1、聚合函数
select e.job,sum(e.sal) as sum_sal,avg(e.sal) as avg_sal,max(e.sal) as max_sal,min(e.sal) as min_sal,count(e.sal) as count_salfrom emp egroup by e.job;
2、nvl 空值转换函数
select e.comm,nvl(e.comm,0) as new_comm1,nvl(e.comm,1000) as new_comm2 -- 你想返回什么值就写什么-- ,nvl(e.comm,'a') as new_comm3 -- 报错 数据类型要一致from emp e;-- Nvl2 空值转换函数升级版-- 如果不是空值就返回第二个参数 如果是空值就返回第三个参数select e.comm,nvl2(e.comm,e.comm,0) as new_comm1 -- 实现nvl的功能 如果不是空值返回它本身 如果是空值则返回第三个参数,nvl2(e.comm,100,200) as new_comm2from emp e;
3、mod 求余函数
select mod(32,3) from dual;
4、power 求幂
select power(2,10) from dual;
5、concat 拼接字符串函数
-- concat 拼接字符串函数 只能拼接两个 || 可以拼接多个字符串select concat('ss',10) from dual;
6、ASCII 返回字符的ASCII码
select ASCII('a') from dual;
7、length与lenghtb
-- LENGTH与LENGTHB的区别 一个算个数 一个算长度select LENGTH('aaa') from dual;select LENGTH('唐老师') from dual;select LENGTHB('唐老师') from dual;
8、lower upper 字母大小写
-- 字母转大小写select LOWER('AAAvv'),UPPER('AAAvv') from dual;
9、replace 替换
select replace('aaffcc','f','xxx'),replace('aaffcc','ff','xx'),replace('aaffccffcc','ff','xx') from dual;
10、去空 操作ltrim
-- 默认去空格 你还可以去掉你想要去掉的字符select '=='|| ltrim(' aaa'),ltrim('bbbaaa','b') from dual;select rtrim(' aaa ')||'==',rtrim('bbbaaa','a') from dual;-- 默认去掉两边的空格select '=='||trim(' aaa ') ||'==',trim('a' from 'aaabbbaaa') from dual;
11、instr 返回字符串的位置
select instr('Helloweorld','e') -- 默认从第一个字符开始返回字符第一次出现的位置,instr('Helloweorld','e',1,2) --'1'为指定从第一个字符开始, '2'为第二次出现,instr('Helloweorldex','e',5,2) --从第五个字符开始,第二次出现from dual;
12、substr 截取
-- 第三个参数可以省略 默认截取到最后select substr('ABCDE',2) from dual;select substr('ABCDE',2,3) from dual; --从第2位开始截取,截取三位select ename,substr(ename,2,3) from emp;select ename,substr(ename,-3,2) from emp; --从倒数第三位开始截取,截取两位-- 工作中经常要用的select substr('20200913',1,4) -- 截取年,substr('20200913',5,2) -- 截取月,substr('20200913',7,2) -- 截取日from dual;
13、数字函数
--数字函数abs(x) --x绝对值 abs(-3)=3mod(x,y) --x除以y的余数 mod(8,3)=2power(x,y) --x的y次幂 power(2,3)=8round(x[,y]) --x在第y位四舍五入 round(3.456,2)=3.46trunc(x[,y]) --x在第y位截断 trunc(3.456,2)=3.45ceil(x) --大于或等于x的最小值 ceil(5.4)=6 天花板floor(x) --小于或等于x的最大值 floor(5.8)=5 地板-- 绝对值select abs(3),abs(0),abs(-3)from dual;-- 余数select mod(12,3),mod(12,10)from dual;-- 幂select power(2,3),power(2,10) -- 1024 程序员的节日from dual;-- round 四舍五入 默认到整数select round(2073.21428571429,4),round(2073.61428571429),round(2073.21428571429,-2)from dual;-- 求部门平均工资 四舍五入到小数点后四位select e.deptno,avg(e.sal) as avg_sal,round(avg(e.sal),4) as avg_sal_rdfrom emp egroup by e.deptno;-- trunc 截取 默认到整数select trunc(2073.21428571429,4),trunc(2073.61428571429),trunc(2273.21428571429,-2)from dual;select e.deptno,round(avg(e.sal),4) as avg_sal,trunc(avg(e.sal),4) as avg_salfrom emp egroup by e.deptno;-- ceil(5.4)=6 往上收-- floor(5.8)=5 往下收select ceil(5.00001),floor(5.99999999)from dual;
14、日期函数
--日期函数:
