作者:Laurynas Biveinis and Alexey Stroganov
发布时间:2016.5.9
文章关键字:MySQL
原文:Percona Server 5.7 parallel doublewrite
In this blog post, we’ll discuss the ins and outs of Percona Server 5.7 parallel doublewrite.
在这篇文章中,我们将由里及外讨论Percona Server 5.7的并行doublewrite。
After implementing parallel LRU flushing as described in the previous post, we went back to benchmarking. At first, we tested with the doublewrite buffer turned off. We wanted to isolate the effect of the parallel LRU flusher, and the results validated the design. Then we turned the doublewrite buffer back on and saw very little, if any, gain from the parallel LRU flusher. What happened? Let’s take a look at the data:
在上篇文章中 ,我们描述了多线程LRU刷新线程的实现,现在让我们回到基准测试。首先,在doublewrite buffer关闭状态下进行测试。我们想要隔离并行LRU刷新带来的影响,结果验证了设想。然后,重新开启doublewrite,发现从并行LRU刷新获得的好处很小。到底发生了什么?我们先来看看数据:
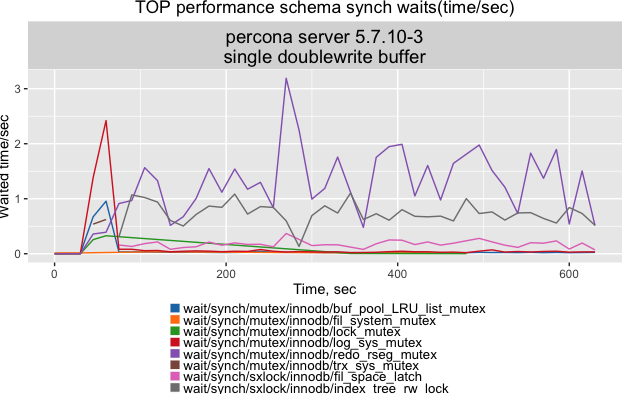
We see that the doublewrite buffer mutex is gone as expected and that the top waiters are the rseg mutexes and the index lock (shouldn’t this be fixed in 5.7?). Then we checked PMP:
如上图,我们看到doublewrite buffer互斥量如预期一样消失了,最高的等待是rseg 互斥量和index锁(这不应该在5.7修复了么?)。接着,我们检查下PMP:
2678 nanosleep(libpthread.so.0),...,buf_LRU_get_free_block(buf0lru.cc:1435),...867 pthread_cond_wait,...,log_write_up_to(log0log.cc:1293),...396 pthread_cond_wait,...,mtr_t::s_lock(sync0rw.ic:433),btr_cur_search_to_nth_level(btr0cur.cc:1022),...337 libaio::??(libaio.so.1),LinuxAIOHandler::collect(os0file.cc:2325),...240 poll(libc.so.6),...,Protocol_classic::read_packet(protocol_classic.cc:810),...
Again we see that PFS is not telling the whole story, this time due to a missing annotation in XtraDB. Whereas the PFS results might lead us to leave the flushing analysis and focus on the rseg/undo/purge or check the index lock, PMP clearly shows that a lack of free pages is the biggest source of waits. Turning on the doublewrite buffer makes LRU flushing inadequate again. This data, however, doesn’t tell us why that is.
