MySQL 订单数据同步 ES
!!!markdown 格式的文件上传到语雀排版会有一些错误,更好的阅读体验请跳转到 github 查看 MySql 订单数据同步 ES .md
一. 需求分析
- 数据同步速度在满足业务需求情况下要尽可能快
- MySQL 中 order 表所有更新都要同步 ES
- ES 只保存最新的 MySql 数据
- 出现问题能轻松排查
二. 主流方案调研评估
现在主流的同步脚本有两种方案
1. 基于 MySQL 的 binary log 增量更新
应用程序模拟 MySQL replication 协议,向 Mysql master 发送 dump 协议,接收 master 的 binary log ,解析 binary log 对象后发送给日志消费者,消费者拿到变更的信息处理后写入 ES。目前主流实现 MySQL replication 协议和 binlog 解析的开源库
- canal (18K start | 567 issues) https://github.com/alibaba/canal
阿里开源的 MySQL 数据库增量日志解析,使用 Java 开发,相关组件比较多,比如简单的ES同步等,但多为 Java 开发。但特别设计了 client-server 模式,提供多语言客户端。
架构如下

- python-mysql-replication (1.8K start | 55 issues) https://github.com/noplay/python-mysql-replication
基于 PyMYSQL,纯 python 实现的MySQL replication 协议和 binlog 解析。 - go-mysql-elasticsearch (3.4K start | 186 issues) https://github.com/siddontang/go-mysql-elasticsearch
纯 GO 语言实现的MySQL replication 协议和 binlog 解析,性能很优秀,但已经不维护,只支持简单业务,复杂业务需要基于源码自定义开发,且作者没在生产环境上使用过。
此方案优点:
- 业务对同步操作无感知
- 由于使用的是 MySql 副本订阅机制,同步延时很低,性能优秀。
此方案缺点:
- 需要 MySQL 设置 binlog-format = row (不过大部分云数据库都会开启这个选项)
- 几个开源库都不是很稳定,需要开发者通读开源库源码,有二次开发的能力,还需要了解 MySQL replication 相关协议(根据 go-mysql-elasticsearch 作者文章描述,相当复杂),知识储备要求高。
- canal 的高可用依赖于 ZooKeeper,一个Client作为工作Client,其余Client作为冷备,当工作Client挂掉时,冷备Client监听到ZooKeeper数据变化,抢占锁成为工作Client。需要引入新组件。
其他两个开源库则需要自己二次开发,当程序崩溃如何记录断点数据。
2. 基于 SQL 查询的增量更新
通过 SQL 语句查询出 MySql 增量变更的数据,处理后写入 ES。
优点:
- 实现简单,可自由定制开发
缺点:
- 需要改动业务或者数据库表,为了表示增量这个条件,需要设置一个类似 modify_time 的字段,这个字段在创建时最好设置了 ON UPDATE CURRENT_TIMESTAMP 在更新数据时自动更新时间戳。又或者业务上主动更新数据的 modify_time。
- 性能和实时性比较方案1较差,需要不断的循环查表,增加了数据库压力, 而且如果有业务忘记更新 modify_time 就无法增量同步到ES。
三. 本次开发方案
因为主流方案1 需要对 MySql 和 第三方库 细节特别熟悉,且对第三方库订制开发, 风险比较大。而我们在以前的业务已经有过使用 order 表 modify_time 来做增量更新的方案(保证了 order 表每一次数据变动都会更新 modify_time ),这次也能直接使用。综上所述,这次开发采取调研的方案 2。
四.详细设计
对需求分析中每一点的具体实现
数据同步速度在满足业务需求情况下要尽可能快
order 表是在内网,且 MySql 批量查询速度非常快,但是查询出来的批量数据需要对每一条做各种清洗格式化才能写入 ES。这中间就会导致查询 MySql 的速率 远快于 写入到 ES 的速率。
遇到进出速率有差距时,我们可以在进出之间加一个 队列 来提高速度。(进程内存队列)
把 Mysql 查询数据这个动作比做生产者,而 取数据清洗写入 ES 比做消费者。
目前情况是生产者速度远大于消费者,如果生产者等着消费者一条一条数据地同步,自然速率会自动降低为消费者的速度,此时使用队列就能大幅提高生产者的速度,在队列满之前都能让生产者全速工作。
但是如果队列满就会阻塞生产者生产数据,为了尽快消费队列中的数据,可以使用多进程增加消费者的数量。
(为什么不使用多线程?因为多线程只使用与 IO 速度慢的情况,但是内网的数据库 IO 其实相当快,单线程情况下就已经把单个 CPU 跑到接近百分百,使用多线程实验后也是单个 CPU 百分比,没有任何提升,所以使用多进程。)
使用流式查询和批量写入,以一个批次为一个单位进行同步,例如生产者每次查询250条数据包装为一个数组,插入队列中,占队列空间为1,消费者每次也取1个单位的数据(实际取了250条数据),代码层面,所有函数只针对批次做处理,不对一条一条数据做处理。MySQL 中 order 表所有更新都要同步到 ES