-- 两个日期相减 就是天数
select e.hiredate,sysdate, sysdate - hiredate as dt from emp e;
-- 日期可以直接 加减数字 那个数字表示天数
select sysdate
,sysdate + 5
,sysdate - 5
,sysdate + 0.5 -- 半天
,sysdate + 1/24 -- 一个小时
from dual;
-- add_months 月份加减 年份加减
select sysdate
,add_months(sysdate,2)
,add_months(sysdate,-2)
,add_months(sysdate,12) -- 年份加减
from dual;
-- last_day 当前日期所在月份的最后一天
select sysdate,last_day(sysdate) from dual;
select sysdate
,last_day(sysdate) + 1 -- 下月的第一天
,add_months(last_day(sysdate) + 1,-1) -- 当月的第一天
from dual;
-- round 四舍五入 默认天
select round(sysdate) from dual;
-- 周的四舍五入
select round(sysdate,'day') from dual;
-- 年和月的四舍五入
select round(sysdate,'year')
,round(sysdate,'month')
from dual;
-- trunc 截取 默认天
select trunc(sysdate) from dual;
-- 周的截取
select trunc(sysdate,'day') from dual;
-- 年和月的截取 所在年份/月份得第一天
select trunc(sysdate,'year')
,trunc(sysdate,'MONTH')
from dual;
-- 返回星期几
select to_char(sysdate,'day') from dual;
15、类型转换
一 字符转日期 to_date
SELECT to_date('20180101','yyyymmdd')
,to_date('20180101 153540','yyyymmdd hh24miss')
,to_date('2018-01-01 15:35:40','yyyy-mm-dd hh24:mi:ss')
FROM dual;
二 日期转字符 to_char
SELECT to_char(SYSDATE,'yyyymmdd hhmiss') -- 默认12小时制
,to_char(SYSDATE,'yyyymmdd hh24miss')
,to_char(SYSDATE,'yyyymmdd')
,to_char(SYSDATE,'yyyymm')
,to_char(SYSDATE,'yyyy')
FROM dual;
SELECT to_char(SYSDATE,'yyyy-mm-dd')
,to_char(SYSDATE,'yyyy/mm/dd')
,to_char(SYSDATE,'yyyy-mm-dd hh24:mi:ss')
FROM dual;
三 字符 互转 数字 to_number to_char
-- oracle会自动的做下面的转换
-- 字符转数字 to_number
SELECT to_number('777') FROM dual;
-- 数字转字符
SELECT to_char(777) FROM dual;
16、补齐
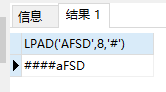
-- lpad 左补齐
SELECT lpad('aFSD',8,'#') FROM dual;
-- rpad 右补齐
SELECT Rpad('aFSD',8,'#') FROM dual;

17、大小的另外取法 least greatest
-- least 最少的
select least (null,11,22 ) -- 如果有空值则返回空值
,least (33,11,22 ) -- 如果没有空值返回最小的
from dual ;
-- greatest 最大的
select greatest (null,11,22 ) -- 如果有空值则返回空值
,greatest (33,11,22 ) -- 如果没有空值返回最大的
from dual ;
--
select coalesce (null,11,22 ) -- 返回第一个不是空值的字段
from dual ;
18、exists
19、decode与case when
-- decode 不是所有数据库都可用
-- case when 通用 功能比decode强大多了
-- decode 可以实现的 CASE WHEN都可以实现,反之不一定
-- decode 针对一个字段的值去判断
SELECT e.*
,DECODE(e.job,'CLERK','职员' --判断job字段,如果是 'CLERK' 的时候,就给值 '职员'
,'SALESMAN','销售员'
,'PRESIDENT','董事长'
,'MANAGER','经理'
-- ,'ANALYST','分析师'
,'分析师' --剩下的都是分析师 如果是确定的不建议这么写
) AS new_job
FROM emp e;
-- case when 改写上面的语句 语法:case when 条件 then 值 else end
SELECT e.*
,CASE WHEN job = 'CLERK' THEN '职员'
WHEN job = 'SALESMAN' THEN '销售员'
WHEN job = 'PRESIDENT' THEN '董事长'
WHEN job = 'MANAGER' THEN '经理'
-- WHEN job = 'ANALYST' THEN '分析师'
ELSE '分析师' --剩下的都是分析师,我们尽量不写 else 代码可读性不强
END AS new_job
FROM emp e;
-- when 后面可以接多个条件
SELECT e.*
,CASE WHEN job = 'CLERK' THEN '职员'
WHEN job = 'SALESMAN' or job = 'PRESIDENT' or job = 'MANAGER' or job = 'ANALYST'
