从人工智能到NLP
人工智能:为机器赋予人的智能
早在1956年夏天那次会议,人工智能的先驱们就梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。这就是我们现在所说的“强人工智能”(General AI)。这个无所不能的机器,它有着我们所有的感知(甚至比人更多),我们所有的理性,可以像我们一样思考。
我们目前能实现的,一般被称为“弱人工智能”(Narrow AI)。弱人工智能是能够与人一样,甚至比人更好地执行特定任务的技术。例如,Pinterest上的图像分类;或者Facebook的人脸识别。这些是弱人工智能在实践中的例子。这些技术实现的是人类智能的一些具体的局部。但它们是如何实现的?这种智能是从何而来?这就带我们来到下一层,机器学习。
机器学习:一种实现人工智能的方法
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
机器学习最成功的应用领域是计算机视觉,虽然也还是需要大量的手工编码来完成工作。人们需要手工编写分类器、边缘检测滤波器,以便让程序能识别物体从哪里开始,到哪里结束;写形状检测程序来判断检测对象是不是有八条边;写分类器来识别字母“STOP”。使用以上这些手工编写的分类器,人们总算可以开发算法来感知图像,判断图像是不是一个停止标志牌。
机器学习有三类:
第一类是无监督学习,指的是从信息出发自动寻找规律,并将其分成各种类别,有时也称”聚类问题”。
第二类是监督学习,监督学习指的是给历史一个标签,运用模型预测结果。如有一个水果,我们根据水果的形状和颜色去判断到底是香蕉还是苹果,这就是一个监督学习的例子。
最后一类为强化学习,是指可以用来支持人们去做决策和规划的一个学习方式,它是对人的一些动作、行为产生奖励的回馈机制,通过这个回馈机制促进学习,这与人类的学习相似,所以强化学习是目前研究的重要方向之一。
深度学习:一种实现机器学习的技术
机器学习同深度学习之间是有区别的,机器学习是指计算机的算法能够像人一样,从数据中找到信息,从而学习一些规律。虽然深度学习是机器学习的一种,但深度学习是利用深度的神经网络,将模型处理得更为复杂,从而使模型对数据的理解更加深入。
深度学习是机器学习中一种基于对数据进行表征学习的方法。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分。不同的学习框架下建立的学习模型很是不同。例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。
自然语言处理
自然语言处理是指利用人类交流所使用的自然语言与机器进行交互通讯的技术。通过人为的对自然语言的处理,使得计算机对其能够可读并理解。自然语言处理的相关研究始于人类对机器翻译的探索。虽然自然语言处理涉及语音、语法、语义、语用等多维度的操作,但简单而言,自然语言处理的基本任务是基于本体词典、词频统计、上下文语义分析等方式对待处理语料进行分词,形成以最小词性为单位,且富含语义的词项单元。
发展阶段
- 早期自然语言处理:基于规则
- 统计自然语言处理:基于统计的机器学习
- 神经网络自然语言处理:基于深度学习计算特征和建模
相关技术
神经网络语言模型(NNLM)
神经网络语言模型(Neural Network Language Model,NNLM)最早由 Bengio 等人[27]提出,其核心思路是用一个 K 维的向量来表示词语,被称为词向量( Word Embedding),使得语义相似的词在向量空间中处于相近的位置,并基于神经网络模型将输入的上下文词向量序列转换成成固定长度的上下文隐藏向量,使得语言模型不必存储所有不同词语的排列组合信息,从而改进传统语言模型受词典规模限制的不足。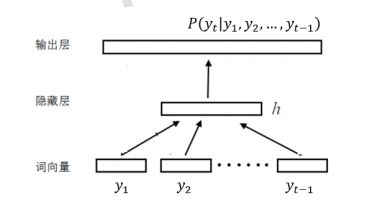
自编码器(AE)
自编码器(Autoencoder, AE)是一种无监督的学习模型,由 Rumelhart 等人[28]最早提出。自编码器由编码器和解码器两部分组成,先用编码器对输入数据进行压缩,将高维数据映射到低维空间,再用解码器解压缩,对输入数据进行还原,从而来实现输入到输出的复现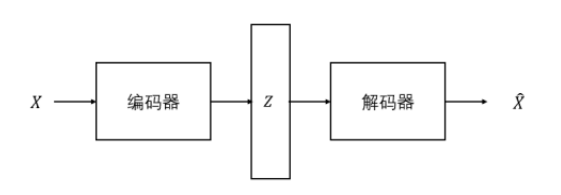
卷积神经网络(CNN)
核心思想是设计局部特征抽取器运用到全局,利用空间相对关系共享参数,来提高训练性能。
卷积层和池化层是卷积神经网络的重要组成部分。其中,卷积层的作用是从固定大小的窗口中读取输入层数据,经过卷积计算,实现特征提取。卷积神经网络在同一层共享卷积计算模型来控制参数规模,降低模型复杂度。池化层的作用是对特征信号进行抽象,用于缩减输入数据的规模,按一定方法将特征压缩。池化的方法包括加和池化、最大池化、均值池化、最小值池化和随机池化。最后一个池化层通常连接到全连接层,来计算最终的输出。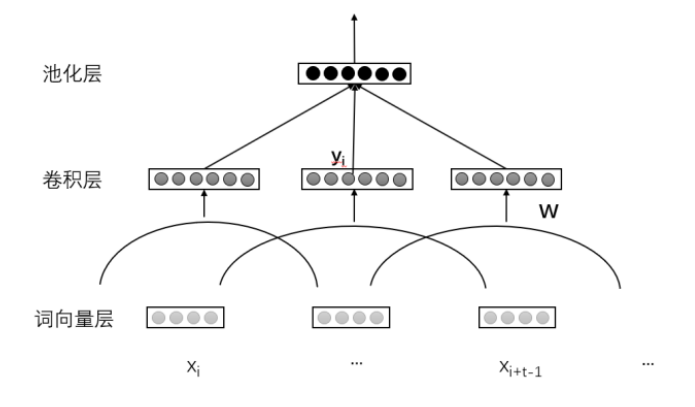
循环神经网络(RNN)
自环的网络对前面 的信息进行记忆并应用于当前输出的计算中,即当前时刻隐藏层的输入包括输入层变量和上一时刻的隐藏层变量。
由于可以无限循环,所以理论上循环神经网络能够对任何长度的序列数据进行处理。
循环神经网络在实际应用时有梯度消失等问题。后来提出了LSTM和GRU解决这一问题。
Seq2Seq
编码器-解码器模型
输入一个序列,输出另一个序列。
基本模型利用两个RNN:一个循环神经网络作为编码器,将输入序列转换成定长的向量,将向量视为输
入序列的语义表示;另一个循环神经网络作为解码器,根据输入序列的语义表示生成输出序列。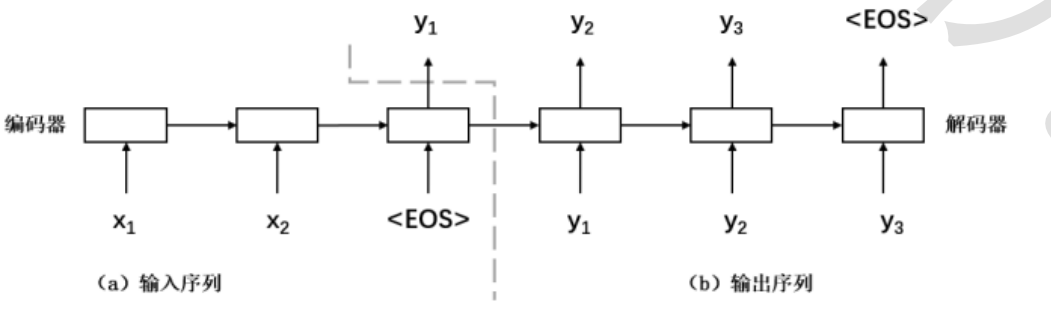
注意力机制
注意力机制可以理解为回溯策略。它在当前解码时刻,将解码器 RNN 前一个时刻的隐藏向量与输入序列关联起来,计算输入的每一步对当前解码的影响程度作为权重。通过 softmax 函数归一化,得到概率分布权重对输入序列做加权,重点考虑输入数据中对当前解码影响最大的输入词。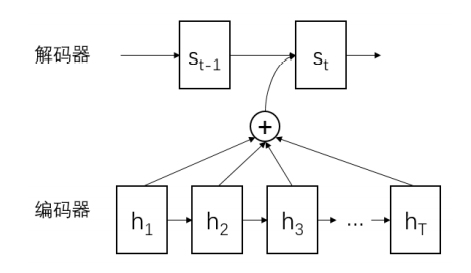
自注意力机制,多头注意力机制
强化学习
观察值,奖励,动作一起构成智能体的经验数据。
智能体的目标是依据经验获取最大累计奖励。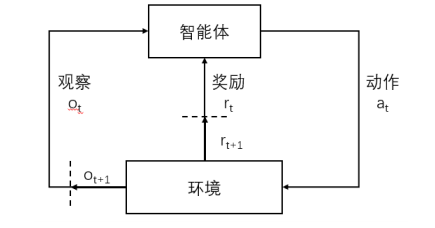
Transformer模型
Pytorch入门
从0到1实现两层全连接神经网络
- 完全使用numpy实现
```python
两层全连接神经网络
使用numpy
import numpy as np N,D_in,H,D_out=64,1000,100,10随机生成训练数据
x=np.random.randn(N,D_in) y=np.random.randn(N,D_out)
w1=np.random.randn(D_in,H) w2=np.random.randn(H,D_out)
lr=1e-6 for it in range(500):
#Forward passh=x.dot(w1)h_relu=np.maximum(h,0)#激活函数y_pred=h_relu.dot(w2)#预测y#lossloss=np.square(y_pred - y).sum()print(it,loss)#Backward pass#compute the gardientgrad_y_pred=2.0*(y_pred-y)grad_w2=h_relu.T.dot(grad_y_pred)grad_h_relu=grad_y_pred.dot(w2.T)grad_h=grad_h_relugrad_h[h<0]=0grad_w1=x.T.dot(grad_h).copy()#updatew1 -= lr*grad_w1w2 -= lr*grad_w2
