1、你们的项目中使用的设计模式有哪些?/你了解设计模式,项目具体怎么用?
回答:用到了哪些设计模式;设计模式是什么,解决什么问题的;怎么用;
1.1、构建者模式(Builder)
是什么:基于 lombok插件实现 @Builder;
解决的问题:可快速构建一个对象,避免大量的setter,提高代码开发效率;
如何使用:ResponseWrapBuild : 构建者模式的实现体现
/*** @Description 构造ResponseWrap工具*/public class ResponseWrapBuild {public static <T>ResponseWrap<T> build(IBasicEnum basicEnumIntface, T t){//从UserVoContext中拿到userVoStringString userVoString = UserVoContext.getUserVoString();UserVo userVo = null;if (!EmptyUtil.isNullOrEmpty(userVoString)){userVo = JSONObject.parseObject(userVoString, UserVo.class);}else {userVo = new UserVo();}//构建对象return ResponseWrap.<T>builder().code(basicEnumIntface.getCode()).msg(basicEnumIntface.getMsg()).operationTime(new Date()).userId(userVo.getId()).userName(userVo.getUsername()).datas(t).build();}}
1.2、工厂模式(Factory):
基于类的全路径生成对应的实现对象,我们现在项目中基于Spring IOC容器完成
1.3、适配器模式(Adapter):
解决不同实现类不能兼容在一起工作的问题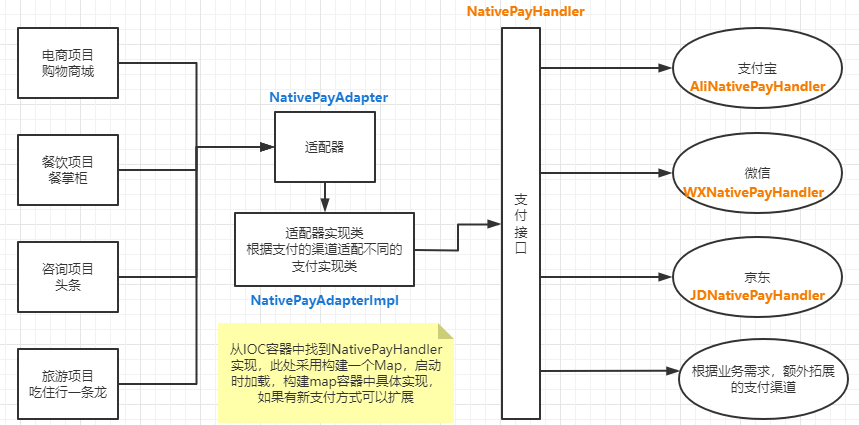
适配器设计模式:使接口不兼容的类可以一起工作,我们在项目中使用适配器设计的思想,根据支付渠道适配不同的支付实现类,如支付渠道为支付宝时,我们就匹配支付宝的支付服务实现类,若为微信,则适配微信支付。
解决了不同支付实现类兼容的问题,并且提高了代码的可拓展性和维护性,后期如果有业务需求需新增支付渠道,我们只需在IOC容器中构建的Map添加对应的键值对,并按照三方接口添加对应的配置类及业务代码实现即可。
1.4、策略模式(Strategy)
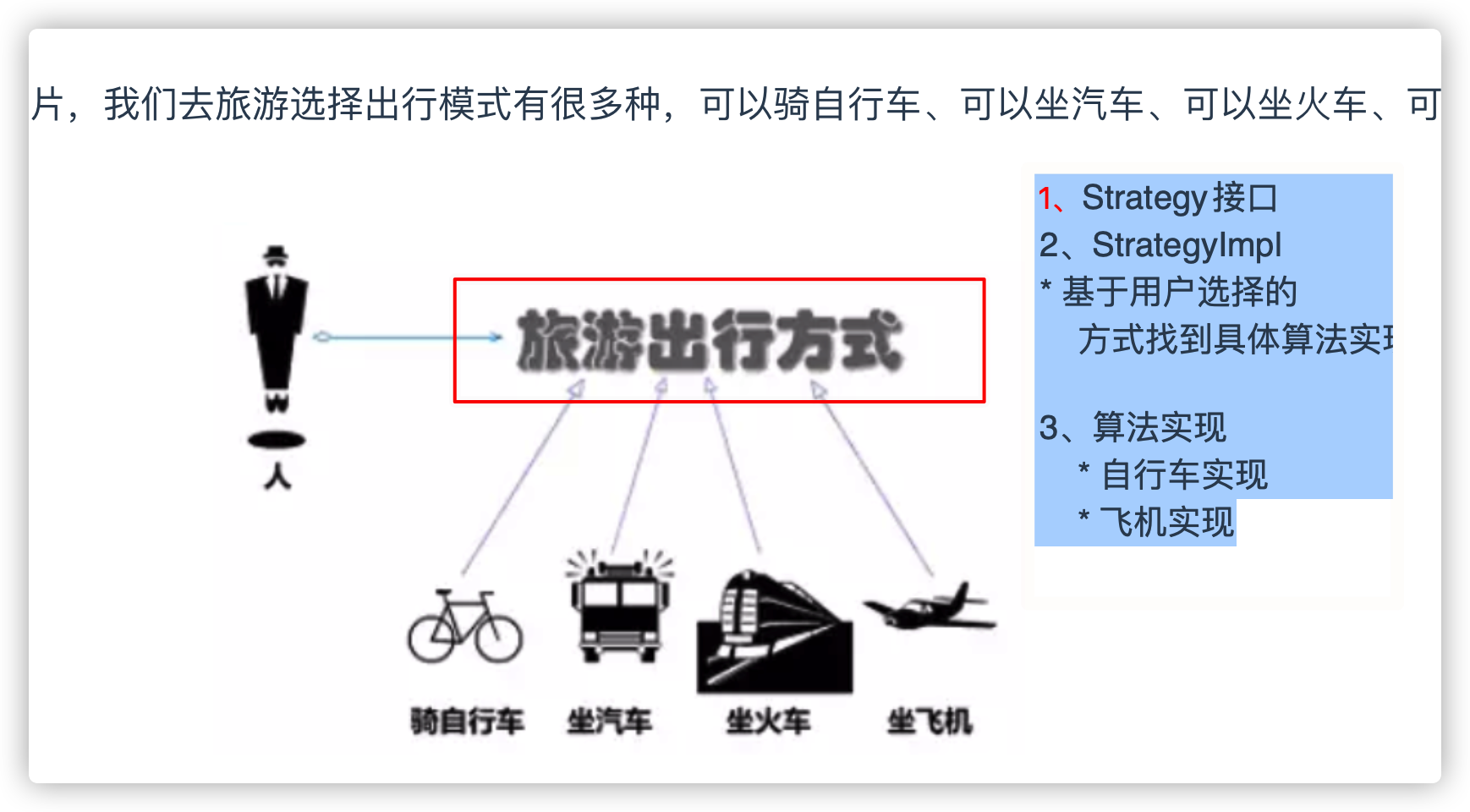
解决了:
1、if/else 过多的问题
2、代码扩展性, 满足开闭原则(对新增开放,对修改关闭)
1.5设计模式优缺点:
缺点:
1、代码结构复杂度变高
2、耗费内存也会变高
优点:
1、代码扩展性
2、代码结构清晰,可维护增强
3、解耦项目的业务
2、你们项目中你印象最深的一个问题是什么? 项目遇到了什么样bug?
