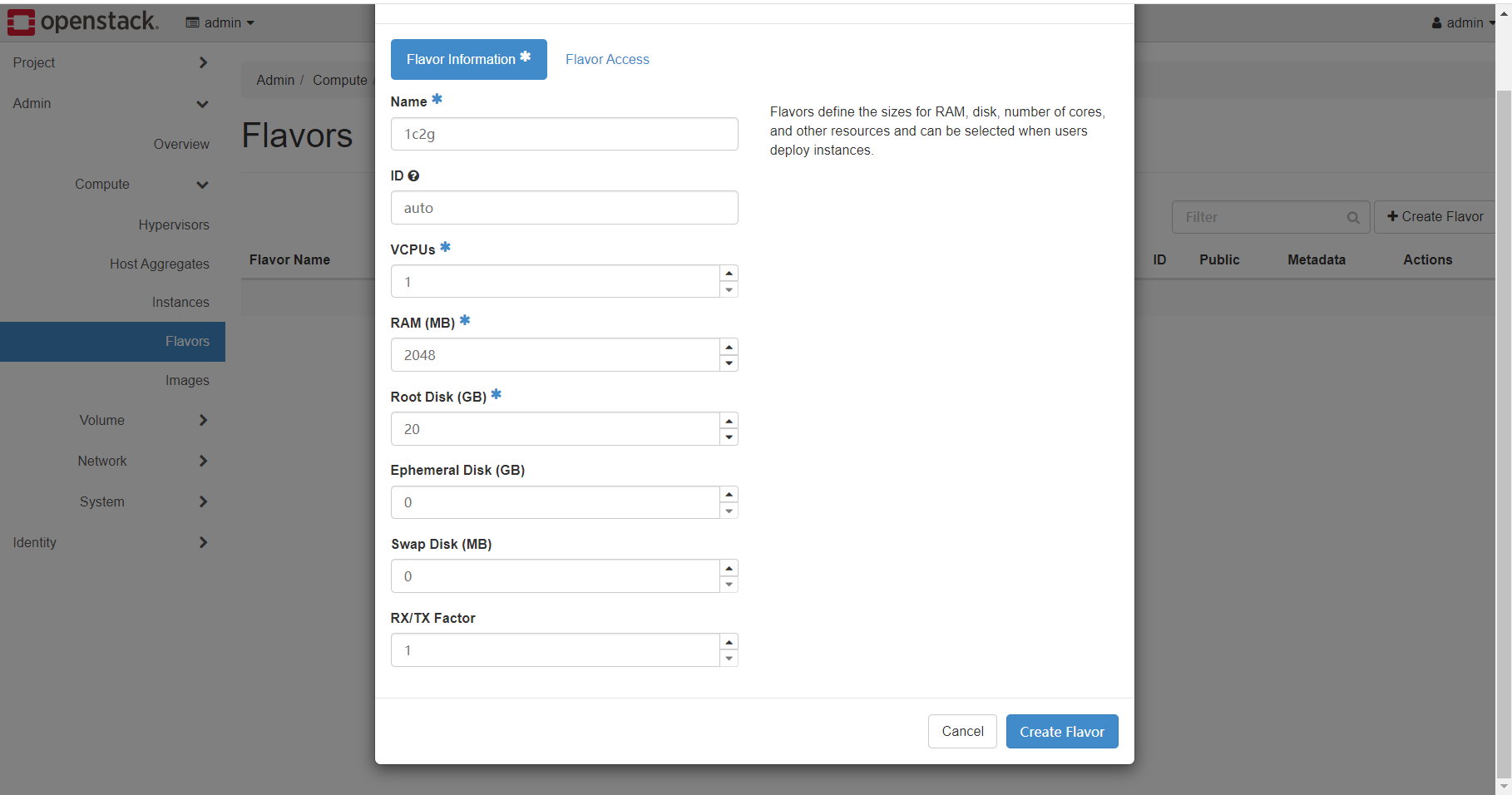
下载centos7 qcow2镜像,https://cloud.centos.org/altarch/7/images/CentOS-7-x86_64-GenericCloud-2003.qcow2.xz,下载好记得解压