唤醒手腕Python爬虫学习笔记
1、基础语法知识点
字符串的分割
webString = 'www.baidu.com'print(webString.split('.'))# ['www', 'baidu', 'com']
字符串前后空格的处理,或者特殊字符的处理
webString = ' www.baidu.com 'print(webString.strip())# www.baidu.comwebString = '!*www.baidu.com*!'print(webString.strip('!*'))# www.baidu.com
字符串格式化
webString = '{}www.baidu.com'.format('https://')print(webString)# https://www.baidu.com
自定义函数
webString = input("Please input url = ")print(webString)def change_number(number):return number.replace(number[3:7], '*'*4)print(change_number("15916881234"))# 159****1234
python文件通常有两种使用方法:
第一是作为脚本直接执行。
第二是 import 到其他的 python 脚本中被调用(模块重用)执行。
因此 if __name__ == 'main' 的作用就是控制这两种情况执行代码的过程,在 if __name__ == 'main' 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行。
2、基本爬虫操作
网络请求加密方式:1. 对称密钥加密 2. 非对称密钥加密 3.证书加密(https)
首先安装request第三方的库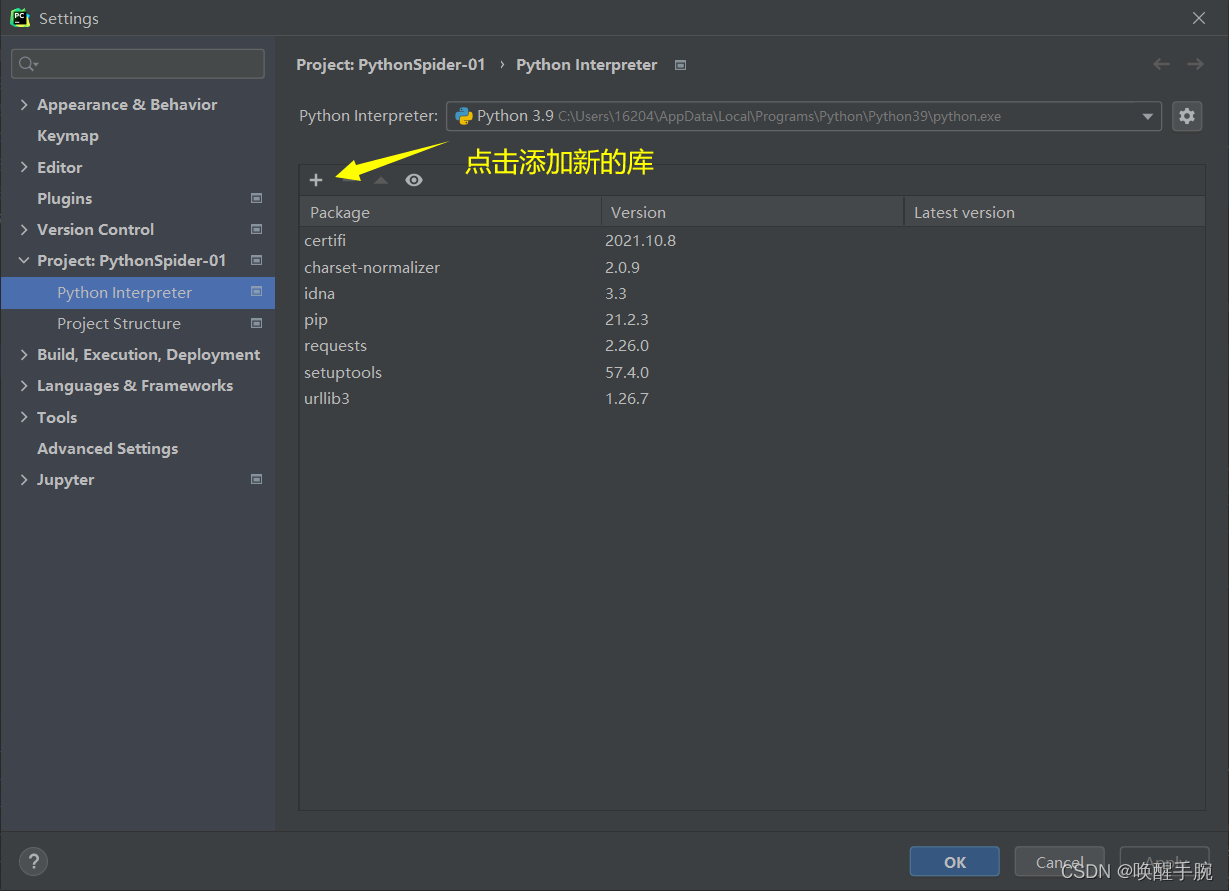
GuessedAtParserWarning: No parser was explicitly specified 未添加解析器
基本请求的案例
import requestslink = "http://www.santostang.com/"headers = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}data = requests.get(link, headers=headers)print(data.text)
完整代码展示
import requestsfrom bs4 import BeautifulSouplink = "http://www.santostang.com/"headers = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}data = requests.get(link, headers=headers)soup = BeautifulSoup(data.text, "html.parser")print(soup.find("h1", class_="post-title").a.text)# 第四章 – 4.3 通过selenium 模拟浏览器抓取
数据持久化的操作,写入文件中
with open('index.txt', 'w+', encoding="utf-8") as f:f.write(text)f.close()
3、数据持久化储存
如果发生写入文件的字符出现乱码,那么需要增加 encoding=”utf-8
文件操作的基础模式有三种(默认的操作模式为r模式):
- r 模式为 read
- w 模式为 write
- a 模式为 append
文件读写内容的格式有两种(默认的读写内容的模式为b模式):
- t 模式为 text
- b 模式为 bytes
常见的文件打开模式:
r:只读模式,文件的指针放在文件开头w:只写模式,文件不存在则创建,文件存在,则覆盖原有内容,文件指针在文件开头a:追加模式打开文件,文件不存在则创建,文件指针在开头,文件存在则在文件尾追加内容,文件指针在源文件末尾b:以二进制方式打开文件,不能单独使用,需要与其他模式一起使用,如:rb,wb+:以读写模式代开文件,不能单独使用,需要与其他模式一起使用,如:a+
4、json库的使用
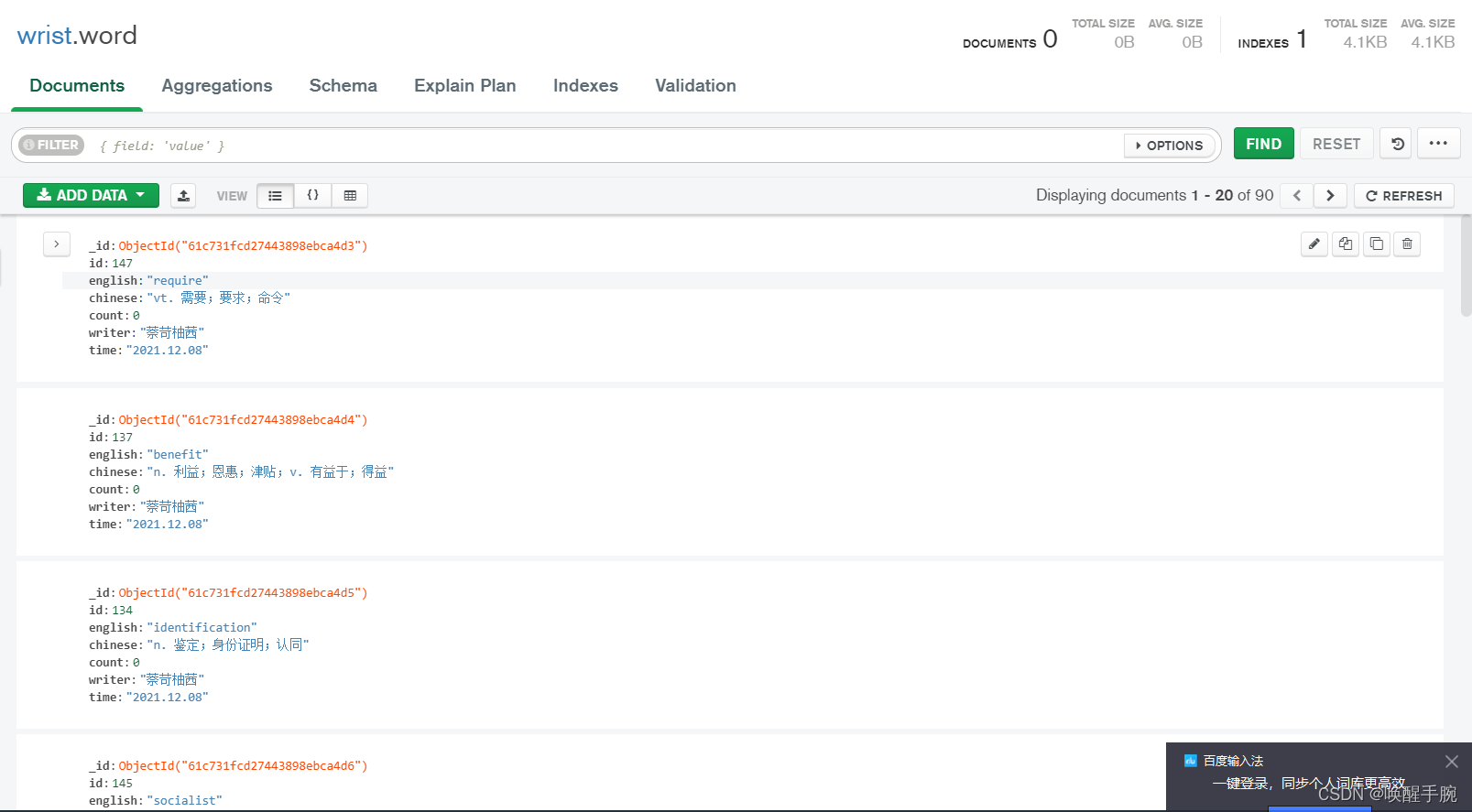
import requestsimport jsonheaders = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}data = requests.get("http://localhost:8080/person/words/all", headers=headers, timeout=0.5)json_data = json.loads(data.text)for index, each_row in enumerate(json_data):print()print(str(index + 1) + '.\t' + each_row['english'].ljust(20) + each_row['chinese'])# 1. extreme adj. 极度的,极端的;n. 极端## 2. concern n. 关心;关系;公司 vt. 涉及,有关;使担心## 3. benefic adj. 有益的
5、selenium库的使用
| 定位一个元素 | 定位多个元素 | 含义 |
|---|---|---|
| find_element_by_id | find_elements_by_id | 通过元素id定位 |
| find_element_by_name | find_elements_by_name | 通过元素name定位 |
| find_element_by_xpath | find_elements_by_xpath | 通过xpath表达式定位 |
| find_element_by_link_text | find_elements_by_link_text | 通过完整超链接定位 |
| find_element_by_partial_link_text | find_elements_by_partial_link_text | 通过部分链接定位 |
| find_element_by_tag_name | find_elements_by_tag_name | 通过标签定位 |
| find_element_by_class_name | find_elements_by_class_name | 通过类名进行定位 |
| find_elements_by_css_selector | find_elements_by_css_selector | 通过css选择器进行定位 |
假如我们有一个Web页面,通过前端工具(如,Firebug)查看到一个元素的属性是这样的。
<html><head></head><body link="#0000cc"><a id="result_logo" href="/" onmousedown="return c({'fm':'tab','tab':'logo'})"><form id="form" class="fm" name="f" action="/s"><span class="soutu-btn"></span><input id="kw" class="s_ipt" name="wd" value="" maxlength="255" autocomplete="off"/></form></body></html>
通过id定位:
dr.find_element_by_id("kw")
通过name定位:
dr.find_element_by_name("wd")
通过class name定位:
dr.find_element_by_class_name("s_ipt")
通过tag name定位:
dr.find_element_by_tag_name("input")
通过xpath定位,xpath定位有N种写法,这里列几个常用写法:
