我们都知道 Spring 会根据 @ComponentScan(“xxx.xxx.xxx”) 指定的包路径,完成 bean 的扫描,那么 Spring 是如何实现扫描的呢?
@Configuration@ComponentScan("org.wesoft.spring.scan")public class AppConfig {}
scan 方法
我们先做一个实验,去掉 @ComponentScan(“org.wesoft.spring.scan”) 这个注解,利用一个 API,来完成扫描
@Configuration// @ComponentScan("org.wesoft.spring.scan")public class AppConfig {}public class App {public static void main(String[] args) {AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();ac.register(AppConfig.class);ac.scan("org.wesoft.spring.scan");ac.refresh();System.out.println(ac.getBean(TestBean.class)); // TestBean@3dd4520b}}
这里使用了 ac.scan("org.wesoft.spring.scan"); 这个 API,同样完成了 bean 的扫描,那么我们就知道 @ComponentScan(“org.wesoft.spring.scan”) 其实就是使用了 ac.scan("xxx")
scan 解析
@Overridepublic void scan(String... basePackages) {Assert.notEmpty(basePackages, "At least one base package must be specified");// 扫描 指定包 下的所有符合 spring 规则的类this.scanner.scan(basePackages);}
内部其实也调用了
this.scanner.scan(basePackages);方法,那么this.scanner这个对象是从何而来,这个对象是 Spring 初始化的时候,就对 scanner 进行了初始化,本章暂不对this.scanner进行详解,后面会有章节详细描述
public AnnotationConfigApplicationContext() {this.reader = new AnnotatedBeanDefinitionReader(this);this.scanner = new ClassPathBeanDefinitionScanner(this);}
点开 scan 方法,里面有一个 doScan(basePackages); 方法 ,这个方法完成了 bean 的扫描,在没有看 doScan 源码的情况下,我们思考一个问题,如果给我们一个包名,我们如何拿到所有的 @Component 标记的 bean 呢?
其实第一个想到的就是用 File I/O 来进行操作,递归拿到所有该包下的文件名,通过反射出对象,判断是否含有 @Component 注解
对了,其实 Spring 也就是这么做的,只是 Spring 进行了一些封装
下图是 Spring 扫描出来的该包下的所有的类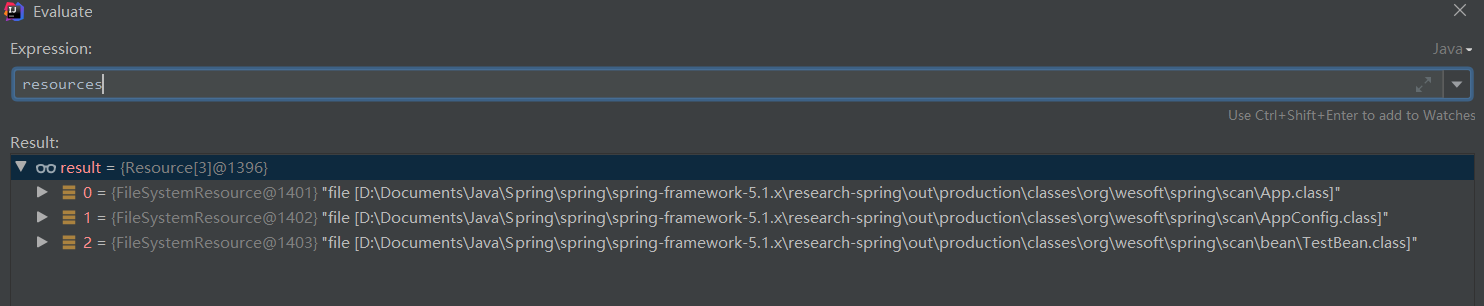
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {Assert.notEmpty(basePackages, "At least one base package must be specified");Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();for (String basePackage : basePackages) {// 关键代码,完成扫描Set<BeanDefinition> candidates = findCandidateComponents(basePackage);for (BeanDefinition candidate : candidates) {ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);candidate.setScope(scopeMetadata.getScopeName());String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);if (candidate instanceof AbstractBeanDefinition) {postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}if (candidate instanceof AnnotatedBeanDefinition) {AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}if (checkCandidate(beanName, candidate)) {BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);registerBeanDefinition(definitionHolder, this.registry);}}}return beanDefinitions;}
继续看 findCandidateComponents(basePackage) 里的代码
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {// 定义了一个存放 Spring Bean 的候选集合Set<BeanDefinition> candidates = new LinkedHashSet<>();try {// 解析 basePackage 对于的路径String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;// 解析 packageSearchPath 获取所有类Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);boolean traceEnabled = logger.isTraceEnabled();boolean debugEnabled = logger.isDebugEnabled();for (Resource resource : resources) {if (traceEnabled) {logger.trace("Scanning " + resource);}if (resource.isReadable()) {try {// 解析当前这个类所有的元数据,包括注解信息MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);// ★★★ 关键代码:判断当前类是否是符合 Spring 规则的 @Componentif (isCandidateComponent(metadataReader)) {// ★ 创建了 ScannedGenericBeanDefinition// ★ 这里就证明了通过注解扫描出来的类都是 ScannedGenericBeanDefinitionScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setResource(resource);sbd.setSource(resource);// ★★★ 关键代码:返回是(是否一个独立的类(可以通过构造函数创建)并且 不能是接口和抽象类)或者(是一个抽象类,并且 有 Lookup 注解)if (isCandidateComponent(sbd)) {if (debugEnabled) {logger.debug("Identified candidate component class: " + resource);}// ★ 加入到候选集合中candidates.add(sbd);}else {if (debugEnabled) {logger.debug("Ignored because not a concrete top-level class: " + resource);}}}else {if (traceEnabled) {logger.trace("Ignored because not matching any filter: " + resource);}}}catch (Throwable ex) {throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, ex);}}else {if (traceEnabled) {logger.trace("Ignored because not readable: " + resource);}}}}catch (IOException ex) {throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);}return candidates;}
代码中有一段逻辑 isCandidateComponent(metadataReader) ,是判断是否是 Spring bean 的关键方法,其中有一个 this.includeFilters 包含了两个注解,一个是 @Component 和 @ManagedBean,其中 @ManagedBean 是 JSR-250 的规范,同样可以让 Spring 扫描到
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {for (TypeFilter tf : this.excludeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return false;}}// 判断是否是 Spring 所需要的类型 @Componentfor (TypeFilter tf : this.includeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return isConditionMatch(metadataReader);}}return false;}
看到这里,是否有一个疑问?那么这样,如果我们提供了一个自定义注解,然后放到 this.includeFilters 中,不就可以扩展 Spring 了么?