THEN '分析师'
END AS new_job
FROM emp e;
-- 判断字段还可以写在case when的中间 我不建议这么写
SELECT e.*
,CASE job WHEN 'CLERK' THEN '职员'
WHEN 'SALESMAN' THEN '销售员'
WHEN 'PRESIDENT' THEN '董事长'
WHEN 'MANAGER' THEN '经理'
WHEN 'ANALYST' THEN '分析师'
END AS new_job
FROM emp e;
--case 嵌套
select e.*
,case when deptno = 10
then case when sal >= 2500 then 'A1'
when sal < 2500 then 'B1' end
when deptno = 20
then case when sal >= 1800 then 'A2'
when sal < 1800 then 'B2' end
when deptno = 30
then case when sal >= 1200 then 'A3'
when sal < 1200 then 'B3' end
end as sal_grade
from emp e;
20、分析函数
-- 分析函数的语法:分析函数(分析的字段) over(partition by 分组的字段 order by 排序的字段)
-- lead 向上 lag 向下 默认是移一行
select e.empno,e.deptno,e.sal
-- ,lead(e.sal) over(order by sal) as lead1
-- ,lag (e.sal) over(order by sal) as lag1
-- ,lead(e.sal) over(partition by null order by sal) as lead1
-- ,lag (e.sal) over(partition by null order by sal) as lag1
,lead(e.sal) over(partition by e.deptno order by sal) as lead2
,lag (e.sal) over(partition by e.deptno order by sal) as lag2
from emp e;
-- 也可以移动多行
select e.empno,e.deptno,e.sal
,lead(e.sal,2) over(order by sal) as lead1
,lag (e.sal,5) over(order by sal) as lag1
from emp e;
-- 参数可以是负数么? 不可以
-- 聚合的分析函数 min max avg sum count
-- 不要分组 整个表看成一组
-- 与聚合函数的区别:聚合函数数据量会变少,分析函数数据量不会变少
select e.empno,e.deptno,e.sal
,min(e.sal) over(partition by null) as min_sal
,max(e.sal) over(partition by null) as max_sal
,avg(e.sal) over(partition by null) as avg_sal
,sum(e.sal) over(partition by null) as sum_sal
,count(e.sal) over(partition by null) as count_sal
from emp e;
-- 用分析函数 来解决以前讲过的问题
select e.*
,avg(e.sal) over(partition by null) as avg_sal
from emp e;
-- 分组的情况下 组里面再去求
select e.empno,e.deptno,e.sal
,min(e.sal) over(partition by e.deptno) as min_sal
,max(e.sal) over(partition by e.deptno) as max_sal
,avg(e.sal) over(partition by e.deptno) as avg_sal
,sum(e.sal) over(partition by e.deptno) as sum_sal
,count(e.sal) over(partition by e.deptno) as count_sal
from emp e;
-- 用分析函数 来解决以前讲过的问题
select e.*
,avg(e.sal) over(partition by e.deptno) as avg_sal
from emp e;
-- 分组的情况下 并且排序
-- 加了order by 表示累计的意思
select e.empno,e.deptno,e.sal
,min(e.sal) over(partition by e.deptno order by e.sal) as min_sal
,max(e.sal) over(partition by e.deptno order by e.sal) as max_sal
,avg(e.sal) over(partition by e.deptno order by e.sal) as avg_sal
,sum(e.sal) over(partition by e.deptno order by e.sal) as sum_sal -- 累计求和 工作中会用到
,count(e.sal) over(partition by e.deptno order by e.sal) as count_sal
from emp e;
-- 排序字段有重复数据的时候会出现问题 再多加一个没有重复数据的字段排序
select e.empno,e.deptno,e.sal
,sum(e.sal) over(partition by e.deptno order by e.sal,e.empno) as sum_sal -- 累计求和 工作中会用到
from emp e;
-- 排序分析函数 只是排序 不是针对某个字段分析
select e.empno,e.deptno,e.sal
,row_number() over(order by e.sal desc) as rn1 --有重复数据的时候 随机排序