- 双写一致性:时刻保证 mysql和redis库存一致
在项目中,我们采用预扣方案解决商品超卖问题,我们将商品的库存数据使用redisson的atomiclong缓存到redis中做预扣,再同步更新mysql中的商品库存(atomiclong可保持数据的++i,—i操作的原子性)
具体实现步骤:
1、先将所有的菜品对应的库存保存到Redis, AtomicLong(key:dishId, vlaue:num)—>在并发情况下,保持数据++i,—i操作的原子性,使得数据保持一致性
2、更改数据库的库存之前,先去在redis 预扣
3、判断 redis中库存 >=0 库存足,可以扣减数据库库存, <0 库存不足,终止当前请求
(四)小结
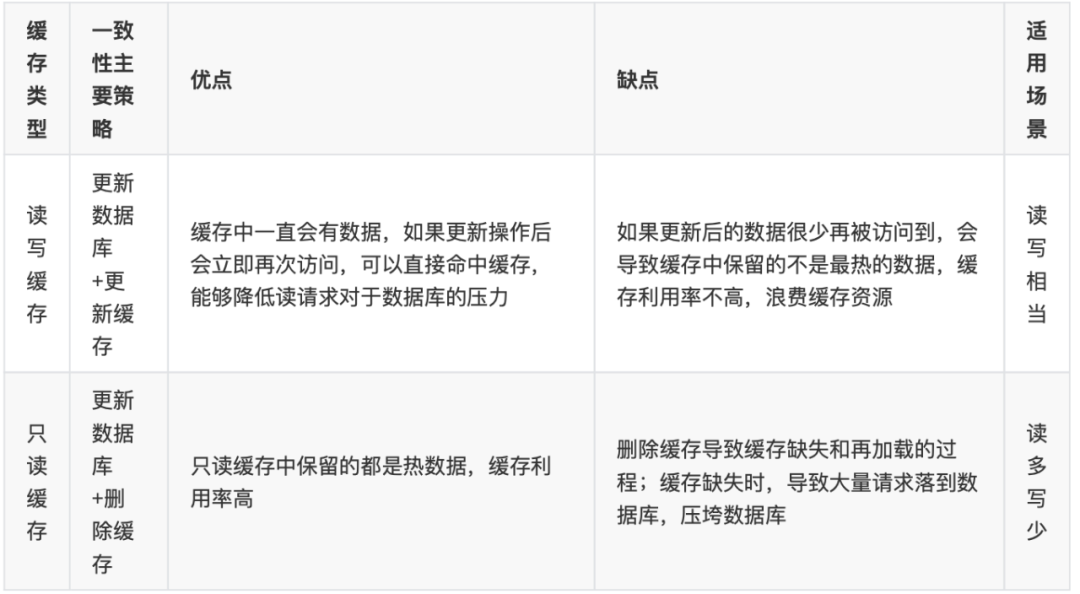
针对读写缓存时:同步直写,更新数据库+更新缓存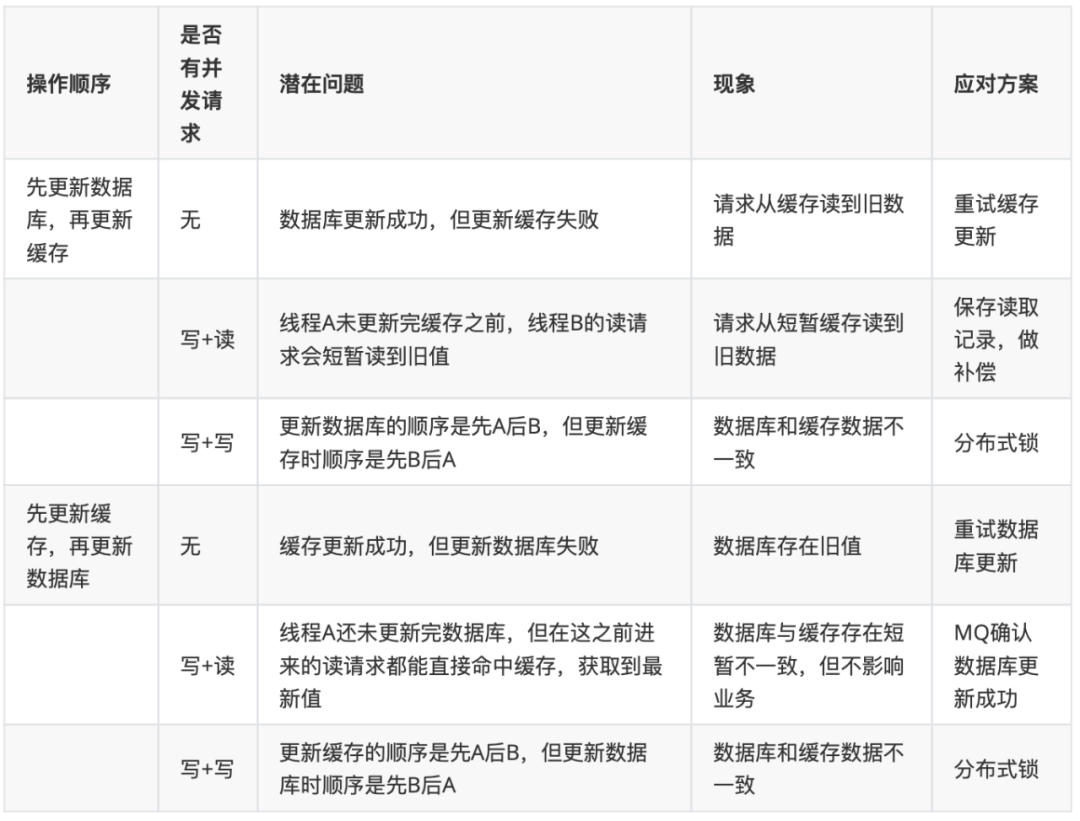
针对只读缓存时:更新数据库+删除缓存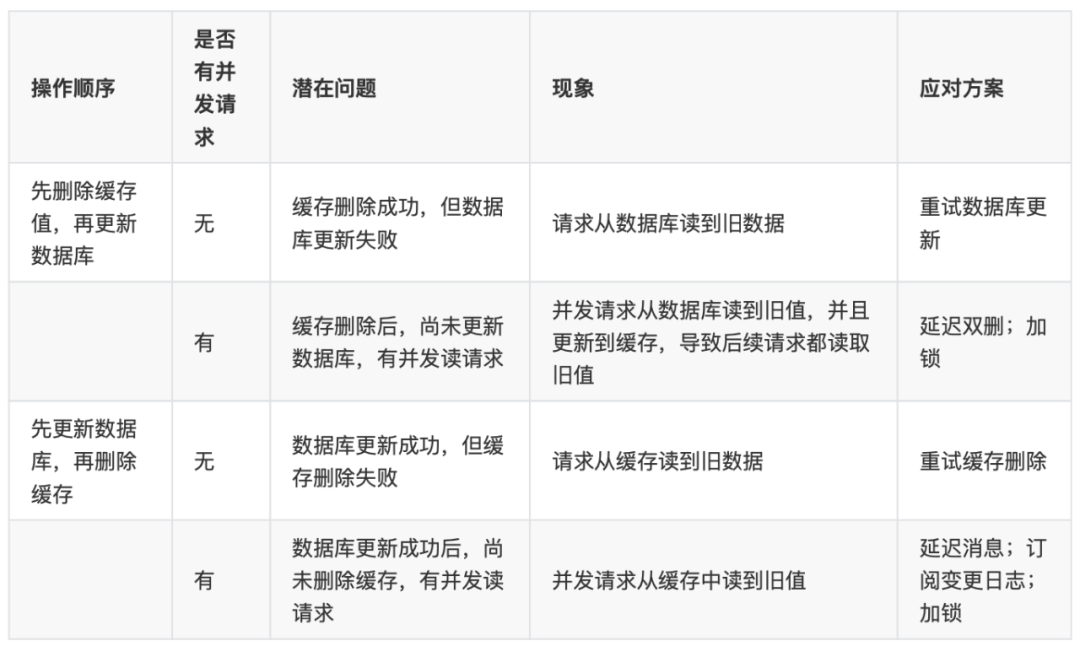
较为通用的一致性策略拟定:
