1. 概述
MNN 工作台目标检测训练模版用来产出目标检测模型,可以用来识别并标定图像中不同物体的类目以及所处位置问题。目前 MNN 工作台内置 MNN 团队自行基于迁移学习优化的 FastDetection 模型。
2. 模型训练
2.1 制作目标检测数据集
目标检测训练数据集包含图片和标签两类数据,其中,图片文件支持JPG和PNG格式,标签文件支持xml格式。
在 MNN 工作台中内置提供了相关标注工具 Label Image,具体标注使用流程请参考《5.5 图像标注工具 Label Image》
数据格式需求请参考《5.5 图像标注工具 Label Image》,否则会导致训练出错。
标注中请勿添加中文标注,会出错。
标注中请勿添加中文标注,会出错。
标注中请勿添加中文标注,会出错。**
2.2 创建工程
- 打开 MNN 工作台,进入工作台主界面。
图例 1. MNN 工作台主界面
- 点击
Train a deep learning model,进入模型训练页面。
图例 2. MNN 工作台模型训练模版选择界面
- 图片分类工程在
Image分类下,点击Image栏,找到并点击Object Detection。首次/更新使用需联网,MNN 工作台会不定期更新最好用的训练模版
图例 3. MNN 工作台目标检测模型下载
- 下载完成,点击
Next进入项目配置页面,在Project Name上出入项目名称,比如ObjectDetection,点击Next
图例 4. MNN 工作台目标检测工程配置
- 选择目标文件夹,对工程进行保存。
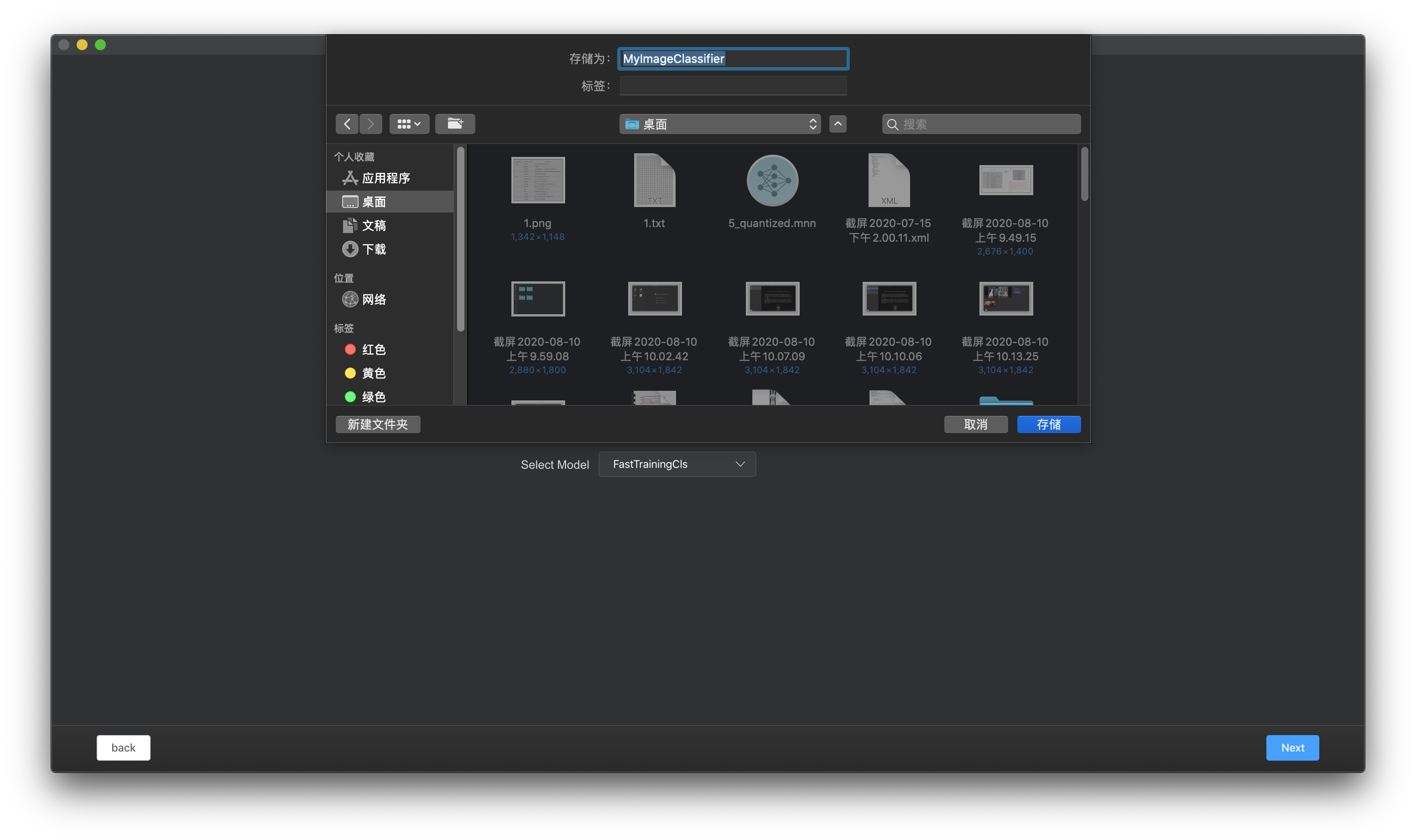
图例 5. MNN 工作台选择工程保存路径
- 点击
Next,进入训练工程界面。工作台会自动配置训练环境,首次使用需联网加载相关配置,请耐心等候。
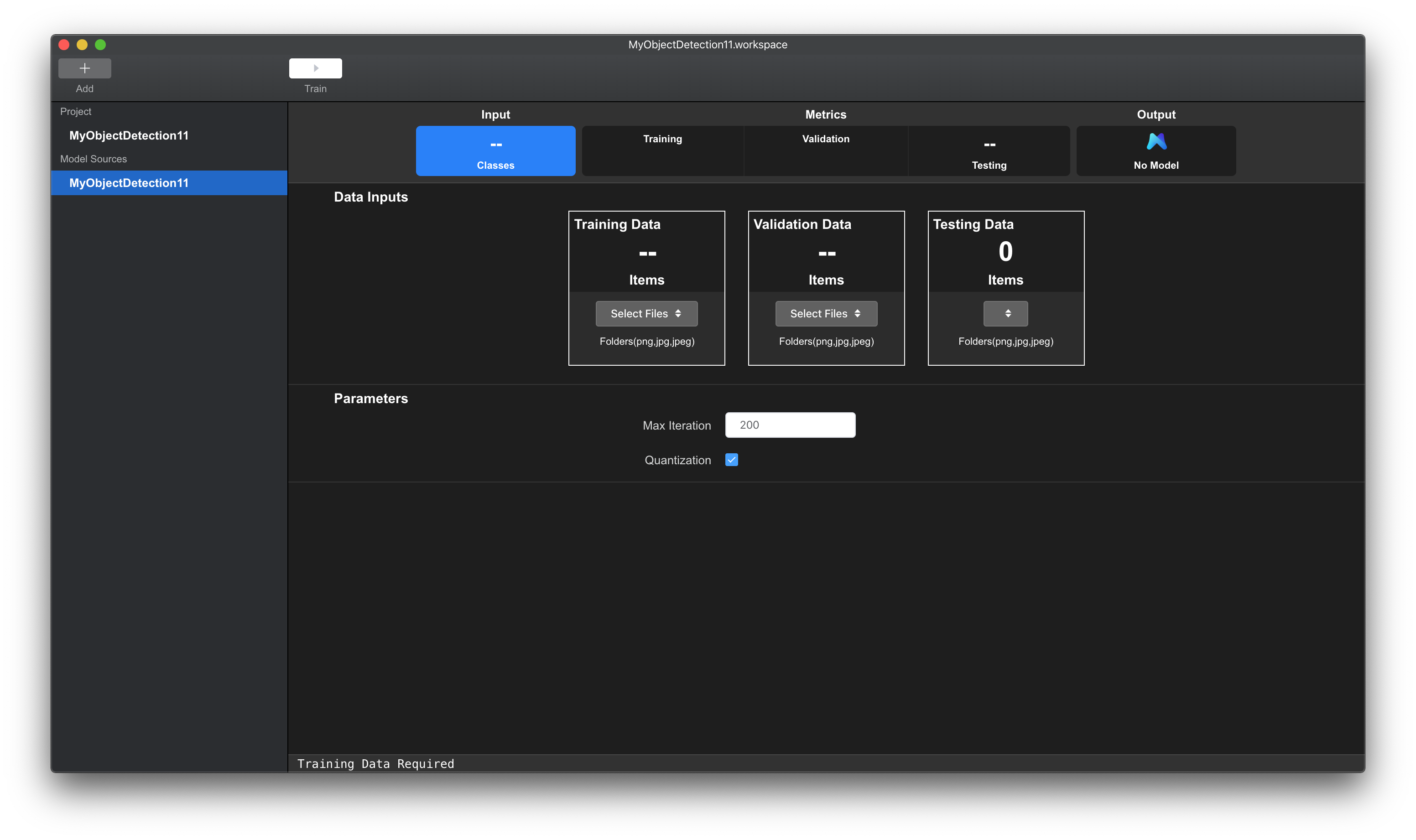
图例 6. MNN 工作台训练工程初始化
2.3 训练流程
训练页面中存在两个配置模块:
Data Inputs,数据输入模块。主要进行数据相关操作。Training Data,选择训练数据集。Validation Data,选择验证数据集。可选。Testing Data,选择测试数据集。可选。
Parameters,参数配置模块。用于调节模型训练的相关参数。
此处有一个训练相关的超级参数Max Iteration,工作台会推荐一个默认值,如200。 用户可以根据自己的需求进行修改。 理论上Max Iteration越大,模型对训练数据集的拟合越好,但是耗时同时会更长。