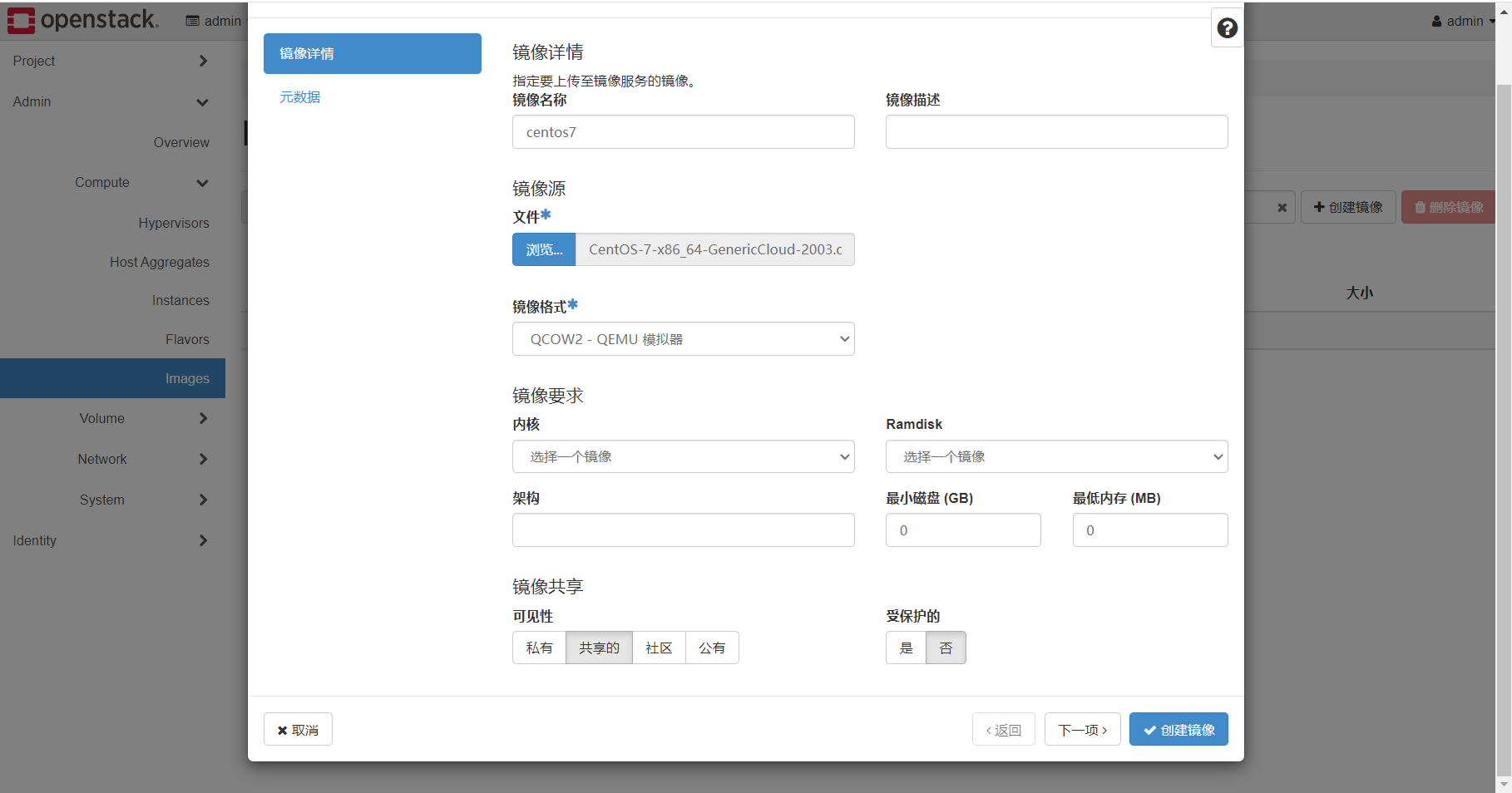
Admin.Images里创建新的镜像,把刚刚解压出来的qcow2格式的镜像上传,名称写centos7。
接下来在Identity中创建project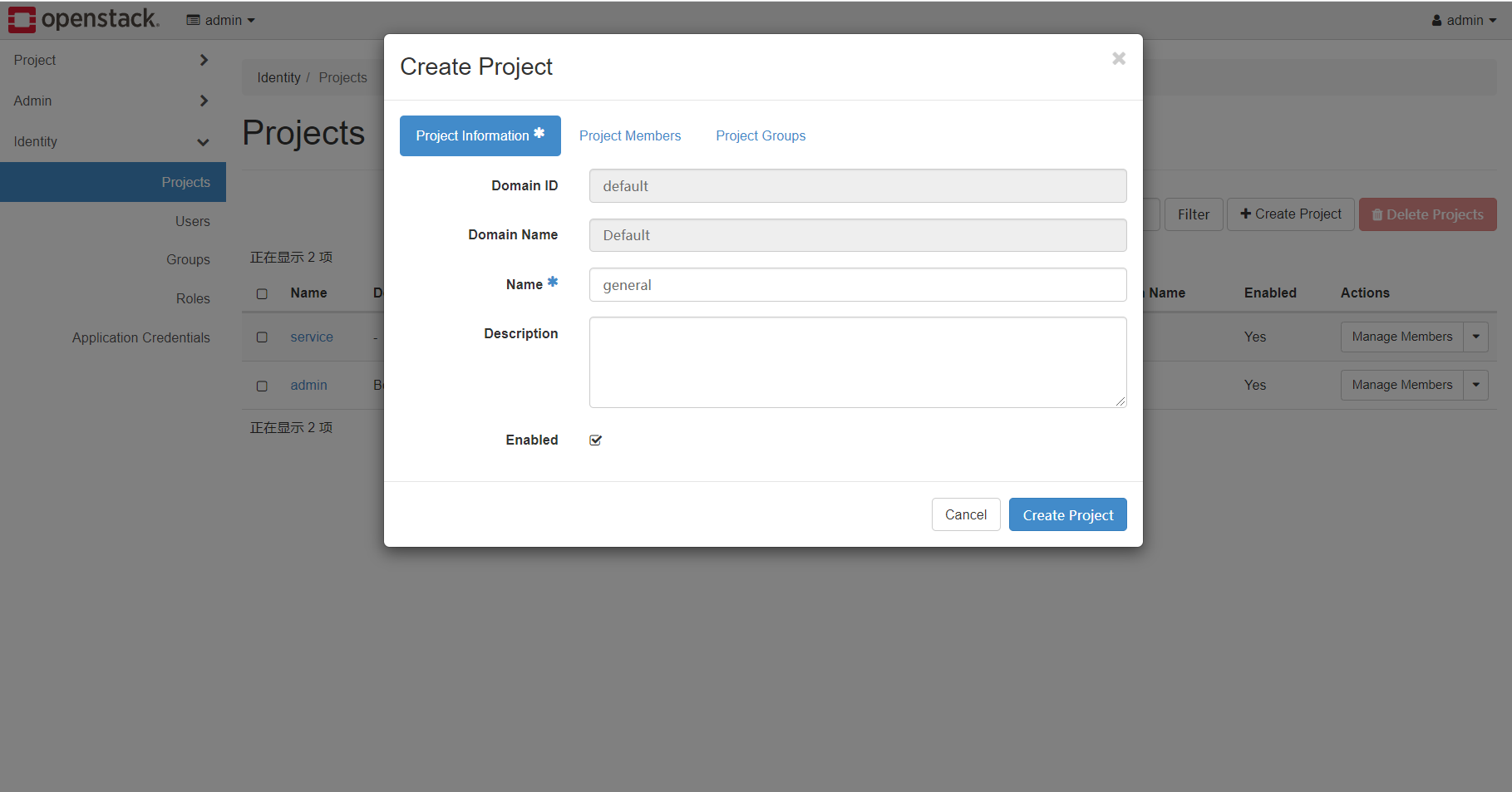
