一些Unicode背景
ASCII, Latin-1, and Unicode
所有的ASCII码在Unicode里都有相同的编码值,范围是0-0x7f。0-0ff是ASCII的一个超集,是用来表示Western European languages字符的ISO/IEC 8859-1标准,在Unicode中被称为 Latin-1 code block。
因为ASCII和Latin-1和Unicode只有范围不一样,值都一样,所以char和另外两个的转换很容易
fn latin1_to_char(latin1: u8) -> char {latin1 as char}fn char_to_latin1(c: char) -> Option<u8> {if c as u32 <= 0xff {Some(c as u8)} else {None}}
UTF-8
字符utf-8编码是是一序列的1到4字节的编码。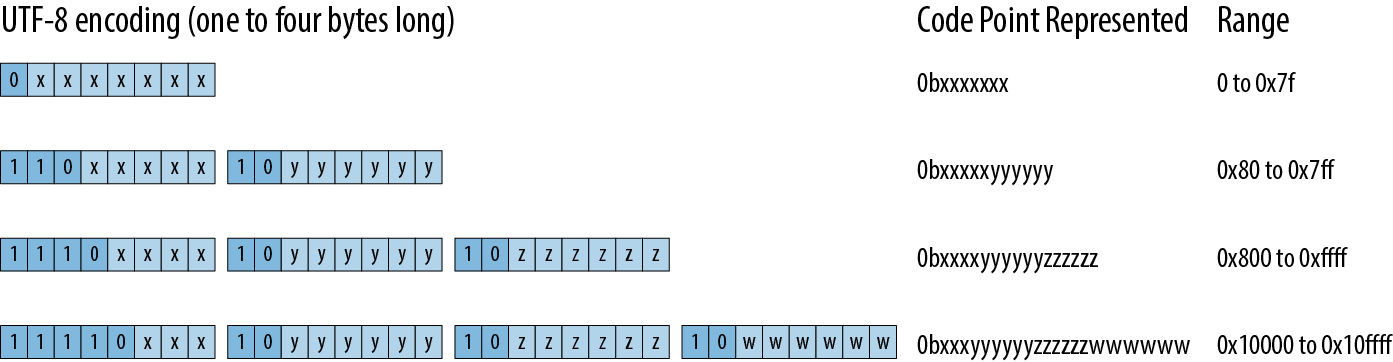
utf-8有两个规则,一个字符只有最短的表示方式是有效的;保留编码值和超出范围的编码是无效的,也就是说编码中没有0xd800到0xdfff和超过0x10ffff的值。
文本方向
对于读写方向是从右向左的语言,比如希伯来和阿拉伯,Unicode的存储字符串的方向也是从右向左的。
assert_eq!("ערב טוב".chars().next(), Some('ע'));
这是怎么实现的?按编码区来区分是那种语言吗?
字符(character,char)
Rust的字符是一个32位的值,保存一个Unicode编码。一个char的值确保是在0到0xd7ff和0xe000到0x10ffff的。
字符的分类
Unicode分类:
| Method | Description | Examples |
|---|---|---|
| ch.is_numeric() | A numeric character. This includes the Unicode general categories “Number; digit” and “Number; letter” but not “Number; other”. | ‘4’.is_numeric() ‘ᛮ’.is_numeric() ‘⑧’.is_numeric() |
| ch.is_alphabetic() | An alphabetic character: Unicode’s “Alphabetic” derived property. | ‘q’.is_alphabetic() ‘七’.is_alphabetic() |
| ch.is_alphanumeric() | Either numeric or alphabetic, as defined earlier. | ‘9’.is_alphanumeric() ‘饂’.is_alphanumeric() !’*’.is_alphanumeric() |
| ch.is_whitespace() | A whitespace character: Unicode character property “WSpace=Y”. | ‘ ‘.is_whitespace() ‘\n’.is_whitespace() ‘\u{A0}’.is_whitespace() |
| ch.is_control() | A control character: Unicode’s “Other, control” general category. | ‘\n’.is_control() ‘\u{85}’.is_control() |
ASCII相关分类
| Method | Description | Examples |
|---|---|---|
| ch.is_ascii() | An ASCII character: one whose code point falls between 0 and 127 inclusive. | ‘n’.is_ascii() !’ñ’.is_ascii() |
| ch.is_ascii_alphabetic() | An upper- or lowercase ASCII letter, in the range ‘A’..=’Z’ or ‘a’..=’z’. | ‘n’.is_ascii_alphabetic() !’1’.is_ascii_alphabetic() !’ñ’.is_ascii_alphabetic() |
| ch.is_ascii_digit() | An ASCII digit, in the range ‘0’..=’9’. | ‘8’.is_ascii_digit() !’-‘.is_ascii_digit() !’⑧’.is_ascii_digit() |
| ch.is_ascii_hexdigit() | Any character in the ranges ‘0’..=’9’, ‘A’..=’F’, or ‘a’..=’f’. | |