图例 7. MNN 工作台训练界面功能区块
点击Training Data中的Select Files,选择训练数据集所在的文件夹,该文件夹应当包块图片以及对应的标注标签。工作台会自动读取该文件夹下的数据,并显示数据类别数量以及推荐迭代次数Max Iteration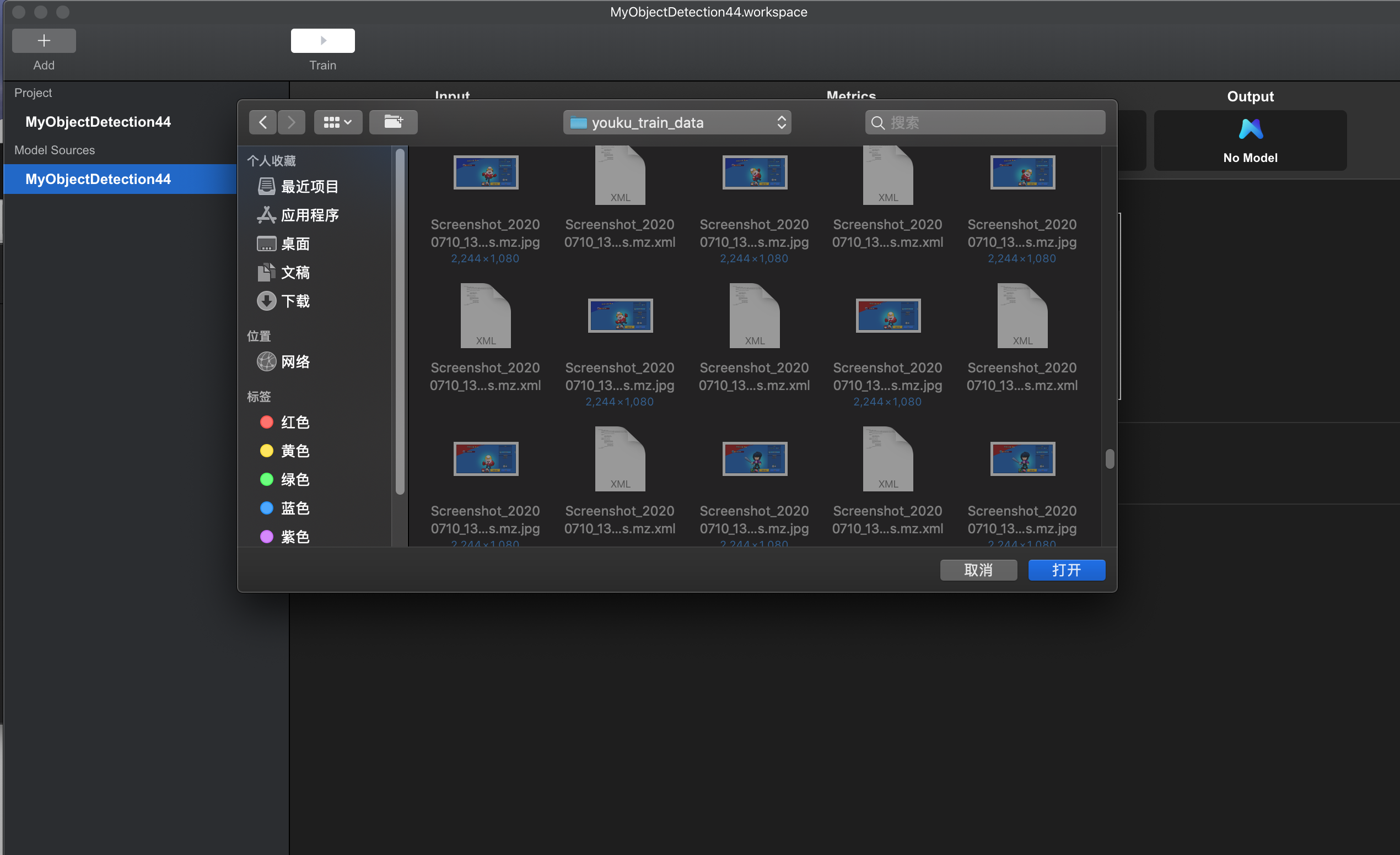
图例 8. MNN 工作台选择目标检测数据集
点击上方的Train按钮,进入训练状态,界面会展示训练进度条。
训练需要一段时间,耐心等待。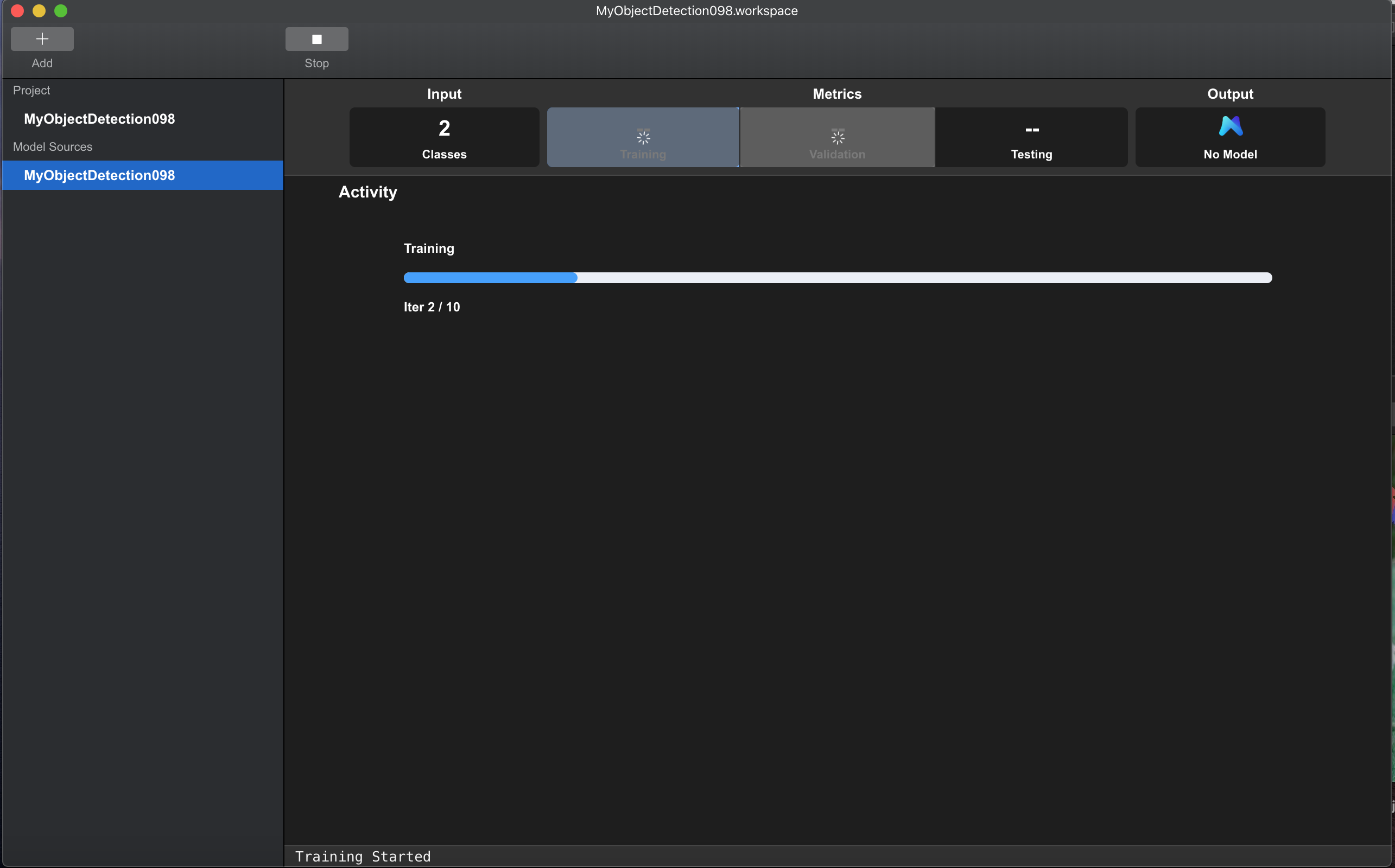
图例 9. MNN 工作台训练中
模型完成训练后,工作台会展示模型训练结果。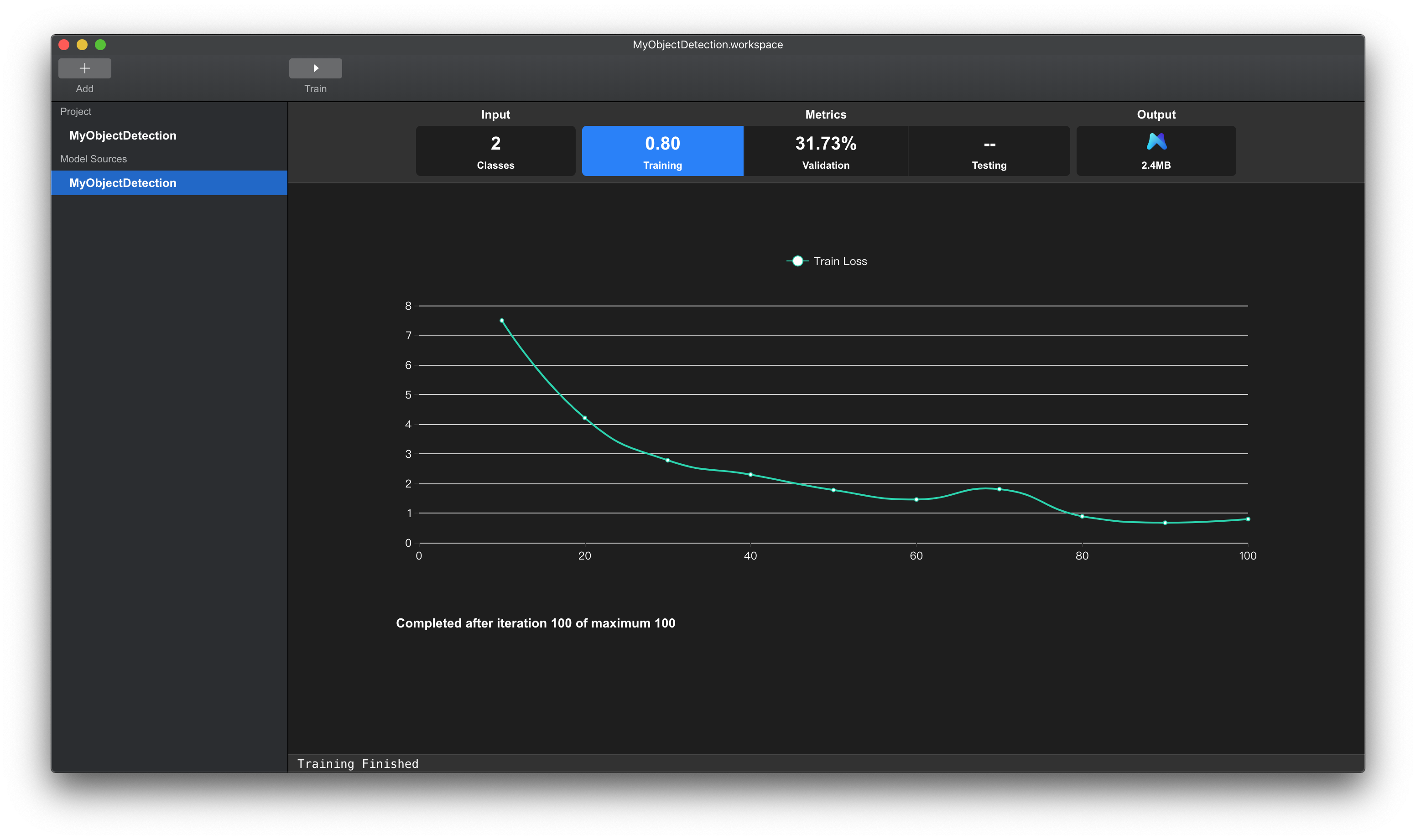
图例 10. MNN 工作台训练完成 Training Loss 界面
该页面包括数值栏和图表栏:
- 数值栏展示的最终模型的状态,分别训练结束时模型在训练集损失数值,在验证集上的准确率以及模型大小。
- 图表栏展示训练过程中一些与训练相关的数据变化趋势。
上方Tab页Training项中的数值(0.80)表示训练完成时,模型在训练数据集上面的损失数值。
该数值越低表示模型对训练数据集拟合的越好。