dr.find_element_by_xpath("//*[@id='kw']")dr.find_element_by_xpath("//*[@name='wd']")dr.find_element_by_xpath("//input[@class='s_ipt']")dr.find_element_by_xpath("/html/body/form/span/input")dr.find_element_by_xpath("//span[@class='soutu-btn']/input")dr.find_element_by_xpath("//form[@id='form']/span/input")dr.find_element_by_xpath("//input[@id='kw' and @name='wd']")
通过css定位,css定位有N种写法,这里列几个常用写法:
dr.find_element_by_css_selector("#kw")dr.find_element_by_css_selector("[name=wd]")dr.find_element_by_css_selector(".s_ipt")dr.find_element_by_css_selector("html > body > form > span > input")dr.find_element_by_css_selector("span.soutu-btn> input#kw")dr.find_element_by_css_selector("form#form > span > input")
接下来,我们的页面上有一组文本链接。
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a><a class="mnav" href="http://www.hao123.com" name="tj_trhao123">hao123</a>
通过link text定位:
dr.find_element_by_link_text("新闻")dr.find_element_by_link_text("hao123")
通过partial link text定位:
dr.find_element_by_partial_link_text("新")dr.find_element_by_partial_link_text("hao")dr.find_element_by_partial_link_text("123")
6、jieba库的使用
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode)
print(*objects, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False) print不换行,print(“helloworld”,end=””)
import jiebaString = "My name is wrist waking"for item in jieba.cut(String):print(item, end='')String_chinese = "我的名字叫唤醒手腕"for item in jieba.cut(String_chinese, cut_all=True):print(item, end=',')# My name is wrist waking我,的,名字,叫唤,唤醒,手腕,
7、pymysql库的使用
python3 与 MySQL 进行交互编程需要安装 pymysql 库,故首先使用如下命令安装pymysql
pip install pymysql
import pymysql# 打开数据库连接conn = pymysql.connect(host='localhost', user="root", passwd="root", db="nodedb")print(conn)print(type(conn))
conn.cursor() : 获取游标
要想操作数据库,光连接数据是不够的,必须拿到操作数据库的游标,才能进行后续的操作,比如读取数据、添加数据。通过获取到的数据库连接实例conn下的cursor()方法来创建游标。
游标用来接收返回结果
说明:cursor返回一个游标实例对象,其中包含了很多操作数据的方法,比如执行sql语句。
执行sql语句execute和executemany
- execute(query,args=None)
- 函数作用:执行单条的sql语句,执行成功后返回受影响的行数
- 参数说明:
- query:要执行的sql语句,字符串类型
- args:可选的序列或映射,用于query的参数值。如果args为序列,query中必须使用%s做占位符;如果args为映射,query中必须使用%(key)s做占位符
- executemany(query,args=None)
- 函数作用:批量执行sql语句,比如批量插入数据,执行成功后返回受影响的行数
- 参数说明:
- query:要执行的sql语句,字符串类型
- args:嵌套的序列或映射,用于query的参数值
数据库性能瓶颈很大一部份就在于网络IO和磁盘IO,将多个sql语句放在一起,只执行一次IO,可以有效的提升数据库性能。
用executemany()方法一次性批量执行sql语句,固然很好,但是当数据一次传入过多到server端,可能造成server端的buffer溢出,也可能产生一些意想不到的麻烦。所以,合理、分批次使用executemany是个合理的办法。
定义数据连接操作的类
# connect_db:连接数据库,并操作数据库import pymysqlclass OperationMysql:"""数据库SQL相关操作import pymysql# 打开数据库连接db = pymysql.connect("localhost","testuser","test123","TESTDB" )# 使用 cursor() 方法创建一个游标对象 cursorcursor = db.cursor()# 使用 execute() 方法执行 SQL 查询cursor.execute("SELECT VERSION()")"""def __init__(self):# 创建一个连接数据库的对象self.conn = pymysql.connect(host='127.0.0.1', # 连接的数据库服务器主机名port=3306, # 数据库端口号user='root', # 数据库登录用户名passwd='root',db='nodedb', # 数据库名称charset='utf8', # 连接编码cursorclass=pymysql.cursors.DictCursor)# 使用cursor()方法创建一个游标对象,用于操作数据库self.cur = self.conn.cursor()# 查询一条数据def search_one(self, sql):self.cur.execute(sql)result = self.cur.fetchone() # 使用 fetchone()方法获取单条数据.只显示一行结果# result = self.cur.fetchall() # 显示所有结果return result# 更新SQLdef updata_one(self, sql):try:self.cur.execute(sql) # 执行sqlself.conn.commit() # 增删改操作完数据库后,需要执行提交操作except:# 发生错误时回滚self.conn.rollback()self.conn.close() # 记得关闭数据库连接# 插入SQLdef insert_one(self, sql):try:self.cur.execute(sql) # 执行sqlself.conn.commit() # 增删改操作完数据库后,需要执行提交操作except:# 发生错误时回滚self.conn.rollback()self.conn.close()# 删除sqldef delete_one(self, sql):try:self.cur.execute(sql) # 执行sqlself.conn.commit() # 增删改操作完数据库后,需要执行提交操作except:# 发生错误时回滚self.conn.rollback()self.conn.close()if __name__ == '__main__':op_mysql = OperationMysql()res = op_mysql.search_one("SELECT * from people WHERE id = 1")print(res)# {'id': 1, 'name': '周杰伦', 'age': 42}
8、mongodb数据库