我们再次看到,PFS并没有显示所有的内容,这里是因为XtraDB的缺陷。而PFS的结果让我们忽略刷新方面的分析,转而聚焦rseg/undo/purge或者索引锁的检查上。PMP清晰地展现缺少空闲也是最大等待的源头。打开doublewriter buffer又会导致LRU刷新不足。然而,这些数据并没有告诉我们为什么会这样。
To see how enabling the doublewrite buffer makes LRU flushing perform worse, we collect PFS and PMP data only for the server flusher (cleaner coordinator, cleaner worker, and LRU flusher) threads and I/O completion threads:
为了了解为何开启了doublewrite buffer 会使LRU刷新变得糟糕,我们收集了PFS和PMP数据,这些数据只包含刷新相关(cleaner coordinator,cleaner worker,以及LRU flusher)线程和I/O相关线程:
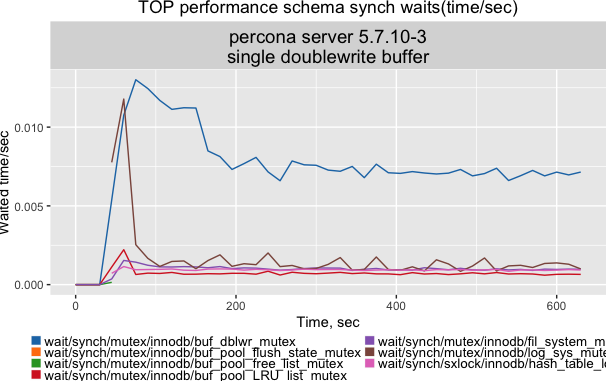
If we zoom in from the whole server to the flushers only, the doublewrite mutex is back. Since we removed its contention for the single page flushes, it must be the batch doublewrite buffer usage by the flusher threads that causes it to reappear. The doublewrite buffer has a single area for 120 pages that is shared and filled by flusher threads. The page add to the batch action is protected by the doublewrite mutex, serialising the adds, and results in the following picture:
如果我们从整个服务放大到刷新线程,就又能看到douoblewrite mutex了。由于我们移除了单页刷新之间的争用,所以它会在刷新线程批量使用doublewrite buffer时重新出现。doublewrite buffer有一个有120个page的单独区域,刷新线程负责填充并共享使用。将页添加到批处理操作由doublewrite mutex保护,持续添加之后的结果如下图:
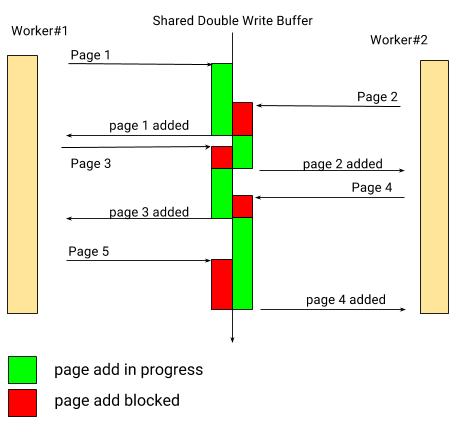
By now we should be wary of reviewing PFS data without checking its results against PMP. Here it is:
现在我们应该更谨慎地评估PFS数据,并与PMP进行对比。PMP结果如下:
139 libaio::??(libaio.so.1),LinuxAIOHandler::collect(os0file.cc:2448),LinuxAIOHandler::poll(os0file.cc:2594),...56 pthread_cond_wait,...,os_event_wait_low(os0event.cc:534),buf_dblwr_add_to_batch(buf0dblwr.cc:1111),...,buf_flush_LRU_list_batch(buf0flu.cc:1555),...,buf_lru_manager(buf0flu.cc:2334),...25 pthread_cond_wait,...,os_event_wait_low(os0event.cc:534),buf_flush_page_cleaner_worker(buf0flu.cc:3482),...21 pthread_cond_wait,...,PolicyMutex<TTASEventMutex<GenericPolicy>(ut0mutex.ic:89),buf_page_io_complete(buf0buf.cc:5966),fil_aio_wait(fil0fil.cc:5754),io_handler_thread(srv0start.cc:330),...8 pthread_cond_timedwait,...,buf_flush_page_cleaner_coordinator(buf0flu.cc:2726),...