下方图表栏显示的是在模型训练过程中损失值的变化曲线。
可以发现该曲线后端还没有平稳,模型还没有完全拟合训练集,说明可以适当增加迭代次数,增强模型的拟合能力。
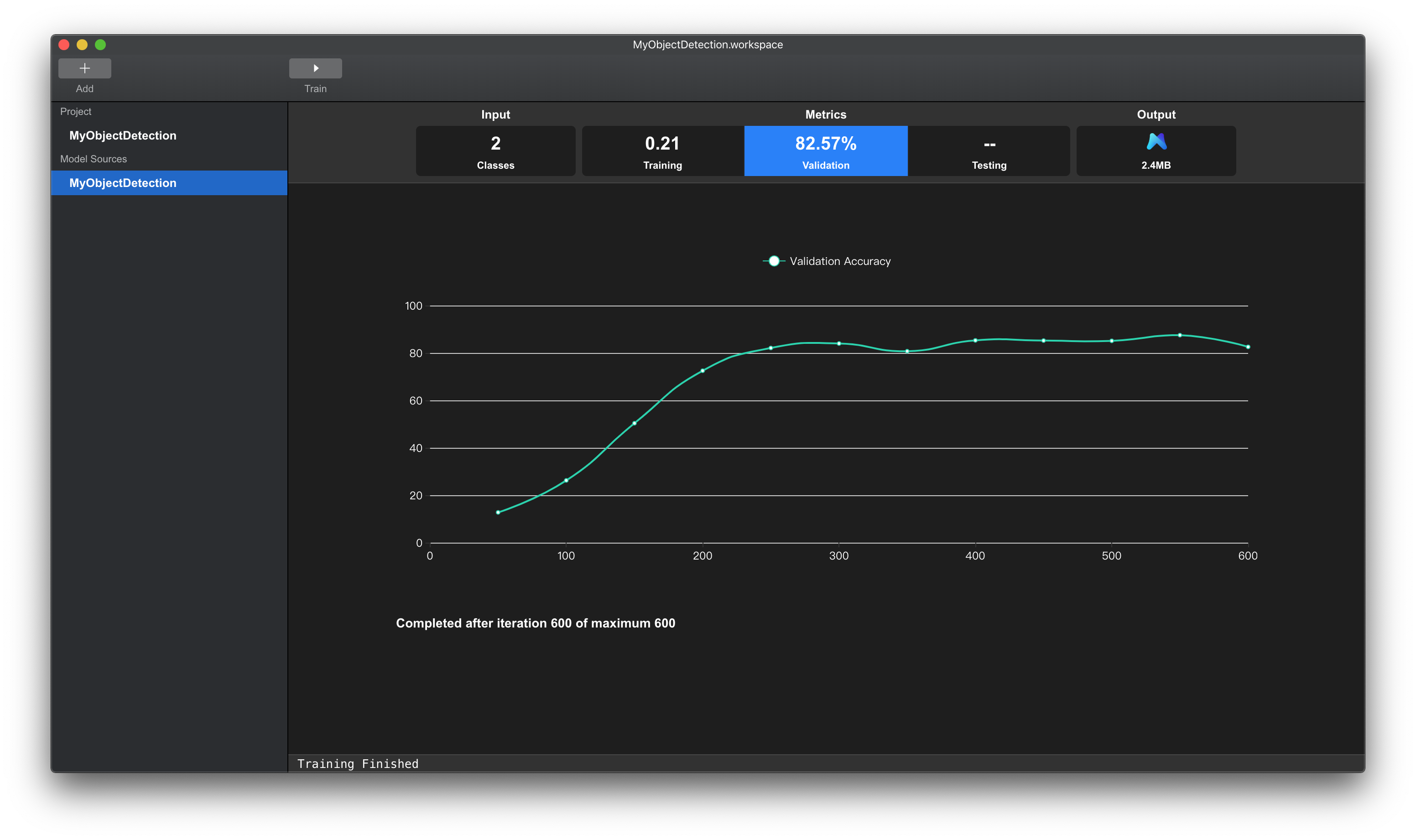
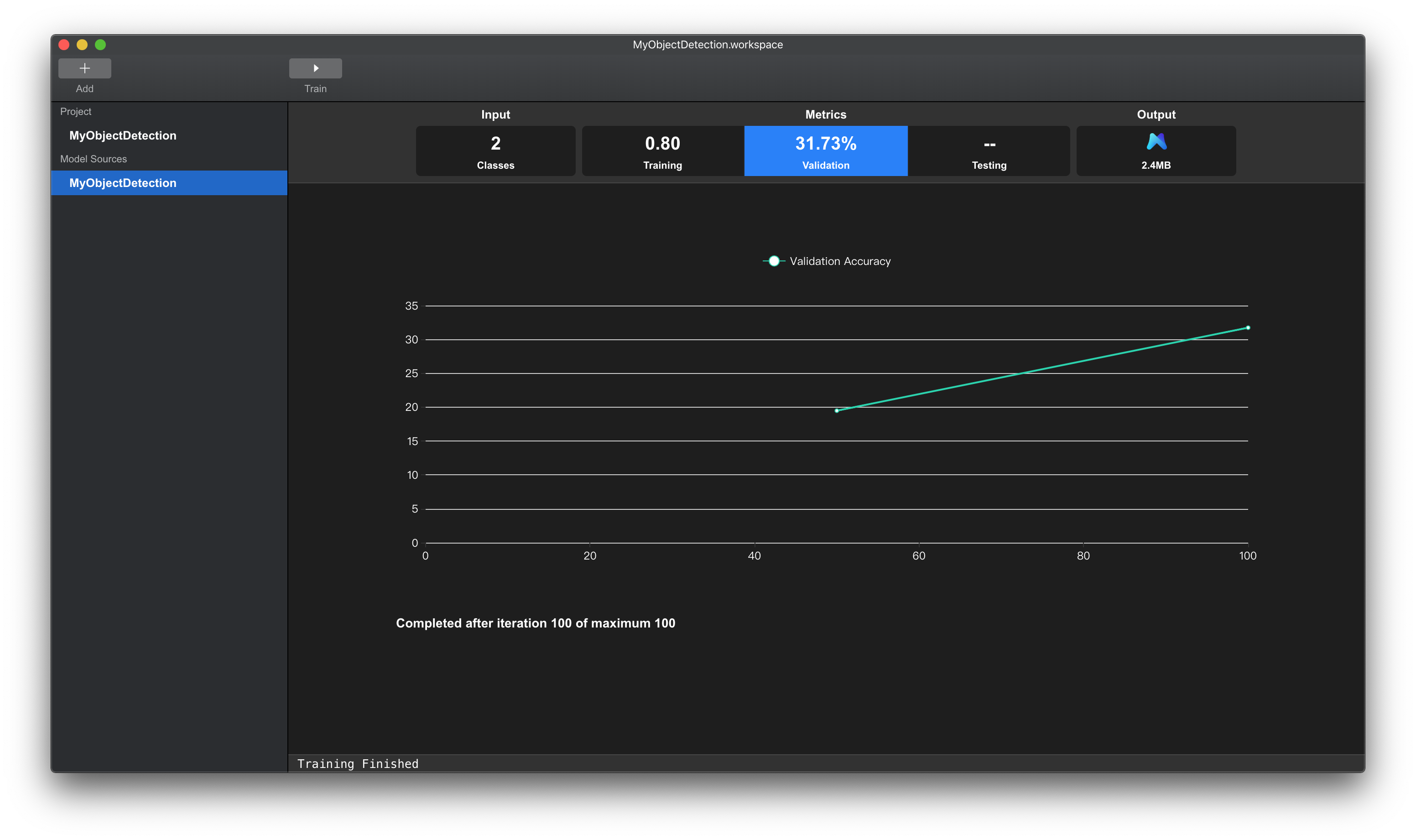
点击上方tab页的Validation项。Validation项中的数据表示模型在验证集上的mAP(mean average precision)。
该数值表示该模型在验证集上的泛化能力,数值越大,表示模型越好。
下方图表显示在训练阶段,验证集上准确率的变化曲线。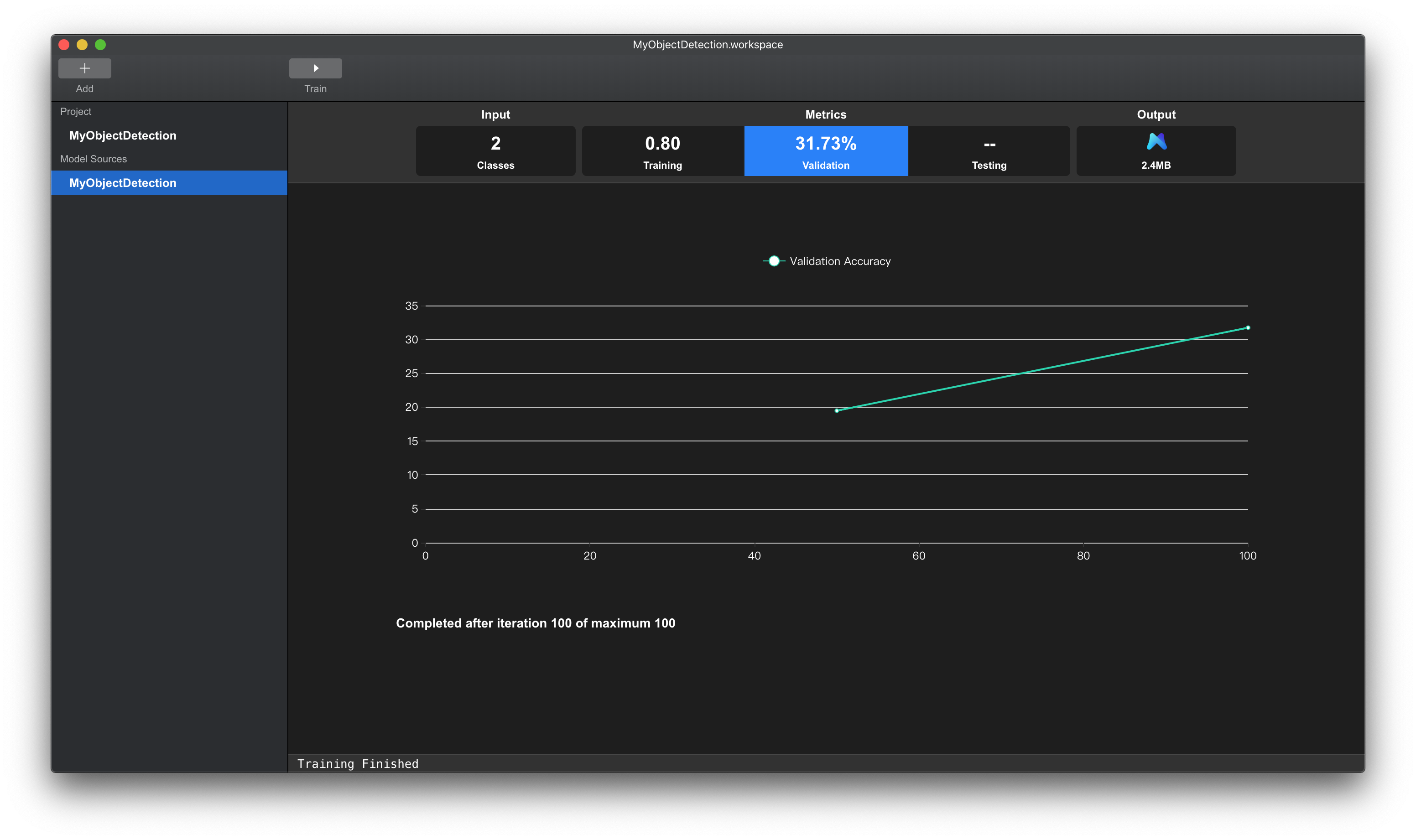
图例 10. MNN 工作台训练完成 Validation 界面
3. 模型输出与测试
3.1. 模型输出
点击上方tab页的Output项,进入Output页面。Output项中的数值表示模型大小,当前模型大小为2.4MB。**`
3.2. 模型测试
在Output页面,将测试的图片拖入左边栏,点击图片,即可显示测试结果。
测试结果包括目标框位置,类别以及预测概率。页面具有以下功能:
- 拖动