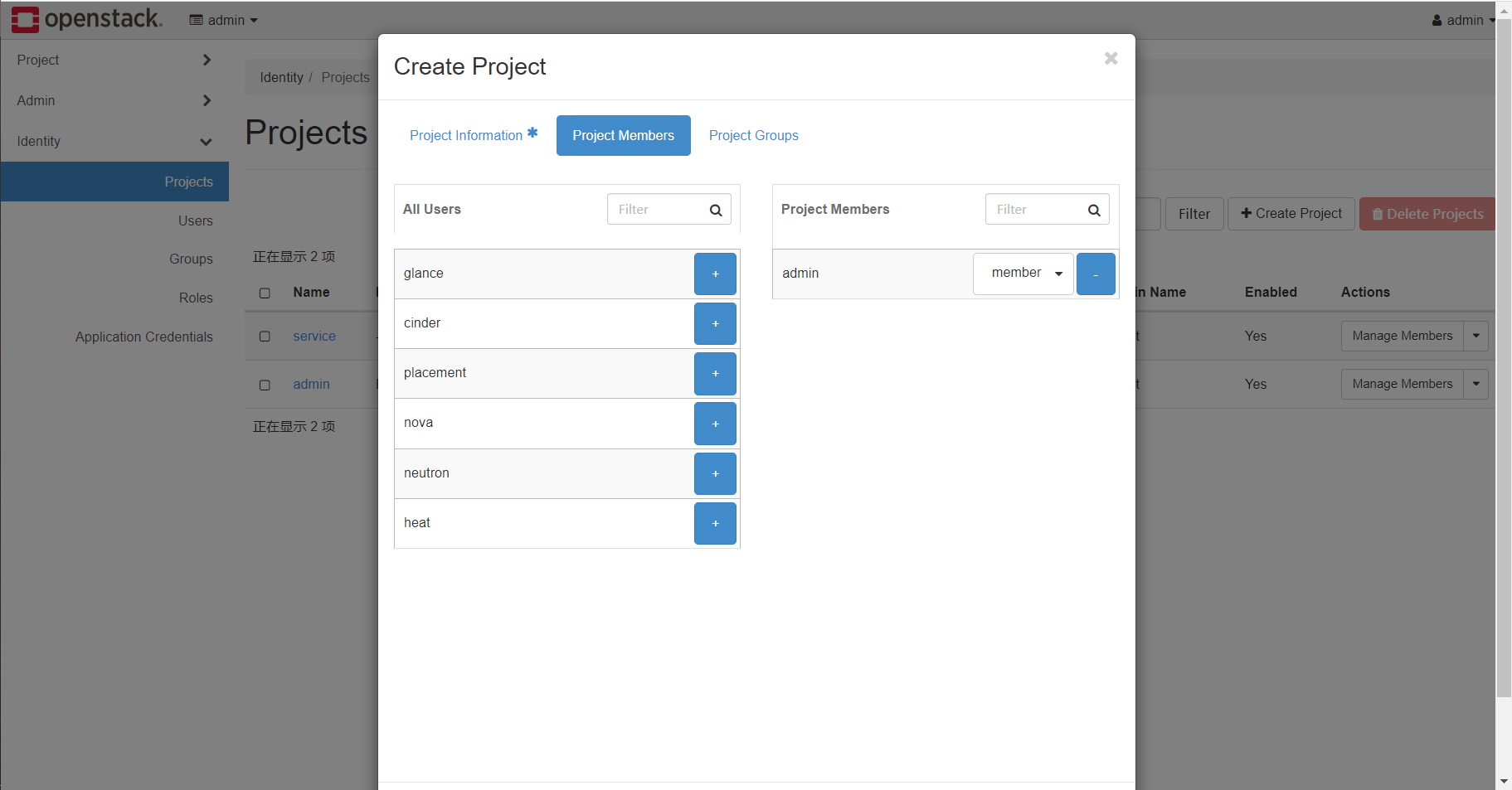
将admin用户添加进入本project,并同时给予member和admin角色权限,Project Group无需配置。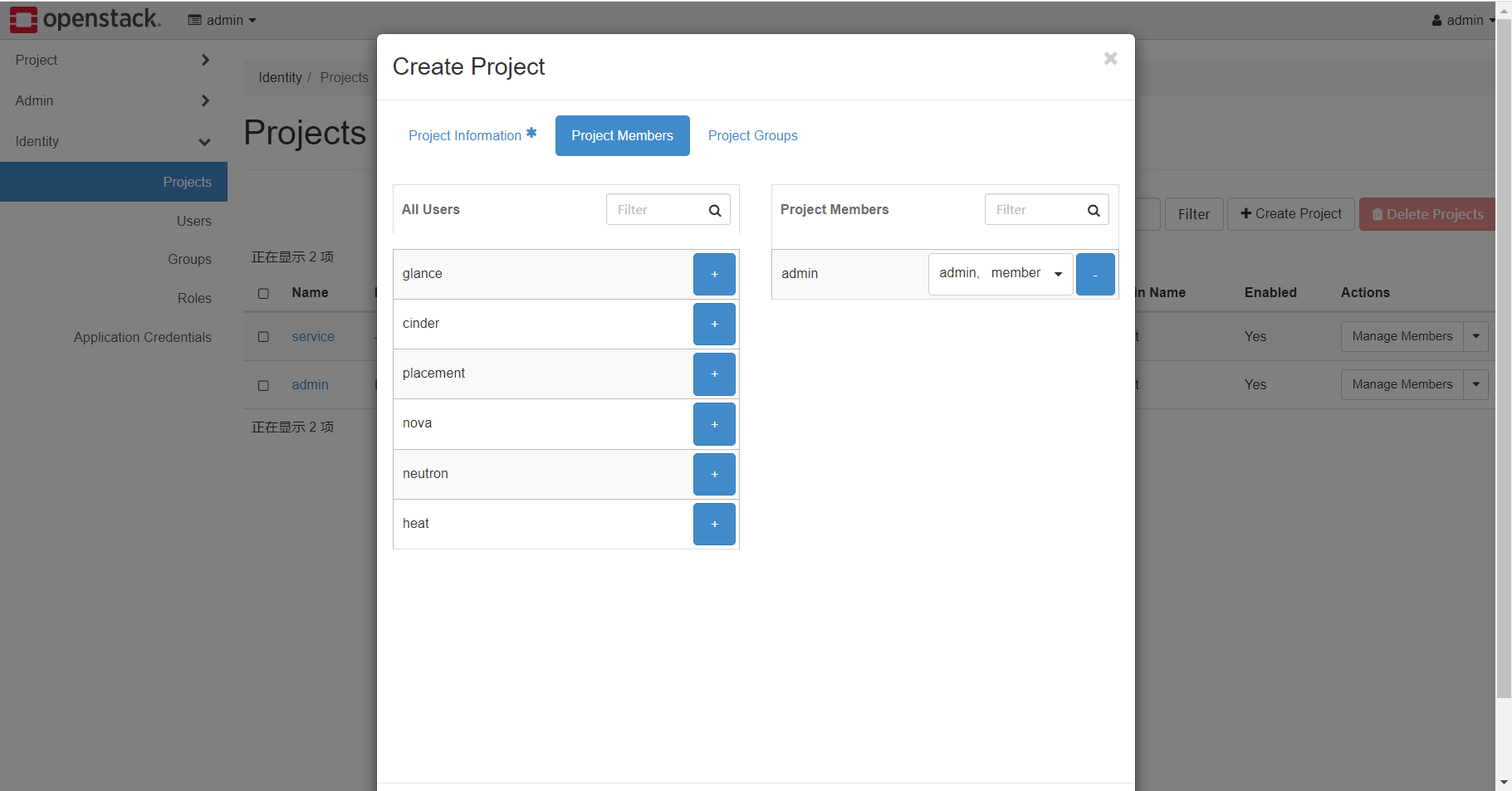
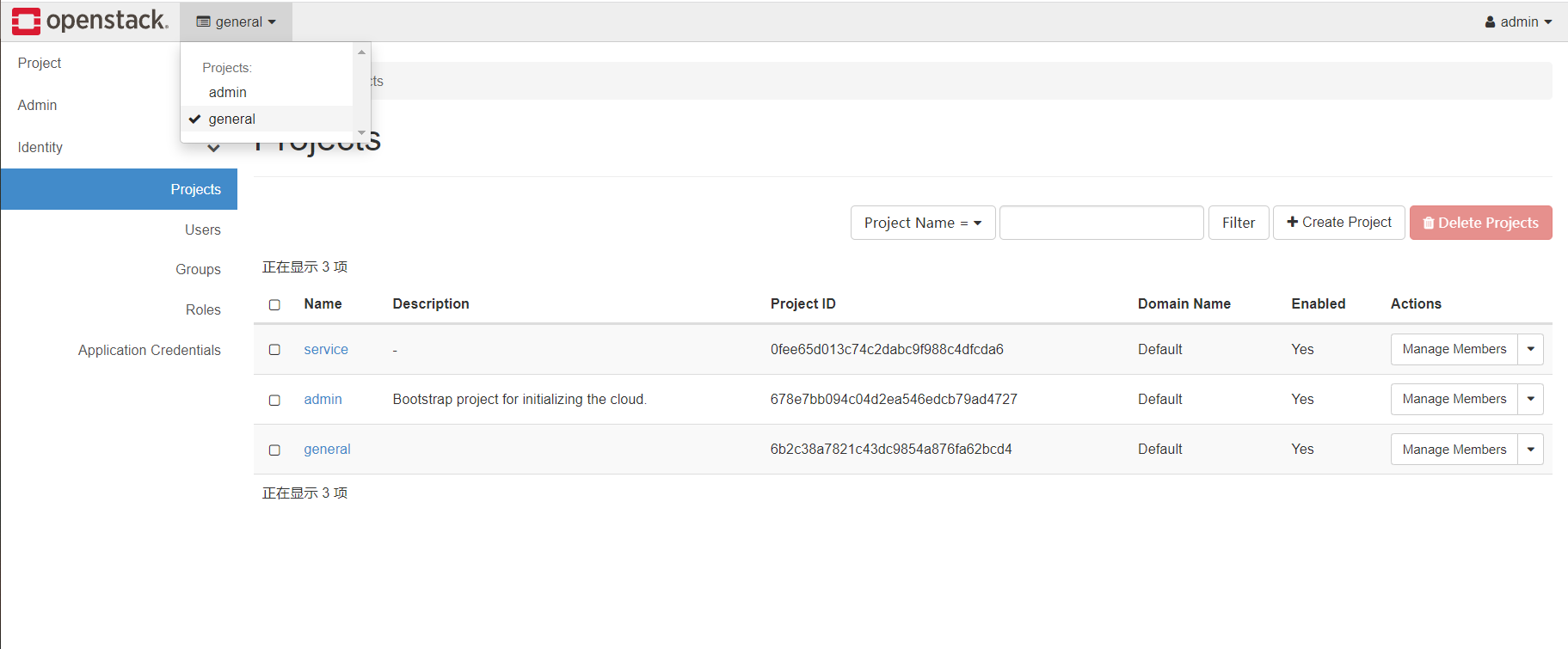