如果程序正常运行,那自然每一条 Mysql 中的更新数据都会同步到 ES 中,但是考虑到现代开发模式下不可靠因素太多了,数据,代码,系统,网络甚至人为的因素随时都有可能导致程序崩溃,所以我们要默认程序就是会崩溃的,只要在重启后能正常运行就好了。
那重启如何能正常恢复呢,这就需要在程序运行时保存一些上下文到外部,以供重启的时候读取。
在每一个脚本启动的时候,我们需要获取一个 MySql 中 order 表 modify_time 字段查询的开始时候和结束时间。
第一次启动时,我们查找数据库,是否有一个 next_start_from 字段,如果值为空,则 开始时间 设置为 当前时间前2分钟,结束时间 为 当前时间 ,意思是同步脚本启动时刻前2分钟的数据。
如果脚本正常运行完整个流程,则数据库中 next_start_from 字段值设置为结束时间,那么下一个启动就会就会读取到这个 next_start_from 字段,并从这里开始。
假设程序崩溃了,那 next_start_from 字段就不会更新,重启后获取的 next_start_from 和崩溃时刻运行的相同。
虽然这样做会导致程序恢复后同步的数据增多,如果一直崩溃带更新数据甚至可能多到永远跑不完。但是我们可以监控数据库中的 next_start_from 字段,只要它的值小于当前时间超过一定阈值就报警,超过阈值肯定是程序一直在崩溃,由开发者去处理。
解决完程序崩溃恢复的问题,那如果程序执行过程中发生异常,某几个订单意外同步失败了这么办,或者队列被意外清空?如果保证所有数据同步成功呢?
增加重试机制,每次数据进入队列前先写入 未同步数据表 (no_sync_data) ,消费者成功写入 ES 后到数据库删除。每次脚本启动前,先到 未同步数据表 查看是否有数据,有就先同步上一轮未同步的数据。
如果上一轮未同步数据一直失败,有可能导致一直在同步之前的数据时崩溃,导致本轮的数据也进入未同步数据库,恶性循环。所以需要给 未同步数据 增加重试次数,查询 未同步数据库 时要查询 重试次数 < 重试次数阈值的数据。 例如 重试阈值为2,那每条未同步数据就只能重试2次,重试次数大于2的数据 就不会从未同步数据库中筛选出来。
但是重试次数大于2的数据的数据并不能不管他,可以设置一个监控告警,如果有多条数据重试次数大于阈值,说明一直同步失败,需要开发人员介入。
这里解答一下 为什么使用进程内存队列,而不是使用 redis, rabbitmq 之类的外部消息队列?
因为我们要保证每一条数据都能同步到 ES ,那我们就要保证数据在每一个环节都不会丢失,如果使用了外部组件的队列,以下几方面是不可靠的。monitor = sync_monitor_conn.find_one(_filter)if monitor and monitor.get("next_start_from"):query_begin_time = monitor["next_start_from"]else:query_begin_time = query_end_time - timedelta(minutes=2)query_end_time = datetime.now()try:# 正常业务# 更新 next_start_from 字段sync_monitor_conn.update(_filter, {"$set": {"next_start_from": query_end_time}}, upsert=True)except Exception as e:# 错误处理
- 程序发送给外部队列的网络请求,随时都有可能失败,要增加重试机制。
- 外部队列崩溃重启 或者 队列数据清空情况下,要保证本地能重新推送。
- 外部队列因为其他程序导致阻塞,影响我们的同步程序。
- 外部队列发送异常不推送消息
以上只是我想到的情况,还有多种未考虑到情况,引入一个新的组件会给程序带来指数级别的复杂度。
所以在使用 python 自带的多进程内存队列 已经能满足性能要求的情况下,不引入其他组件能大大降低开发难度,提高程序稳定性。
但是在开发中还是需要把队列的入队出队代码抽象了一下,方便以后为了性能考虑直接换成第三方消息队列。
ES 只保存最新的 MySql 数据
因为消费者采用了多进程,多个消费者可能获取数据的不同版本,如何保证写入 ES 的是最新的版本呢?
下面举个例子, 例如
消费者1 获取了 modify_time 为 12:00:01 的数据1, 然后清洗,准备写入 es ,但是消费者1的网络有问题,导致写入 es 一直失败。
数据1 在 12:00:20 就行了数据变更,例如金额变多了。
消费者2 获取了 modify_time 为 12:00:20 的数据1, 然后清洗,准备写入 es ,网络正常,写入成功。
到12:00:59 时,消费者1 网络正常,正常传输写入 es 的请求。
此时如果让消费者1写入成功,则会让 12:00:01 时刻的数据1 覆盖 12:00:20 的数据1,显然不符合 只保存最新的 MySql 数据 这个要求,如何解决这个问题?
恰好 ES 提供了版本控制功能,可以在写入时带上版本字段,只有版本字段 version (int) 大于 ES 中原来数据的 version 时才能正常写入。我们可以将 modify_time 转换为时间戳,以这个时间戳作为版本,如果低于原来的版本就写入失败,这样就能保证老的数据不会覆盖新的数据。出现问题能轻松排查
这个比较简单,就是每次更新 next_start_from 时,顺便把程序那一轮运行中捕获到的的异常添加进一个列表,再写入到数据库中。
五. 流程图