| ch.is_ascii_alphanumeric() | An ASCII digit or upper- or lowercase letter. | ‘q’.is_ascii_alphanumeric() ‘0’.is_ascii_alphanumeric() |
| ch.is_ascii_control() | An ASCII control character, including ‘DEL’. | ‘\n’.is_ascii_control() ‘\x7f’.is_ascii_control() |
| ch.is_ascii_graphic() | Any ASCII character that leaves ink on the page: neither a space nor a control character. | ‘Q’.is_ascii_graphic() ‘~’.is_ascii_graphic() !’ ‘.is_ascii_graphic() |
| ch.is_ascii_uppercase(), ch.is_ascii_lowercase() |
ASCII uppercase and lowercase letters. | ‘z’.is_ascii_lowercase() ‘Z’.is_ascii_uppercase() |
| ch.is_ascii_punctuation() | Any ASCII graphic character that is neither alphabetic nor a digit. | |
| ch.is_ascii_whitespace() | An ASCII whitespace character: a space, horizonal tab, line feed, form feed, or carriage return. | ‘ ‘.is_ascii_whitespace() ‘\n’.is_ascii_whitespace() !’\u{A0}’.is_ascii_whitespace() |
这些方法也适用于u8。
注意:Unicode和ASCII的一些分类标准不一定一样
let line_tab = '\u{000b}'; // 'line tab', AKA 'vertical tab'assert_eq!(line_tab.is_whitespace(), true);assert_eq!(line_tab.is_ascii_whitespace(), false);
数字字符
ch.to_digit(radix),radix是进制,如果ch是该进制的数字,返回Some(u),u是个u32,否则返回None。只适用于ASCII。
std::char::from_digit(num, radix):从数字转字符。如果大于10进制,字符是小写的。
ch.is_digit(radix)
大小写
ch.to_lowercase(), ch.to_uppercase():返回的是迭代器,Unicode里有些字母的大小写可能是多个字符。
// The uppercase form of the German letter "sharp S" is "SS":let mut upper = 'ß'.to_uppercase();assert_eq!(upper.next(), Some('S'));assert_eq!(upper.next(), Some('S'));assert_eq!(upper.next(), None);// Unicode says to lowercase Turkish dotted capital 'İ' to 'i'// followed by `'\u{307}'`, COMBINING DOT ABOVE, so that a// subsequent conversion back to uppercase preserves the dot.let ch = 'İ'; // `'\u{130}'`let mut lower = ch.to_lowercase();assert_eq!(lower.next(), Some('i'));assert_eq!(lower.next(), Some('\u{307}'));assert_eq!(lower.next(), None);
和整形的转换
转成的整形如果位数不够会截取
assert_eq!('B' as u32, 66);assert_eq!('饂' as u8, 66); // upper bits truncatedassert_eq!('二' as i8, -116); // same
从数字转字符,u8可以直接转,但u32会返回Option,因为有的u32不是有效的Unicode。
字符串String和str
String::new(),一开始并不会申请内存。
String::with_capacity(n),n是字节数,不是字符数。
to_owned和to_string的区别是什么???