创建好后,左上角当前project选项,选择刚刚创建的general,如上图。
接下来进入project中的network部分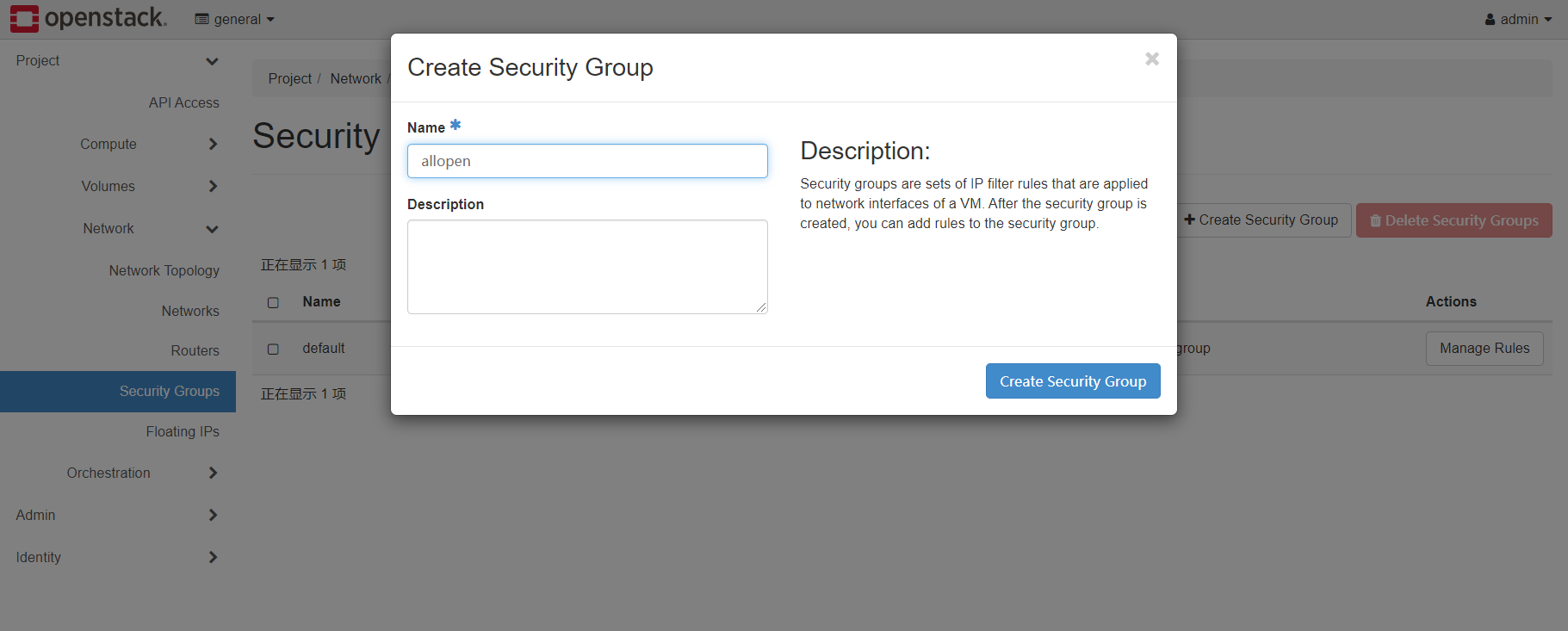
创建新的security groups即安全组,用于网络上的三层IP、四层TCPUDP访问控制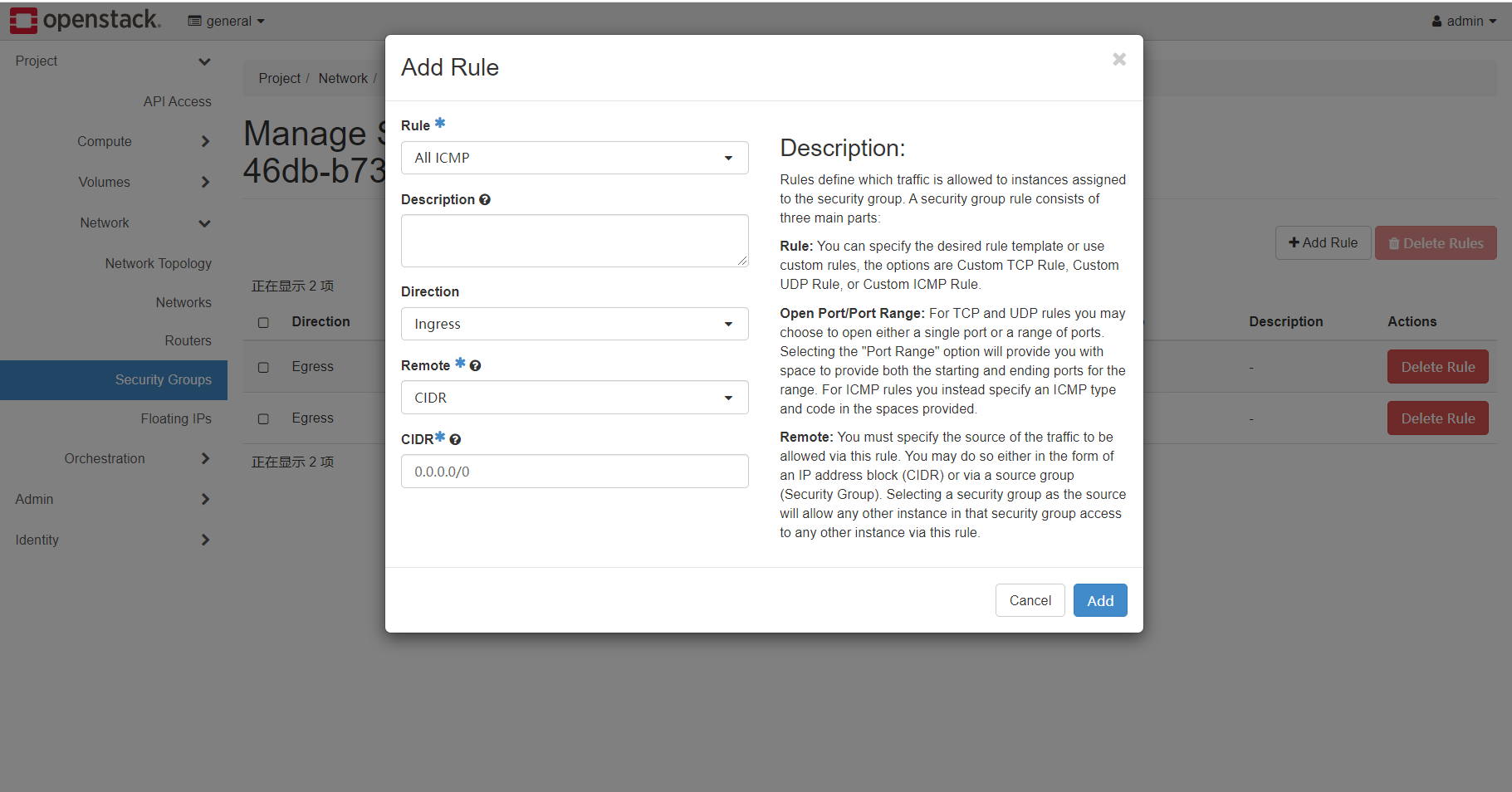
添加三条规则,在入方向(以虚拟机本机为第一人称)放行所有的TCP、UDP、ICMP通信,效果如图: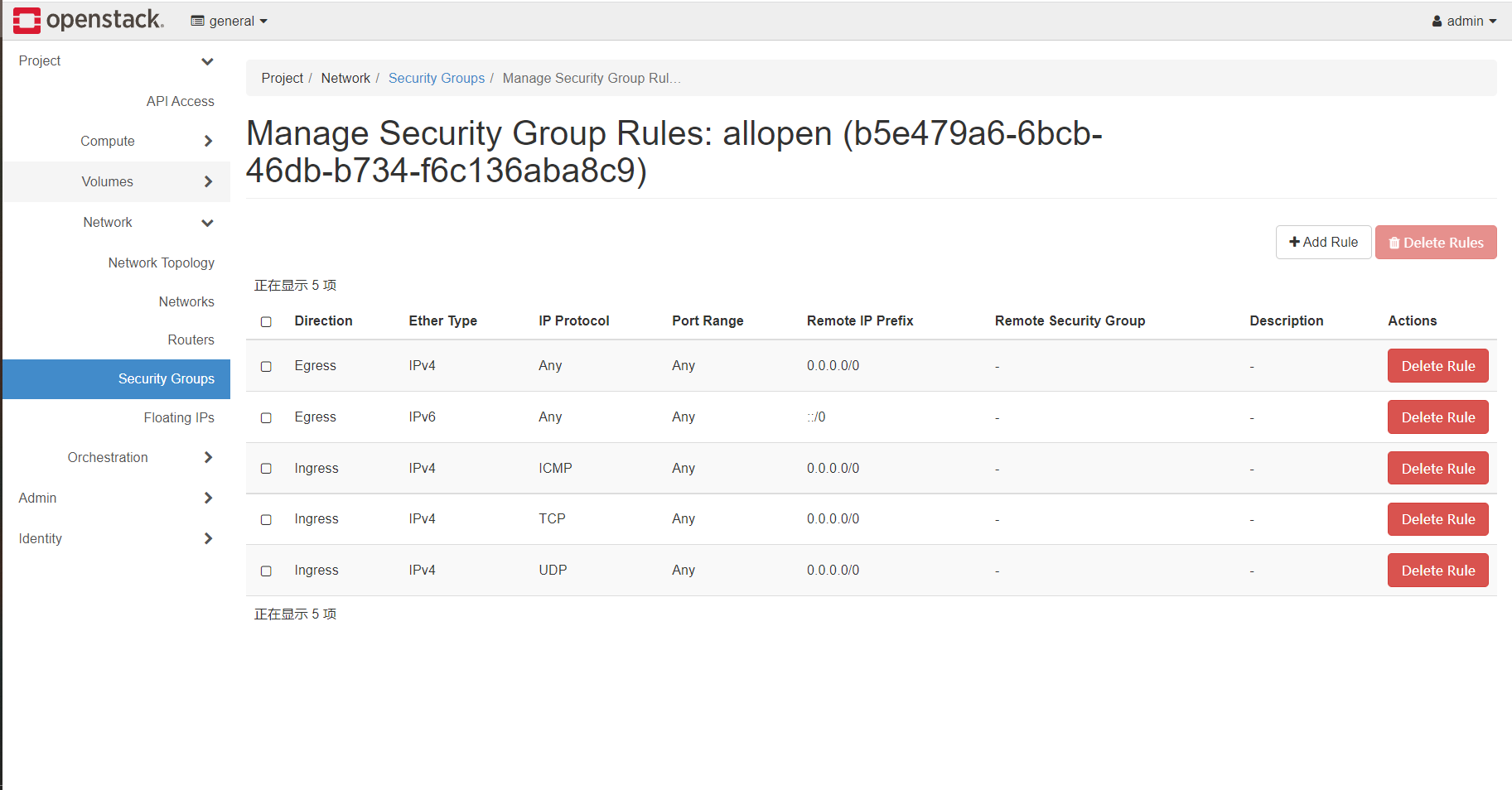
创建实例