在并发场景下,使用“更新数据库+更新缓存”需要用分布式锁保证缓存和数据一致性,且可能存在“缓存资源浪费”和“机器性能浪费”的情况;一般推荐使用“更新数据库+删除缓存”的方案。如果根据需要,热点数据较多,可以使用“更新数据库+更新缓存”策略。
在“更新数据库+删除缓存”的方案中,推荐使用推荐用“先更新数据库,再删除缓存”策略,因为先删除缓存可能会导致大量请求落到数据库,而且延迟双删的时间很难评估。
在“先更新数据库,再删除缓存”策略中,可以使用“消息队列+重试机制”的方案保证缓存的删除。并通过“订阅binlog”进行缓存比对,加上一层保障。
此外,需要通过初始化缓存预热、多数据源触发、延迟消息比对等策略进行辅助和补偿。【多种数据更新触发源:定时任务扫描,业务系统MQ、binlog变更MQ,相互之间作为互补来保证数据不会漏更新】
三、数据不一致性需注意其他问题
(二)避免其他问题导致缓存服务器崩溃,进而简直导致数据一致性策略失效缓存穿透、缓存击穿、缓存雪崩、机器故障等问题

参考链接:
https://blog.csdn.net/yulidrff/article/details/86296714
https://mp.weixin.qq.com/s/LqWiwzr1jdX0N9tAxw9gMQ
3、你们项目中哪些地方涉及到了分布式事务的问题?
