fork-join
特点:
- 简单抑郁实现。
- 没有瓶颈,因为没有共享的资源。
- 性能的计算容易,大致上就是把总任务除以线程数。
- 便于验证程序的正确性。
过程
use std::{thread, io};fn process_files_in_parallel(filenames: Vec<String>) -> io::Result<()> {// Divide the work into several chunks.const NTHREADS: usize = 8;let worklists = split_vec_into_chunks(filenames, NTHREADS);// Fork: Spawn a thread to handle each chunk.let mut thread_handles = vec![];for worklist in worklists {thread_handles.push(thread::spawn(move || process_files(worklist)));}// Join: Wait for all threads to finish.for handle in thread_handles {handle.join().unwrap()?;}Ok(())}
- 在主线程中创建任务的数据(worklist)
- 将一份任务move到closure里
- spawn将closure和数据转移到子线程中,返回JoinHandle。转移closure和数据到子线程和转移所有权是一样的没有任何数据拷贝,所以是轻的。
- 用join等待子线程结束,否则主线程结束后子线程会被杀掉,没有任何处理。
错误处理
handle.join() 返回 std::thread::Result。如果子线程panic里就返回错误。panic是安全的且局限于线程的。如果成功就返回子线程的返回值。
共享的不可变数据
如果需要处理的数据量很大有不能分割,那所有的子线程需要共享这个数据的引用。如果直接传引用给子线程的closure
fn process_files_in_parallel(filenames: Vec<String>,glossary: &GigabyteMap)-> io::Result<()>{...for worklist in worklists {thread_handles.push(spawn(move || process_files(worklist, glossary)) // error);}...}
会报错,提示glossary需要static lifetime。因为编译器无法预估子线程的运行时间,默认是一直运行。实际原因是有可能其中一个线程失败后,整个进程就会结束,主线程就会drop引用的值,其他子线程就读不到该数据了。解决方法是使用。
因此要使用特殊引用:计数引用,又因为是多线程所以要用原子计数引用Arc。
use std::sync::Arc;fn process_files_in_parallel(filenames: Vec<String>,glossary: Arc<GigabyteMap>)-> io::Result<()>{...for worklist in worklists {// This call to .clone() only clones the Arc and bumps the// reference count. It does not clone the GigabyteMap.let glossary_for_child = glossary.clone();thread_handles.push(spawn(move || process_files(worklist, &glossary_for_child)));}...}
支持fork-join模式的库
crossbeam,rayon。
rayon
use rayon::prelude::*;// "do 2 things in parallel"let (v1, v2) = rayon::join(fn1, fn2);// "do N things in parallel"giant_vector.par_iter().for_each(|value| {do_thing_with_value(value);});
par_iter返回一个ParallelIterator迭代器。看似每个value一个线程,实际上,rayon底层只用n个线程,n是cpu数。
用rayon重写之前的列子
use rayon::prelude::*;fn process_files_in_parallel(filenames: Vec<String>, glossary: &GigabyteMap)-> io::Result<()>{filenames.par_iter().map(|filename| process_file(filename, glossary)).reduce_with(|r1, r2| {if r1.is_err() { r1 } else { r2 }}).unwrap_or(Ok(()))}