字符串实现了std::fmt::Write,所以可以使用write和write!。
实现了Add<&str> and AddAssign<&str>所以可以用+和+=来拼接字符。左边的操作数必须是String,因为+需要去左边操作数的值也就是buffer内存,把右边的复制进去。
有一些类型向量的操作,但如果操作的索引不是完整的utf-8就会panic。所以类似slice[range],string.insert(i, ch),string.insert_str(i, slice), string.truncate(n), string.remove(i),string.drain(range),string.replace_range(range, replacement)等设计到范围和索引的方法,都有可能panic。
搜索的模式包括:1. 字符;2. 字符串或索引;3. 用来判断的函数;4. char的数组的切片,只要是出现在数组中的字符都会匹配到。其内部实现是实现了std::str::Pattern trait,但这个trait现在还不稳定,自己的代码里还不能用。搜索和替换相关的方法都接收Pattern作为参数。
查找方法slice.find(pattern), slice.rfind(pattern),返回的是字节的索引,不是字符的索引。
字符串生成的迭代器大多数是reversible的,但split类的除外,因为如果pattern是&str从不同的方向split,得到的结果可能是不一样。所以这类的split有r—版的。
解析字符串活动别的类型需要该类型实现std::str::FromStr。所有的基础类型都有。
如果一个类型实现了Display,Rust会自动实现ToString。
字符串转Vec
返回来有:str::from_utf8(byte_slice)从u8切片,不可变,返回Result<&str>。
String::from_utf8(vec)获取vec的所有权,返回Result
String::from_utf8_lossy(byte_slice)永远会成功,将无效的字节用代替符替换。返回Cow
str::from_utf8_unchecked和String::from_utf8_unchecked是unsafe函数,直接转换,不做检查。
Cow在字符串中使用很多,所以标准库为Cow<’a, str>实现了From,Into,std::ops::Add和std::ops::AddAssign等。
String实现了std::default::Default和std::iter::Extend。&str实现了Default。
值的格式化
格式化宏都是去参数的引用,不会获取所有权。
模板里的{...}被称作format parameters。里面的格式是{which:how},两个都可以忽略。
| Template string | Argument list | Result |
|---|---|---|
| “number of {}: {}” | “elephants”, 19 | “number of elephants: 19” |
| “from {1} to {0}” | “the grave”, “the cradle” | “from the cradle to the grave” |
| “v = {:?}” | vec![0,1,2,5,12,29] | “v = [0, 1, 2, 5, 12, 29]” |
| “name = {:?}” | “Nemo” | “name = \“Nemo\“” |
| “{:8.2} km/s” | 11.186 | “ 11.19 km/s” |
| “{:20} {:02x} {:02x}” | “adc #42”, 105, 42 | “adc #42 69 2a” |
| “{1:02x} {2:02x} {0}” | “adc #42”, 105, 42 | “69 2a adc #42” |
| “{lsb:02x} {msb:02x} {insn}” | insn=”adc #42”, lsb=105, msb=42 | “69 2a adc #42” |
| “{:02?}” | [110, 11, 9] | “[110, 11, 09]” |
| “{:02x?}” | [110, 11, 9] | “[6e, 0b, 09]” |
格式化文本
字符串:
| Features in use | Template string | Result |
|---|---|---|
| Default | “{}” | “bookends” |
| Minimum field width | “{:4}” | “bookends” |
| “{:12}” | “bookends “ | |
| Text length limit | “{:.4}” | “book” |
| “{:.12}” | “bookends” | |
| Field width, length limit | “{:12.20}” | “bookends “ |
| “{:4.20}” | “bookends” | |
| “{:4.6}” | “booken” | |
| “{:6.4}” | “book “ | |
| Aligned left, width | “{:<12}” | “bookends “ |
| Centered, width | “{:^12}” | “ bookends “ |
| Aligned right, width | “{:>12}” | “ bookends” |
| Pad with ‘=’, centered, width | “{:=^12}” | “==bookends==” |
| Pad ‘*’, aligned right, width, limit | “{:*>12.4}” | “**book” |
Rust对所有的字符都当作相同的宽度,对一些附加的声调符号或不同宽度的字符都一样。
要准确的处理宽度应该在具体的平台上比如浏览器实现,或用crate,如unicode-width。
数字:
| Features in use | Template string | Result |
|---|---|---|
| Default | “{}” | “1234” |