MongoDB是基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB服务端可运行在Linux、Windows或mac os x平台,支持32位和64位应用,默认端口为27017。
推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
MongoDB 主要特点
- MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。
- 集合就是一组文档,类似于关系数据库中的表。
既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
MongoDB 实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。
MongoDB 中存在以下系统数据库:
- Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。
- Local 数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。
- Config 数据库:当MongoDB使用分片模式时,config 数据库在内部使用,用于保存分片的信息。
用户权限介绍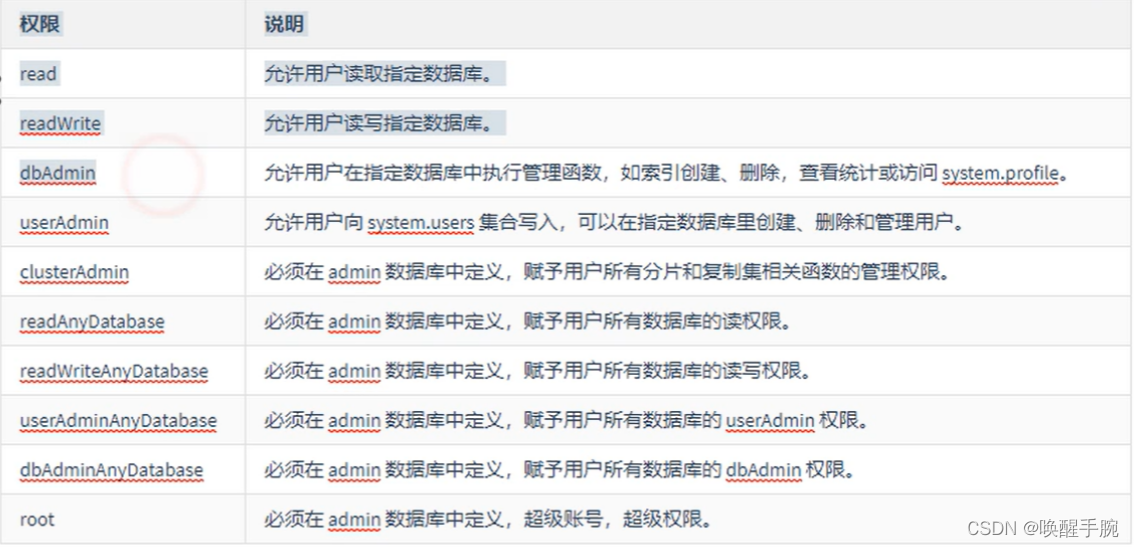
创建用户
cd /www/server/mongodb/bin# mongo安装目录下的bin目录mongo# 启动mongo服务,输入命令行mongo,进入mongodb环境use admin# 切换到admin数据库# 正常情况就会报错 Error: not authorized on admin# 先鉴权登录 db.auth('root', '此处是密码')db.createUser({user: "root",pwd:"root",roles:[{ role: "readWriteAnyDatabase" , db: "DBNAME" }] })# 创建用户# 成功结果如下:Successfully added user: {"user" : "root","roles" : [{"role" : "readWriteAnyDatabase","db" : "admin"}]}show users# 查看用户列表
远程联机宝塔centos系统的Mongodb数据库
进行权限的配置修改:
宝塔面板 和 服务器平台 都要开启27017的端口号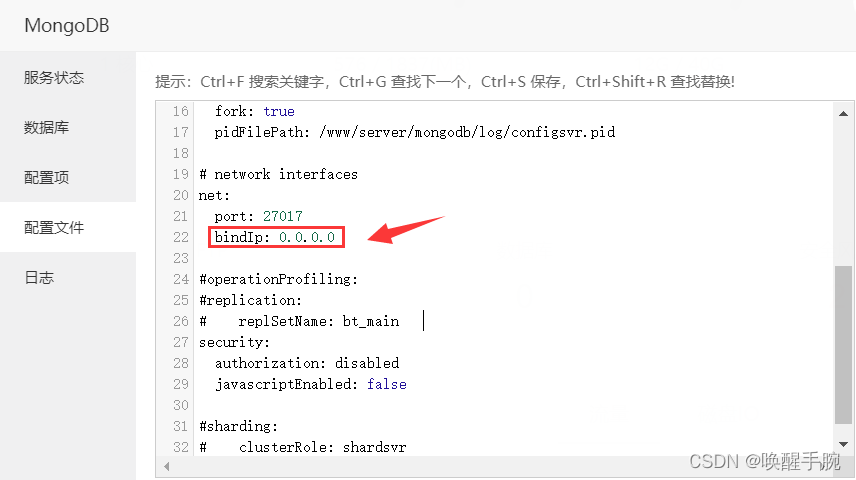
9、pymongo库的使用
远程连接宝塔面板的Mongodb
import pymongofrom datetime import datetimeprint(datetime.now())# username="test"# password="test"# connection=pymongo.mongo_client.MongoClient(host="192.168.10.9:27017,connect=False,username=username,password=password)# 链接服务器, 是本地服务器可不需要传入参数MongoClient = pymongo.mongo_client.MongoClient("mongodb://root:root@远程服务器IP:27017")# MongoClient = pymongo.MongoClient("mongodb://root:root@远程服务器IP:27017")# 获取数据库, 中括号中填入数据库中的名字db = MongoClient["wrist"]collection = db.zhangyanres = collection.find()for item in res:print(item.get("name"))
在Document中插入数据:
collection.insert_one({'name': '唤醒手腕', 'datetime': datetime.now()})insert_many(list_of_dict) # 插入多个
比较运算符 查找数据
| 符号 | 说明 |
|---|---|
| $eq | 它将匹配等于指定值的值 |
| $ne | 它将匹配所有不等于指定值的值 |
| $gt | 它将匹配大于指定值的值 |
| $gte | 它将匹配所有大于或等于指定值的值 |
| $lt | 它将匹配所有小于指定值的值 |
| $lte | 它将匹配所有小于或等于指定值的值 |
| $in | 它将匹配数组中指定的任何值 |
| $nin | 它讲匹配不再数组中的值 |
filterOption = {"age": {"$gte": 20}}# 查询年龄大于等于20岁的data = collection.find_one(filterOption)print(data)# {'_id': ObjectId('61c7297dfff4db0a50af9f06'), 'name': '张燕', 'age': 20}
逻辑运算符查询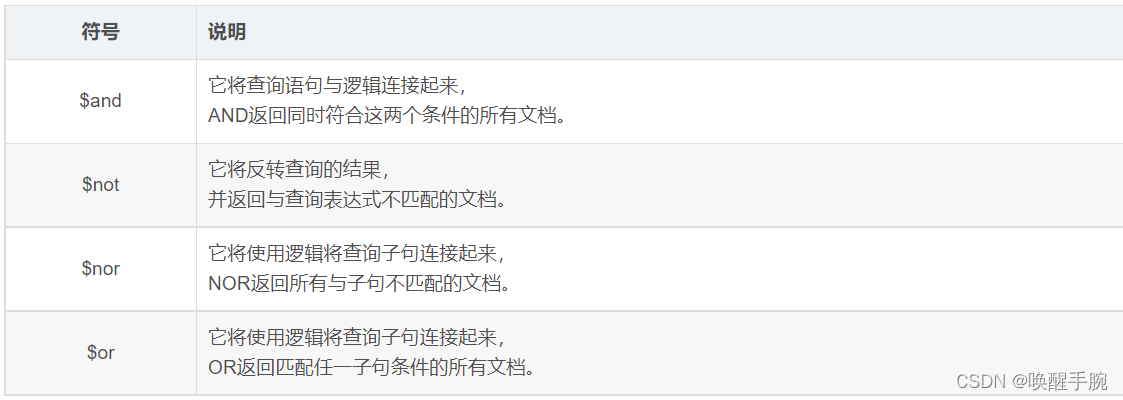
filterAnd = {'$and':[{'fid': {'$eq': 2048}}, # filter_01{'sid': {'$ne': 1024}} # filter_02]}filterOr = {'$or':[{'fid': {'$eq': 2048}}, # filter_01{'sid': {'$ne': 1024}} # filter_02]}
正则表达式查询
filterOption = {'name': {'$regex': r'Tom [a-zA-Z]+'}}
遍历文档获取集合内所有文件:
# collection.find({})# collection.find_one(filter) 只返回1个for one in collection.find({}):print(one)
删除的操作:
删除一个 collection.delete_one(filter)
删除多个 collection.delete_many(filter)
修改的操作:
collection.update_many(filter, update)
新参量 update 说明:形式 {command: {key: value}}
- $set 修改或新增字段
- $unset 删除指定字段
- $rename 重命名字段
# 修改或新增字段filter = {'name': '马大师'}add_data = {'age': 60}# key name 存在,改其值为 马大师?update1 = {'$set': {'name': '马大师?'}}# key age 不存在,插入字段update2 = {'$set': add_data}collection.update_one(filter, update1)collection.update_one(filter, update2)# 删除指定字段filter = {'name': '马大师?'}del_data = {'age': 60}update = {'$unset': del_data}collection.update_one(filter, update)# 重命名字段filter = {'name': '马大师?'}update = {'$rename': {'name': '名字'}}collection.update_one(filter, update)
断开连接:
client.close()
综合案例:
import requestsimport jsonimport pymongoheaders = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}data = requests.get("http://localhost:8080/person/words/all", headers=headers)words = json.loads(data.text)MongoClient = pymongo.mongo_client.MongoClient("mongodb://root:root@远程服务器IP:27017")db = MongoClient['wrist']collection = db.wordcollection.insert_many(words)