Thresh滑动条,可以控制最低概率,调整模型输出结果。 - 点击下方单选框,可以选中对应的预测框。选中的预测框变为黄色。
- 可以通过鼠标拖拽改变选中的预测框的位置和大小。
- 双击单选框中的标签(带有下划线部分),可以编辑预测框对应的标签。
- 点击Delete按钮,可以删除选中的预测框。
- 点击Save按钮,可以将当前展示的所有预测框,保存到文件中,格式为
VOC格式,保存路径为图片所在的路径(Save按钮左侧展示的路径)。文件名与图片相同。
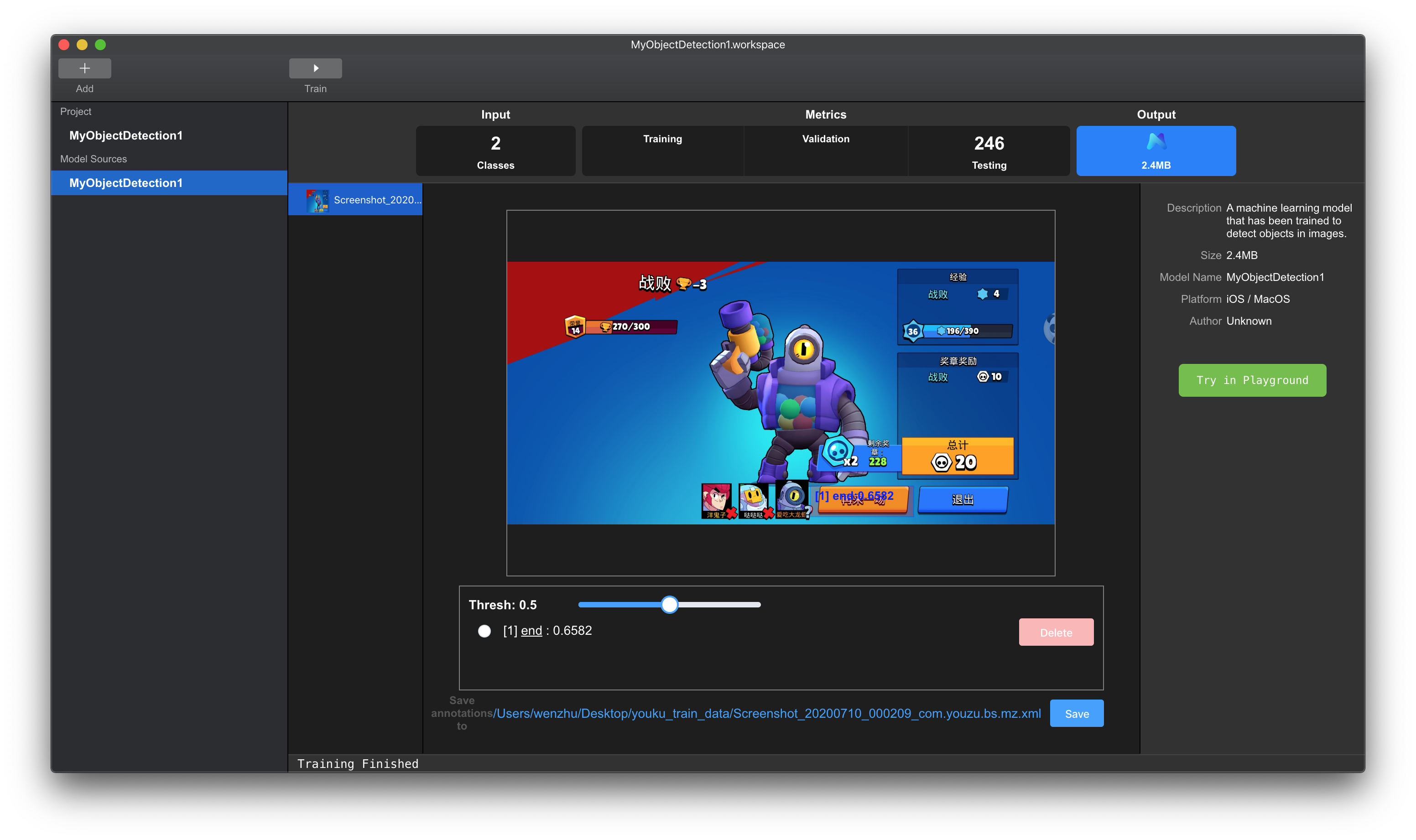
图例 10. MNN 工作台所见即所得验证界面
3.3 批量测试与半自动标注
当我们在已有训练数据集上完成对模型的充分训练之后,可以利用模型对未标注数据进行批量预测和半自动标注。具体的,点击Testing选项,点击Select按钮,选择待标注数据文件夹。点击Test Model按钮,模型进行批量预测,如下图所示。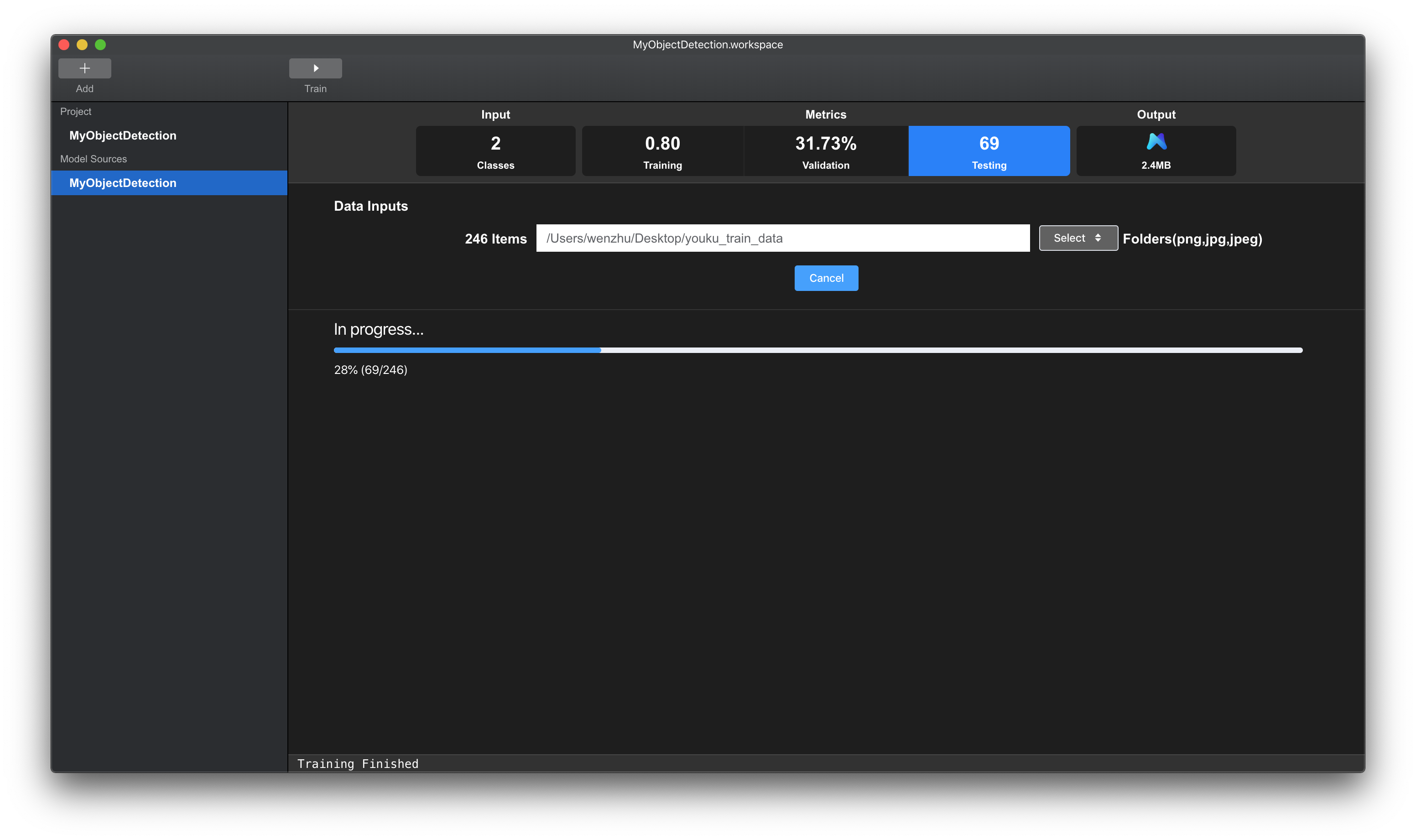
图例 10. MNN 工作台批量验证界面
待批量预测完成后,界面会显示模型预测结果,如下图所示。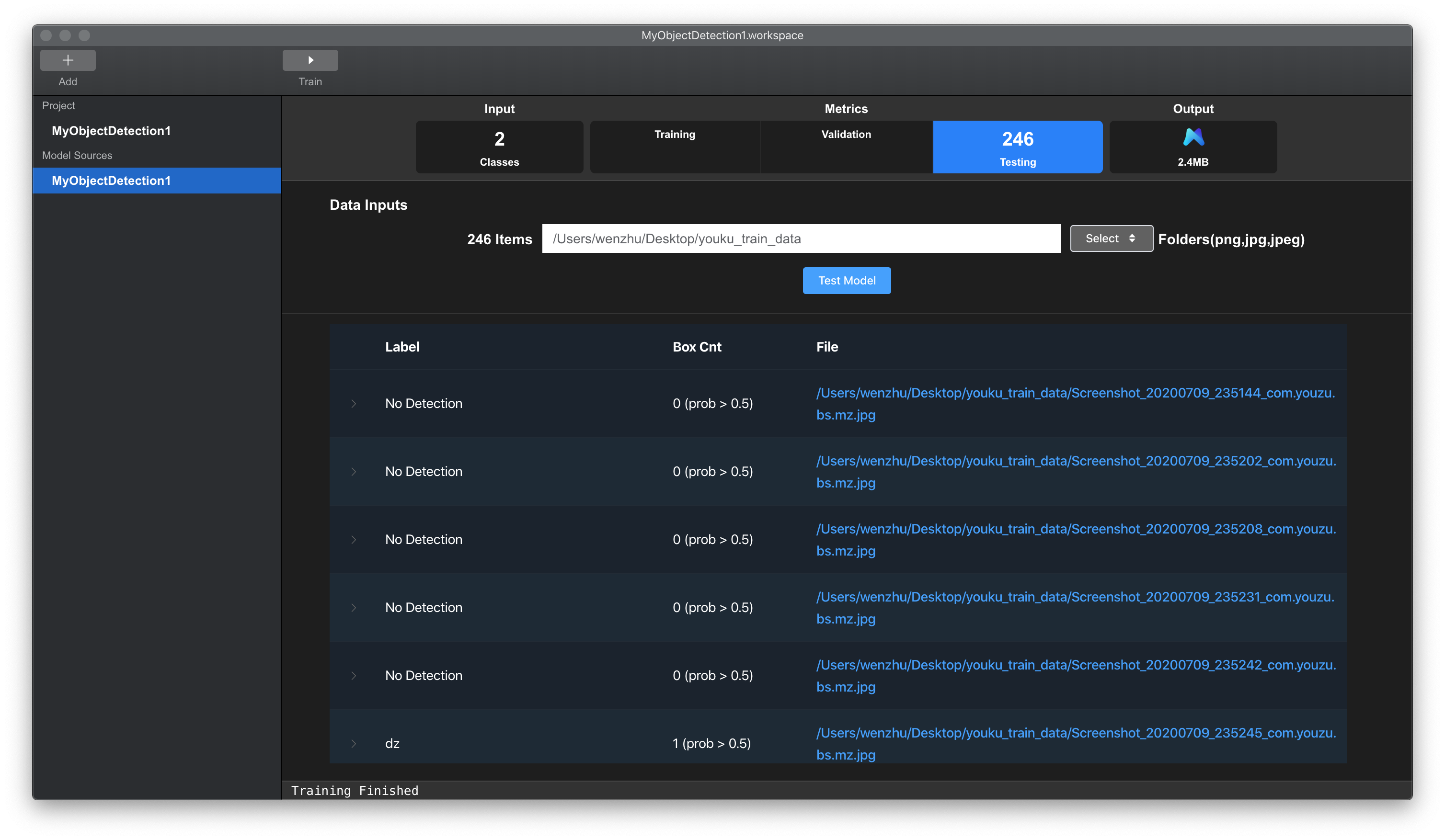
图例 10. MNN 工作台批量验证结果