| Forced sign | “{:+}” | “+1234” |
| Minimum field width | “{:12}” | “ 1234” |
| “{:2}” | “1234” | |
| Sign, width | “{:+12}” | “ +1234” |
| Leading zeros, width | “{:012}” | “000000001234” |
| Sign, zeros, width | “{:+012}” | “+00000001234” |
| Aligned left, width | “{:<12}” | “1234 “ |
| Centered, width | “{:^12}” | “ 1234 “ |
| Aligned right, width | “{:>12}” | “ 1234” |
| Aligned left, sign, width | “{:<+12}” | “+1234 “ |
| Centered, sign, width | “{:^+12}” | “ +1234 “ |
| Aligned right, sign, width | “{:>+12}” | “ +1234” |
| Padded with ‘=’, centered, width | “{:=^12}” | “====1234====” |
| Binary notation | “{:b}” | “10011010010” |
| Width, octal notation | “{:12o}” | “ 2322” |
| Sign, width, hexadecimal notation | “{:+12x}” | “ +4d2” |
| Sign, width, hex with capital digits | “{:+12X}” | “ +4D2” |
| Sign, explicit radix prefix, width, hex | “{:+#12x}” | “ +0x4d2” |
| Sign, radix, zeros, width, hex | “{:+#012x}” | “+0x0000004d2” |
| “{:+#06x}” | “+0x4d2” |
浮点数
| Features in use | Template string | Result |
|---|---|---|
| Default | “{}” | “1234.5678” |
| Precision | “{:.2}” | “1234.57” |
| “{:.6}” | “1234.567800” | |
| Minimum field width | “{:12}” | “ 1234.5678” |
| Minimum, precision | “{:12.2}” | “ 1234.57” |
| “{:12.6}” | “ 1234.567800” | |
| Leading zeros, minimum, precision | “{:012.6}” | “01234.567800” |
| Scientific | “{:e}” | “1.2345678e3” |
| Scientific, precision | “{:.3e}” | “1.235e3” |
| Scientific, minimum, precision | “{:12.3e}” | “ 1.235e3” |
| “{:12.3E}” | “ 1.235E3” |
debug:{:?},比较好看的debug{:#?}
指针:{:p}
运行时决定格式化参数:format!(“{:>1$}”, content, get_width()),其中1$表示取第一个参数的值。这个值必须是个u32。
实现自定义类型的格式化,需要实现不同的trait来实现不同的格式化参数
| Notation | Example | Trait | Purpose |
|---|---|---|---|
| none | {} | std::fmt::Display | Text, numbers, errors: the catchall trait |
| b | {bits:#b} | std::fmt::Binary | Numbers in binary |
| o | {:#5o} | std::fmt::Octal | Numbers in octal |
| x | {:4x} | std::fmt::LowerHex | Numbers in hexadecimal, lowercase digits |
| X | {:016X} | std::fmt::UpperHex | Numbers in hexadecimal, uppercase digits |
| e | {:.3e} | std::fmt::LowerExp | Floating-point numbers in scientific notation |
| E | {:.3E} | std::fmt::UpperExp | Same, uppercase E |
| ? | {:#?} | std::fmt::Debug | Debugging view, for developers |
| p | {:p} | std::fmt::Pointer | Pointer as address, for developers |
实现的方法都是将字符串写道Formatter里,formatter还带着格式化参数的信息
trait Display {fn fmt(&self, dest: &mut std::fmt::Formatter)-> std::fmt::Result;}impl fmt::Display for Complex {fn fmt(&self, dest: &mut fmt::Formatter) -> fmt::Result {let (re, im) = (self.re, self.im);if dest.alternate() {let abs = f64::sqrt(re * re + im * im);let angle = f64::atan2(im, re) / std::f64::consts::PI * 180.0;write!(dest, "{} ∠ {}°", abs, angle)} else {let im_sign = if im < 0.0 { '-' } else { '+' };write!(dest, "{} {} {}i", re, im_sign, f64::abs(im))}}}