2. **仅替换为torch中对应的函数,如mm表示矩阵乘,clamp(min=0)表示激活函数**```python#改成torch版本import torch#两层全连接神经网络#使用numpyimport numpy as npN,D_in,H,D_out=64,1000,100,10#随机生成训练数据x=torch.randn(N,D_in)y=torch.randn(N,D_out)w1=torch.randn(D_in,H)w2=torch.randn(H,D_out)lr=1e-6for it in range(500):#Forward passh=x.mm(w1)#矩阵的乘h_relu=h.clamp(min=0)#激活函数y_pred=h_relu.mm(w2)#预测y#lossloss=(y_pred - y).pow(2).sum().item()print(it,loss)#Backward pass#compute the gardientgrad_y_pred=2.0*(y_pred-y)grad_w2=h_relu.t().mm(grad_y_pred)grad_h_relu=grad_y_pred.mm(w2.t())grad_h=grad_h_relugrad_h[h<0]=0grad_w1=x.t().mm(grad_h).clone()#updatew1 -= lr*grad_w1w2 -= lr*grad_w2
import torch
两层全连接神经网络
import numpy as np N,D_in,H,D_out=64,1000,100,10
随机生成训练数据
x=torch.randn(N,D_in) y=torch.randn(N,D_out)
w1=torch.randn(D_in,H,requires_grad=True) w2=torch.randn(H,D_out,requires_grad=True)
lr=1e-6 for it in range(500):
#Forward passy_pred=x.mm(w1).clamp(min=0).mm(w2)#lossloss=(y_pred - y).pow(2).sum()print(it,loss.item())#Backward pass#compute the gardientloss.backward()#updatewith torch.no_grad(): #声明不是计算图,可以节省内存w1 -= lr*w1.gradw2 -= lr*w2.gradw1.grad.zero_()#梯度清零w2.grad.zero_()
4. **引入pytorch中封装好的nn.Sequential模型**```python#改成torch带有nn.Sequential的版本!!!import torchimport torch.nn as nnN,D_in,H,D_out=64,1000,100,10#随机生成训练数据x=torch.randn(N,D_in)y=torch.randn(N,D_out)model=nn.Sequential(nn.Linear(D_in,H,bias=False),nn.ReLU(),nn.Linear(H,D_out),)#如果不初始化权重为正态分布,效果很会差nn.init.normal_(model[0].weight)nn.init.normal_(model[2].weight)loss_fn=nn.MSELoss(reduction='sum')#model=model.cuda()lr=1e-6for it in range(500):#Forward passy_pred=model(x)#lossloss=loss_fn(y_pred , y)print(it,loss.item())#Backward pass#compute the gardientloss.backward()#updatewith torch.no_grad():for param in model.parameters():param -= lr * param.gradmodel.zero_grad()#清零所有的参数
import torch import torch.nn as nn N,D_in,H,D_out=64,1000,100,10
随机生成训练数据
x=torch.randn(N,D_in) y=torch.randn(N,D_out)
model=nn.Sequential( nn.Linear(D_in,H,bias=False), nn.ReLU(),#激活函数 nn.Linear(H,D_out), )
nn.init.normal(model[0].weight) nn.init.normal(model[2].weight)
loss_fn=nn.MSELoss(reduction=’sum’)
model=model.cuda()
lr=1e-4
optmizer=torch.optim.Adam(model.parameters(),lr=lr)#此时不需要手动更新,参数群全部放进optm,自动更新
lr=1e-6 optmizer=torch.optim.SGD(model.parameters(),lr=lr)#此时不需要手动更新,参数群全部放进optm,自动更新
for it in range(500):
#Forward passy_pred=model(x)#lossloss=loss_fn(y_pred , y)print(it,loss.item())optmizer.zero_grad()#求导之前清零#Backward passloss.backward()#求导#更新optmizer.step()#求导之后更新
6. **实现将定义的模型封装在class中:主要包括__init__()和forward()两个方法的定义**```python#使用class声明模型 从Module中继承模型,定义更复杂的模型import torchimport torch.nn as nnN,D_in,H,D_out=64,1000,100,10#随机生成训练数据x=torch.randn(N,D_in)y=torch.randn(N,D_out)class TwoLayerNet(nn.Module):def __init__(self,D_in,H,D_out):super(TwoLayerNet,self).__init__()self.linear1=nn.Linear(D_in,H,bias=False)self.linear2=nn.Linear(H,D_out,bias=False)def forward(self,x):y_pred=self.linear2(self.linear1(x).clamp(min=0))return y_predmodel=TwoLayerNet(D_in,H,D_out)loss_fn=nn.MSELoss(reduction='sum')#model=model.cuda()lr=1e-4optmizer=torch.optim.Adam(model.parameters(),lr=lr)#此时不需要手动更新,参数群全部放进optm,自动更新for it in range(500):#Forward passy_pred=model(x)#lossloss=loss_fn(y_pred , y)print(it,loss.item())optmizer.zero_grad()#求导之前清零#Backward passloss.backward()#求导#更新optmizer.step()#求导之后更新
FizzBuzz利用神经网络训练
#FizzBuzzdef fizz_buss_encode(i):if i%15==0:return 3elif i%5==0:return 2elif i%3==0:return 1else:return 0def fizz_buzz_decode(i,predict):return [str(i),'fizz','buzz','fizzbuzz'][predict]def helper(i):print(fizz_buzz_decode(i,fizz_buss_encode(i)))for i in range(1,30):helper(i)import numpy as npimport torchNUM_DIDITS = 10def binary_encode(i,num_digits):return np.array([i>>d & 1 for d in range(num_digits)][::-1])#binary_encode(15,NUM_DIDITS)#训练数据trX=torch.Tensor([binary_encode(i,NUM_DIDITS) for i in range(101,2**NUM_DIDITS)])trY=torch.LongTensor([ fizz_buss_encode(i) for i in