测试结果以表格形式展示:
Label列,该图片中预测出的所有标签。Box Cnt列,设定概率下,预测框的个数。括号中显示当前最小概率,低于该概率的预测框被排除。File列,图片文件路径。点击可打开图片所在的文件夹。
点击行左侧的灰色箭头(>),会展开显示图片和预测结果,我们可以根据模型预测结果动态调整模型预测框,如下图所示。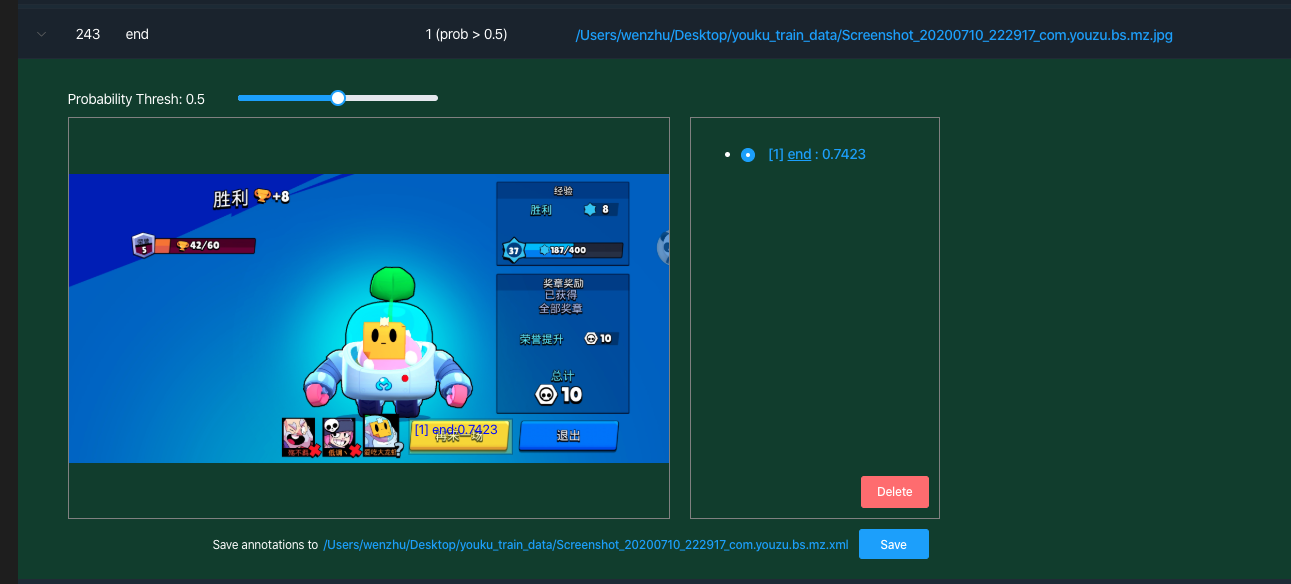
图例 11. MNN 工作台批量验证结果详细信息
也可以通过双击预测结果界面右侧的标签来修改目标检测框标签。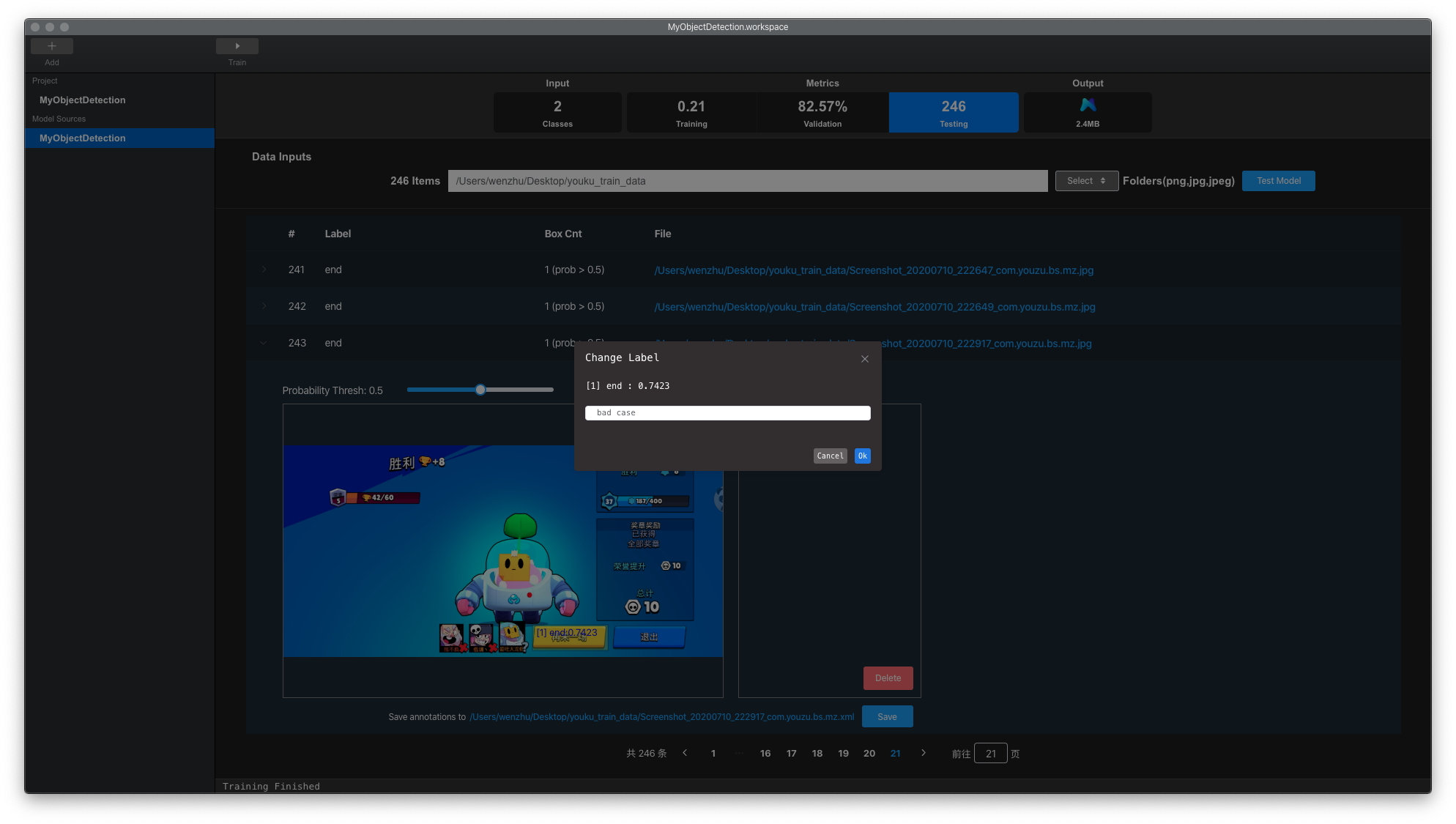
图例 11. MNN 工作台批量验证结果详细信息
当修改完成后,我们点击Save按钮,标签会保存在该数据文件夹中,标签与图片同名。
4. Try in Playground
MNN 工作台图像训练模版在训练完成得到 MNN 模型后,可以通过点击训练结果界面的 Try in Playground 进入三端一体的 Playground 体验环节。具体请阅读《4.1 Playground 整体介绍》
图例 12. MNN 工作台结果页 Try in Playground
5. 常见问题与答疑
5.1 如何判断模型是否训练充分?
