项目一 爬取雨课堂视频
目标网站url : https://changjiang.yuketang.cn/v2/web/playback/5183588/slide/2/0
说明
使用模块
import requestsfrom bs4 import BeautifulSoupimport reimport asyncioimport aiohttpimport aiofilesfrom Crypto.Cipher import AES # pycryptodomeimport os
分析
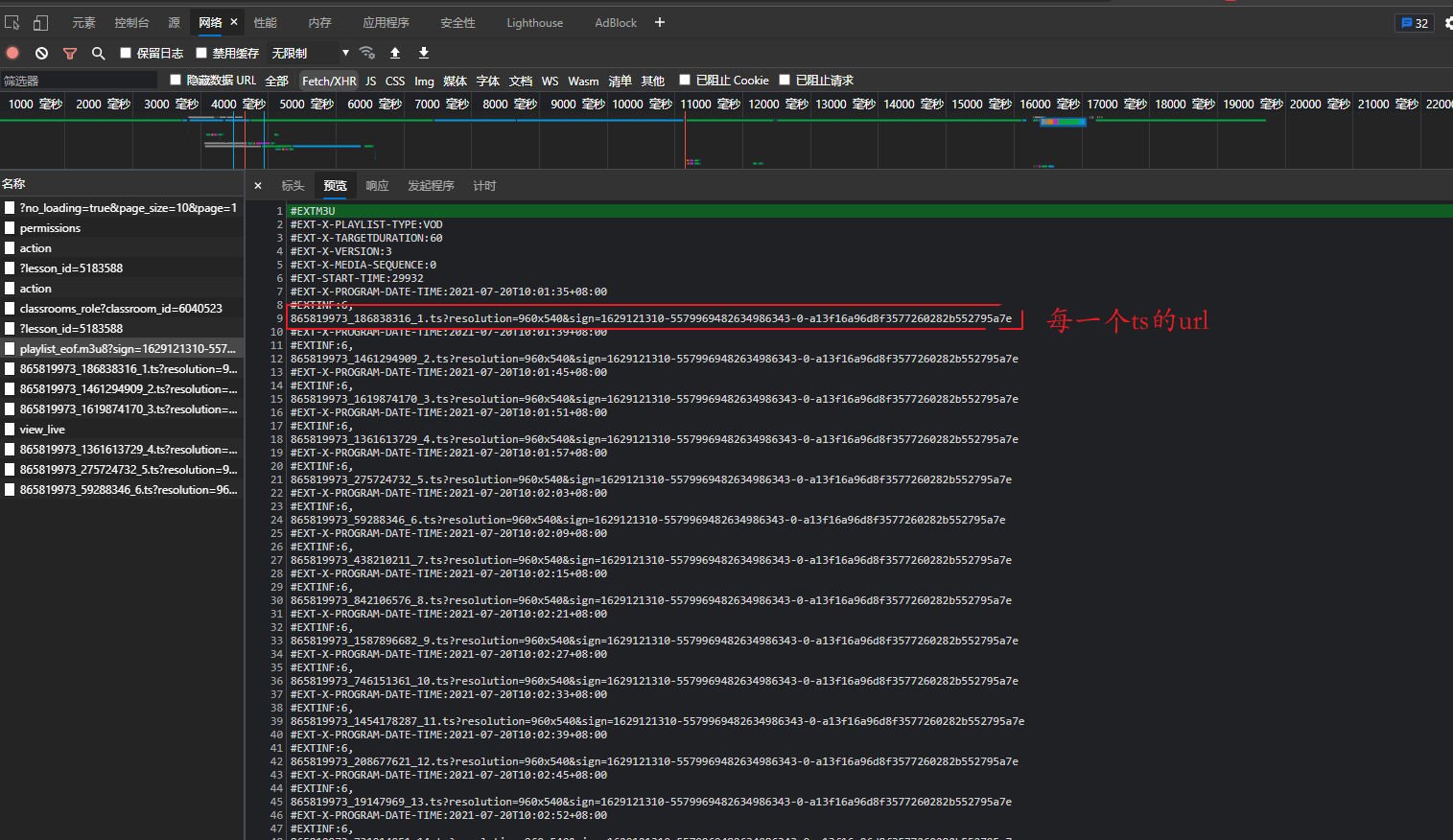
通过抓包工具分析,只要得到m3u8文件,就可以获得每一个ts文件的url,我们通过异步协程的方式下载视频的每一小段,最后合并到一起,便可以得到整个视频.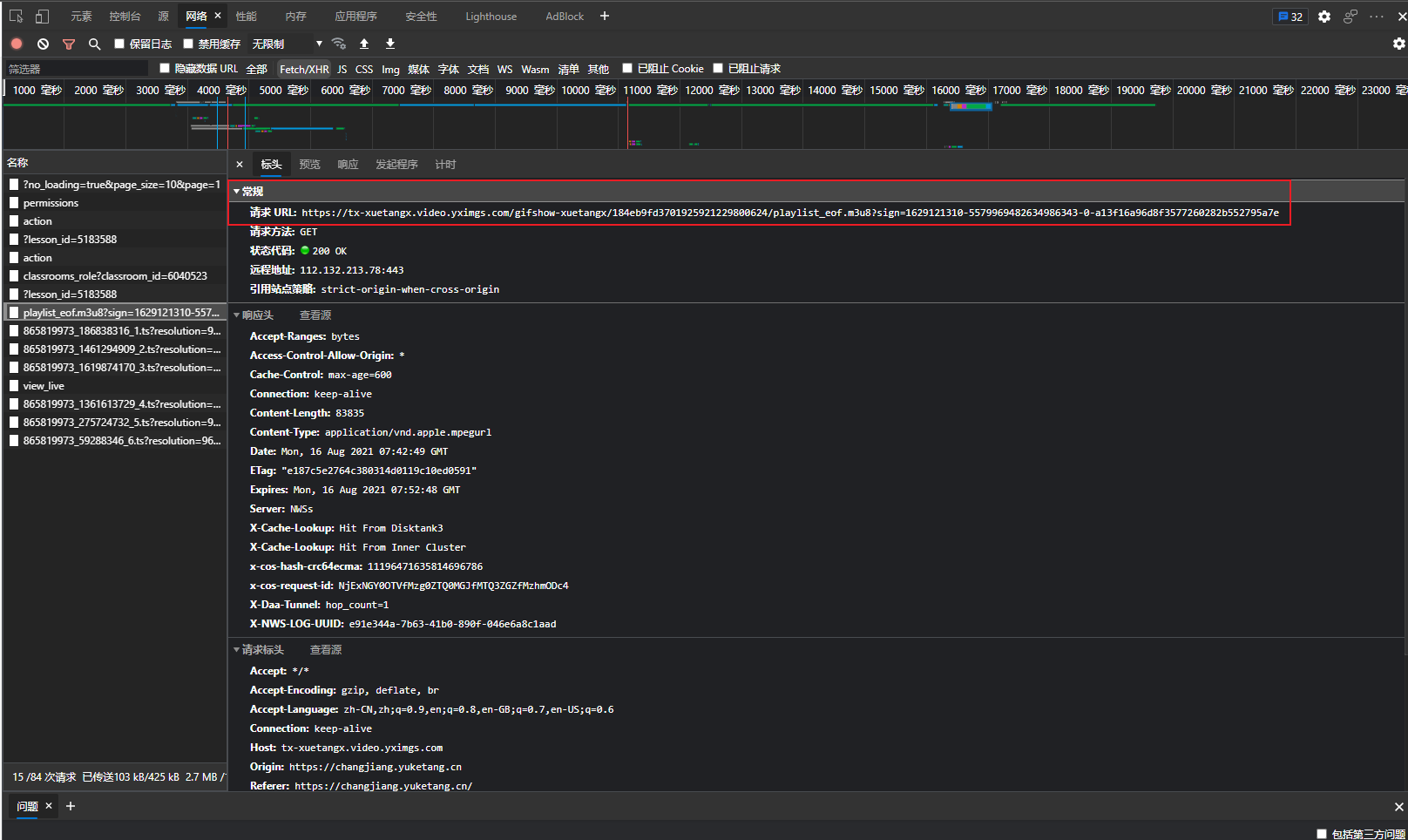
反爬手段
使用加headers,如referer防盗链的处理,给出该网页上级网页url,可以实现应对反爬虫.