range(101,2**NUM_DIDITS)])NUM_HIDDEN=100model=nn.Sequential(nn.Linear(NUM_DIDITS,NUM_HIDDEN),nn.ReLU(),nn.Linear(NUM_HIDDEN,4),)if torch.cuda.is_available():model=model.cuda()loss_fn=torch.nn.CrossEntropyLoss()#四分类问题,需要用交叉验证optimizer=torch.optim.SGD(model.parameters(),lr=0.01)BATCH_SIZE=128for epoch in range(10000):for start in range(0,len(trX),BATCH_SIZE):end=start+BATCH_SIZEbatchX=trX[start:end]batchY=trY[start:end]if torch.cuda.is_available():batchX=batchX.cuda()batchY=batchY.cuda()y_pred=model(batchX) #forwardloss=loss_fn(y_pred,batchY)print("Epoch",epoch,loss.item())optimizer.zero_grad()loss.backward() #backpassoptimizer.step() #gradient descent#测试训练效果#101以上的数据为训练数据,100以内为测试数据testX=torch.Tensor([binary_encode(i,NUM_DIDITS) for i in range(1,101)])with torch.no_grad():testY=model(testX)testY.max(1)[1].data.tolist()predictions=zip(range(0,101),testY.max(1)[1].data.tolist())print([fizz_buzz_decode(i,x)for i,x in predictions ])
Mnist数据集的识别
mnist数据识别简单程序
import numpy as npfrom torch import nn,optimfrom torch.autograd import Variablefrom torchvision import datasets, transformsfrom torch.utils.data import DataLoaderimport torch# 训练集train_dataset = datasets.MNIST(root='./',train=True,transform=transforms.ToTensor(),download=True)# 测试集test_dataset = datasets.MNIST(root='./',train=False,transform=transforms.ToTensor(),download=True)# 批次大小,每次训练传入64个数字batch_size = 64# 装载训练集,dataloader是数据生成器,可以打乱。在循环中使用,每次生成特定批量的数据train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)# 装载训练集test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True)#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。for i,data in enumerate(train_loader):inputs,labels = dataprint(inputs.shape)print(labels.shape)break# 定义网络结构class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784,10)#简单神经网络无隐藏层,只有输入输出层self.softmax = nn.Softmax(dim=1)#激活函数,dim=1为对第一个维度进行转换,输出为(64,10)def forward(self,x):# ([64, 1, 28, 28])->(64,784) 通道数=1,因为是黑白的图片#全连接层必须转化为二维的数据,-1表示自动匹配x = x.view(x.size()[0], -1)x = self.fc1(x)x = self.softmax(x)return xLR = 0.5# 定义模型model = Net()# 定义代价函数mse_loss = nn.MSELoss()# 定义优化器optimizer = optim.SGD(model.parameters(), LR)def train():for i,data in enumerate(train_loader):# 获得一个批次的数据和标签inputs, labels = data# 获得模型预测结果(64,10)out = model(inputs)# to onehot,把数据标签变成独热编码# (64)-(64,1)labels = labels.reshape(-1,1)# tensor.scatter(dim, index, src)# dim:对哪个维度进行独热编码# index:要将src中对应的值放到tensor的哪个位置。# src:插入index的数值one_hot = torch.zeros(inputs.shape[0],10).scatter(1, labels, 1)# 计算loss,mes_loss的两个数据的shape要一致loss = mse_loss(out, one_hot)# 梯度清0optimizer.zero_grad()# 计算梯度loss.backward()# 修改权值optimizer.step()def test():correct = 0for i,data in enumerate(test_loader):# 获得一个批次的数据和标签inputs, labels = data# 获得模型预测结果(64,10)out = model(inputs)# 获得最大值,以及最大值所在的位置_, predicted = torch.max(out, 1)#out的第一个维度# 预测正确的数量correct += (predicted == labels).sum()# list==list会得到一个list(true or false)print("Test acc:{0}".format(correct.item()/len(test_dataset)))for epoch in range(10):print('epoch:',epoch)train()test()
引入dropout
# 定义网络结构class Net(nn.Module):def __init__(self):super(Net, self).__init__()#全连接层;p=0.5表示50%神经元不工作self.layer1 = nn.Sequential(nn.Linear(784,500), nn.Dropout(p=0.5), nn.Tanh())self.layer2 = nn.Sequential(nn.Linear(500,300), nn.Dropout(p=0.5), nn.Tanh())self.layer3 = nn.Sequential(nn.Linear(300,10), nn.Softmax(dim=1))def forward(self,x):# ([64, 1, 28, 28])->(64,784)x = x.view(x.size()[0], -1)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)return x
引入正则化
LR = 0.5# 定义模型model = Net()# 定义代价函数mse_loss = nn.CrossEntropyLoss()# 定义优化器,设置L2正则化optimizer = optim.SGD(model.parameters(), LR, weight_decay=0.001)
使用卷积神经网络