As with the single-page flush doublewrite contention and the wait to get a free page in the previous posts, here we have an unannotated-for-Performance Schema doublewrite OS event wait (same bug 80979):
与之前文章中提到的单页刷新doublewrite争用,等待一个空闲的页的情景一样,这里我们有一个在Performance Schema中未被注解的doublewrite OS 事件(见bug80979)。
if (buf_dblwr->batch_running) {/* This not nearly as bad as it looks. There is onlypage_cleaner thread which does background flushingin batches therefore it is unlikely to be a contentionpoint. The only exception is when a user thread isforced to do a flush batch because of a synccheckpoint. */int64_t sig_count = os_event_reset(buf_dblwr->b_event);mutex_exit(&buf_dblwr->mutex);os_event_wait_low(buf_dblwr->b_event, sig_count);goto try_again;}
This is as bad as it looks (the comment is outdated). A running doublewrite flush blocks any doublewrite page add attempts from all the other flusher threads for the duration of the flush (up to 120 data pages written twice to storage):
这看起来很糟糕(里面的注释可以不用关注,已经过时)。活跃的doublewrite刷新时会阻塞所有其他flush线程任何的doublewrite page添加(多达120个页写入两次存储)。
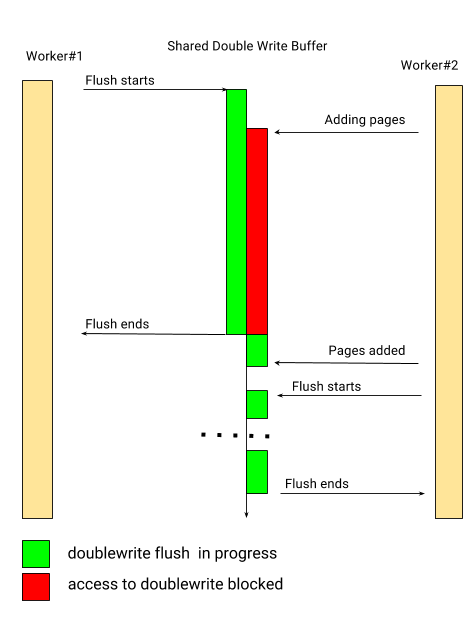
The issue also occurs with MySQL 5.7 multi-threaded flusher but becomes more acute with the PS 5.7 multi-threaded LRU flusher. There is no inherent reason why all the parallel flusher threads must share the single doublewrite buffer. Each thread can have its own private buffer, and doing so allows us to add to the buffers and flush them independently. This means a lot of synchronisation simply disappears. Adding pages to parallel buffers is fully asynchronous:
使用MySQL 5.7多线程flush也会出现此问题,但Percona Server 5.7的多线程LRU 刷新尤为突出。但并发flush线程并非必须共享单个doublewrite buffer。每个线程都可以有自己的私有buffer,这样可以允许添加到buffer并单独刷新它们。这意味着大量的同步会消失。将页面添加到并行buffer完全是异步的。
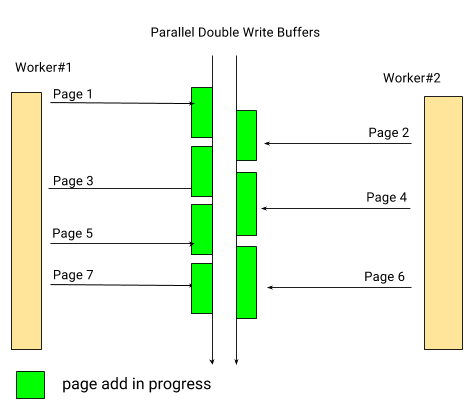
And so is flushing them:
变成了下面的刷新模式:
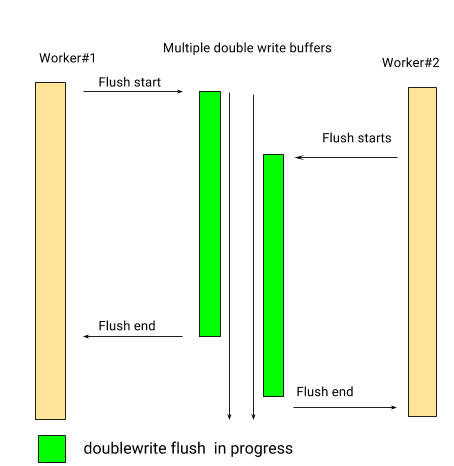
This behavior is what we shipped in the 5.7.11-4 release, and the performance results were shown in a previous post. To see how the private doublewrite buffer affects flusher threads, let’s look at isolated data for those threads again.
