Sharding-JDBC 分库分表基于java bean的聚合分页查询
- 数据库分片思想
- 1 垂直切分
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。
1.2 水平切分
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表)
- Sharding-JDBC 简介
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
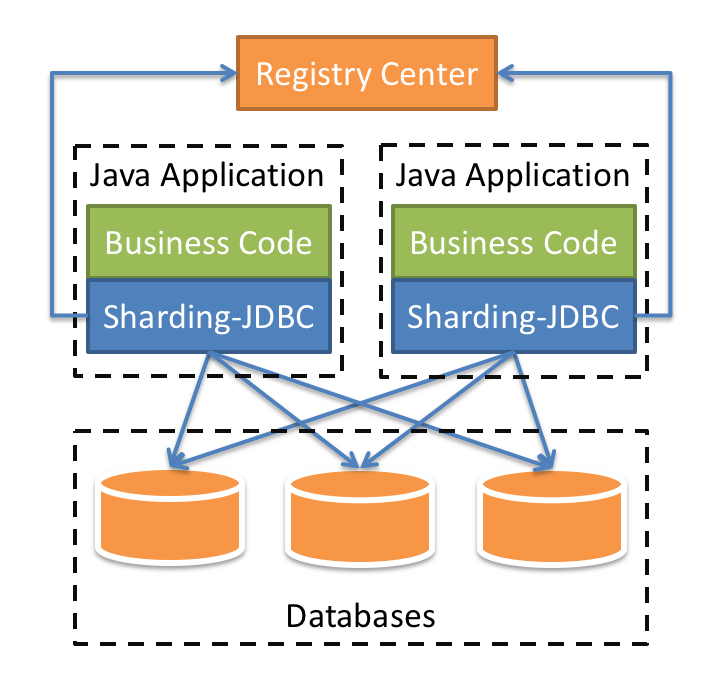 Sharding-JDBC采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;
Sharding-JDBC采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;
- 功能列表
分库 & 分表
读写分离
分布式主键
数据脱敏 - 分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
4.1 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
精准分库算法
public class MyDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {@Overridepublic String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue) {/*** databaseNames 所有分片库的集合* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值*/for (String databaseName : databaseNames) {String value = shardingValue.getValue() % databaseNames.size() + "";if (databaseName.endsWith(value)) {return databaseName;}}throw new IllegalArgumentException();}}
精准分表算法
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Long> shardingValue) {
/**
* tableNames 对应分片库中所有分片表的集合
* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String tableName : tableNames) {
/**
* 取模算法,分片健 % 表数量
*/
String value = shardingValue.getValue() % tableNames.size() + "";
if (tableName.endsWith(value)) {
return tableName;
}
}
throw new IllegalArgumentException();
}
}
4.2 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
使用场景:当我们 SQL中的分片健字段用到 BETWEEN AND操作符会使用到此算法,会根据 SQL中给出的分片健值范围值处理分库、分表逻辑。
SELECT * FROM t_order where order_id BETWEEN 1 AND 100;
自定义范围分片算法需实现 RangeShardingAlgorithm 接口,重写 doSharding() 方法,下边我通过遍历分片健值区间,计算每一个分库、分表逻辑。
public class MyDBRangeShardingAlgorithm implements RangeShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> databaseNames, RangeShardingValue<Integer> rangeShardingValue) {
Set<String> result = new LinkedHashSet<>();
// between and 的起始值
int lower = rangeShardingValue.getValueRange().lowerEndpoint();
int upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (int i = lower; i <= upper; i++) {
for (String databaseName : databaseNames) {
if (databaseName.endsWith(i % databaseNames.size() + "")) {
result.add(databaseName);
}
}
}
return result;
}
}
在配置上由于范围分片算法和精准分片算法,同在标准分片策略下使用,所以只需添加上 range-algorithm-class-name 自定义范围分片算法类路径即可。
# 精准分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.xiaofu.sharding.algorithm.dbAlgorithm.MyDBPreciseShardingAlgorithm
# 范围分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=com.xiaofu.sharding.algorithm.dbAlgorithm.MyDBRangeShardingAlgorithm
4.3 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
public class MyDBComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> databaseNames, ComplexKeysShardingValue<Integer> complexKeysShardingValue) {
// 得到每个分片健对应的值
Collection<Integer> orderIdValues = this.getShardingValue(complexKeysShardingValue, "order_id");
Collection<Integer> userIdValues = this.getShardingValue(complexKeysShardingValue, "user_id");
List<String> shardingSuffix = new ArrayList<>();
// 对两个分片健同时取模的方式分库
for (Integer userId : userIdValues) {
for (Integer orderId : orderIdValues) {
String suffix = userId % 2 + "_" + orderId % 2;
for (String databaseName : databaseNames) {
if (databaseName.endsWith(suffix)) {
shardingSuffix.add(databaseName);
}
}
}
}
return shardingSuffix;
}
private Collection<Integer> getShardingValue(ComplexKeysShardingValue<Integer> shardingValues, final String key) {
Collection<Integer> valueSet = new ArrayList<>();
Map<String, Collection<Integer>> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if (columnNameAndShardingValuesMap.containsKey(key)) {
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
}
return valueSet;
}
}