# 定义网络结构class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(1, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2, 2))self.conv2 = nn.Sequential(nn.Conv2d(32, 64, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2, 2))self.fc1 = nn.Sequential(nn.Linear(64 * 7 * 7, 1000), nn.Dropout(p=0.4), nn.ReLU())self.fc2 = nn.Sequential(nn.Linear(1000, 10), nn.Softmax(dim=1))#卷积生成的是四维数据,而全连接要求输入2维数据def forward(self, x):# ([64, 1, 28, 28])x = self.conv1(x)x = self.conv2(x)x = x.view(x.size()[0], -1)x = self.fc1(x)x = self.fc2(x)return x
使用LSTM
# 定义网络结构# input_size输入特征的大小# hidden_size,LSTM模块的数量# num_layers,LSTM的层数# LSTM默认input(seq_len, batch, feature)# batch_first=True,input和output(batch, seq_len, feature)class LSTM(nn.Module):def __init__(self):super(LSTM, self).__init__()self.lstm = torch.nn.LSTM(input_size=28,hidden_size=64,num_layers=1,batch_first=True)self.out = torch.nn.Linear(in_features=64,out_features=10)self.softmax = torch.nn.Softmax(dim=1)def forward(self, x):# (batch, seq_len, feature)x = x.view(-1,28,28)# output:[batch, seq_len, hidden_size]包含每个序列的输出结果# 虽然LSTM的batch_first为True,但是h_n,c_n的第0个维度还是num_layers# h_n:[num_layers, batch, hidden_size]只包含最后一个序列的输出结果# c_n:[num_layers, batch, hidden_size]只包含最后一个序列的输出结果output,(h_n,c_n) = self.lstm(x)output_in_last_timestep = h_n[-1,:,:]x = self.out(output_in_last_timestep)x = self.softmax(x)return x
代码复现
Transformers
import mathimport torchimport numpy as npimport torch.nn as nnimport torch.optim as optimimport torch.utils.data as Data# S: Symbol that shows starting of decoding input# E: Symbol that shows starting of decoding output# P: Symbol that will fill in blank sequence if current batch data size is short than time stepssentences = [# enc_input dec_input dec_output['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']]# Padding Should be Zerosrc_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}src_vocab_size = len(src_vocab)tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}idx2word = {i: w for i, w in enumerate(tgt_vocab)}tgt_vocab_size = len(tgt_vocab)src_len = 5 # enc_input max sequence lengthtgt_len = 6 # dec_input(=dec_output) max sequence length# Transformer Parametersd_model = 512 # Embedding Sized_ff = 2048 # FeedForward dimensiond_k = d_v = 64 # dimension of K(=Q), Vn_layers = 6 # number of Encoder of Decoder Layern_heads = 8 # number of heads in Multi-Head Attentiondef make_data(sentences):enc_inputs, dec_inputs, dec_outputs = [], [], []for i in range(len(sentences)):enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]enc_inputs.extend(enc_input)dec_inputs.extend(dec_input)dec_outputs.extend(dec_output)return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)enc_inputs, dec_inputs, dec_outputs = make_data(sentences)class MyDataSet(Data.Dataset):def __init__(self, enc_inputs, dec_inputs, dec_outputs):super(MyDataSet, self).__init__()self.enc_inputs = enc_inputsself.dec_inputs = dec_inputsself.dec_outputs = dec_outputsdef __len__(self):return self.enc_inputs.shape[0]def __getitem__(self, idx):return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):'''x: [seq_len, batch_size, d_model]'''x = x + self.pe[:x.size(0), :]return self.dropout(x)def get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# eq(zero) is PAD tokenpad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is maskedreturn pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]def get_attn_subsequence_mask(seq):attn_shape = [seq.size(0), seq.size(1), seq.size(1)]subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrixsubsequence_mask = torch.from_numpy(subsequence_mask).byte()return subsequence_mask # [batch_size, tgt_len, tgt_len]class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V, attn_mask):'''Q: [batch_size, n_heads, len_q, d_k]K: [batch_size, n_heads, len_k, d_k]V: [batch_size, n_heads, len_v(=len_k), d_v]attn_mask: [batch_size, n_heads, seq_len, seq_len]'''scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.attn = nn.Softmax(dim=-1)(scores)context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]return context, attnclass MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)def forward(self, input_Q, input_K, input_V, attn_mask):'''input_Q: [batch_size, len_q, d_model]input_K: [batch_size, len_k, d_model]input_V: [batch_size, len_v(=len_k), d_model]attn_mask: [batch_size, seq_len, seq_len]'''residual, batch_size = input_Q, input_Q.size(0)# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]output = self.fc(context) # [batch_size, len_q, d_model]return nn.LayerNorm(d_model).cuda()(output + residual), attnclass PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()self.fc = nn.Sequential(nn.Linear(d_model, d_ff, bias=False),nn.ReLU(),nn.Linear(d_ff, d_model, bias=False))def forward(self, inputs):'''inputs: [batch_size, seq_len, d_model]'''residual = inputsoutput = self.fc(inputs)return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, enc_inputs, enc_self_attn_mask):'''enc_inputs: [batch_size, src_len, d_model]enc_self_attn_mask: [batch_size, src_len, src_len]'''# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,Venc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]return enc_outputs, attnclass DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__()self.dec_self_attn = MultiHeadAttention()self.dec_enc_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):'''dec_inputs: [batch_size, tgt_len, d_model]enc_outputs: [batch_size, src_len, d_model]dec_self_attn_mask: [batch_size, tgt_len, tgt_len]dec_enc_attn_mask: [batch_size, tgt_len, src_len]'''# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]return dec_outputs, dec_self_attn, dec_enc_attnclass Encoder(nn.Module):def __init__(self):super(Encoder, self).__init__()self.src_emb = nn.Embedding(src_vocab_size, d_model)self.pos_emb = PositionalEncoding(d_model)self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])def forward(self, enc_inputs):enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]enc_self_attns = []for layer in self.layers:# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)enc_self_attns.append(enc_self_attn)return enc_outputs, enc_self_attnsclass Decoder(nn.Module):def __init__(self):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)self.pos_emb = PositionalEncoding(d_model)self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])def forward(self, dec_inputs, enc_inputs, enc_outputs):dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]dec_self_attns, dec_enc_attns = [], []for layer in self.layers:# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)return dec_outputs, dec_self_attns, dec_enc_attnsclass Transformer(nn.Module):def __init__(self):super(Transformer, self).__init__()self.encoder = Encoder().cuda()self.decoder = Decoder().cuda()self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()def forward(self, enc_inputs, dec_inputs):'''enc_inputs: [batch_size, src_len]dec_inputs: [batch_size, tgt_len]'''# tensor to store decoder outputs# outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]enc_outputs, enc_self_attns = self.encoder(enc_inputs)# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attnsmodel = Transformer().cuda()criterion = nn.CrossEntropyLoss(ignore_index=0)optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)for epoch in range(1000):for enc_inputs, dec_inputs, dec_outputs in loader:'''enc_inputs: [batch_size, src_len]dec_inputs: [batch_size, tgt_len]dec_outputs: [batch_size, tgt_len]'''enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()# outputs: [batch_size * tgt_len, tgt_vocab_size]outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)loss = criterion(outputs, dec_outputs.view(-1))print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))optimizer.zero_grad()loss.backward()optimizer.step()def greedy_decoder(model, enc_input, start_symbol):enc_outputs, enc_self_attns = model.encoder(enc_input)dec_input = torch.zeros(1, 0).type_as(enc_input.data)terminal = Falsenext_symbol = start_symbolwhile not terminal:dec_input=torch.cat([dec_input.detach(),torch.tensor([[next_symbol]],dtype=enc_input.dtype)],-1)dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)projected = model.projection(dec_outputs)prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]next_word = prob.data[-1]next_symbol = next_wordif next_symbol == tgt_vocab["."]:terminal = Trueprint(next_word)return dec_input# Testenc_inputs, _, _ = next(iter(loader))for i in range(len(enc_inputs)):greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"])predict, _, _, _ = model(enc_inputs[i].view(1, -1), greedy_dec_input)predict = predict.data.max(1, keepdim=True)[1]print(enc_inputs[i], '->', [idx2word[n.item()] for n in predict.squeeze()])
Seq2Seq
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchtext.datasets import Multi30kfrom torchtext.data import Field, BucketIteratorimport spacyimport numpy as npimport randomimport mathimport time"""Set the random seeds for reproducability."""SEED = 1234random.seed(SEED)np.random.seed(SEED)torch.manual_seed(SEED)torch.cuda.manual_seed(SEED)torch.backends.cudnn.deterministic = True"""Load the German and English spaCy models."""! python -m spacy download despacy_de = spacy.load('de')spacy_en = spacy.load('en')"""We create the tokenizers."""def tokenize_de(text):# Tokenizes German text from a string into a list of stringsreturn [tok.text for tok in spacy_de.tokenizer(text)]def tokenize_en(text):# Tokenizes English text from a string into a list of stringsreturn [tok.text for tok in spacy_en.tokenizer(text)]"""The fields remain the same as before."""SRC = Field(tokenize = tokenize_de,init_token = '<sos>',eos_token = '<eos>',lower = True)TRG = Field(tokenize = tokenize_en,init_token = '<sos>',eos_token = '<eos>',lower = True)"""Load the data."""train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),fields = (SRC, TRG))"""Build the vocabulary."""SRC.build_vocab(train_data, min_freq = 2)TRG.build_vocab(train_data, min_freq = 2)"""Define the device."""device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')"""Create the iterators."""BATCH_SIZE = 128train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train_data, valid_data, test_data),batch_size = BATCH_SIZE,device = device)class Encoder(nn.Module):def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):super().__init__()self.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)self.dropout = nn.Dropout(dropout)def forward(self, src):'''src = [src_len, batch_size]'''src = src.transpose(0, 1) # src = [batch_size, src_len]embedded = self.dropout(self.embedding(src)).transpose(0, 1) # embedded = [src_len, batch_size, emb_dim]# enc_output = [src_len, batch_size, hid_dim * num_directions]# enc_hidden = [n_layers * num_directions, batch_size, hid_dim]enc_output, enc_hidden = self.rnn(embedded) # if h_0 is not give, it will be set 0 acquiescently# enc_hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]# enc_output are always from the last layer# enc_hidden [-2, :, : ] is the last of the forwards RNN# enc_hidden [-1, :, : ] is the last of the backwards RNN# initial decoder hidden is final hidden state of the forwards and backwards# encoder RNNs fed through a linear layer# s = [batch_size, dec_hid_dim]s = torch.tanh(self.fc(torch.cat((enc_hidden[-2,:,:], enc_hidden[-1,:,:]), dim = 1)))return enc_output, sclass Attention(nn.Module):def __init__(self, enc_hid_dim, dec_hid_dim):super().