这个特性是我们在5.7.11-4版本添加的,其性能提升效果在之前的文章中已经展示。想知道私有doublewrite buffer对flush线程的影响,让我们再看下这些线程的隔离数据:
Performance Schema:
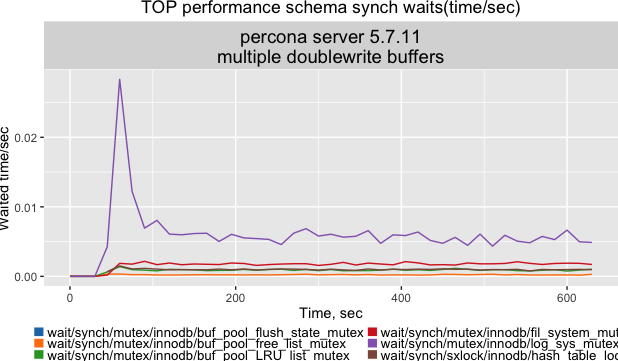
It shows the redo log mutex as the current top contention source from the PFS point of view, which is not caused directly by flushing.
从PFS的角度看,redo log互斥量是当前使用量最多的争用来源,这不是直接由flush引起的。
PMP data looks better too:
PMP的数据看起来好点:
112 libaio::??(libaio.so.1),LinuxAIOHandler::collect(os0file.cc:2455),...,io_handler_thread(srv0start.cc:330),...54 pthread_cond_wait,...,buf_dblwr_flush_buffered_writes(buf0dblwr.cc:1287),...,buf_flush_LRU_list(buf0flu.cc:2341),buf_lru_manager(buf0flu.cc:2341),...35 pthread_cond_wait,...,PolicyMutex<TTASEventMutex<GenericPolicy>(ut0mutex.ic:89),buf_page_io_complete(buf0buf.cc:5986),...,io_handler_thread(srv0start.cc:330),...27 pthread_cond_wait,...,buf_flush_page_cleaner_worker(buf0flu.cc:3489),...10 pthread_cond_wait,...,enter(ib0mutex.h:845),buf_LRU_block_free_non_file_page(ib0mutex.h:845),buf_LRU_bloc
The buf_dblwr_flush_buffered_writes now waits for its own thread I/O to complete and doesn’t block other threads from proceeding. The other top mutex waits belong to the LRU list mutex, which is again not caused directly by flushing.
buf_dblwr_flush_buffered_writes 现在等待自己的线程I/O完成,并不阻塞其他线程运行。其他较高的互斥量等待属于LRU list mutex,这也不是由flush引起的。
This concludes the description of the current flushing implementation in Percona Server. To sum up, in these post series we took you through the road to the current XtraDB 5.7 flushing implementation:
- Under high concurrency I/O-bound workloads, the server has a high demand for free buffer pages. This demand can be satisfied by either LRU batch flushing, either single page flushing.
- Single page flushes cause a lot of doublewrite buffer contention and are bad even without the doublewrite.
- Same as in XtraDB 5.6, we removed the single page flushing altogether.
- Existing cleaner LRU flushing could not satisfy free page demand.
- Multi-threaded LRU flushing design addresses this issue – if the doublewrite buffer is disabled.
- If the doublewrite buffer is enabled, MT LRU flushing contends on it, negating its improvements.
- Parallel doublewrite buffers address this bottleneck.
以下是对当前Percona Server的flush实现描述。总结一下,在这些的系列文章中,我们重现了XtraDB 5.7刷新实现的风雨历程:
- 在I/O密集的工作负载下,server对空闲buffer页面的需求量很大,这要求通过批量的LRU刷新,或者单个页面刷新来满足需要。
- 单个页面flush会导致大量的doublewrite buffer争用,即使没开启doublewrite也是糟糕的。
- 与XtraDB 5.6 相同,我们一并移除了单页flush。
- 现有的LRU刷新机制不能满足空闲页的需求。
- 多线程LRU刷新解决了这个问题——如果doublewrite buffer关闭掉。
- 如果开启了doublewrite,则多线程的LRU flush会争用它,也会使得性能下降。
- 并行的doublewrite buffer解决了这个问题。

若有收获,就点个赞吧
0 人点赞