10、媒体资源爬取
requests对象的get和post方法都会返回一个对象Response对象,在这个对象中存放的是服务器返回的所有信息,包括响应头,响应状态码等等。
- .text 返回的是Beautifulsoup根据猜测的编码方式将content内容编码成字符串。
- .content 返回的是bytes字节码
.text是现成的字符串,.content还要编码,但是.text不是所有时候显示都正常,这是就需要用.content进行手动编码。
关于图片资源的爬取
首先就是获取图片资源的URL地址,对地址发起请求获取二进制数据 data.content
import requestsurl = "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fc-ssl.duitang.com%2Fuploads%2Fitem%2F202005%2F12%2F20200512131057_4Rsc8.thumb.1000_0.jpeg"data = requests.get(url)with open('minitang.jpg', 'wb') as f:f.write(data.content)f.close()
关于视频资源的爬取
首先就是获取视频资源的URL地址,对地址发起请求获取二进制数据 data.content
import requestsurl = "https://vd3.bdstatic.com/mda-mmq1yv5cag635vhm/cae_h264/1640395713342120634/mda-mmq1yv5cag635vhm.mp4"data = requests.get(url)with open("kaoyan.mp4","wb") as f:f.write(data.content)f.close()
关于音频资源的爬取
网易云音乐的接口:从这里获取id,调用http://music.163.com/song/media/outer/url?id=歌曲ID
打开网易云音乐PC端官网,搜索你想要的歌曲(举个例子:All Falls Down),在浏览器的Url地址栏,找到歌曲的id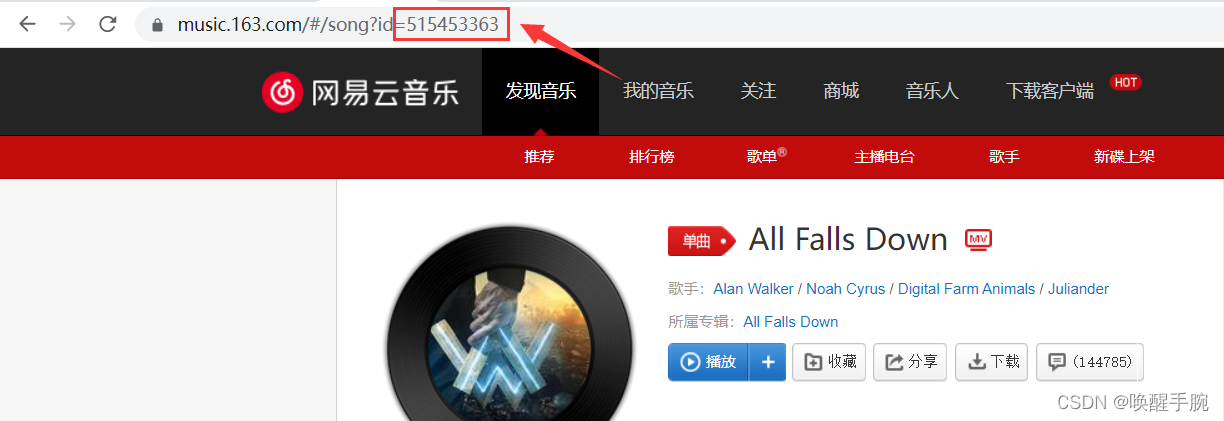
代码测试如下所示:
import requestsimport osdata = requests.get("http://music.163.com/song/media/outer/url?id=515453363")with open("music.mp3", 'wb') as f:f.write(data.content)# 写入文件f.close()# 关闭文件流os.system("music.mp3")# os.system("") 调用操作系统读取打开文件
11、PIL库的使用
使用 PIL 之前需要 import Image 模块
PIL是python平台事实上的图像处理标准库,但PIL仅支持到python2.7,加上年久失修,于是在PIL的基础上创建了兼容的版本pillow,支持最新的python3.X。
然后你就可以使用Image.open(‘xx.bmp’) 来打开一个位图文件进行处理了。
打开文件你不用担心格式,也不用了解格式,无论什么格式,都只要把文件名丢给 Image.open 就可以了。真所谓 bmp、jpg、png、gif……,万物皆可斩。
img = Image.open(‘origin.png’) # 得到一个图像的实例对象 img
图像处理中,最基本的就是色彩空间的转换。一般而言,我们的图像都是 RGB 色彩空间的,但在图像识别当中,我们可能需要转换图像到灰度图、二值图等不同的色彩空间。
PIL 在这方面也提供了极完备的支持,我们可以:
new_img = img.convert(‘L’)
把 img 转换为 256 级灰度图像, convert() 是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式,mode 的取值可以是如下几种:
- 1 (1-bit pixels, black and white, stored with one pixel per byte)
- L (8-bit pixels, black and white)
- P (8-bit pixels, mapped to any other mode using a colour palette)
- RGB (3x8-bit pixels, true colour)
- RGBA (4x8-bit pixels, true colour with transparency mask)
- CMYK (4x8-bit pixels, colour separation)
- YCbCr (3x8-bit pixels, colour video format)
- I (32-bit signed integer pixels)
- F (32-bit floating point pixels)
图像增强通常用以图像识别之前的预处理,适当的图像增强能够使得识别过程达到事半功倍的效果。 PIL 在这方面提供了一个名为 ImageEnhance 的模块,提供了几种常见的图像增强方案:
import ImageEnhanceenhancer = ImageEnhance.Sharpness(image)for i in range(8):factor = i / 4.0enhancer.enhance(factor).show("Sharpness %f" % factor)
上面的代码即是一个典型的使用 ImageEnhance 模块的例子。
Sharpness 是 ImageEnhance 模块的一个类,用以锐化图片。这一模块主要包含如下几个类:Color、Brightness、Contrast和Sharpness,它们都有一个共同的接口 .enhance(factor),接受一个浮点参数 factor,标示增强的比例。
灰度图的制作
from PIL import Imageimg = Image.open("../ImageMake/minitang.jpg")img = img.convert('L')try:img.save("L.jpg")except IOError:print("cannot convert")
子图片粘贴到父图片上
from PIL import Imageimport osimgMini = Image.open('../ImageMake/L.jpg')imgMini = imgMini.resize((300, 300))imgBack = Image.open('../ImageMake/minitang.jpg')imgBack = imgBack.resize((600, 600))imgBack.paste(imgMini, (200, 200, 500, 500))try:imgBack.save("bingjie.jpg")except IOError:print("cannot save")
高斯模糊图制作
from PIL import Image,ImageFilterimage = Image.open("minitang.jpg")image = image.filter(ImageFilter.GaussianBlur(radius=20))try:image.save("gaoshi02.jpg")except IOError:print("cannot save")
二维码制作
首先要安装qrcode库,url可以是链接地址,也可以是文本数据。
import qrcodeqr = qrcode.QRCode(version=None,error_correction=qrcode.constants.ERROR_CORRECT_Q,box_size=10,border=1,)url = '巩师伟你是个傻逼!'qr.add_data(url)qr.make(fit=True)img = qr.make_image(fill_color="green", back_color="transparent")print (img.pixel_size)img.save('output2.png')
12、图像识别技术
图片的文字识别
若未安装pillow,以管理员的身份打开命令提示符,输入:pip install pillow.