没错,下面的文章,我们就会自定义一些注解,加入到
this.includeFilters中,让 Spring 帮助我们扫描
上述代码中,我已经详细描述了 Spring 是如何扫描 @Component 注解的类了,并加入到 candidates 集合中
小结
也就是 Spring 会通过 I/O 读取 basePackage 下所有的类,然后进行判断(是否是一个独立的类(可以通过构造函数创建)并且 不能是接口和抽象类)或者(是一个抽象类,并且 有 Lookup 注解),如果符合要求,就加入 **candidates 集合**中,供后续逻辑执行
自定义 @MyComponent 注解
我们自定义注解一个注解 @MyComponent,让 Spring 帮助我们完成扫描,放入单例池,上面的文章也说了,关键就是让 Spring 认识我们提供的注解,核心就是 this.includeFilters 里面需要包含我们的注解,那么怎么给 includeFilters 添加注解呢?我们先看看 Spring 是怎么做的
public AnnotationConfigApplicationContext() {this.reader = new AnnotatedBeanDefinitionReader(this);this.scanner = new ClassPathBeanDefinitionScanner(this);}
Spring 在初始化的时候,就直接 new ClassPathBeanDefinitionScanner(this) 来给 scanner,同时,在 new ClassPathBeanDefinitionScanner 的时候又初始化了默认的 Filters, registerDefaultFilters();
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,Environment environment, @Nullable ResourceLoader resourceLoader) {Assert.notNull(registry, "BeanDefinitionRegistry must not be null");this.registry = registry;// 关键代码:useDefaultFilters 默认为 trueif (useDefaultFilters) {// 注册默认的过滤器,一般情况下会注册两个默认过滤器// 1、Component Filter// 2、ManagedBean Filter// 如果使用了 JSR-330 'javax.inject.Named' ,则会再注册一个 Named FilterregisterDefaultFilters();}setEnvironment(environment);setResourceLoader(resourceLoader);}
其中 registerDefaultFilters 方法,就注册了 @Component,并尝试中注册 @ManagedBean 和 @Named
protected void registerDefaultFilters() {// 注册默认过滤器// 这里传了一个 Component.class// 后续 spring 扫描出来一个 resource 以后需要判断它是否合理,这里的代码非常重要this.includeFilters.add(new AnnotationTypeFilter(Component.class));ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();// 尝试注册 @ManagedBean,这是 JSR-250 的 APItry {this.includeFilters.add(new AnnotationTypeFilter(((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");}catch (ClassNotFoundException ex) {// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.}// 尝试注册 @Named,这是 JSR-330 的 APItry {this.includeFilters.add(new AnnotationTypeFilter(((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");}catch (ClassNotFoundException ex) {// JSR-330 API not available - simply skip.}}
所以,我们可以看到,其实关键代码就是
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
实现步骤
看到这里,其实实现起来就比较简单了,我们可以直接使用 ClassPathBeanDefinitionScanner 中的 addIncludeFilter 方法,就可以完成 filter 的添加
如有特殊需求,也可以写一个类继承 ClassPathBeanDefinitionScanner
@MyComponentpublic class CustomTestBean {}@MyComponentpublic class CustomBean {public CustomBean(CustomTestBean customTestBean) {System.out.println(customTestBean);}}ClassPathBeanDefinitionScanner customScanner = new ClassPathBeanDefinitionScanner(ac);customScanner.addIncludeFilter(new AnnotationTypeFilter(MyComponent.class));int scan = customScanner.scan("org.wesoft.spring.scan");System.out.println(scan); // 扫描到符合要求 bean 的数量// org.wesoft.spring.scan.bean.TestBean@5ae63ade// 2
自定义 MyBatis 的 MapperScanner 注解
其实 MyBatis 的 MapperScanner 也是对 includeFilters 做了一些手脚,重写了 filter 的 match 方法,让他永远返回 true,同时,判断是一个接口
@Overrideprotected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {addIncludeFilter(new TypeFilter() {@Overridepublic boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException {return true;}});return beanDefinition.getMetadata().isInterface();}

若有收获,就点个赞吧
0 人点赞
