1、Sharding-JDBC
Sharding-JDBC是ShardingSphere的一个模块,定位为“轻量级Java框架”,在java的JDBC层提供额外的服务。
解决:海量数据储存的问题,原则上当单表数据达到百万级别,大小为2GB时就要考虑分库分表;
原理:Sharding-JDBC的核心功能为数据分片和读写分离
2、分库分表方式
2.1垂直分表:
将一个表按照字段分成多表,每个表存储其中一部分字段
它带来的提升是:
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
- 改变了数据库的表结构,对数据存储的行数没有影响
垂直拆分原则:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
2.2垂直分库
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
它带来的提升是:
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
垂直分表、垂直分库在项目设计的初始阶段就已经考虑到了,但它们均未能解决单表数据量过大的问题!
2.3水平分库
是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
它带来的提升是:
- 解决了单库单表大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性
2.4水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
它带来的提升是:
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
水平分库和水平分表的分片键不能是同一个,否则会造成数据倾斜,如在分库时id%2奇偶,再分表时再id%2,未能达到分表的效果!
3、分库分表带来的问题有哪些?
- 事务一致性问题
- 跨节点关联查询
- 跨节点分页、排序函数、聚合函数
- 主键避重
- 公共表
4、分库分表的最佳实践?
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
5、sharding-jdbc架构
5.1名词解释
逻辑表(LogicTable):进行水平拆分的时候同一类型(逻辑、数据结构相同)的表的总称。例:用户数据根据主键尾数拆分为2张表,分别是tab_user_0到tab_user_1,他们的逻辑表名为tab_user。
真实表(ActualTable):在分片的数据库中真实存在的物理表。即上个示例中的tab_user_0到tab_user_1。
广播表(公共表):指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
绑定表(BindingTable):指E。例如:t_order表和t_order_item表,均按照order_no分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
分片键(ShardingColumn):分片字段用于将数据库(表)水平拆分的字段,支持单字段及多字段分片。例如上例中的order_id。
5.2执行原理
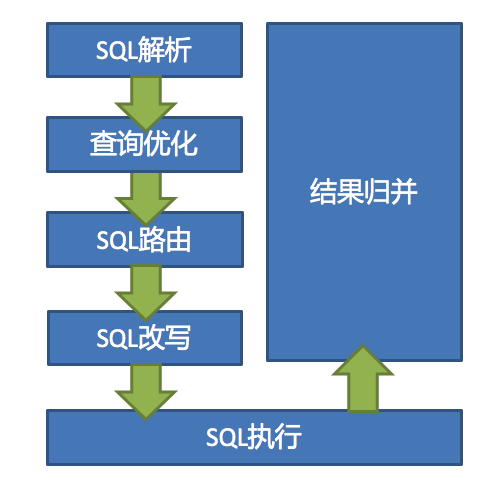
- sql解析:通过解析sql语句提取分片键列与值进行分片,例如比较符 =、in 、between and,及查询的表等。
- 执行器优化:合并和优化分片条件,如OR等。
- sql路由:找到sql需要去哪个库、哪个表执行语句,上例sql根据采用的策略可以得到将在ds0库,t_user_0表执行语句。
- sql改写:根据解析结果,及采用的分片逻辑改写sql,SQL改写分为正确性改写和优化改写。
- sql执行:通过多线程执行器异步执行。
- 结果归并:将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
5.3注意事项
在使用sharding-jdbc中,需导入相应的依赖,并且有以下注意点:
1、sharding-JDBC 必须使用原生的druid,排除druid-spring-boot-starter;
2、seata的分布式处理模式XA和AT不能共存,使用一个必须把另外一个排除;
<!--sharding-JDBC 必须使用原生的druid,排除druid-spring-boot-starter--><dependency><groupId>com.itheima.restkeeper</groupId><artifactId>model-shop-service</artifactId><exclusions><exclusion><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId></exclusion></exclusions></dependency><!--使用XA事务,则必须移除seata-at依赖--><dependency><groupId>com.itheima.restkeeper</groupId><artifactId>framework-sharding-jdbc</artifactId><exclusions><exclusion><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-base-seata-at</artifactId></exclusion></exclusions>
#数据源配置shardingsphere:datasource:names: ds0,ds1ds0:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.200.129:3306/restkeeper-shop-0?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8username: rootpassword: passds1:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.200.151:3306/restkeeper-shop-1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8username: rootpassword: root#分库分表sharding:tables:tab_order: #数据库中要分表的逻辑名actualDataNodes: ds${0..1}.tab_order_${0..1}databaseStrategy:inline:shardingColumn: sharding_idalgorithmExpression: ds${sharding_id % 2}tableStrategy:inline:shardingColumn: order_noalgorithmExpression: tab_order_${order_no % 2}keyGenerator:type: SNOWFLAKEcolumn: idtab_order_item: #数据库中要分表的逻辑名actualDataNodes: ds${0..1}.tab_order_item_${0..1}databaseStrategy:inline:shardingColumn: sharding_idalgorithmExpression: ds${sharding_id % 2}tableStrategy:inline:shardingColumn: product_order_noalgorithmExpression: tab_order_item_${product_order_no % 2}keyGenerator:type: SNOWFLAKEcolumn: idbinding-tables:- tab_order- tab_order_itembroadcast-tables:- tab_brand- tab_category- tab_dish- tab_dish_flavor- tab_printer- tab_printer_dish- tab_store- tab_table- tab_table_area- undo_logdefault-key-generator:type: SNOWFLAKEcolumn: idprops:sql.show: true

若有收获,就点个赞吧
0 人点赞