例如识别如下图片中的文字,打印到控制台上:
代码如下所示:
from PIL import Imageimport pytesseractim = Image.open('imgText.png')print(pytesseract.image_to_string(im, lang='chi_sim').replace('\n', ''))
运行Python文件,如果出现如下报错,错误原因是:没有安装识别引擎**tesseract-ocr**
tesseract-ocr : 链接:https://pan.baidu.com/s/1cu4xF8fAXfKYq71qMETeCg 提取码:5hjq
解压后,双击 tesseract-ocr-w64-setup-v4.1.0.20190314.exe 进行安装
解压安装tesseract-ocr后做如下操作,就可以支持中文识别了。因为tesseract-ocr默认不支持中文识别。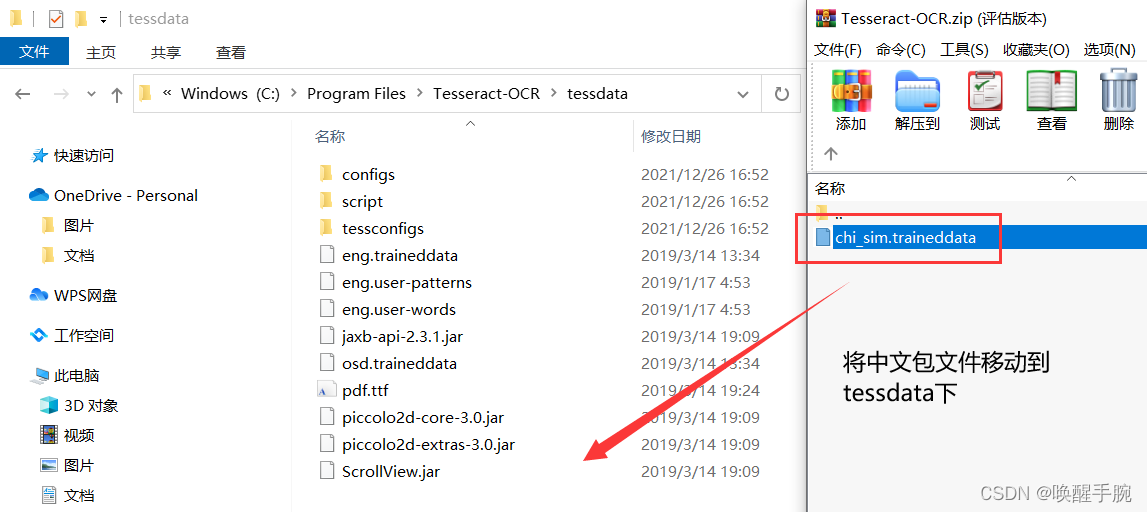
安装完成tesseract-ocr后,我们还需要做一下配置
打开目录:C:\Users\你的账户名称\AppData\Local\Programs\Python\Python39\Lib\site-packages\pytesseract
我的账号名称是16204,效果如下:,
找到pytesseract.py,打开(用pycharm打开)后做如下操作
......# tesseract_cmd = 'tesseract'# 将上面的注释,tesseract_cmd,重新赋值为你tesseract-ocr安装目录下tesseract.exe文件的地址值tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'# 加r是不进行转义的意思......
以上的操作就是:关联OCR和pytesseract
至此我们所有的配置就完成了,运行下面代码就可以解析成文字了
若出现如下的错误,先不要着急,是环境变量没有配置,我们再进行环境变量配置。
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:/Program Files/Tesseract-OCR/tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
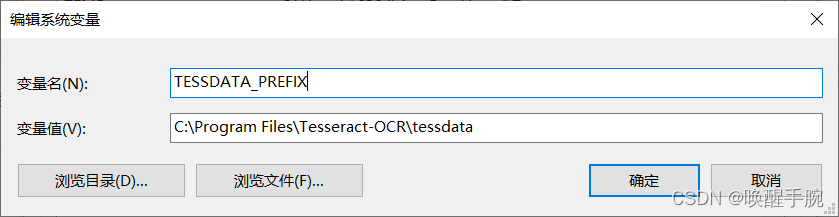
在进行系统变量配置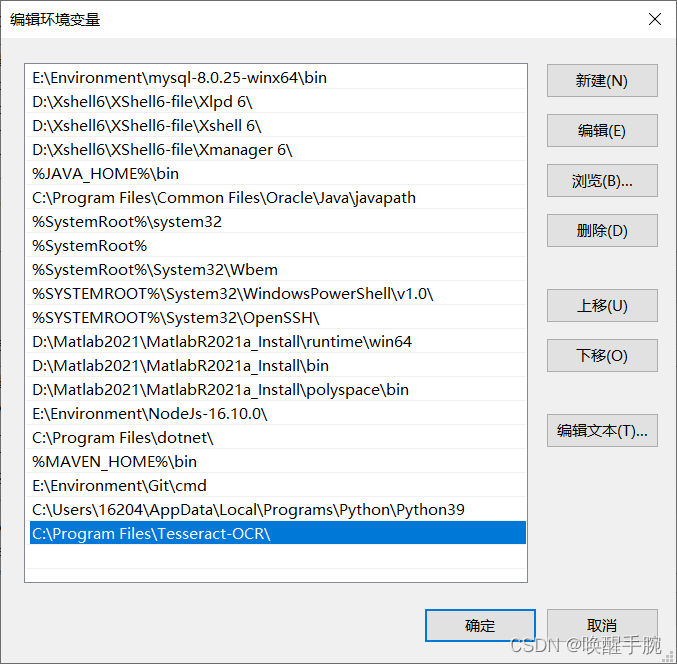
运行结果如下所示:(识别中文还是存在误差的)
唤醒ˉˉ腕你罡个 痴傻帽呀!
英文图片识别的测试
读取下面图片中的英文,打印在控制台上。
代码展示:
from PIL import Imageimport pytesseractim = Image.open('imgenglish.png')print(pytesseract.image_to_string(im, lang='eng').replace('\n', ''))# lang='eng' 识别语言设置为 eng (英语)# 解释下为什么要加.replace('\n', ''),因为在文字识别时候会出现空行,所以要清除这些不必要的空行。
打印的结果如下所示:(可见英文的识别度比中文高)
Time runs fast with the rapid of my heart.
13、pypiwin32库的使用
上个小节介绍了,图像识别技术,那么这个小节,介绍下智能语音朗读
需要用到的第三方库是pypiwin32,可以到pycharm的setting下安装该第三方库
import win32com.clientspeaker = win32com.client.Dispatch("SAPI.SpVoice")speaker.Speak("唤醒手腕你真的帅呀!") # 朗读内容
运行上述的代码,可以听到智能语言朗读,不仅支持中文朗读,也支持英语朗读。
编写语音朗读闹钟功能的示例代码
首先介绍下python中关于时间的库:time,它是python环境自带的本地库,无需安装。
import timecurrentTime = time.localtime() # 获取本地时间赋值给currentTime变量print(currentTime)# 结果:time.struct_time(tm_year=2021, tm_mon=12, tm_mday=26, tm_hour=19, tm_min=23, tm_sec=29, tm_wday=6, tm_yday=360, tm_isdst=0)
由上可见time.localtime()是有关当前系统时间的结构体。time.struct_time.tm_year表示当前年,time.struct_time.tm_mon表示当前月······,其他表示很容易理解,不举例了。
import win32com.clientimport timespeak = win32com.client.Dispatch("SAPI.SpVoice")setUpTime = input("你要闹铃的时间(例如:19:45:40)= ")def timeFormat(value):if value >= 10:return str(value)else:return '0' + str(value)# 自定义 时间格式化函数while 1:currentTime = time.localtime()# 当前时间的纪元值currentH = timeFormat(currentTime.tm_hour)currentM = timeFormat(currentTime.tm_min)currentS = timeFormat(currentTime.tm_sec)timeShow = currentH + ':' + currentM + ':' + currentSprint('当前时间:' + timeShow)if timeShow == setUpTime:speak.Speak("请注意,请注意,It's time for homework")breaktime.sleep(1)# time.sleep(1) 延迟1秒
14、数据可视化案例
为什么学数据可视化,对于我们在爬取到数据进行分析,那么进行数据可视化是必不可少的。如果有志于在大数据、机器学习、人工智能领域从业的话,数据可视化是首当其冲的的,因此说不得不学。
数据可视化是指通过可视化表示来探索数据,它与数据挖掘紧密相关,而数据挖掘指得是使用代码来探索数据集的规律和关联。
对于博主来说呢,博主常用Matlab进行数据可视化,我是哔哩哔哩Matlab方向的UP主,Matlab和Python都可以进行数据可视化,主要区别:Matlab比较偏向于工程计算,对于计算数学的模拟。而python来说呢,比较轻量级些,用于数据可视化是比较优越的。
数据可视化常用的第三方库:plotly、Matplotlib
如何画折线图?