,rank() over(order by e.sal desc) as rn2 --有重复数据的时候 相同的数据排一起 跳过
,dense_rank() over(order by e.sal desc) as rn3 --有重复数据的时候 相同的数据排一起 不跳过
from emp e;
-- 没有重复数据的时候 三个函数是没有区别
select e.empno,e.deptno,e.sal
,row_number() over(partition by e.deptno order by e.sal desc) as rn1
,rank() over(partition by e.deptno order by e.sal desc) as rn2
,dense_rank() over(partition by e.deptno order by e.sal desc) as rn3
from emp e;
-- 求百分比
select e.empno,e.deptno,e.sal
,ratio_to_report(e.sal) over(partition by e.deptno) as rtr
from emp e;
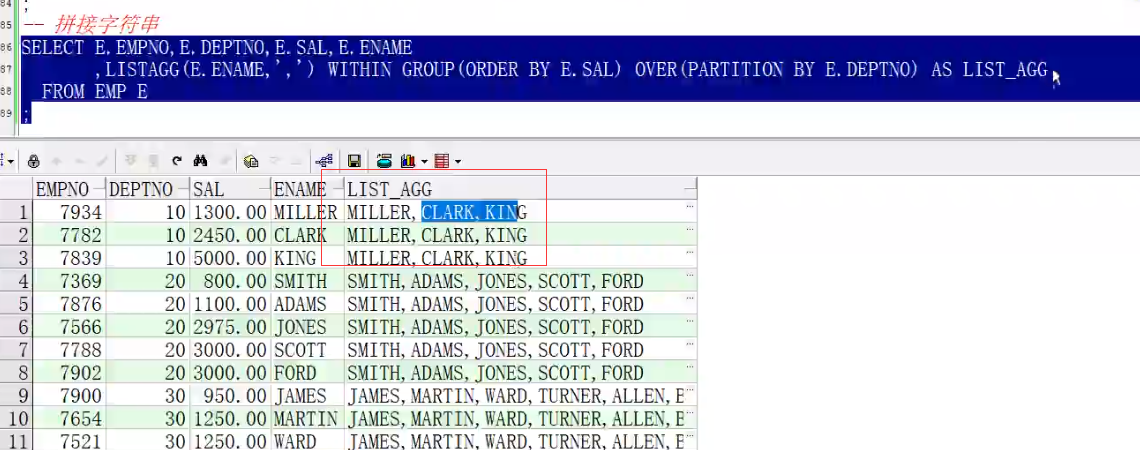
-- 拼接字符串
select e.empno,e.deptno,e.sal,e.ename
,listagg(e.ename,',') within group(order by e.sal) over(partition by e.deptno) as list_agg
,listagg(e.ename) within group(order by e.sal) over(partition by e.deptno) as list_agg
from emp e

21、列转行
------------- 建表 --------
drop table score_line;
drop table score_col;
create table score_line(
sname varchar2(20)
,subject varchar2(20)
,score number(3)
);
create table score_col(
sname varchar2(20)
,yuwen number
,shuxue number
,yingyu number
);
----------- 插数 ------
insert into score_line (sname, subject, score) values ('小明', '英语', 20);
insert into score_line (sname, subject, score) values ('唐斌', '语文', 76);
insert into score_line (sname, subject, score) values ('林艇', '语文', 90);
insert into score_line (sname, subject, score) values ('唐斌', '数学', 94);
insert into score_line (sname, subject, score) values ('林艇', '数学', 59);
insert into score_line (sname, subject, score) values ('唐斌', '英语', 15);
insert into score_line (sname, subject, score) values ('林艇', '英语', 88);
insert into score_col (sname, yuwen, shuxue, yingyu) values ('唐斌', 76, 94, 15);
insert into score_col (sname, yuwen, shuxue, yingyu) values ('小明', null, 0, 20);
insert into score_col (sname, yuwen, shuxue, yingyu) values ('林艇', 90, 59, 88);
commit;
-- 列转行
-- 方法1 union all
select s.sname,'语文' as subject,s.yuwen as score from score_col s;
select s.sname,'数学' as subject,s.shuxue as score from score_col s;
select s.sname,'英语' as subject,s.yingyu as score from score_col s;
select s.sname,'语文' as subject,s.yuwen as score from score_col s
union all
select s.sname,'数学' as subject,s.shuxue as score from score_col s
union all
select s.sname,'英语' as subject,s.yingyu as score from score_col s;
select * from score_col;
--方法2 oracle 自带的 列转行 函数
select sname,subject,score
from score_col
unpivot ( score for subject in(yuwen,shuxue,yingyu) );
-- 字段名 自己可以随便命名
select sname,bbb,aaa
from score_col
unpivot ( aaa for bbb in(yuwen,shuxue,yingyu) );
-- 这么把 科目里面的值改成中文 相当于给字段给个别名再写入
select sname,subject,score
from score_col
unpivot ( score for subject in(yuwen as '语文',shuxue as '数学',yingyu as '英语') );
22、行转列
-- 行转列
-- 行转列 工作中应用更多
-- 方法1 关联
select s.sname,s.score from score_line s where s.subject = '语文';