headers = {'User - Agent': "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 92.0.4515.131 Safari / 537.36 Edg / 92.0.902.73",'Referer': 'https: // changjiang.yuketang.cn /'}resp = requests.get(url,headers=headers)
代码
若m3u8中采取了数据加密,则需要想要的解密过程.
协程:
一般情况下, 当程序处于 IO操作的时候. 线程都会处于阻塞状态
协程: 当程序遇见了IO操作的时候. 可以选择性的切换到其他任务上.
在微观上是一个任务一个任务的进行切换. 切换条件一般就是IO操作
在宏观上,我们能看到的其实是多个任务一起在执行
多任务异步操作
import requestsfrom bs4 import BeautifulSoupimport reimport asyncioimport aiohttpimport aiofilesfrom Crypto.Cipher import AES # pycryptodomeimport osdef download_m3u8_file(url, name):headers = {'User - Agent': "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 92.0.4515.131 Safari / 537.36 Edg / 92.0.902.73",'Referer': 'https: // changjiang.yuketang.cn /'}resp = requests.get(url,headers=headers)with open(name, mode="wb") as f:f.write(resp.content)async def download_ts(url, name, session):async with session.get(url) as resp:async with aiofiles.open(f"test/{name}", mode="wb") as f:await f.write(await resp.content.read()) # 把下载到的内容写入到文件中#print(f"{name}下载完毕")async def aio_download(up_url):tasks = []async with aiohttp.ClientSession() as session: # 提前准备好sessionasync with aiofiles.open("test.m3u8", mode="r", encoding='utf-8') as f:n=1async for line in f:if line.startswith("#"):continue# line就是xxxxx.tsline = line.strip() # 去掉没用的空格和换行# 拼接真正的ts路径ts_url = up_url + linename=str(n)+'.ts'task = asyncio.create_task(download_ts(ts_url, name, session)) # 创建任务tasks.append(task)n=n+1await asyncio.wait(tasks) # 等待任务结束def merge_ts():# mac: cat 1.ts 2.ts 3.ts > xxx.mp4# windows: copy /b 1.ts+2.ts+3.ts xxx.mp4print("here3")lst = []with open("test.m3u8", mode="r", encoding="utf-8") as f:n=1for line in f:if line.startswith("#"):continuename=str(n)+'.ts'lst.append(f"test\{name}")n=n+1s = "+".join(lst) # 1.ts 2.ts 3.tsprint(s)os.system(f"copy /b {s} test.ts")print("搞定!")remove()def remove():path = './test'for i in os.listdir(path):path_file = os.path.join(path, i)if os.path.isfile(path_file):os.remove(path_file)else:for f in os.listdir(path_file):path_file2 = os.path.join(path_file, f)if os.path.isfile(path_file2):os.remove(path_file2)def get_key(url):headers={'user - agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 92.0.4515.107 Safari / 537.36 Edg / 92.0.902.55','referer': 'https: // www.acwing.com /'}resp = requests.get(url,headers=headers)return resp.textasync def dec_ts(name, key):aes = AES.new(key=key, IV=b"0000000000000000", mode=AES.MODE_CBC)async with aiofiles.open(f"test/{name}", mode="rb") as f1,\aiofiles.open(f"test/temp_{name}", mode="wb") as f2:bs = await f1.read() # 从源文件读取内容await f2.write(aes.decrypt(bs)) # 把解密好的内容写入文件print(f"{name}处理完毕")async def aio_dec(key):# 解密tasks = []async with aiofiles.open("test.m3u8", mode="r", encoding="utf-8") as f:n=1async for line in f:if line.startswith("#"):continueline = line.strip()# 开始创建异步任务name=str(n)+'.ts'task = asyncio.create_task(dec_ts(name, key))tasks.append(task)n=n+1await asyncio.wait(tasks)if __name__=='__main__':m3u8url="https://tx-xuetangx.video.yximgs.com/gifshow-xuetangx/184eb9fd3701925921229800624/playlist_eof.m3u8?sign=1629121310-5579969482634986343-0-a13f16a96d8f3577260282b552795a7e"up='https://tx-xuetangx.video.yximgs.com/gifshow-xuetangx/184eb9fd3701925921229800624/'download_m3u8_file(m3u8url,"test.m3u8")asyncio.run(aio_download(up))merge_ts()
数据说明
获取m3u8文件
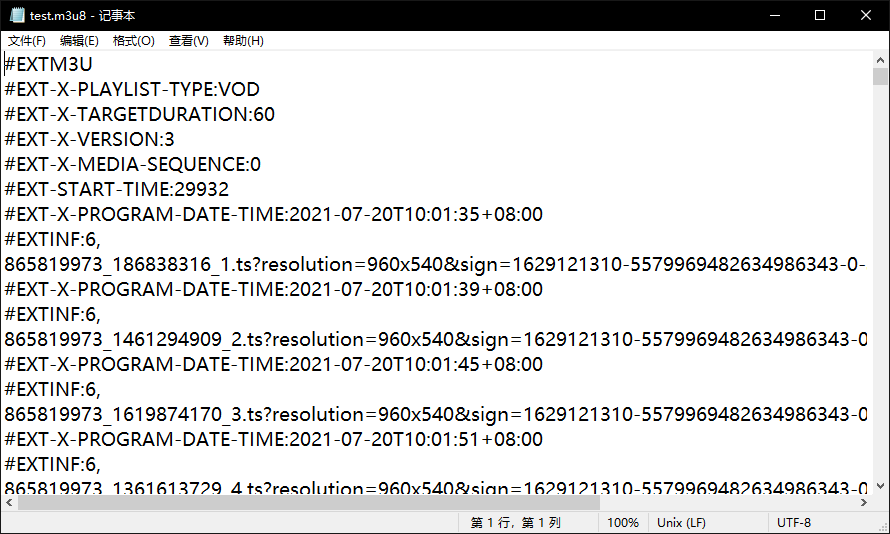
获取每一个ts文件
合并为整段视频
项目二 使用scrapy爬取图片
说明
源页面
反爬手段

模块
import scrapyfrom imgsPro.items import ImgsproItem
分析
图片数据爬取之ImagesPipeline
- 基于scrapy爬取字符串类型的数据和爬取图片类型的数据区别?