目标检测在图像型机器学习任务属于相对较复杂的一类,结果可能因为训练的次数差异天差地被。判断模型是否充分训练主要观察训练页面中的Training Loss和Validation Accuracy两个指标的曲线变化趋势。
如果发现这Training Loss曲线与Validation Accuracy曲线出现平稳,不再大幅的减小或者增长,如下图所示,则表示模型在当前训练数据集上已经训练充分。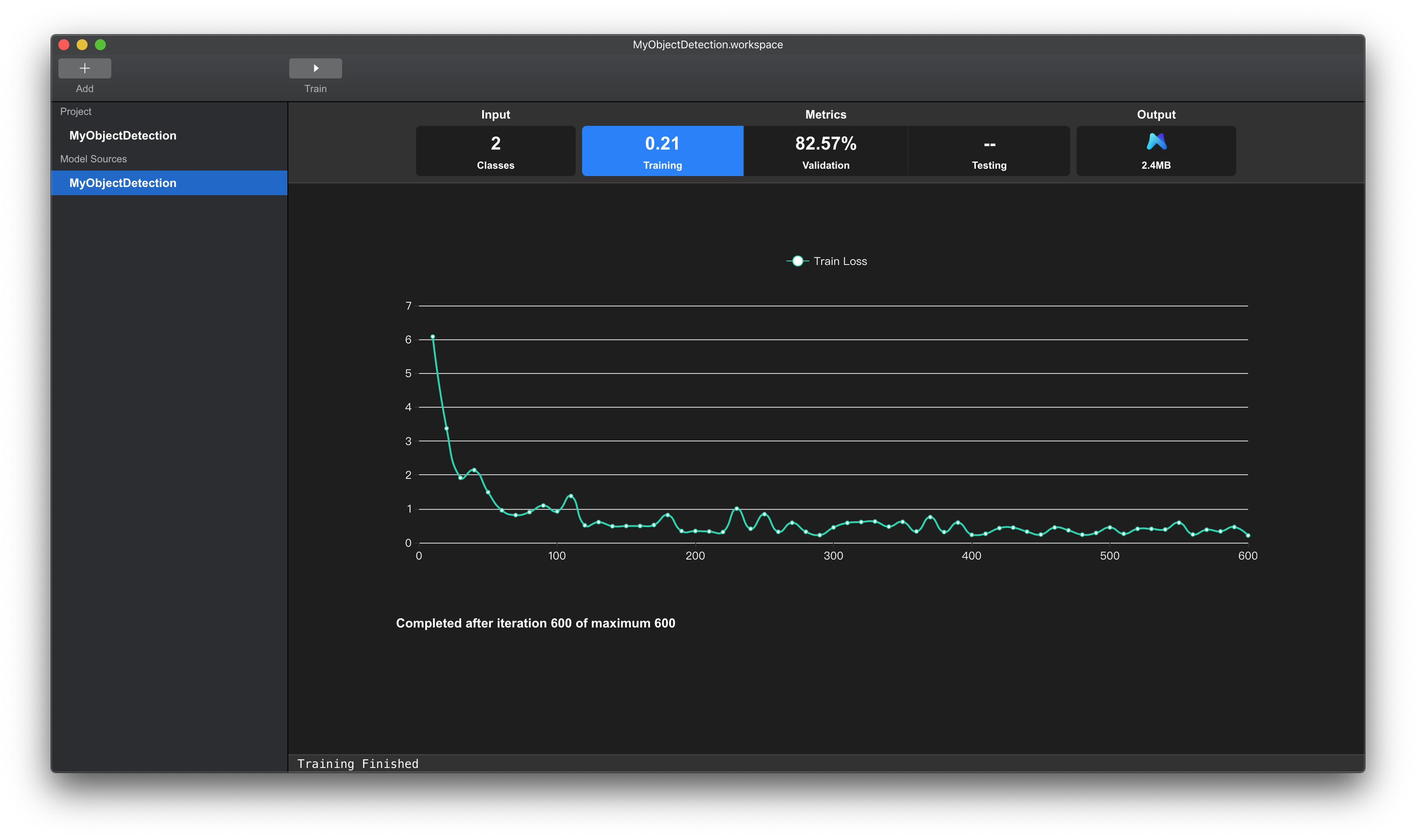
如果发现Training Loss曲线并不平稳且有下降趋势,同时Validation Accuracy曲线也不平稳且有上升趋势,如下图所示,表明模型还未充分拟合训练数据集,模型训练不充分。此时,可以直接点击Train按钮,再训练一次,直到两条训练曲线趋于平稳。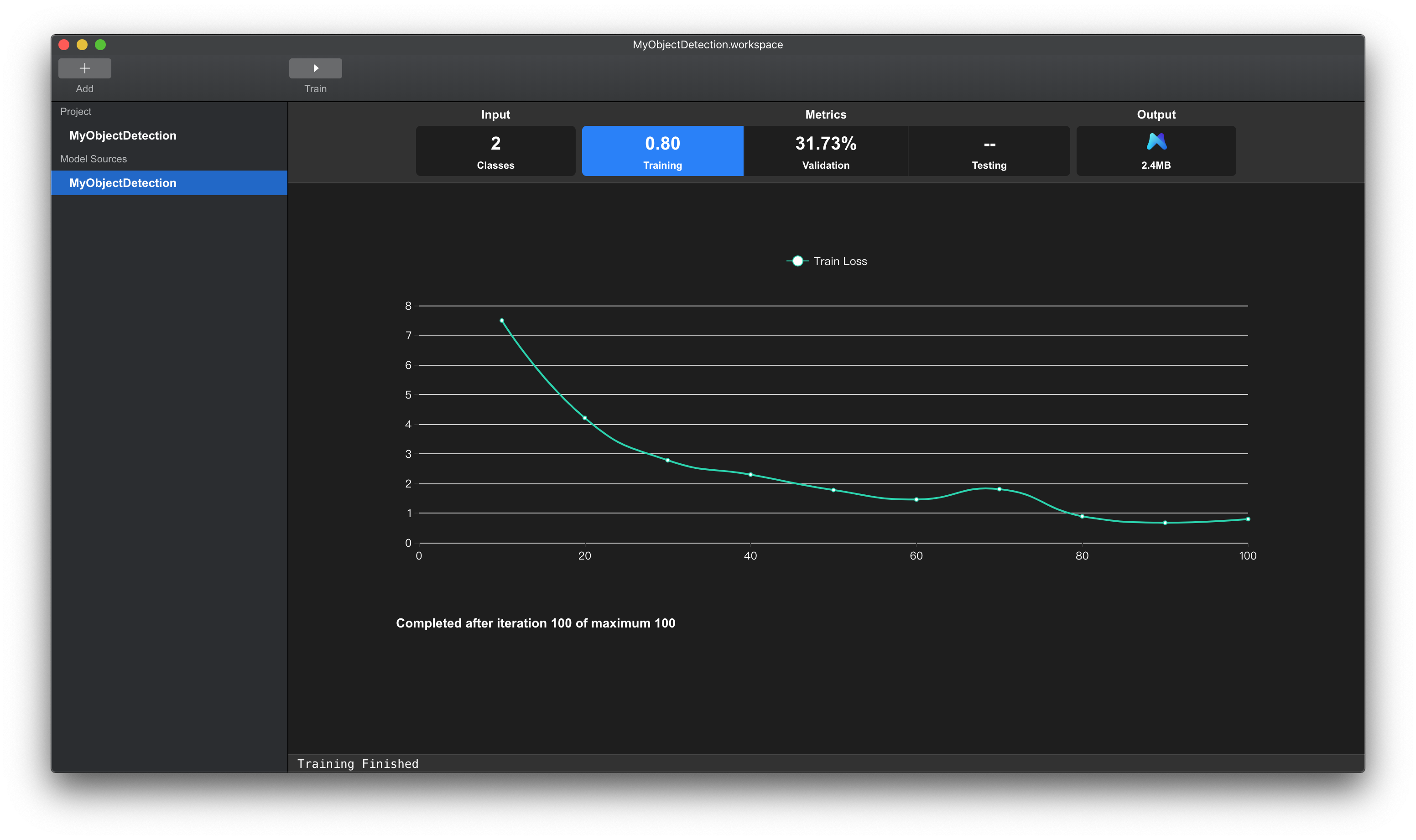
5.2 如何设置预测置信截断阈值?
模型预测结果主要有三项,即预测目标框,目标类别以及置信度。以下图为例,模型预测的类别为"end",预测得分为0.6713,且在相应区域标注了检测目标框。我们在工作台测试界面上设置了一个Probability Thresh动态条,可以用于调节滤除输出结果的概率阈值。当Probability Thresh设置为0.5时,可以发现界面显示模型输出结果。当Probability Thresh设置为0.68时,模型输出结果被滤除,该页面没有模型输出结果,如下图所示。由此可知Probability Thresh设置的越高,模型输出的目标检测框对应的得分值越高,模型的误检率越低,但同时也可能会<br />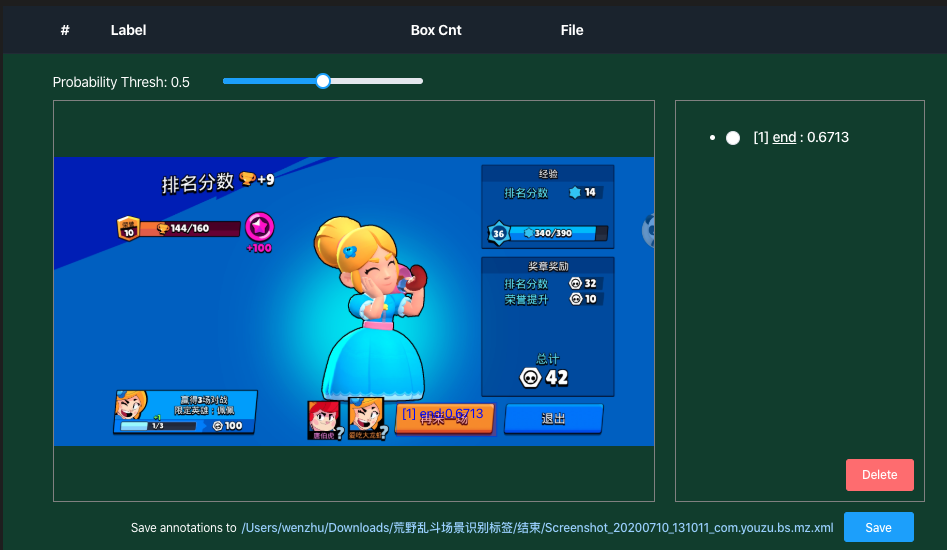 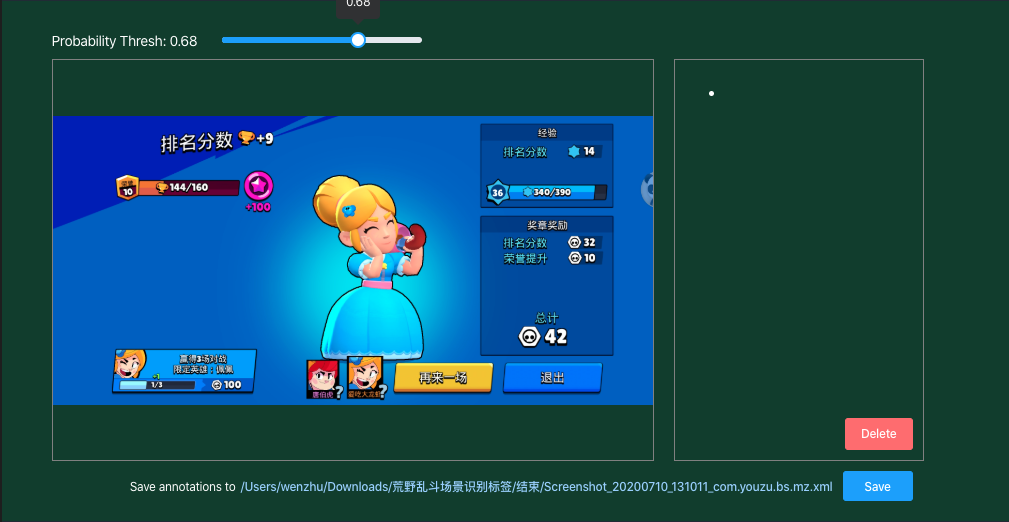<br />带来一定层度的漏检。如果Probability Thresh设置的越低,模型能够输出更多的目标检测框,可以提升物体的检出率,但是会带来一定层度的误检。用户可以在一批测试数据集中调试Probability Thresh,通过调试设置一个合适的Probability Thresh,使得模型的检出率和误检率在对应业务上取得平衡。
5.3 如何减少模型的误检率?
