MapReduce 的流程:
在hdfs 中会对文件进行文件的物理的切块, 分为block-0, block-1, block-2 …
在MapReduce 中又抽离一层逻辑切片 split0, split1, split2 …
切片的出现可以动态控制每次的数据大小。防止io密集型导致block 的过小和cpu密集型导致block过大
进入到Map 为 k, v 键值对的形式。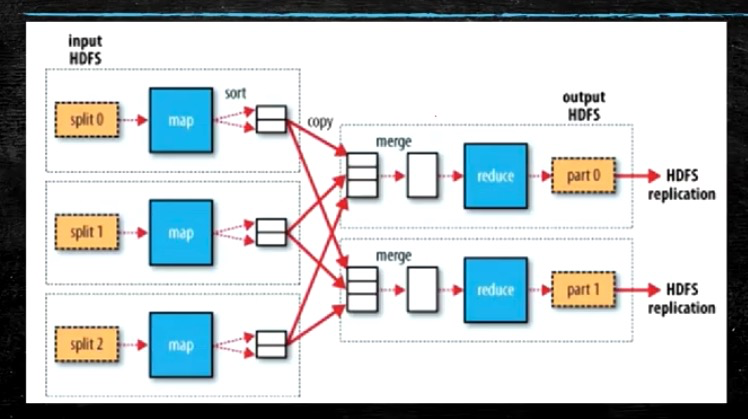

MP 的计算框架: 计算向数据移动
角色:
- JobTracker
- 资源管理
- 任务调度
- TaskTracker[与DN一一对应]
- 任务管理
- 资源汇报[心跳]
- client[客户端]
- 会根据每次的计算数据, 咨询NN 的元数据[block]->计算切片[split] -> 得到切片的清单,map 的数量就确定了。
- split是逻辑的, block 是物理的。block 身上有[offset, locations]. split 和block 有对应关系的。
- 结果: split 包含偏移量, 以及split对应的map 任务应该移动到哪些节点[locations]。
- client 会将jar, split清单,配置xml 上传到hdfs的目录中[上传的数据, 副本数10]。
- client 会调用JobTracker, 通知要启动一个计算程序了。并且告知文件都存放在什么地方。

若有收获,就点个赞吧
0 人点赞
