五、DQL语言学习
5.8 子查询
5.8.1 含义
出现在其他语句中的select语句,称为子查询或内查询
外部的查询语句,称为主查询或外查询
5.8.2 分类
- 按子查询出现的位置:
- select后面:仅仅支持标量子查询
- from后面:支持表子查询
- where或having后面:支持标量子查询、列子查询、行子查询
- exists后面(相关子查询):表子查询
- 按结果集的行列数不同:
- 标量子查询(单行子查询)
- 列子查询(多行子查询)
- 行子查询(多行多列)
特点:
- 子查询放在小括号内
- 子查询一般放在条件的右侧
- 标量子查询,一般搭配着单行操作符(> < >= <= = <>)使用
- 列子查询,一般搭配着多行操作符(in any/some all)使用
标量子查询
要求:左后返回的结果为一行一列
案例1:谁的工资比Abel高?
# 1. 查询Abel的工资# select salary from employees where last_name='Abel';# 2. 查询员工的信息,满足salary>1的结果select * from employees where salary>(select salary from employees where last_name='Abel');
案例2:返回job_id与141号员工相同,salary比143号员工多的员工,姓名、job_id和工资
# 1.查询141号员工的job_id# select job_id from employees where employee_id=141# 2.查询143号员工的salary# select salary from employees where employee_id=143# 3.查询员工的姓名,job_id和工资,要求job_id= 1的结果 并且salary>2的结果select last_name,job_id,salaryfrom employeeswhere job_id=(select job_id from employees where employee_id=141)and salary>(select salary from employees where employee_id=143)
案例3:返回公司工资最少的员工的last_name,job_id和salary
# 1.查询公司的最低工资# select min(salar) from employees# 2.查询last_name,job_id和salary,要求salary=1的结果select last_name,job_id,salaryfrom employeeswhere salary=(select min(salary) from employees)
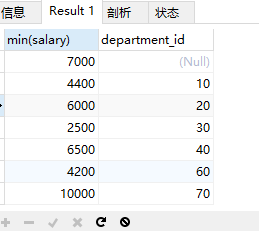
案例4:查询最低工资>50号部门最低工资的部门id和其最低工资
# 1.查询50号部门的最低工资-- select min(salary) from employees where department_id=50# 2.查询每个部门的最低工资-- select min(salary),department_id-- from employees-- group by department_id# 3.在2.结果基础上筛选,满足min(salary)>1的结果select min(salary),department_idfrom employeesgroup by department_idhaving min(salary)>(select min(salary)from employeeswhere department_id=50)
列子查询(多行子查询)
- 返回多行
- 使用多行比较操作符 | 操作符 | 含义 | | —- | —- | | IN / NOT IN | 等于列表中的任意一个 | | ANY | SOME | 和子查询返回的某一个值比较 | | ALL | 和子查询返回的所有值比较 |
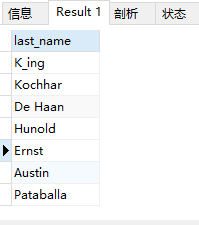
案例1:返回location_id是1400或1700的部门中所有员工姓名
# 1. 查询location_id是1400或1700的部门编号-- select distinct department_id-- from departments-- where location_id in (1400,1700)--# 2. 查询员工姓名,要求部门编号是1的结果中的某一个select last_namefrom employeeswhere department_id in(select distinct department_idfrom departmentswhere location_id in (1400,1700))
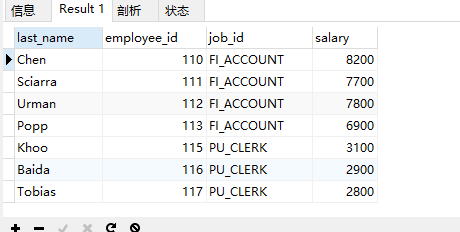
案例2:返回其他工种中比job_id为’IT_PROG’工种任一工资低的员工号、姓名、job_id以及salary
# 1.查询job_id为`IT_PROG`部门任一工资-- select distinct salary-- from employees-- where job_id='IT_PROG'# 2.查询员工号、姓名、job_id以及salary,salary<(1的结果)的任意一个select last_name,employee_id,job_id,salaryfrom employeeswhere salary<any(select distinct salaryfrom employeeswhere job_id='IT_PROG')and job_id<>'IT_PROG';
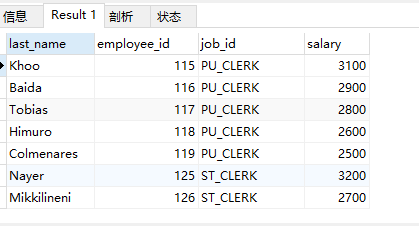
案例3:返回其他部门中比job_id为’IT_PROG’部门所有工资都低的员工大的员工号、姓名
、job_id以及salary
# 1.查询job_id为`IT_PROG`部门任一工资-- select distinct salary-- from employees-- where job_id='IT_PROG'# 2.查询员工号、姓名、job_id以及salary,salary<(1的结果)的所有select last_name,employee_id,job_id,salaryfrom employeeswhere salary<all(select distinct salaryfrom employeeswhere job_id='IT_PROG')and job_id<>'IT_PROG';
行子查询(多列子查询)
案例:查询员工编号最小并且工资最高的员工信息
按照之前的思路解法