import matplotlib.pyplotplt = matplotlib.pyplot# 演示一下,y = x^2X_value = [1, 2, 3, 4, 5]Y_value = [1, 4, 9, 16, 25]plt.plot(X_value, Y_value)plt.show()# plt.show() 进行图像的展示
运行上述的代码,效果如下: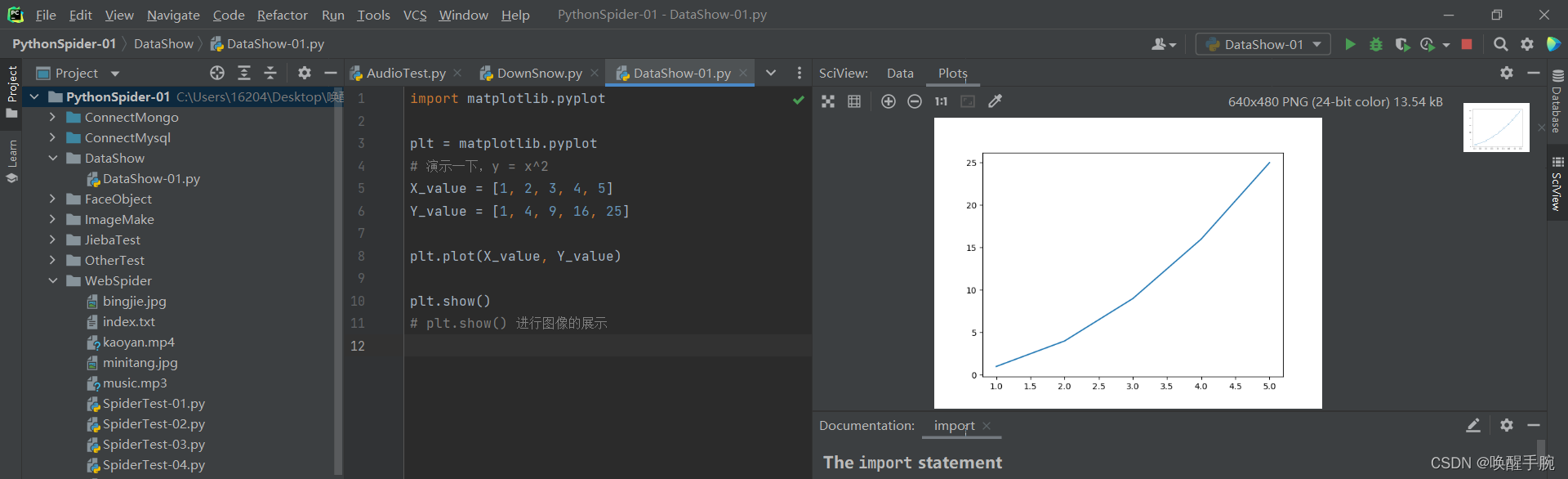
对数据表格进行操作代码,展示如下(我们不需要会背,理解会用就行,后期可以查文档进行制作就行)
import matplotlib.pyplotplt = matplotlib.pyplot# 演示一下,y = x^2X_value = [1, 2, 3, 4, 5]Y_value = [1, 4, 9, 16, 25]plt.plot(X_value, Y_value)plt.title("Squares Numbers", fontsize=24)# 设置标题及大小,只支持英语plt.xlabel("variable X_value", fontsize=14)# 设置x坐标名称及大小,只支持英语plt.ylabel("Function Squares of X_value", fontsize=14)# 设置y坐标名称及大小,只支持英语plt.tick_params(axis='both', labelsize=14)# 设置坐标轴上数字大小plt.legend(['X'], loc=1)# 为添加线描述;loc为描述的位置,可用数字为1-10;多个标签时为['X,'Y']类推plt.show()# plt.show() 进行图像的展示
完善信息后的图像,展示的效果如下: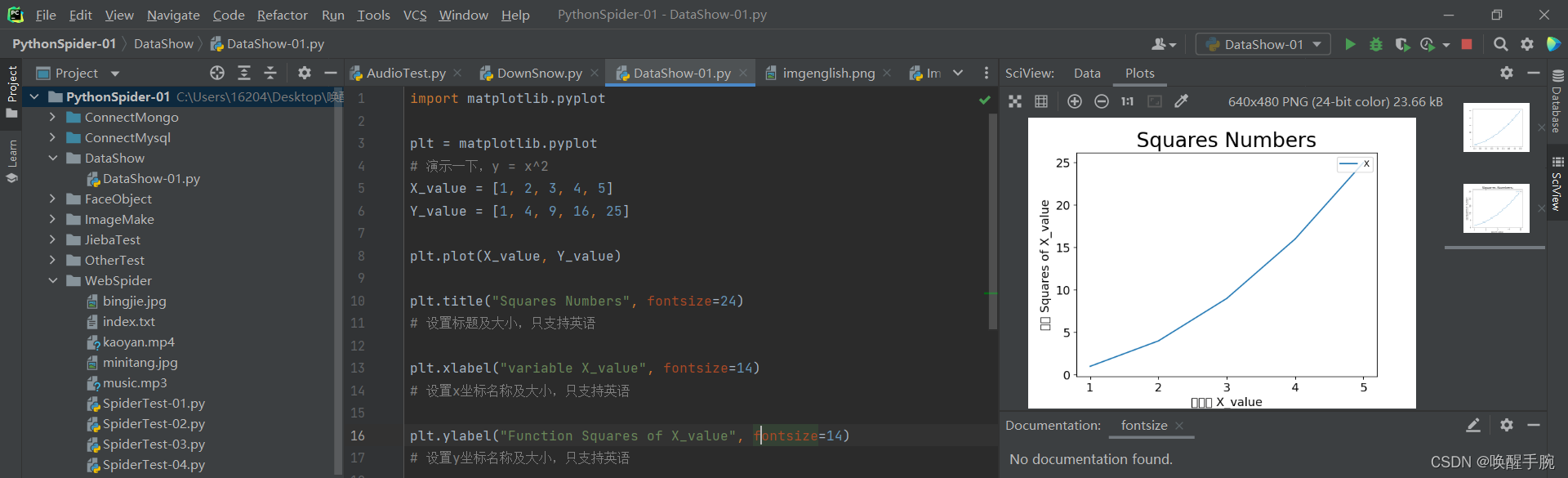
显示中文字符:matplotlib.pyplot默认是不支持中文字符的,最简单的方法就是在代码前添加如下命令:
plt.rcParams['font.sans-serif']=['SimHei']
15、matplotlib库的使用
在上个小节我们简单介绍了数据可视化简单案例,这小节我们详细去介绍matplotlib库的具体如何去使用。
matplotlib.pyplot是使matplotlib像MATLAB一样工作的命令样式函数的集合。
每个pyplot功能都会对图形进行一些更改:例如,创建图形,在图形中创建绘图区域,在绘图区域中绘制一些线条,用标签装饰绘图等。
使用pyplot生成可视化效果非常快:
import matplotlib.pyplot as pltplt.plot([1, 2, 3, 4])plt.ylabel('some numbers')plt.show()# import matplotlib.pyplot# plt = matplotlib.pyplot# 上面注释的两行代码简化成 import matplotlib.pyplot as plt
展示的效果如下: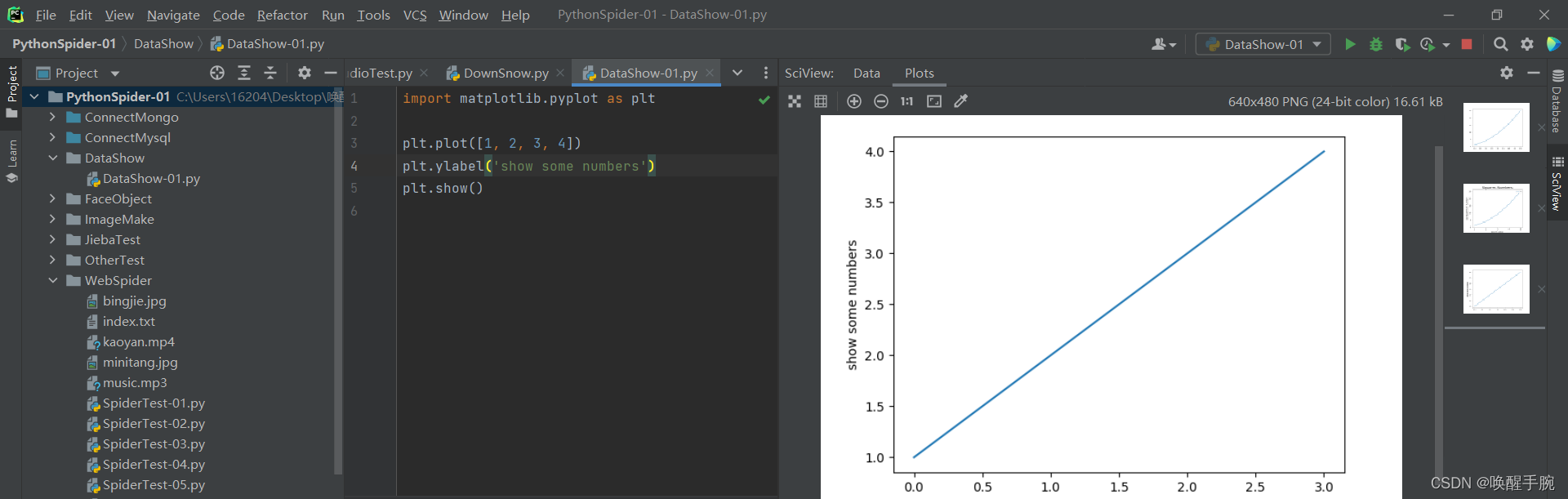
如果为plot()命令提供单个列表或数组 ,则matplotlib假定它是y值的序列,并自动生成x值。由于python范围从0开始,因此默认x向量的长度与y相同,但从0开始,因此x数据为 [0, 1, 2, 3]
plot()是一个通用命令,它将接受任意数量的参数。例如,要绘制x与y的关系,可以发出以下命令:
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
格式化绘图样式
对于每对x,y参数,都有一个可选的第三个参数,它是表示图的颜色和线条类型的格式字符串。
格式字符串的字母和符号来自MATLAB,您将颜色字符串与线条样式字符串连接在一起。默认格式字符串是“ b-”,这是一条蓝色实线。例如,要用红色圆圈绘制以上内容,则需要编写代码如下:
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro')plt.axis([0, 6, 0, 20]) #[xmin, xmax, ymin, ymax]