4.4 Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
Hint分片策略(HintShardingStrategy)相比于上面几种分片策略稍有不同,这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。ShardingSphere 通过 Hint API实现指定操作,实际上就是把分片规则tablerule 、databaserule由集中配置变成了个性化配置。
举个例子,如果我们希望订单表t_order用 user_id 做分片健进行分库分表,但是 t_order 表中却没有 user_id 这个字段,这时可以通过 Hint API 在外部手动指定分片健或分片库。
下边我们这边给一条无分片条件的SQL,看如何指定分片健让它路由到指定库表。
SELECT * FROM t_order;
使用 Hint分片策略同样需要自定义,实现 HintShardingAlgorithm 接口并重写 doSharding()方法。
public class MyTableHintShardingAlgorithm implements HintShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> tableNames, HintShardingValue<String> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String tableName : tableNames) {
for (String shardingValue : hintShardingValue.getValues()) {
if (tableName.endsWith(String.valueOf(Long.valueOf(shardingValue) % tableNames.size()))) {
result.add(tableName);
}
}
}
return result;
}
}
- 分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度。
5.1 数据源分片策略
对应于DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
5.2 表分片策略
对应于TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。故表分片策略是依赖与数据源分片策略的结果的。
两种策略的API完全相同。
- 广播表、绑定表、逻辑表 、真实表、 数据节点 的区分
首先这些概念先搞清楚,不然容易搞混
分片
一般我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过 分库策略、分片策略 将数据分散到不同的数据库、表内。
 图片
图片
在这里插入图片描述
数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。
真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表
绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
分片键
用于分片的数据库字段。我们将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。

图片
在这里插入图片描述
这样以来同一个订单的相关数据就会存在同一个数据库表中,大幅提升数据检索的性能,不仅如此 sharding-jdbc 还支持根据多个字段作为分片健进行分片。
分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。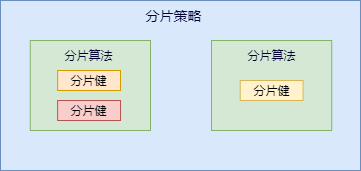
分片算法和分片策略的关系
注意:sharding-jdbc 并没有直接提供分片算法的实现,需要开发者根据业务自行实现。
7 Sharding-JDBC 分库分表基于java bean 的实际案例
7.1 添加依赖
<properties>
<sharding-sphere.version>4.0.1</sharding-sphere.version>
</properties>
<!-- for spring boot -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
7.2 应用配置
spring.shardingsphere.props.sql.show=true
logging.level.com.yisu= debug
spring.main.allow-bean-definition-overriding=true
7.3 数据源配置
import com.zaxxer.hikari.HikariDataSource;
import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.StandardShardingStrategyConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
@Configuration
public class DataSourceConfig{
/**
*
* @return
* @throws SQLException
*/
@Bean
public DataSource dataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
//相同表分片规则的组,如果表分片规则相同,则可以放在一个组里
shardingRuleConfig.getBindingTableGroups().add("sys_user");
//广播表
// shardingRuleConfig.getBroadcastTables().add("t_config");
// 根据ID分库 一共分为2个库
// shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "ds${id % 2}"));
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("tenant", "hatech_${tenant}"));
// 根据ID分表 一共分为2张表
// shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("tenant", new ShardingTableAlgorithmConfig()));
Properties properties = new Properties();
properties.setProperty("sql.show",Boolean.TRUE.toString());
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties);
}
/**
* 主键配生成配置-因用了mybatis-plus,可以不用配置
* @return
*/
// private static KeyGeneratorConfiguration getKeyGeneratorConfiguration() {
// KeyGeneratorConfiguration result = new KeyGeneratorConfiguration("SNOWFLAKE", "id");
// return result;
// }
TableRuleConfiguration getOrderTableRuleConfiguration() {
// TableRuleConfiguration result = new TableRuleConfiguration("sys_user", "hatech_tenant_it_00000${1..2}.sys_user${0..1}");
TableRuleConfiguration result = new TableRuleConfiguration("sys_user", "hatech_tenant_it_00000${1..2}.sys_user");
//TableRuleConfiguration result = new TableRuleConfiguration("sys_user", "ds${0..1}.sys_user${0..1}");
