评价指标


- 准确率(Accuracy)
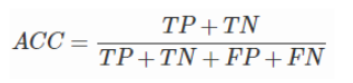
预测正确的个数占总数的比例
- 精确率(Precision)
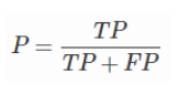
预测出的正例中有多少是真正例
- 召回率(Recall) 也称灵敏度
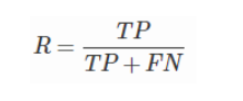
所有正例中我能正确预测出来的比例
- P-R曲线
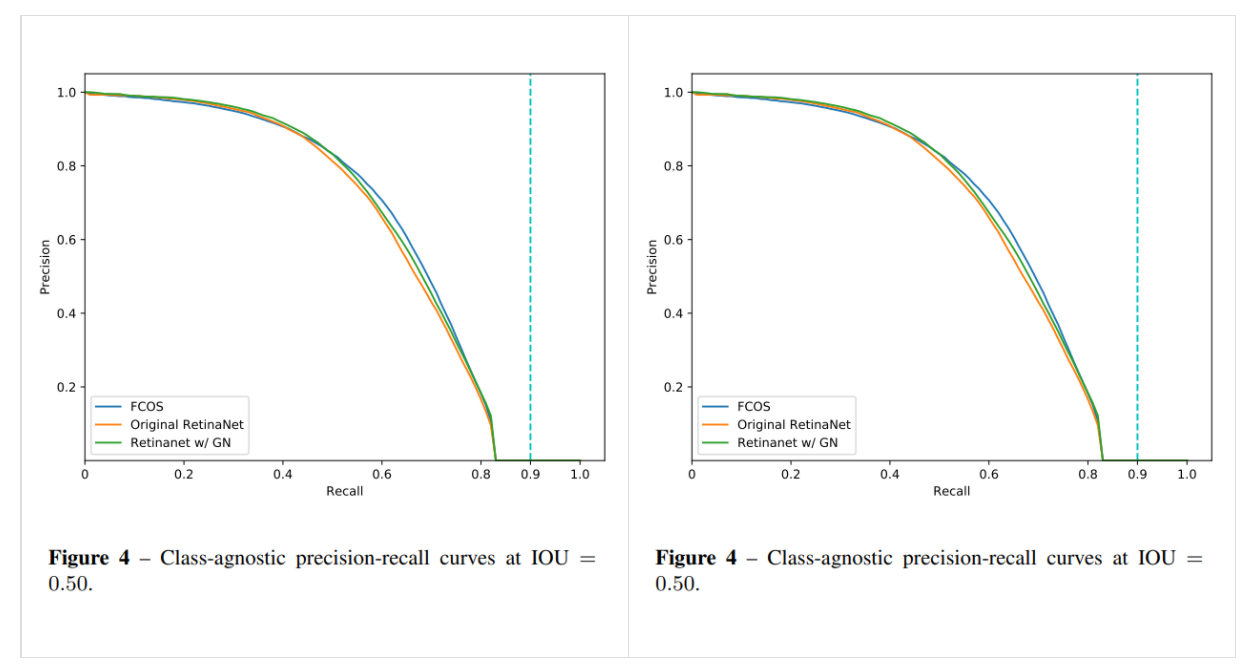
由图可知,P-R曲线是以precision为纵坐标、recall为横坐标的二维曲线,称P-R曲线(precision-recall curves)。通过在不同阈值的情况下所对应precision和recall画出此图。
准确率precision和召回率recall是一对相悖的指数,不可能做到两个指数都特别高,一边高另一边指数就低。
P-R曲线所围起来的面积就是AP值,通常来说,一个越好的检测器,AP值越高。而且一般来说,P-R曲线越靠右,包着左边的曲线,则右边这个是更好的检测器。
可以看到图中是class-agnostic P-R曲线,是分类无关曲线。实际情况中,每一类都可以根据自己的precision和recall绘制P-R曲线,而mAP值就是每一类的AP的平均值。
- IoU
IOU即交并比(Intersection-over-Union),目标检测中最常见的一个指标,用于测量预测到的bounding box和实际标注框之间的分数。值得一提的是,最近在学习anchor-free方式的目标检测,IOU在anchor-free中用的较少。