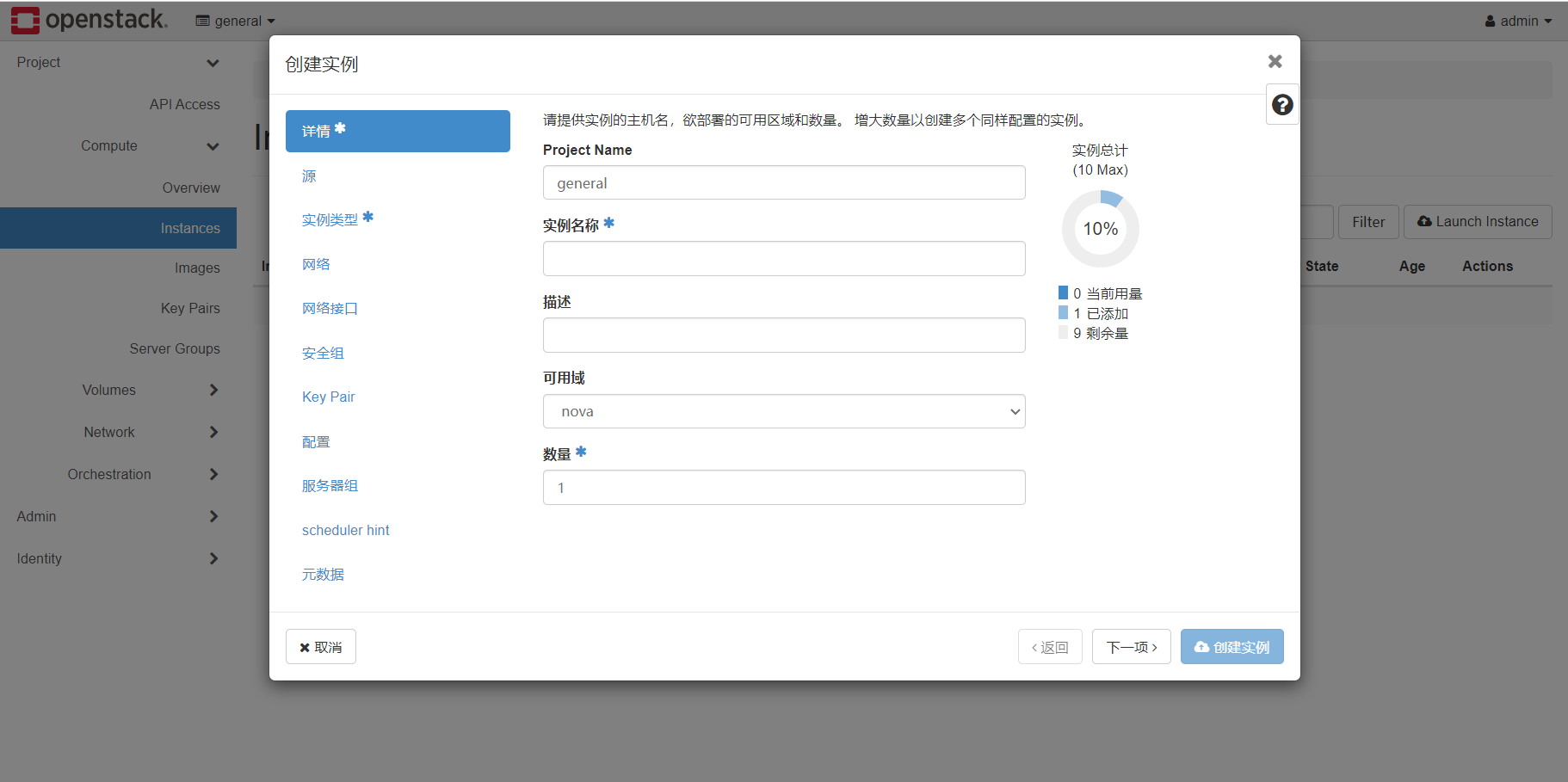
点击project.instace下面的lanuch instance,正式开始创建实例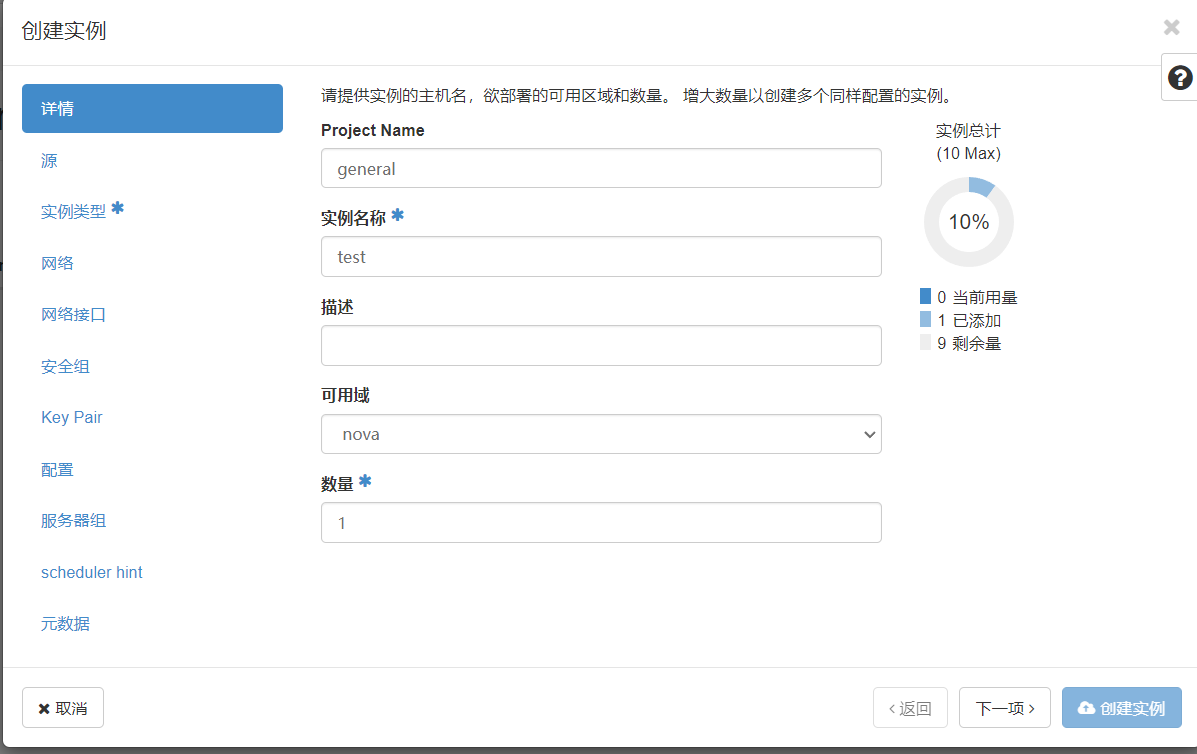
实例名称必填,数量如果填大于1的数字,则会创建test-1,test-2,…以此类推