__init__()self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim, bias=False)self.v = nn.Linear(dec_hid_dim, 1, bias = False)def forward(self, s, enc_output):# s = [batch_size, dec_hid_dim]# enc_output = [src_len, batch_size, enc_hid_dim * 2]batch_size = enc_output.shape[1]src_len = enc_output.shape[0]# repeat decoder hidden state src_len times# s = [batch_size, src_len, dec_hid_dim]# enc_output = [batch_size, src_len, enc_hid_dim * 2]s = s.unsqueeze(1).repeat(1, src_len, 1)enc_output = enc_output.transpose(0, 1)# energy = [batch_size, src_len, dec_hid_dim]energy = torch.tanh(self.attn(torch.cat((s, enc_output), dim = 2)))# attention = [batch_size, src_len]attention = self.v(energy).squeeze(2)return F.softmax(attention, dim=1)class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):super().__init__()self.output_dim = output_dimself.attention = attentionself.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, dec_input, s, enc_output):# dec_input = [batch_size]# s = [batch_size, dec_hid_dim]# enc_output = [src_len, batch_size, enc_hid_dim * 2]dec_input = dec_input.unsqueeze(1) # dec_input = [batch_size, 1]embedded = self.dropout(self.embedding(dec_input)).transpose(0, 1) # embedded = [1, batch_size, emb_dim]# a = [batch_size, 1, src_len]a = self.attention(s, enc_output).unsqueeze(1)# enc_output = [batch_size, src_len, enc_hid_dim * 2]enc_output = enc_output.transpose(0, 1)# c = [1, batch_size, enc_hid_dim * 2]c = torch.bmm(a, enc_output).transpose(0, 1)# rnn_input = [1, batch_size, (enc_hid_dim * 2) + emb_dim]rnn_input = torch.cat((embedded, c), dim = 2)# dec_output = [src_len(=1), batch_size, dec_hid_dim]# dec_hidden = [n_layers * num_directions, batch_size, dec_hid_dim]dec_output, dec_hidden = self.rnn(rnn_input, s.unsqueeze(0))# embedded = [batch_size, emb_dim]# dec_output = [batch_size, dec_hid_dim]# c = [batch_size, enc_hid_dim * 2]embedded = embedded.squeeze(0)dec_output = dec_output.squeeze(0)c = c.squeeze(0)# pred = [batch_size, output_dim]pred = self.fc_out(torch.cat((dec_output, c, embedded), dim = 1))return pred, dec_hidden.squeeze(0)class Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super().__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self, src, trg, teacher_forcing_ratio = 0.5):# src = [src_len, batch_size]# trg = [trg_len, batch_size]# teacher_forcing_ratio is probability to use teacher forcingbatch_size = src.shape[1]trg_len = trg.shape[0]trg_vocab_size = self.decoder.output_dim# tensor to store decoder outputsoutputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)# enc_output is all hidden states of the input sequence, back and forwards# s is the final forward and backward hidden states, passed through a linear layerenc_output, s = self.encoder(src)# first input to the decoder is the <sos> tokensdec_input = trg[0,:]for t in range(1, trg_len):# insert dec_input token embedding, previous hidden state and all encoder hidden states# receive output tensor (predictions) and new hidden statedec_output, s = self.decoder(dec_input, s, enc_output)# place predictions in a tensor holding predictions for each tokenoutputs[t] = dec_output# decide if we are going to use teacher forcing or notteacher_force = random.random() < teacher_forcing_ratio# get the highest predicted token from our predictionstop1 = dec_output.argmax(1)# if