select s.sname,s.score from score_line s where s.subject = '数学';
select s.sname,s.score from score_line s where s.subject = '英语';
-- 小明不见了
select a.sname
,a.score as yuwen
,b.score as shuxue
,c.score as yingyu
from (select s.sname,s.score from score_line s where s.subject = '语文') a
,(select s.sname,s.score from score_line s where s.subject = '数学') b
,(select s.sname,s.score from score_line s where s.subject = '英语') c
where a.sname = b.sname
and a.sname = c.sname;
-- 先把名字取出来 去重
select d.sname
,nvl(a.score,0) as yuwen
,nvl(b.score,0) as shuxue
,nvl(c.score,0) as yingyu
from (select distinct(sname) from score_line) d
,(select s.sname,s.score from score_line s where s.subject = '语文') a
,(select s.sname,s.score from score_line s where s.subject = '数学') b
,(select s.sname,s.score from score_line s where s.subject = '英语') c
where d.sname = a.sname(+)
and d.sname = b.sname(+)
and d.sname = c.sname(+);
-- 优化代码 oracle特有写法
select d.sname
,nvl(a.score,0) as yuwen
,nvl(b.score,0) as shuxue
,nvl(c.score,0) as yingyu
from (select distinct(sname) from score_line) d
,score_line a
,score_line b
,score_line c
where d.sname = a.sname(+)
and d.sname = b.sname(+)
and d.sname = c.sname(+)
and a.subject(+) = '语文'
and b.subject(+) = '数学'
and c.subject(+) = '英语';
-- 优化代码 通用写法
select d.sname
,nvl(a.score,0) as yuwen
,nvl(b.score,0) as shuxue
,nvl(c.score,0) as yingyu
from (select distinct(sname) from score_line) d
left join score_line a on d.sname = a.sname and a.subject = '语文'
left join score_line b on d.sname = b.sname and b.subject = '数学'
left join score_line c on d.sname = c.sname and c.subject = '英语';
-- 方法2 decode
-- 先把数据拆成3部分
select s.sname
,s.subject
,decode(s.subject,'语文',s.score,0) as yuwen
,decode(s.subject,'数学',s.score,0) as shuxue
,decode(s.subject,'英语',s.score,0) as yingyu
from score_line s;
-- 按照名字去聚合 求最大或者求和
with tmp
as (
select s.sname
,s.subject
,decode(s.subject,'语文',s.score,0) as yuwen
,decode(s.subject,'数学',s.score,0) as shuxue
,decode(s.subject,'英语',s.score,0) as yingyu
from score_line s
)
select t.sname
,max(yuwen) as yuwen
,max(shuxue) as shuxue
,max(yingyu) as yingyu
from tmp t
group by t.sname;
-- 优化代码 简化代码
select s.sname
,sum(decode(s.subject,'语文',s.score,0)) as yuwen
,sum(decode(s.subject,'数学',s.score,0)) as shuxue
,sum(decode(s.subject,'英语',s.score,0)) as yingyu
from score_line s
group by s.sname;
-- 方法3 case when
select s.sname
,sum(case when s.subject = '语文' then s.score else 0 end ) as yuwen
,sum(case when s.subject = '数学' then s.score else 0 end ) as shuxue
,sum(case when s.subject = '英语' then s.score else 0 end ) as yingyu
from score_line s
group by s.sname;
-- 方法4 oracle 自带的 行转列 函数
select *
from score_line
pivot ( sum(score) for subject in('语文' as yuwen,'数学' as shuxue,'英语' as yingyu) );

若有收获,就点个赞吧
0 人点赞