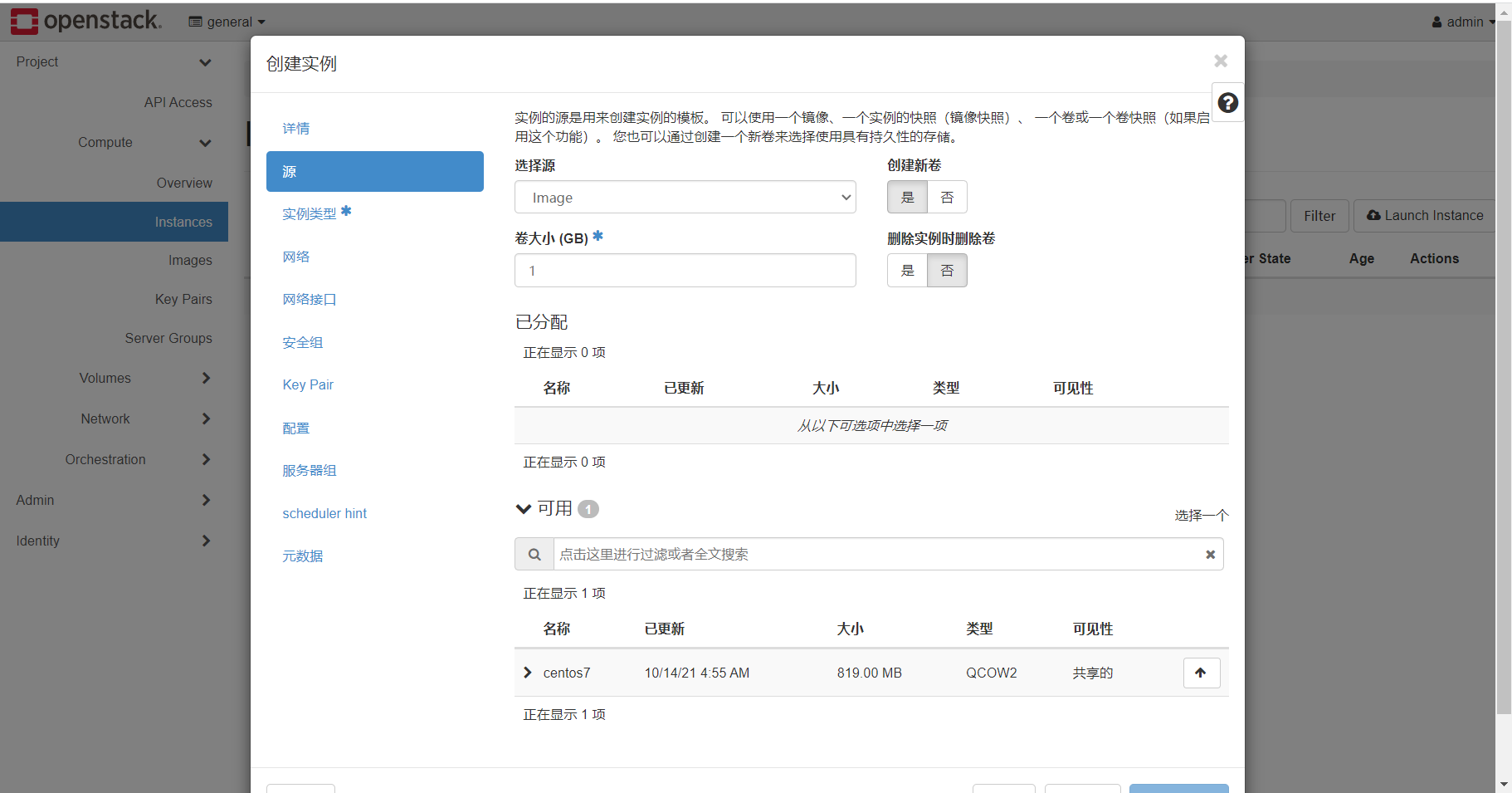
源代表着镜像来源,为系统盘分配21G空间,通过箭头将centos7加入已分配区域,即以centos7为虚拟机镜像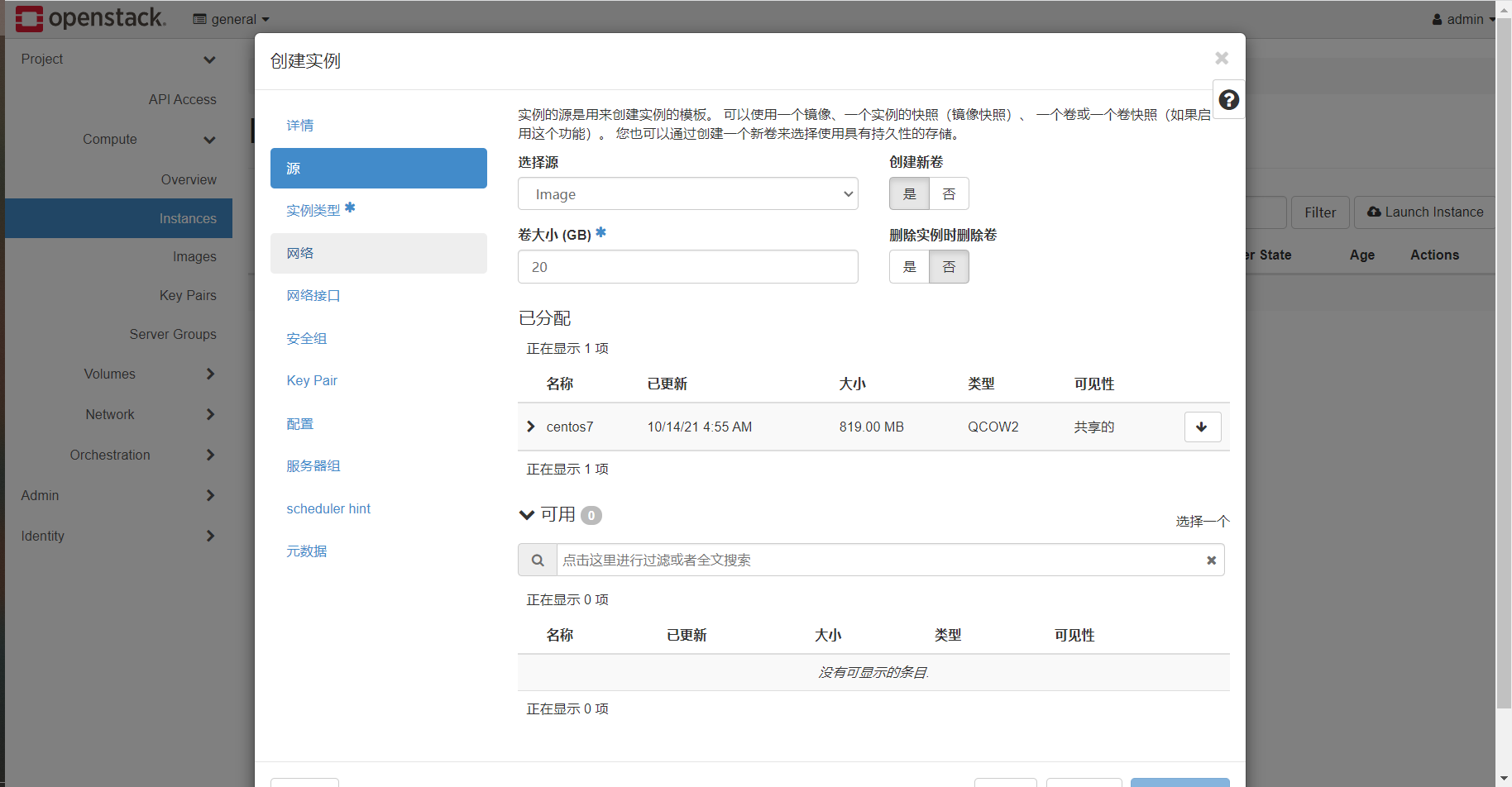
实例类型选择刚刚创建的1c2g