原文:https://blog.51cto.com/xslwahaha/1601706
HA,又称高可用,本篇只说原理。
1. 什么是高可用集群
高可用集群就是当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务。
高可用集群是用于单个节点发生故障时,能够自动将资源、服务进行切换,这样可以保证服务一直在线。在这个过程中,对于客户端来说是透明的。
2. 高可用集群的衡量标准
高可用集群一般是通过系统的可靠性(reliability)和系统的可维护性(maintainability)来衡量的。通常用平均无故障时间(MTTF)来衡量系统的可靠性,用平均维护 时间(MTTR)来衡量系统的可维护性。因此,一个高可用集群服务可以这样来定义:HA=MTTF/(MTTF+MTTR)*100%。
一般高可用集群的标准有如下几种:
99%:表示 一年宕机时间不超过4天
99.9% :表示一年宕机时间不超过10小时
99.99%: 表示一年宕机时间不超过1小时
99.999% :表示一年宕机时间不超过6分钟
3. 高可用集群的三种方式
- Message Layer:信息层,主要用户消息传递。可以提供该组件的软件包括:
- hearbeat:heartbeat 有 v1,v2,v3三个版本,目前只推荐v3。
- corosync:OpenAIS的子项目
- keepalive
- cman
- CRM:集群资源管理器,需要依赖于 Massage Layer,因此工作在其上层。每个节点上都包含一个 CRM,且每个 CRM 都维护一个 CIB(Cluster Internet Base,集群信息库),只有主节点上的 CIB 是可以修改的,其他节点上的CIB 都是从主节点上拷贝过去的。heartbeat v1,v2之前自带资源管理器,但是在 v3 版本之后,资源管理器被独立出来,形成新的项目:pacemaker。
- LRM:本地资源管理器,管理本地资源。
- DC:控制器节点(Designated controller),一般位于主节点上。
- PE:策略引擎
- TE:转移引擎(也叫执行引擎)
- stonithd:shoot the other node in the head,爆头。直接操作电源强制隔离节点。资源隔离包括:
- 节点级别
- 使用 stonithd 设备来实现
- 资源级别
- 使用 FS SAN switch 可以实现资源拒绝某些节点的访问
- 节点级别
- 共享存储:一般分为以下三种。
- DAS:Direct Attached Storage,直接附加存储
- NAS:Network Attached Storage,网络附加存储
- SAN:Storage Area Network,存储区域网络
- 资源:资源就是启动一个服务所需要的单元。资源的分类如下:
- primitive:只有在主节点上才有的资源;
- group:资源组,将多个资源加入一个群组,作为逻辑整体;
- clone:是将 primitive 资源克隆 n 份到每个节点上;
- master/slave: 也是将 primitive 克隆 2 份,其中在 master,slave 节点上各运行一份。
- 约束:控制资源的启动顺序、依赖关系。
- 位置约束:location
- 排列约束:colocation
- 顺序约束:order
- 资源转移:资源运行的节点发生改变。
- 资源粘性:指资源在此节点上运行的倾向,如果别的节点粘性高,可能转移。
- 资源代理:实际负责启动资源的脚本。常见的风格如下:
- LSB:Linux Stand Base,例如 /etc/init.d/ 下标准 Linux 脚本风格;
- OCF:Open Cluster Framwork
- Systemd
- Service:是 pacemaker 支持的一种别名服务,比如区分是源码安装还是安装包安装的资源
- Upstart
- Stonith
所以一个高可用集群服务的组件架构大概是: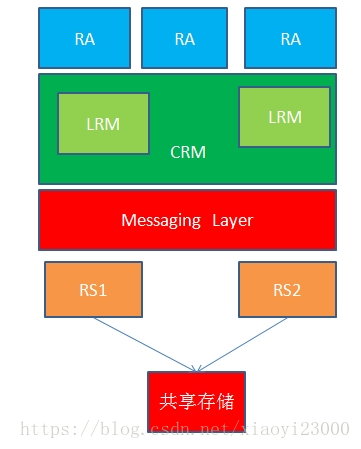

若有收获,就点个赞吧
0 人点赞