teacher forcing, use actual next token as next input# if not, use predicted tokendec_input = trg[t] if teacher_force else top1return outputs"""## Training the Seq2Seq ModelThe rest of this tutorial is very similar to the previous one.We initialise our parameters, encoder, decoder and seq2seq model (placing it on the GPU if we have one)."""INPUT_DIM = len(SRC.vocab)OUTPUT_DIM = len(TRG.vocab)ENC_EMB_DIM = 256DEC_EMB_DIM = 256ENC_HID_DIM = 512DEC_HID_DIM = 512ENC_DROPOUT = 0.5DEC_DROPOUT = 0.5attn = Attention(ENC_HID_DIM, DEC_HID_DIM)enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)model = Seq2Seq(enc, dec, device).to(device)TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX).to(device)optimizer = optim.Adam(model.parameters(), lr=1e-3)"""We then create the training loop..."""def train(model, iterator, optimizer, criterion):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src = batch.srctrg = batch.trg # trg = [trg_len, batch_size]# pred = [trg_len, batch_size, pred_dim]pred = model(src, trg)pred_dim = pred.shape[-1]# trg = [(trg len - 1) * batch size]# pred = [(trg len - 1) * batch size, pred_dim]trg = trg[1:].view(-1)pred = pred[1:].view(-1, pred_dim)loss = criterion(pred, trg)optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)"""...and the evaluation loop, remembering to set the model to `eval` mode and turn off teaching forcing."""def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0with torch.no_grad():for i, batch in enumerate(iterator):src = batch.srctrg = batch.trg # trg = [trg_len, batch_size]# output = [trg_len, batch_size, output_dim]output = model(src, trg, 0) # turn off teacher forcingoutput_dim = output.shape[-1]# trg = [(trg_len - 1) * batch_size]# output = [(trg_len - 1) * batch_size, output_dim]output = output[1:].view(-1, output_dim)trg = trg[1:].view(-1)loss = criterion(output, trg)epoch_loss += loss.item()return epoch_loss / len(iterator)"""Finally, define a timing function."""def epoch_time(start_time, end_time):elapsed_time = end_time - start_timeelapsed_mins = int(elapsed_time / 60)elapsed_secs = int(elapsed_time - (elapsed_mins * 60))return elapsed_mins, elapsed_secs"""Then, we train our model, saving the parameters that give us the best validation loss."""best_valid_loss = float('inf')for epoch in range(10):start_time = time.time()train_loss = train(model, train_iterator, optimizer, criterion)valid_loss = evaluate(model, valid_iterator, criterion)end_time = time.time()epoch_mins, epoch_secs = epoch_time(start_time, end_time)if valid_loss < best_valid_loss:best_valid_loss = valid_losstorch.save(model.state_dict(), 'tut3-model.pt')print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')"""Finally, we test the model on the test set using these "best" parameters."""model.load_state_dict(torch.load('tut3-model.pt'))test_loss = evaluate(model, test_iterator, criterion)print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')"""We've improved on the previous model, but this came at the cost of doubling the training time.In the next notebook, we'll be using the same architecture but using a few tricks that are applicable to all RNN architectures - packed padded sequences and masking. We'll also implement code which will allow us to look at what words in the input the RNN is paying attention to when decoding the output."""
对话系统
基于知识的对话系统(open)
cc-2019328162246.pdf
让机器具备与人交流的能力是人工智能领域的一项重要工作,同时也是一项极具挑战的任务。1951 年图灵在《计算机与智能》一文中提出用人机对话来测试机器智能水平,引起了研究者的广泛关注。此后,学者们尝试了各种方法研究建立对话系统。按照系统建设的目的,对话系统被分为任务驱动的限定领域对话系统和无特定任务的开放领域对话系统。限定领域对话系统是为了完成特定任务而设计的,例如网站客服、车载助手等。开放领域对话系统也被称为聊天机器人,是无任务驱动,为了纯聊天或者娱乐而开发的,它的目的是生成有意义且相关的回复。
任务驱动型对话系统

若有收获,就点个赞吧
0 人点赞