六. 性能优化 - 按月份分索引
因为订单和订单详情表的数据非常巨大,订单表有 5kw 条数据,订单详情表是订单表的10倍左右,大概是 6亿 条数据。而业务中订单的查询通常是只能查询最近 1-3个月 数据,所以在写入 ES 阶段,我们能根据订单的下单时间按 月 来划分索引,每个月一个索引,这样在查询时指定1-3个月索引,能提高很多查询的性能。下面来看一张图,使用 order* (order 所有索引) 和 order_2021.09 (指定索引) 查询一个时间。下面几张图可以清晰看到他们的性能差距。
- 使用 order_*/_serach 无缓存查询
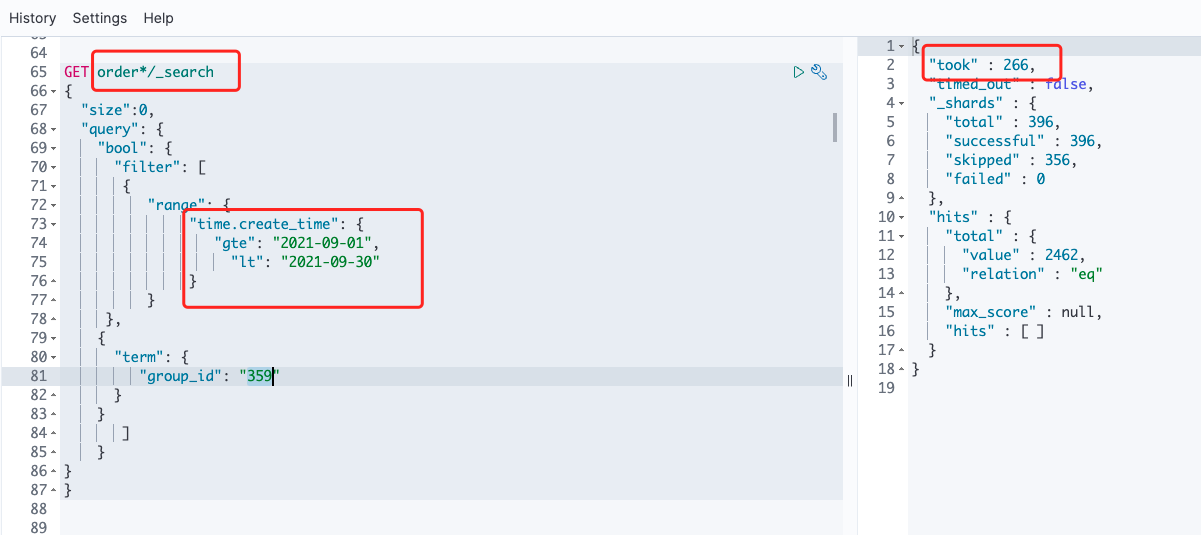
- 使用 order_*/_serach 有缓存查询

- 使用 order_2021.09 /_serach 无缓存查询,看起来好像和 order* 差不多

- 使用 order_2021.09 /_serach 有缓存查询, 是 order* 几十倍的速度,查询结果数据量越大速度差距越明显

如何在查询时挑选一个合适的索引?
观察业务代码的查询,发现几乎几乎所有查询都会携带时间相关字段,这是业务导致,而时间相关字段几乎都是以 _time 为后缀,却只有一个时间范围搜索。那只要提取到这个字段,就能根据这个字段值来选择索引了。编写一个函数,对 ES 查询语句进行深度搜索,找到第一个 _time 为后缀的键值对,根据不同时间字段选择不同的索引。例子如下
{"range": {"time.create_time": {"gte": "2021-09-01","lt": "2021-09-30"}}}因为我们是按下单时间 create_time来按月分索引的上面的语句时间相关字段是下单时间 create_time ,根据业务需求,那上面只需要选择 order_2021.09 这个索引即可如果是 customer.receive_time,则是按收货时间来查询,那收货时间在9月的订单可能是8月下单的,所以根据业务需求,选择 order_2021.08,order_2021.09 两个月的索引来查询

若有收获,就点个赞吧
0 人点赞