// result.setKeyGeneratorConfig(getKeyGeneratorConfiguration());
return result;
}
/**
* 创建数据源的集合
* @return
*/
Map<String, DataSource> createDataSourceMap() {
Map<String, DataSource> result = new HashMap<>();
// result.put("ds0", createDataSource("hatech_tenant_it_000001"));
// result.put("ds1", createDataSource("hatech_tenant_it_000002"));
result.put("hatech_tenant_it_000001", createDataSource("hatech_tenant_it_000001"));
result.put("hatech_tenant_it_000002", createDataSource("hatech_tenant_it_000002"));
return result;
}
/**
* 创建数据库方案
* @param dataSourceName
* @return
*/
public static DataSource createDataSource(final String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", "192.168.1.19", "3306", dataSourceName));
result.setUsername("root");
result.setPassword("root");
return result;
}
}
数据源通过动态根据数据源名称集合构建ShardingDataSource Factory;
分库规则是根据tenant字段的值自动匹配到与tenant字段结尾的数据库;
7.4 编写单元测试
import cn.hutool.core.date.DateUtil;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.google.common.collect.Lists;
import com.yisu.shardingsphere.common.model.SysUser;
import com.yisu.shardingsphere.common.service.SysUserService;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class UserinfoServiceImplReadWriteConfigTest {
@Autowired
private SysUserService sysUserService;
@Test
public void testSelect(){
int count = sysUserService.count();
System.out.println(count);
}
@Test
public void testSelectPage(){
QueryWrapper<SysUser> wrapper = new QueryWrapper<>();
// wrapper.ge("age",26);
Page<SysUser> page = new Page<>(1, 10);
Long count = sysUserService.page(page,wrapper).getSize();
System.out.println(count);
}
@Test
public void testInsert(){
SysUser sysUser=new SysUser();
sysUser.setAvatar("/home/avatar");
sysUser.setCreateTime(DateUtil.date());
sysUser.setCreateUser("sys");
sysUser.setDeleteFlag(0);
sysUser.setDeptCode("depe");
sysUser.setDisableFlag(0);
sysUser.setEmail("***@123.com");
sysUser.setPassword("123456");
sysUser.setPosCode("pos");
sysUser.setRealName("realname");
sysUser.setUpdateTime(DateUtil.date());
sysUser.setUserName("fwcloud");
sysUser.setUpdateUser("sys");
sysUser.setUserPhone("12345678912");
sysUserService.save(sysUser);
}
@Test
public void testBatchTend(){
List<String> tenantList = Lists.newArrayList("tenant_it_000001", "tenant_it_000002" );
List<SysUser> list=new ArrayList<>();
for (int i = 0; i <100 ; i++) {
SysUser sysUser=new SysUser();
sysUser.setAvatar("/home/avatar");
sysUser.setCreateTime(DateUtil.date());
sysUser.setCreateUser("sys"+i);
sysUser.setDeleteFlag(0);
sysUser.setDeptCode("depe"+i);
sysUser.setDisableFlag(0);
sysUser.setEmail("***@123.com"+i);
sysUser.setPassword("123456");
sysUser.setPosCode("pos");
sysUser.setRealName("realname"+i);
sysUser.setUpdateTime(DateUtil.date());
sysUser.setUserName("fwcloud"+i);
sysUser.setUpdateUser("sys"+i);
sysUser.setUserPhone("12345678912"+i);
sysUser.setTenant(tenantList.get(new Random().nextInt(tenantList.size())));
list.add(sysUser);
}
boolean saveBatch = sysUserService.saveBatch(list);
Assert.assertEquals(true,saveBatch);
}
@Test
public void testBatch(){
List<SysUser> list=new ArrayList<>();
for (int i = 0; i <100 ; i++) {
SysUser sysUser=new SysUser();
sysUser.setAvatar("/home/avatar");
sysUser.setCreateTime(DateUtil.date());
sysUser.setCreateUser("sys"+i);
sysUser.setDeleteFlag(0);
sysUser.setDeptCode("depe"+i);
sysUser.setDisableFlag(0);
sysUser.setEmail("***@123.com"+i);
sysUser.setPassword("123456");
sysUser.setPosCode("pos");
sysUser.setRealName("realname"+i);
sysUser.setUpdateTime(DateUtil.date());
sysUser.setUserName("fwcloud"+i);
sysUser.setUpdateUser("sys"+i);
sysUser.setUserPhone("12345678912"+i);
list.add(sysUser);
}
boolean saveBatch = sysUserService.saveBatch(list);
Assert.assertEquals(true,saveBatch);
}
}

若有收获,就点个赞吧
0 人点赞