# 1.查询最小的员工编号-- select min(employee_id)-- from employees# 2.查询最高工资-- select max(salary)-- from employees# 3.查询员工信息select *from employeeswhere employee_id=(select min(employee_id)from employees)and salary=(select max(salary)from employees)
现在换用列子查询:
# 列子查询有其局限性,操作符只能为同一个,下面的就为 = 操作符select *from employeeswhere (employee_id,salary)=(select min(employee_id),max(salary)from employees)
5.8.5 select后面
select后面仅支持标量子查询
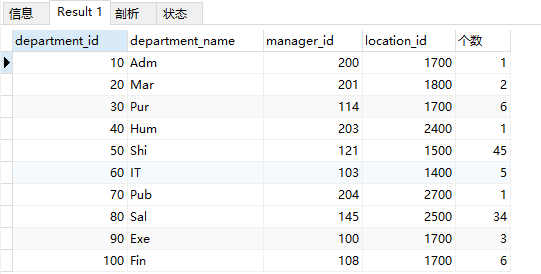
案例:查询每个部门的员工个数
select d.*, (select count(*)from employees ewhere e.department_id=d.department_id) as 个数from departments d;
5.8.6 from后面
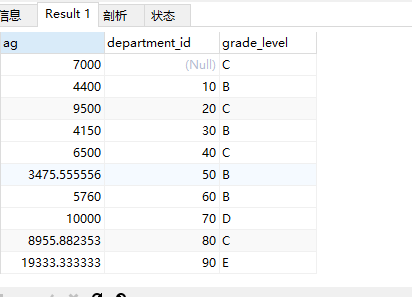
案例:查询每个部门的平均工资的工资等级
# 1.查询每个部门的平均工资-- select avg(salary),department_id-- from employees-- group by department_id;# 2.连接1的结果和job_grades表,筛选平均工资select ag_dep.*,g.grade_levelfrom (select avg(salary) ag,department_idfrom employeesgroup by department_id) as ag_depinner join job_grades gon ag_dep.ag between lowest_sal and highest_sal;
5.8.7 exists后面(相关子查询)
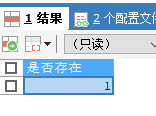
exis用来查询结果是否存在:
/*语法:exists(完整的查询语句)结果:1或0*/SELECT EXISTS(SELECT employee_id FROM employees) AS 是否存在;
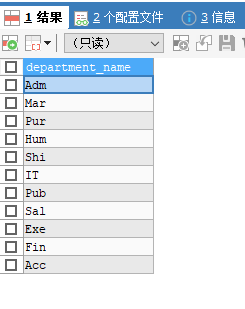
案例1:查询有员工的部门名
# 方法1:使用exists来实现SELECT department_nameFROM departments dWHERE EXISTS(SELECT *FROM employees eWHERE d.`department_id`=e.`department_id`);# 方法2:使用in关键字来实现SELECT department_nameFROM departments dWHERE d.`department_id` IN(SELECT department_idFROM employees);
案例2:查询没有女朋友的男神信息
# 方法1:使用in关键字USE `girls`;SELECT bo.*FROM boys boWHERE bo.id NOT IN(SELECT boyfriend_idFROM beauty);# 方法2:使用exists关键字SELECT bo.*FROM boys boWHERE NOT EXISTS(SELECT boyfriend_idFROM beauty bWHERE bo.`id`=b.`boyfriend_id`);
5.8.8 子查询测试
- 查询和Zlotkey 相同部门的员工姓名和工资
- 查询工资比公司平均工资高的员工的员工号,姓名和工资
- 查询各部门中工资比本部门平均工资高的员工的员工号, 姓名和工资
- 查询和姓名中包含字母 u 的员工在相同部门的员工的员工号和姓名
- 查询在部门的location_id 为1700 的部门工作的员工的员工号
- 查询管理者是King 的员工姓名和工资
查询工资最高的员工的姓名,要求 first_name 和 last_name 显示为一列,列名为 姓.名
5.8.9 子查询经典案例题目
查询工资最低的员工信息: last_name, salary
- 查询平均工资最低的部门信息
- 查询平均工资最低的部门信息和该部门的平均工资
- 查询平均工资最高的 job 信息
- 查询平均工资高于公司平均工资的部门有哪些?
- 查询出公司中所有 manager 的详细信息.
- 各个部门中 最高工资中最低的那个部门的 最低工资是多少
- 查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary
5.9 分页查询
应用场景:我们的数据一次加载不完,所以要分成几页来显示,类似如下 ```sql
/*语法:
select 查询列表
from 表
[join type join 表2
on 连接条件
where 筛选条件
group by 分组字段]
limit offset,size;
```sql
/*语法:
select 查询列表
from 表
[join type join 表2
on 连接条件
where 筛选条件
group by 分组字段]
limit offset,size;
offset 要显示条目的起始索引(起始索引从0开始) size 要显示的条目个数 */
**案例1**:查询前5条员工的信息```sqlSELECT * FROM employees LIMIT 0,5;# 或者SELECT * FROM employees LIMIT 5;
案例2:查询第11条-第25条的信息
SELECT * FROM employees LIMIT 10,15;
案例3:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT *FROM employeesWHERE commission_pct IS NOT NULLORDER BY salary DESCLIMIT 10;
5.10 Union联合查询
联合查询:将多条查询语句联合起来
应用场景:要用到的结果来自于多个表,且多个表之间没有连接关系,但是所要查询的信息是一样的。
/*语法:查询语句1union查询语句2union...*/
案例:查询部门编号>90或邮箱包含a的员工信息
# 方法1:在where后改变条件SELECT *FROM employeesWHERE email LIKE '%a%'OR department_id>90;# 方法2:使用连接查询SELECT * FROM employees WHERE email LIKE '%a%'UNIONSELECT * FROM employees WHERE department_id>90;
注意:
UNION关键字会将结果进行去重,所以有时候为了避免去重,需要使用UNION ALL关键字- 要求多条查询语句的查询列数是一致的
- 要求多条查询语句的查询的每一列的类型和顺序最好一致

若有收获,就点个赞吧
0 人点赞