map部分返回是子线程的结果也就是io::Result。reduce_with只保留第一个错误。rayon支持了线程之间共享引用,所以这里我们直接传了glossary。
通道Channel
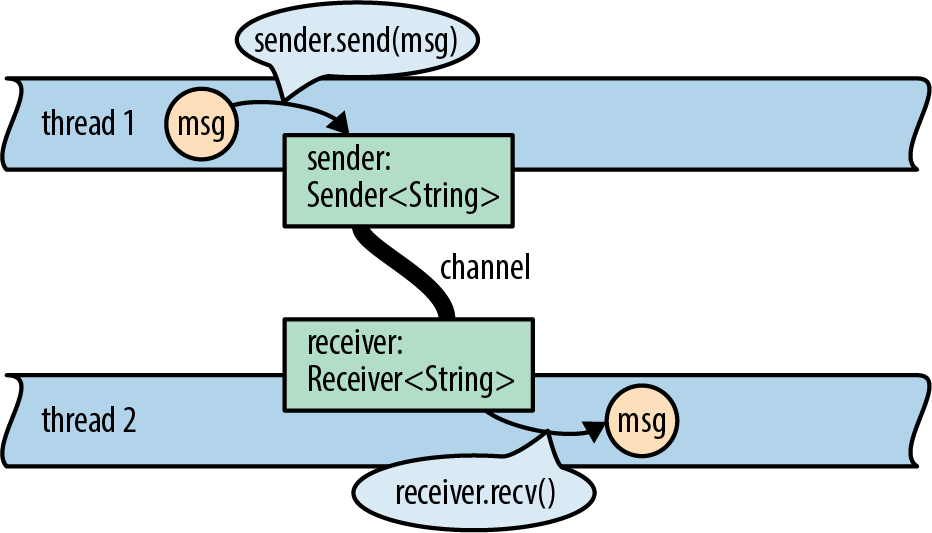
Rust的channel传递的是Rust的值,channel的两头分别被两个线程所有,传递的值的所有权从发送方传递给接收方。如果channel是空的则receiver.recv()会阻塞。
发送和接收
channel的创建使用std::sync::mpsc模块
use std::{fs, thread};use std::sync::mpsc;let (sender, receiver) = mpsc::channel();let handle = thread::spawn(move || {for filename in documents {let text = fs::read_to_string(filename)?;if sender.send(text).is_err() {break;}}Ok(())});
也可以指明类型mpsc::channel::
sender.send(text)和receiver.recv()都会返回Result,Result是Err只有在另一方被drop才会发生。
接收消息的时候可以用receiver.recv()方法
while let Ok(text) = receiver.recv() {do_something_with(text);}
receiver也是一个迭代器,如果通道已空其sender被drop,循环就会停止。
for text in receiver {do_something_with(text);}
性能
mpsc表示multiple producer single comsumor。sender可以clone多个分别移动到不同的线程。
Rust的channel使用一个特殊的one-shot队列实现。如果这个队列只发一个消息,其overhead很小,如果发第二个,Rust会换成另外的队列实现。如果使用了clone又换成另外的实现,能让多个线程来使用。即使是最低性能的实现也是不用锁的。所以通道的消耗只有:几个原子操作;一个堆内存申请;一个转移。只有在通道为空接收者需要sleep的时候才会有系统调用。
有一种情况会造成性能下降:发送者的速度远快雨接受者。这样队列会堆积,并且发送者因为速度快还会占用更多的CPU和其他系统资源,让接受者更慢。这个问题可以使用同步队列(synchronous channel)解决,就是在创建的时候指定一个最大消息数,达到最大数send就会阻塞等待。
线程安全
safe指的是没有数据竞争和未定义行为。
主要由两个trait分别std::marker::Send and std::marker::Sync。
- 实现Send的可以安全的以值在不同的线程间传递
- 实现Sync的可以以不可变引用在线程间分享
Rust的大多数类型都是Send和Sync的,且结构或枚举的元素如果是Send或Sync的则其本身也是,不需derive。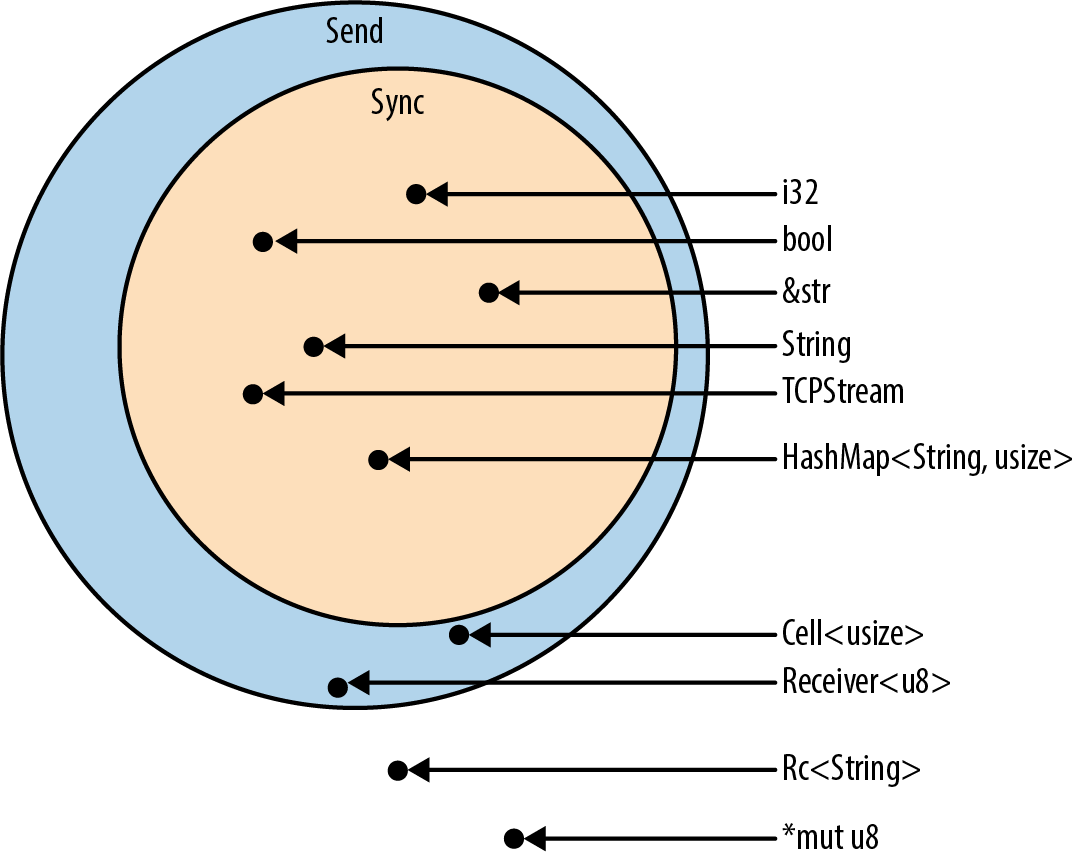
Rc这类可以修改的引用不是Send是因为会竞争。
共享的可变状态
mutext
主要靠mutex,其它语言也有mutex,但他们是和要处理的数据分开的,全靠程序员自己掌握,编译器并没有强制。
创建mutext
use std::sync::Mutex;let waiting_list = Mutex::new(vec![]);
虽然创建方式和Box,Arc类似,但是Box强调数据是分配在堆上的,而Mutex强调数据是有锁的,它并没有负责把数据放哪里,如果要放堆上需要程序员自己写明。
waiting_list.lock()返回的是MutexGuard
这里waiting_list本身并不是mut但我们仍可以修改里面的值,是因为interior mutability。一般来说只有在容器可变的时候里面的值才可变,因为要修改一个值,需要排他的引用或所有权。但mutex因为有锁,在共享的情况下也能保证其内部的值在同一时间只能被一个操作访问,所以他是可变的。和std::cell::RefCell类似,只不过RefCell不支持多线程。
mutex不能解决的问题:
- 并不能完全消除竞争,一些竞争是和时间有关的
- mutex不像channel将逻辑分离,而是会把逻辑变得耦合
- 会引入一下问题
死锁
一个线程也能死锁,如果你一个mutex调两次lock的话。
channel也能死锁,如果两个线程互相发消息,而又同时等着接收对方的消息的话。所以channel的结构最好是开环的。