如果matplotlib只限于使用列表,则对于数字处理将毫无用处。通常,都会使用numpy数组来配合完成。实际上,所有序列都在内部转换为numpy数组。下面的示例说明了使用数组在一条命令中绘制几行具有不同格式样式的行。
import matplotlib.pyplot as pltimport numpy as np#numpy是python内置库,无需安装# 返回一个数组,从0到5,间距是0.25t = np.arange(0, 5, 0.25)# 红色虚线,蓝色正方形,绿色三角形plt.plot(t, t, 'r--', t, t ** 2, 'bs', t, t ** 3, 'g^')plt.show()
展示的效果如下: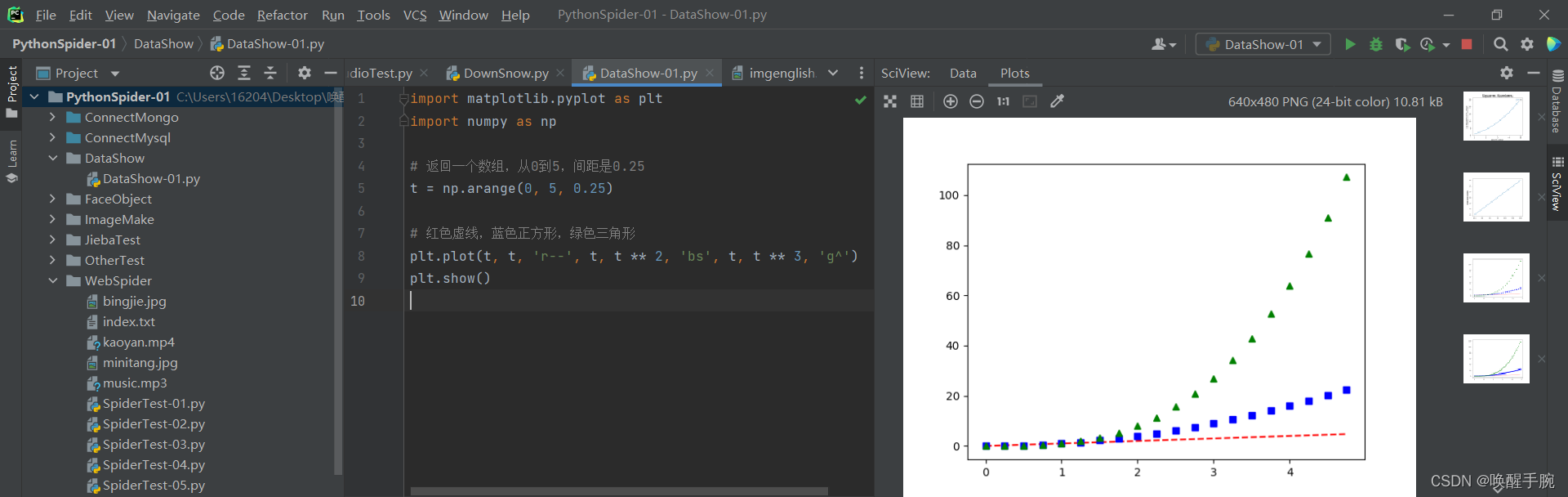
数据可视化图片大小设置与保存
import matplotlib.pyplot as pltx = range(2, 12, 2)y = [3, 6, 2, 7, 8]# 设置图片大小,像素plt.figure(figsize=(10, 4), dpi=70)# 绘制折线图,颜色为红色,线宽为2,透明度为0.5plt.plot(x, y, 'r', label='line 1', linewidth=2, alpha=0.5)# 绘制蓝色点plt.plot(x, y, 'bo')# 保存图片 当前目录下的image.pngplt.savefig("./image.png")# 显示图片plt.show()
展示的效果如下: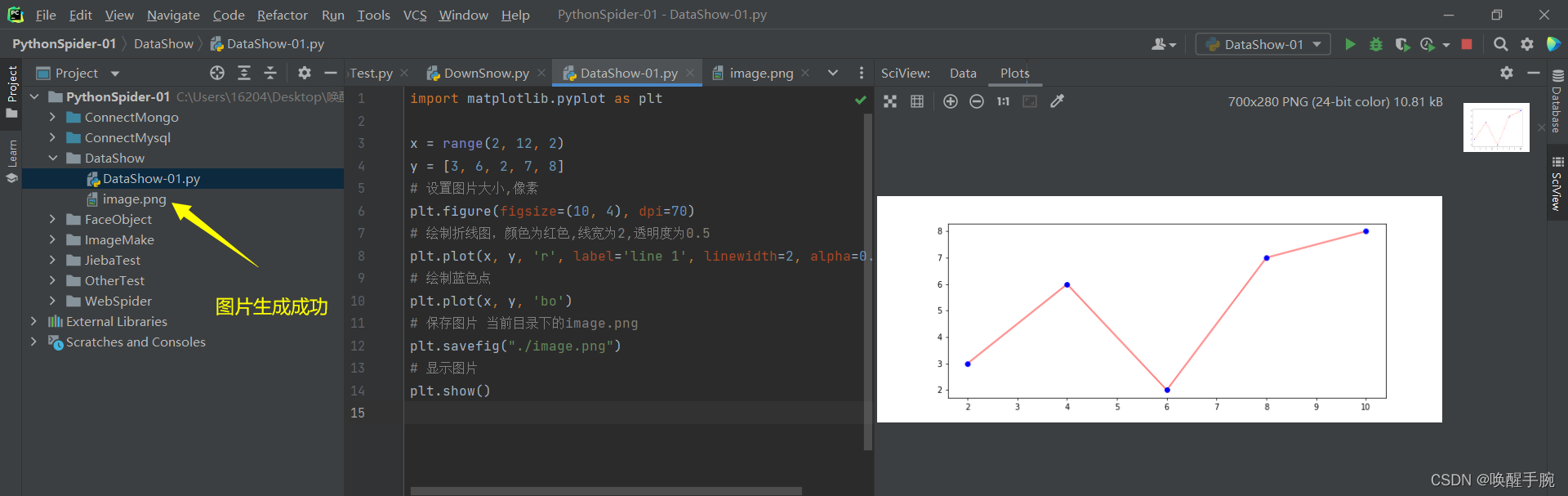
16、数据分析词云图
如何用python进行数据分析,制作词云图,比如下面这只“猪”
我们把构建词云分为两步:
1、处理文本数据
在生成词云时,wordcloud默认会以空格或标点为分隔符对目标文本进行分词处理。
对于中文文本,分词处理需要由用户来完成。一般步骤是先将文本分词处理,然后以空格拼接,再调用wordcloud库函数。
2、产生词云图片
wordcloud库的核心是WordColoud 类,所有的功能都封装在WordCloud 类中。
使用时需要实例化一个WordCloud 类的对象,并调用其generate(text)方法将text文本转化为词云。
处理文本数据
jieba支持三种分词模式:
- 精确模式
lcut(),试图将句子最精确地切开,适合文本分析,单词无冗余; - 全模式
lcut(s, cut_all=True),把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义,存在冗余; - 搜索引擎模式
cut_for_search(s),在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
案例展示如下:
import jiebawith open("wordCloudData.txt", "r", encoding='utf-8') as f: # 读取我们的待处理文本txt = f.read()f.close()remove_data = [",", "。", '\n', '\xa0', ' '] # 无效数据# '\xa0' 就是 HTML里的 # 去除无效数据for r_data in remove_data:txt = txt.replace(r_data, "")words = jieba.lcut(txt) # 使用精确分词模式进行分词后保存为word列表with open("wordCloud_Save.txt", "w", encoding='utf-8') as f:for word in words:f.write(word+' ')print("File save successfully")# UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 111: illegal multibyte sequence# 如果出现上述报错:encoding='utf-8' 没加的缘故
运行成功以后,我们就可以在当前目录下生成wordCloud_Save.txt文件
产生词云图片
wordcloud类的常用方法:
- generate(text) :由text文本生成词云
- to_file(filename) :将词云图保存为名为filename的文件
我们要准备纯底色的图作为词云的背景形状,可以用美图秀秀进行扣图,我就找了马的图片进行扣图,放置到白底图层中(PNG或JPG都可以),效果如下:
生成词云需要调用字体库,找到计算机本地的字库,选择合适某个字库,复制一份,放到当前目录下。路径:此电脑 > C: > Windows > Fonts
我们当前目录下的文件如下所示:
from wordcloud import WordCloudimport matplotlib.pyplot as pltimport numpyfrom PIL import Imagemask = numpy.array(Image.open("horseBackImg.jpg"))# 读取词云形状背景图with open("wordCloud_Save.txt", "r", encoding='utf-8') as f:txt = f.read()f.close()#读取txt(所要生成词云的数据)word = WordCloud(background_color="white", width=1200, height=1200, font_path='STXINGKA.TTF', mask=mask,).generate(txt)word.to_file('finalImg.png')#background_color 生成词云图的背景颜色。red,blueprint("词云图片已保存,名称为finalImg.png")plt.imshow(word) # 使用plt库显示图片plt.axis("off") # 关闭坐标轴plt.show() # 启动展示
完整的代码展示:
from wordcloud import WordCloudimport matplotlib.pyplot as pltimport jiebaimport numpyfrom PIL import Imagewith open("wordCloudData.txt", "r", encoding='utf-8') as f: # 读取我们的待处理文本txt = f.read()f.close()remove_data = [",", "。", '\n', '\xa0', ' '] # 无效数据# 去除无效数据for r_data in remove_data:txt = txt.replace(r_data, "")words = jieba.lcut(txt) # 使用精确分词模式进行分词后保存为word列表with open("wordCloud_Save.txt", "w", encoding='utf-8') as f:for word in words:f.write(word + ' ')f.close()print("File save successfully")# UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 111: illegal multibyte sequence# 如果出现上述报错:encoding='utf-8' 没加的缘故mask = numpy.array(Image.open("horseBackImg.jpg"))with open("wordCloud_Save.txt", "r", encoding='utf-8') as f:txt = f.read()f.close()word = WordCloud(background_color="white", width=2000, height=2000, font_path='STXINGKA.TTF', mask=mask,).generate(txt)word.to_file('finalImg.png')print("词云图片已保存,名称为finalImg.png")plt.imshow(word) # 使用plt库显示图片plt.axis("off")plt.show()
点击运行,展示效果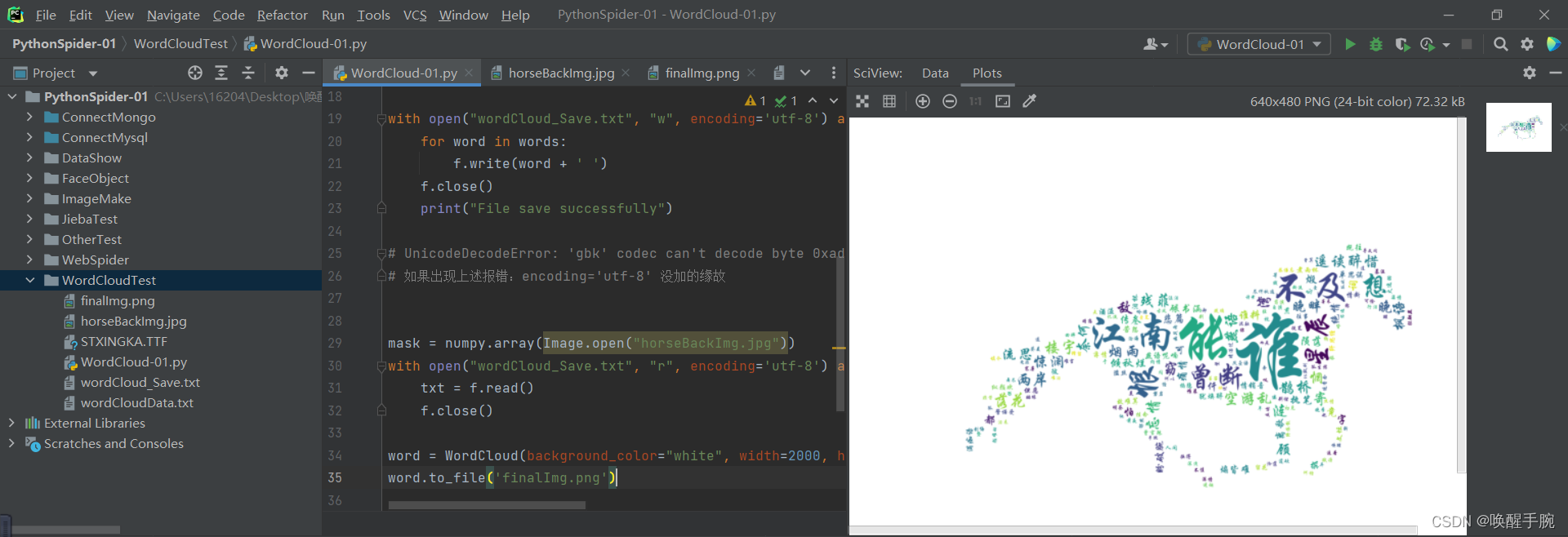

若有收获,就点个赞吧
0 人点赞