1、问题的背景(项目调用链路)
2、解决方案
3、工作原理
4、注意事项
3.1涉及分布式事务的模块及功能:
1、品牌管理:涉及品牌表、附件表,需调用了品牌管理服务、附件上传服务
2、用户管理:涉及用户表、角色表、附件表,需调用了用户管理服务、角色管理服务、附件上传服务
3、菜品管理:涉及菜品表、口味表,需调用菜品管理服务、数据字典查询口味字段
4、开桌操作:涉及桌台表、订单表,需调用桌台管理服务、订单管理服务
5、库存管理:涉及菜品表、订单表、附件表,增删改时会调用菜品管理服务、订单管理服务、附件上传服务
6、购物车管理:涉及菜品表、订单表、附件表,增删改时会调用菜品管理服务、订单管理服务、附件上传服务
3.2解决方案:
3.3工作原理:
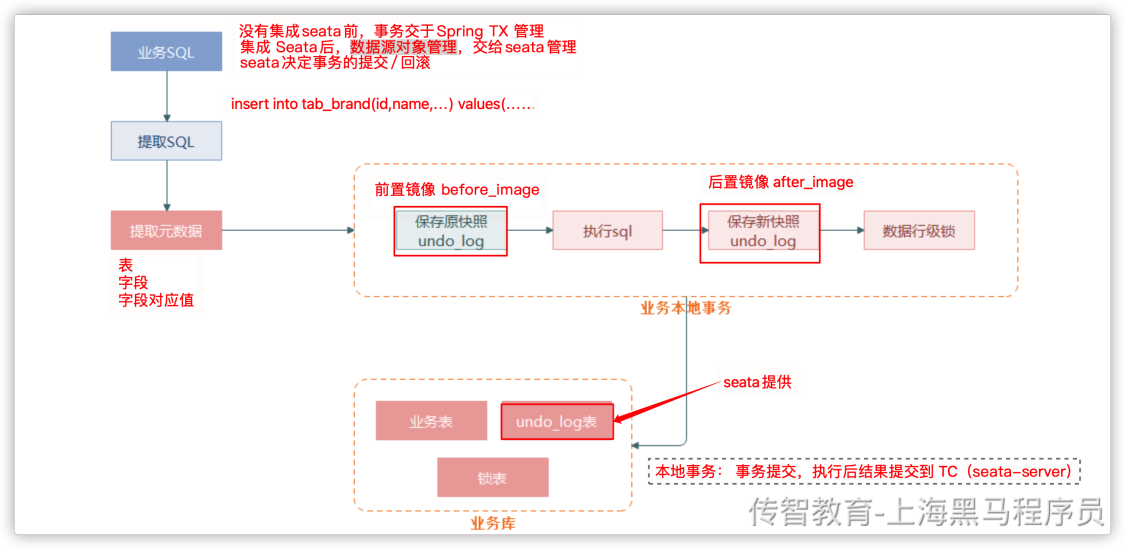
使用前提: 1. 数据库必须是支持事务的关系型数据库
2. 必须是java项目,并且用JDBC去访问数据库
@GlobalTransactional 标记的方法说明开启了全局事务,seata会为该方法准备一个拦截器
当该方法被调用时,拦截器中 会向TC端 注册一个全局事务信息(xid)
注册好全局事务后,开始执行每个分支事务:
整体流程分为两个阶段;
1. 执行 每一个分支事务
seata为datasource创建了代理对象,每个服务中操作数据库的方法执行时会创建分支事务
执行分支事务时:
seata会先解析要执行的sql语句 生成前置镜像 ==> 执行sql ==> 生成后置镜像 ,将镜像内容存入undolog日志中, 分支事务执行完毕
2. 根据第一阶段结果,提交 或 回滚
如果所有的分支事务都执行成功, 说明全局事务成功,异步的删除undolog日志即可
如果有任何一个环节失败, 根据undolog日志进行事务回滚
回滚时: 会判断当前数据内容和后置镜像是否一致,一致回滚;不一致,就一直重试
3.4注意事项:
seata 会出现脏读问题:
默认 会出现脏读,因为每个分支事务 真实提交了数据库的事务
如果不想出现脏读,可以在select语句后加上for update,
seata重写了语法解析, 会通过判断全局锁的方式 将隔离级别提升为 读已提交
—> 性能不好
seata 不会出现脏写问题:
不会,虽然有脏读,但如果另一个事务拿到脏数据想修改,还是需要获取全局锁才可以

若有收获,就点个赞吧
0 人点赞