Poisoned Mutexes
Mutex::lock()返回Result的原因和JoinHandle::join()一样,当另一个线程panic的时候可以优雅的失败,可以将一个线程的失败告诉林外的线程。
如果一个线程在持有锁的时候panic了,这个mutex就成了poisoned,其他线程再lock的时候就会得到错误。poisoned mutex的lock会返回PoisonError,通过PoisonError::into_inner()方法仍然可以获取MutexGuard并得到里面的数据。
读写锁
有些情况,比如配置文件,大多数情况下,多个线程只需要读,只有偶尔修改配置了写需要写,因此使用mutex会造成瓶颈,因为读的时候不需要排他。std::sync::RwLock的read方法返回一个只读的引用,其他线程这时候也可以读,write方法返回一个可变的排他引用。
Condition Variables
在某些情况下让线程等待某个情况改变或某个时间发生的机制。和JoinHandle::join类似。join是等待一个线程的完成,condition variable是等待某件事发生。std::sync::Condvar提供这个机制。
use std::sync::{Arc, Condvar, Mutex};use std::{thread, time};fn main() {let pair = Arc::new((Mutex::new(false), Condvar::new()));let pair2 = Arc::clone(&pair);// Inside of our lock, spawn a new thread, and then wait for it to start.thread::spawn(move || {let (lock, cvar) = &*pair2;let mut started = lock.lock().unwrap();*started = true;let ten_millis = time::Duration::from_millis(10000);thread::sleep(ten_millis);// We notify the condvar that the value has changed.cvar.notify_one();});// Wait for the thread to start up.let (lock, cvar) = &*pair;let mut started = lock.lock().unwrap();while !*started {println!("1");started = cvar.wait(started).unwrap();println!("2");}}
cvar.wait会获取started(是MutexGuard)的所有权,等得到通知之后再返回它。在等待的时候cvar.wait会释放MutexGuard的锁,然后返回的时候再重新锁上。
除此之外Condvar还有其他的等待方法,比如按时间,详见std::sync::Condvar文档。
原子类型
std::sync::atomic包含一些不用锁的原子类型。这些类型的操作使用特定的方法
use std::sync::atomic::{AtomicIsize, Ordering};let atom = AtomicIsize::new(0);atom.fetch_add(1, Ordering::SeqCst);
fetch_add相当于+=。参数Ordering::SeqCst是memory ordering,类似于数据库的事务隔离级别。
原子类型的这个功能可以由mutex实现,但原子类型的性能更好,没有系统调用,且一般都能编译成一个CPU指令。原子类型也是一种形式的内部可变性,可以用来做全局变量。
全局变量
能做全局变量的只有const,static和原子类型。全局变量的初始化只能用字面量或const函数。原子类型的构建函数都是const函数。const函数的返回值是确定性的(deterministic),也就是只有参数决定而不受其他状态或IO的影响,这样编译器在编译的时候就能确定其值。
自定义const函数只需要加const修饰符。const函数不能用泛型参数,可以用lifetime参数。不能申请内存,不能操作裸指针。
对一些没有const函数作为构建函数的类型可以用lazy_static crate。
use lazy_static::lazy_static;use std::sync::Mutex;lazy_static! {static ref HOSTNAME: Mutex<String> = Mutex::new(String::new());}
这样声明的全局变量在第一次使用的时候才声明,之后就直接取。这种方法声明的全局变量在每次使用的时候会有一点性能损耗。其底层使用std::sync::Once实现。

若有收获,就点个赞吧
0 人点赞
