关于最小二乘法(LS)和交替最小二乘法(ALS)可以参考博客:https://blog.csdn.net/qq_37142346/article/details/80472088
交替最小二乘法(ALS)是统计分析中最常用的逼近计算的一种算法,其交替计算结果使得最终结果尽可能地逼近真实结果。而ALS的基础是最小二乘法(LS算法),LS算法是一种常用的机器学习算法,它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便的求得未知的数据,并使得这些求得的数据与实际数据之间误差的平法和为最小。
最小二乘法思想:对损失函数求偏导,然后再使偏导为0。
Rui:实际评分 mu:平均评分 bi:电影评分的偏置值 lamda1:正则参数 |Ru|:用户有过的评分数量

Rui:实际评分 mu:平均评分 bu:用户给出评分的偏置值 lamda2:正则参数 |Ri|:物品收到的评分数量
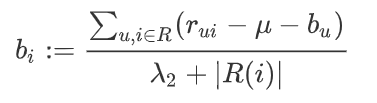
bu和bi分别属于用户和物品的偏置,因此他们从正则参数可以分别设置两个独立的参数。
通过最小二乘推导,我们最终分别得到了bu和bi的表达式,但他们的表达式中却又各自包含对方,因此这里我们将利用一种叫交替最小二乘的方法来计算他们的值:
- 计算其中一项,先固定其他未知参数,即看作其他未知参数为已知
- 如求bu时,将bi看作是已知;求bi时,将bu看作是已知;如此反复交替,不断更新二者的值,求得最终的结果。这就是交替最小二乘法(ALS)
实验数据:链接:https://pan.baidu.com/s/1n76-KsNs1cvgIcyV4YI3Rg 提取码:1314
import pandas as pdimport numpy as npclass BaseLine(object):def __init__(self, number, reg_bu, reg_bi, columns=None):"""初始化最高迭代次数、正则参数等:param number::param reg_bu::param reg_bi::param columns:"""if columns is None:columns = ["uid", "iid", "rating"]self.number = numberself.reg_bu = reg_buself.reg_bi = reg_biself.columns = columnsself.dataset = Noneself.users_rating = Noneself.items_rating = Noneself.global_mean = Noneself.bu = Noneself.bi = Nonedef fit(self, dataset):""":param dataset::return:"""self.dataset = dataset# 用groupby进行‘行分组’,agg进行列的组合self.users_rating = dataset.groupby('userId').agg([list]) # 用户评分数据self.items_rating = dataset.groupby('movieId').agg([list]) # 物品评分数据self.global_mean = dataset['rating'].mean() # 全局平均分self.bu, self.bi = self.als()def als(self):"""利用交替最小二乘法优化BaseLine损失:return:bu, bi"""# 初始化bu、bi的值,设为0bu = dict(zip(self.users_rating.index, np.zeros(len(self.users_rating))))bi = dict(zip(self.items_rating.index, np.zeros(len(self.items_rating))))print('进行 %d 次迭代以优化BaseLine损失' % self.number)for i in range(self.number):print("iter%d" % i)# 不可以使用index=False消除索引# 会报错ValueError: not enough values to unpack (expected 3, got 2)for iid, uids, ratings in self.items_rating.itertuples(index=True):_sum = 0for uid, rating in zip(uids, ratings):_sum += rating - self.global_mean - bu[uid]bi[iid] = _sum / (self.reg_bi + len(uids))for uid, iids, ratings in self.users_rating.itertuples(index=True):_sum = 0for iid, rating in zip(iids, ratings):_sum += rating - self.global_mean - bi[iid]bu[uid] = _sum / (self.reg_bu + len(iids))return bu, bi# 预测评分def predict(self, uid, iid):predict_rating = self.global_mean + self.bu[uid] + self.bi[iid]return predict_ratingif __name__ == '__main__':# 数据加载dtype = [("userId", np.int32), ("movieId", np.int32), ("rating", np.float32)]dataset = pd.read_csv("data/ratings.csv", usecols=range(3), dtype=dict(dtype))bsl = BaseLine(20, 25, 15, ["userId", "movieId", "rating"])bsl.fit(dataset)print('Predict_Score: %f' % bsl.predict(1,1))

若有收获,就点个赞吧
0 人点赞