IOU表示所预测的框(bounding box,简称bbox)与原标注框(ground-truth box,简称gt box)的重合率。最理想的情况下是完全重叠,即比值为1.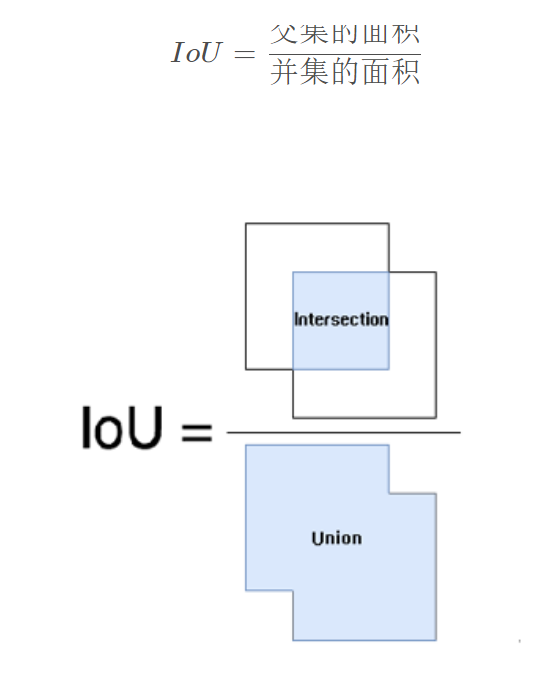
- F score

- ROC(Receiver Operating Characteristic)曲线
ROC曲线为 FPR 与 TPR 之间的关系曲线,这个组合以 FPR 对 TPR,即是以代价 (costs) 对收益 (benefits),显然收益越高,代价越低,模型的性能就越好。
为了更好地理解ROC曲线,我们使用具体的实例来说明:
如在医学诊断的主要任务是尽量把生病的人群都找出来,也就是TPR越高越好。而尽量降低没病误诊为有病的人数,也就是FPR越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的TPR应该会很高,但是FPR也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么TPR达到1,FPR也为1。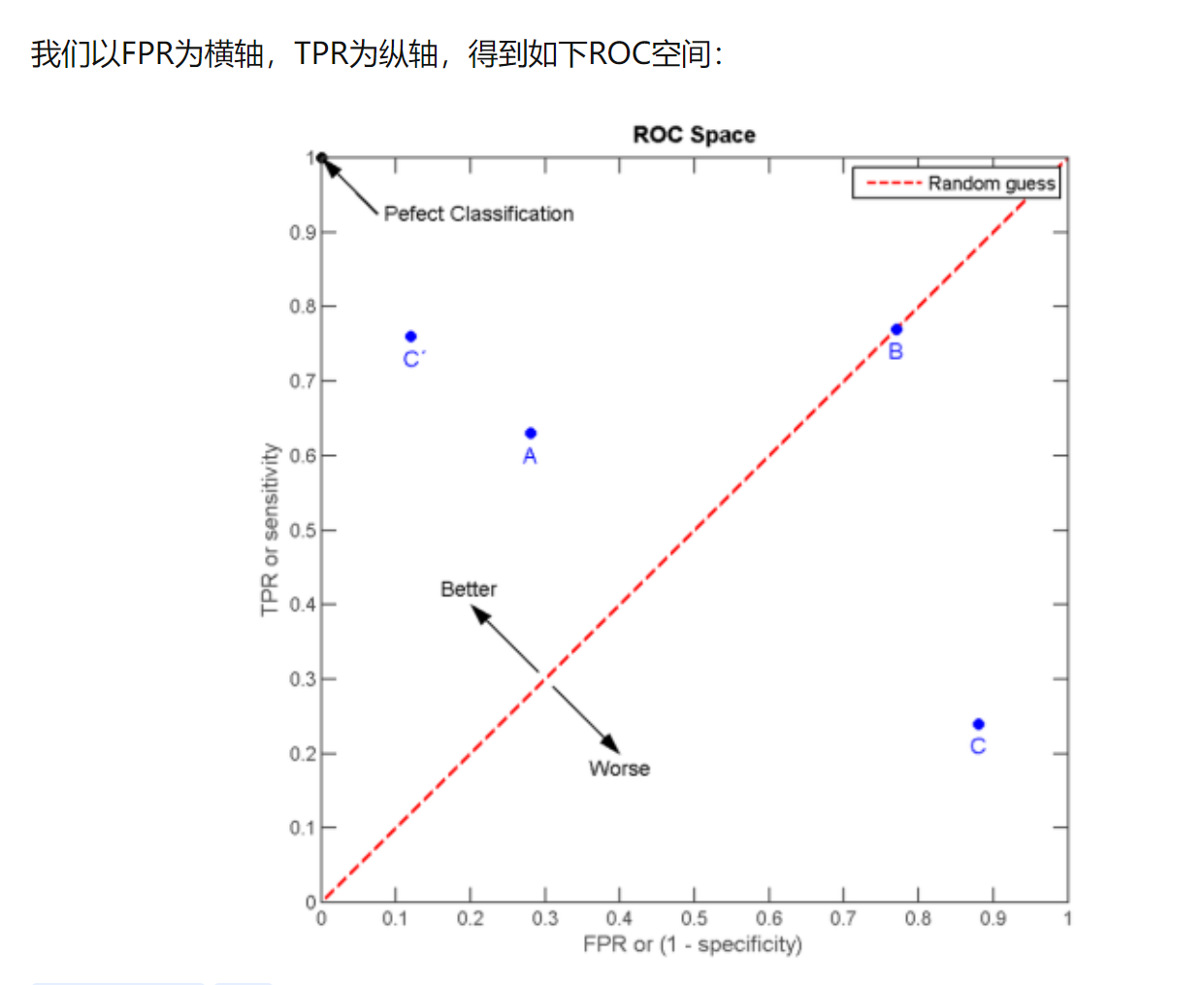
- AUC(Area Under Curve)
AUC 值为 ROC 曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器。
- 0.5 < AUC < 1,优于随机猜测。有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC的物理意义 AUC的物理意义正样本的预测结果大于负样本的预测结果的概率。所以AUC反应的是分类器对样本的排序能力。另外值得注意的是,AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。
为什么说 ROC 和AUC都能应用于非均衡的分类问题?
