个性化推荐算法主要分为五类:
1、基于内容的推荐(Content-based Recommendation)
2、基于协同过滤的推荐(Collaborative Filtering-based Recommendation)
3、混合推荐(Collaborative Filtering Recommendations)
4、基于人口统计信息的推荐(Demographic-based Recommendation)
5、基于规则的推荐(Rule-based Recommendations)
基于内容的推荐
根据物品或内容的元数据,发现物品或内容的相关性,然后基于用户以前的喜好记录推荐给用户相似的物品。
步骤:
- 给物品贴标签(提取数据,计算权重)
- 利用标签的文字转换成词向量
- 利用词向量构建物品的向量
- 通过物品向量计算相似度
物品标签的来源:
- PGC 物品画像—冷启动
- 物品自带的属性(物品一产生就具备的):如标题、类型等
- 服务提供方设定的属性(服务提供商为物品附加的属性):如短视频话题、微博话题等
- 其他渠道:爬虫等
- UGC 冷启动问题
- 用户享受服务过程中提供的物品属性:如用户评论内容、用户拟定的话题等。
权重计算:tf-idf
- tf(Term Frequency) 词频 如5/100
- idf(Inverse Document Frequency) 逆文档频率 lg(文本库篇数/出现关键词的文章篇数)
- 具有代表性的标签要满足 tf高,idf低。即标签在当前文档出现频率高,在所有的文档中出现频率低。
- 由TF和IDF计算词语的权重:tf * idf。
用途:在目标文档中,提取关键词(特征标签)的方法就是将该文档所有词语的TF-IDPFi算出来并进行对比,取其TF-IDF值最大的k个数组成目标文档的特征向量用以表示文档。
如图所示: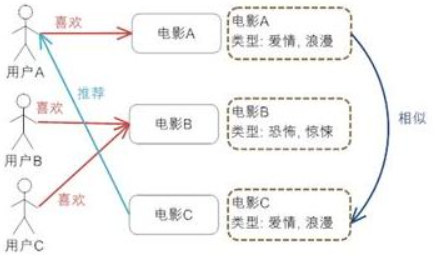
上图给出了基于内容推荐的一个典型的例子,电影推荐系统。
首先我们需要对电影的元数据有一个建模;然后通过电影的元数据发现电影间的相似度,因为类型都是 爱情,浪漫 电影 A 和 C 被认为是相似的电影(当然,只根据类型是不够的,要得到更好的推荐,我们还可以考虑电影的导演,演员等等);最后实现推荐,对于用户 A,他喜欢看电影 A,那么系统就可以给他推荐类似的电影 C。
基于内容推荐的算法流程:
- 根据PGC/UGC内容构建物品画像
- 根据用户行为记录生成用户画像
- 根据用户画像从物品中寻找最匹配的TOP-N物品进行推荐
基于协同过滤的推荐
此推荐分为三类:
(1)基于用户的协同过滤推荐(User-based Collaborative Filtering Recommendation)
基于用户的协同过滤推荐算法先使用统计技术寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的喜好产生向目标用户的推荐。基本原理就是利用用户访问行为的相似性来互相推荐用户可能感兴趣的资源。
(2)基于项目的协同过滤推荐(Item-based Collaborative Filtering Recommendation)
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户。
(3)基于模型的协同过滤推荐(Model-based Collaborative Filtering Recommendation)
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
总结
基于协同过滤的推荐,使用的是系统记录的用户行为,它用消费过物品的用户来表征物品,计算相似。相比基于内容的一般效果较好,因为本质是基于共现,能发掘物品某种层次上的相似关系,这种关系很难从内容维度刻画;但有冷启动问题,因为一个物品如果没有用户消费过,就无法表征它,它也不会被推荐出来。这篇文章里提到了很多协同过滤算法,可以进一步一探究竟。
基于内容的推荐,依靠的是内容本身的相似性,比如把文本进行词袋表征,变成k维的向量,可以i算物品的相似度。由于基于物品本身的文本或图像特征,没有冷启动问题,但是一般效果较差,因为很难在内容特征中提取用户偏好级别的内容相似性,实践中会发现,你觉得计算出来的物品相似非常好,但是线上效果却很差。
混合推荐系统,会融合协同和内容本身的信息去做推荐,提升效果,减缓冷启动问题。
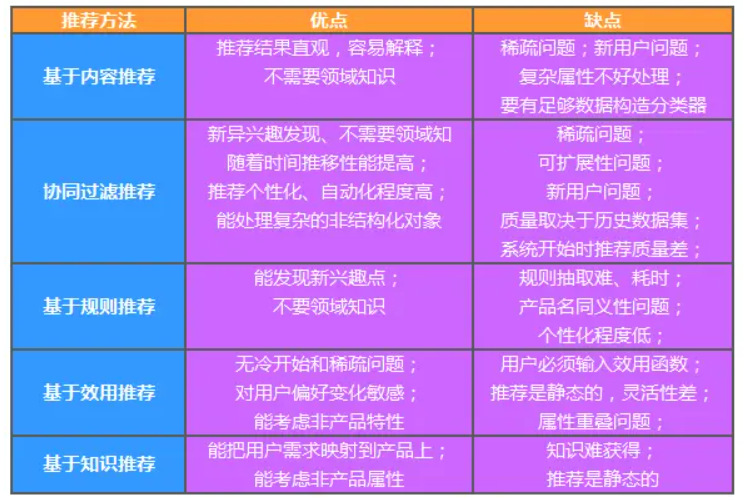
附推荐算法优缺点总略图:

若有收获,就点个赞吧
0 人点赞