dest.alternate()用来取格式化参数里的#。
虽然fmt方法返回一个Result,但这个Result只应该又write返回,用户自己的逻辑不应该产生错误。
在自己的代码里利用格式化语言:
主要是利用format_args!宏来收集模板和参数,然后传递给写输出函数
fn logging_enabled() -> bool { ... }use std::fs::OpenOptions;use std::io::Write;fn write_log_entry(entry: std::fmt::Arguments) {if logging_enabled() {// Keep things simple for now, and just// open the file every time.let mut log_file = OpenOptions::new().append(true).create(true).open("log-file-name").expect("failed to open log file");log_file.write_fmt(entry).expect("failed to write to log");}}write_log_entry(format_args!("Hark! {:?}\n", mysterious_value));
format_args是懒惰的,在传递参数的时候并没有做任何格式化的工作,所以如果logging_enabled的返回是false,则不用做任何工作。
这个函数还可以包装到宏里:
macro_rules! log { // no ! needed after name in macro definitions($format:tt, $($arg:expr),*) => (write_log_entry(format_args!($format, $($arg),*)))}log!("O day and night, but this is wondrous strange! {:?}\n",mysterious_value);
正则表达式
官方维护的regex包,不支持反向引用和LookAround。Regex::new(r"(\d+)\.(\d+)\.(\d+)(-[-.[:alnum:]]*)?")?创建一个新的正则表达式,返回Result。.is_match(haystack)判断是不是有匹配。
.captures(haystack)查找第一个匹配,返回一个Result
let captures = semver.captures(haystack).ok_or("semver regex should have matched")?;assert_eq!(&captures[0], "0.2.5");assert_eq!(&captures[1], "0");assert_eq!(&captures[2], "2");assert_eq!(&captures[3], "5");
find_iter返回一个Matches迭代器,其中每个元素是一个不交叉的匹配。Matches的每个元素是一个Match,其本质上是原字符串的一个切片索引。可以用as_str方法取出一个&str。
captures_iter类似,返回一个组的迭代器。匹配组速度比较慢。
创建Regex是一个很重的操作。
归一化normalization
Unicode中相同的字符有不同的表示方式。用那种方式表示对字符串的行为有很大的影响。字符é既有组合表示方式(composed form)0xe9也有组合形式,也有拆成字母和注音符号的分解表示方式(decomposed form)e\u{301}。两种方式,在比较,哈希的时候有不同的结果。这样在map这类的数据结构中有很大的问题。所以需要归一化。
归一化有两种考虑:
- 使用尽可能组合的方式还是分解的方式:组合的方式有更好的兼容性,因为编码和变现是一样的,比如长度。分解方式更适合展示和搜索,因为他提供更详细的内容。
- 一个字符可能有不同的展示格式,是不是应该按相同的字符对待:比如数字有角标的形式。还有连字
ffi (\u{fb03}),组合的方式按原字符表示,分解方式按连字和表现形式表示。
所以有两种归一化方式:Normalization Form C 和 Normalization Form D (NFC,NFD)。分别表示组合的表示方式和分解的方式,用来解决第一个考虑,但并不设计第二个。NFKC 和 NFKD用来解决第二个问题。World Wide Web建议所有的内容都用NFC来归一化,Unicode Identifier and Pattern Syntax annex建议编程语言的标识符用NFKC。
unicode-normalization crate提供归一化的工具,将UnicodeNormalization引入后,&str就会有函数来返回归一化后的迭代器
use unicode_normalization::UnicodeNormalization;// No matter what representation the left-hand string uses// (you shouldn't be able to tell just by looking),// these assertions will hold.assert_eq!("Phở".nfd().collect::<String>(), "Pho\u{31b}\u{309}");assert_eq!("Phở".nfc().collect::<String>(), "Ph\u{1edf}");// The left-hand side here uses the "ffi" ligature character.assert_eq!("① Di\u{fb03}culty".nfkc().collect::<String>(), "1 Difficulty");
归一化保证幂等性。
归一化的字符串分成多个子串保证保持归一化。
将两个归一化字符串拼成一个不能保证。
Unicode标准保证如果不适用未定义的码,保证归一化的值永远不变。

若有收获,就点个赞吧
0 人点赞