ROC曲线只与横坐标 (FPR) 和 纵坐标 (TPR) 有关系 。我们可以发现TPR只是正样本中预测正确的概率,而FPR只是负样本中预测错误的概率,和正负样本的比例没有关系。因此 ROC 的值与实际的正负样本比例无关,因此既可以用于均衡问题,也可以用于非均衡问题。而 AUC 的几何意义为ROC曲线下的面积,因此也和实际的正负样本比例无关。
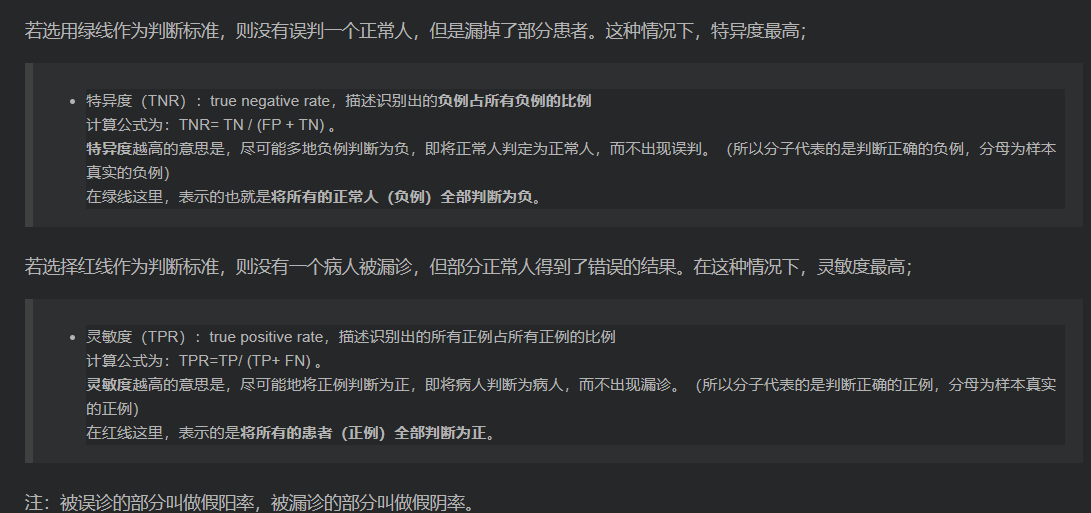
- 特异度和灵敏度
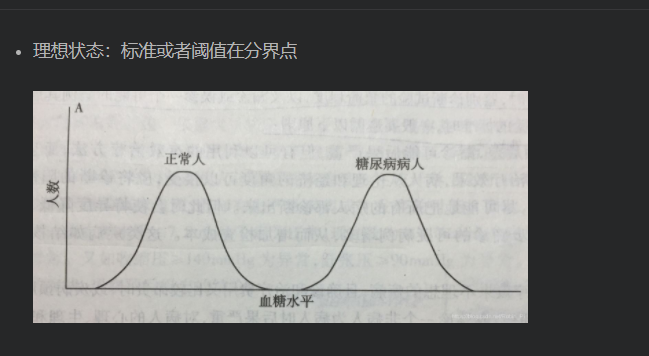

通过标准化和归一化提升各指标
当然,这也不一定就能提升。看数据,看模型
# 归一化操作X_norm1 = (X - X.min())/(X.max() - X.min())# 归一化,标准化X_norm2 = (X - X.mean())/X.std()
参考文献:
https://blog.csdn.net/Robin_Pi/article/details/106966210

若有收获,就点个赞吧
0 人点赞