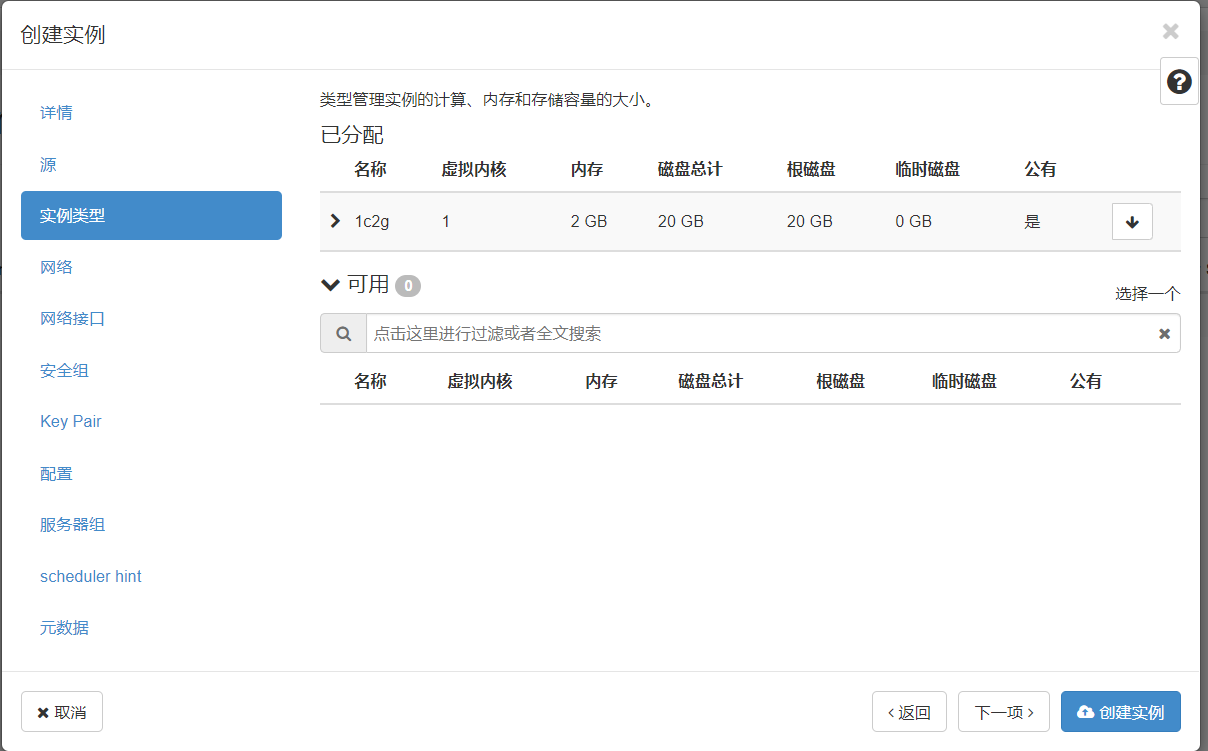
网络选择lan-virt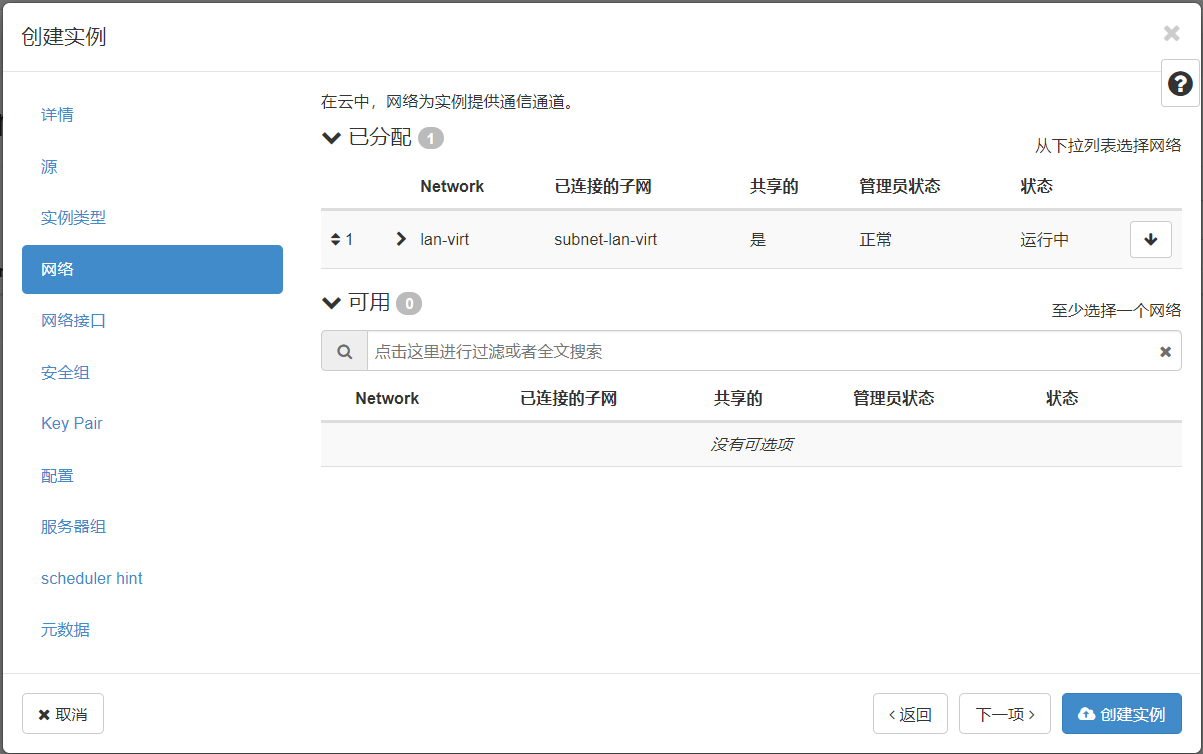
安全组仅使用我们创建的allopen
keypair部分设置root密码
点击创建实例
跳板机部署
跳板机运营

若有收获,就点个赞吧
0 人点赞