- 字符串:只需要基于xpath进行解析且提交管道进行持久化存储
- 图片:xpath解析出图片src的属性值。单独的对图片地址发起请求获取图片二进制类型的数据- ImagesPipeline:
- 只需要将img的src的属性值进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制类型的数据,且还会帮我们进行持久化存储。
- 需求:爬取站长素材中的高清图片
- 使用流程:
- 数据解析(图片的地址)
- 将存储图片地址的item提交到制定的管道类
- 在管道文件中自定制一个基于ImagesPipeLine的一个管道类
- get_media_request
- file_path
- item_completed
- 在配置文件中:
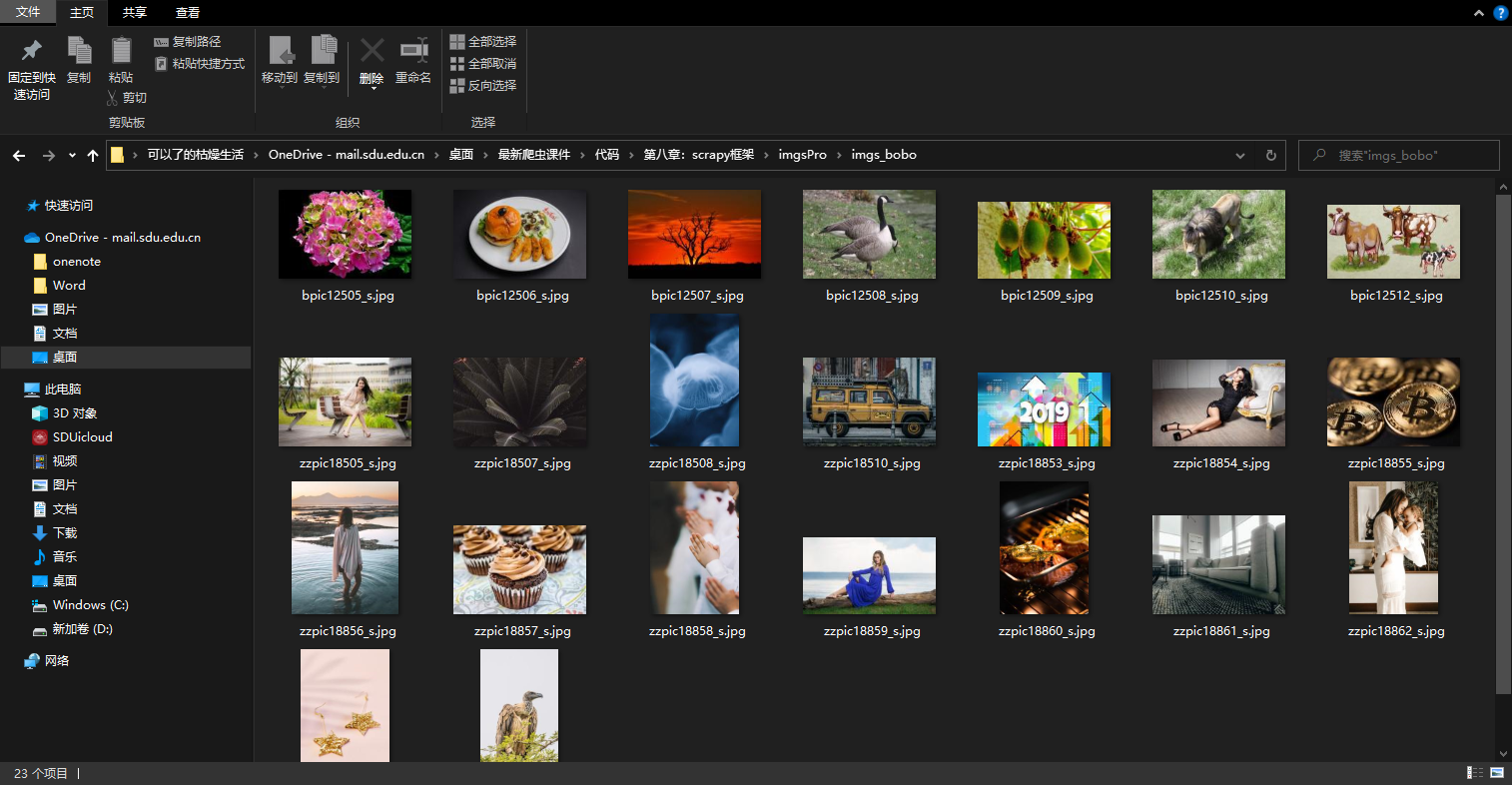
- 指定图片存储的目录:IMAGES_STORE = ‘./imgs_bobo’
- 指定开启的管道:自定制的管道类数据
项目3 爬取小说
说明
url: http://dushu.baidu.com/api/pc/getCatalog?data={“book_id”:”4315647161”}分析
通过目录获取各个章节的url,通过异步协程的方式分别爬取每个章节,通过xpath解析出正文内容,保存到txt中。数据
- ImagesPipeline:

若有收获,就点个赞吧
0 人点赞