根据业务需求合理的设置Probability Thresh能够有效的抑制目标误检,在5.2中我们知道Probability Thresh设置的越高,要求模型输出的目标检测框置信度越高,模型越不容易产生误检。
当训练数据较少时,产生的模型的泛化能力有限,造成误检产生的部分检测框置信值也很高,如大于0.7,如下图所示。这种示例说明模型没有学习到该类数据特征,导致出现误检的置信度很高。这种情况需要将该类数据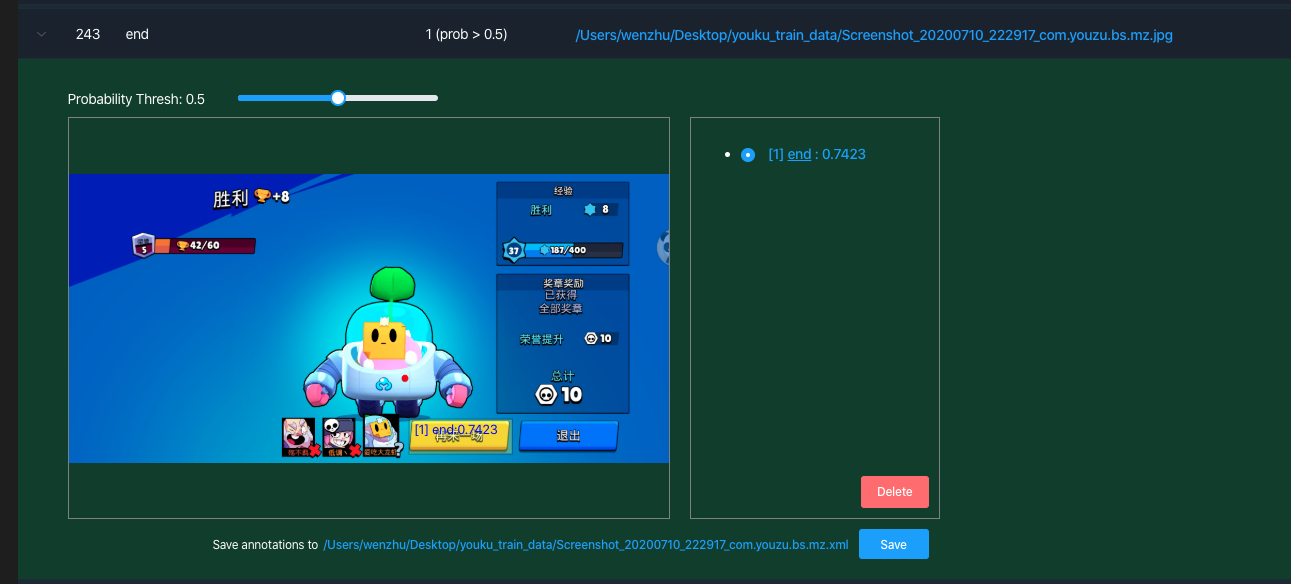
进行标注,加入到训练集中进行训练。我们可以双击预测标签,修改标签名称为”bad case”,如下图所示,点击save保存标签。将该类数据加入训练集,在原有训练工程上继续训练,可以有效减少模型对该类数据误检。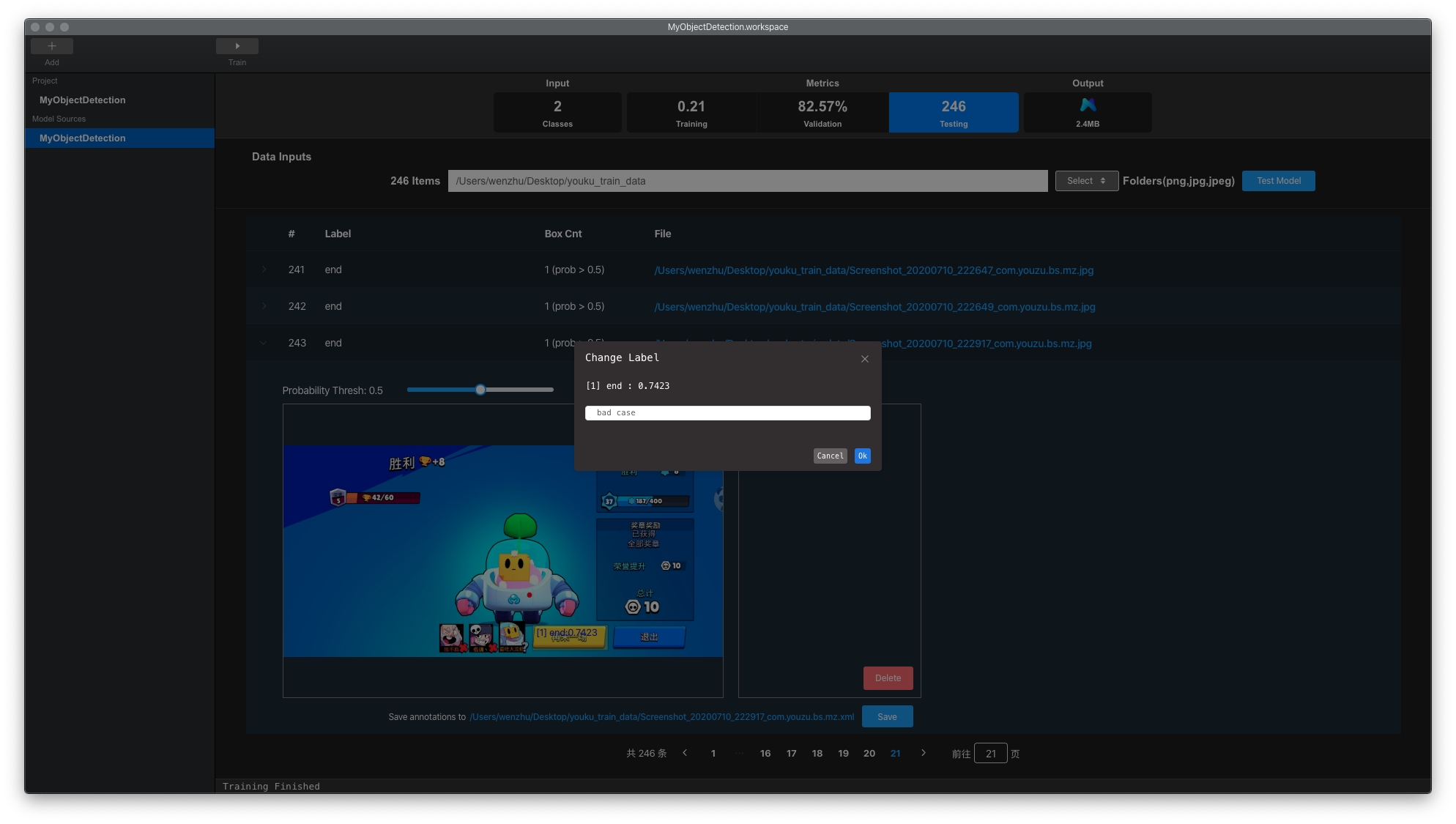
5.4 如何进行半自动数据标注?
当我们在已有训练数据集上完成对模型的充分训练之后,可以利用模型对未标注数据进行标注。具体的,点击Testing选项,点击Select按钮,选择待标注数据文件夹。点击Test Model按钮,模型进行批量预测,如下图所示。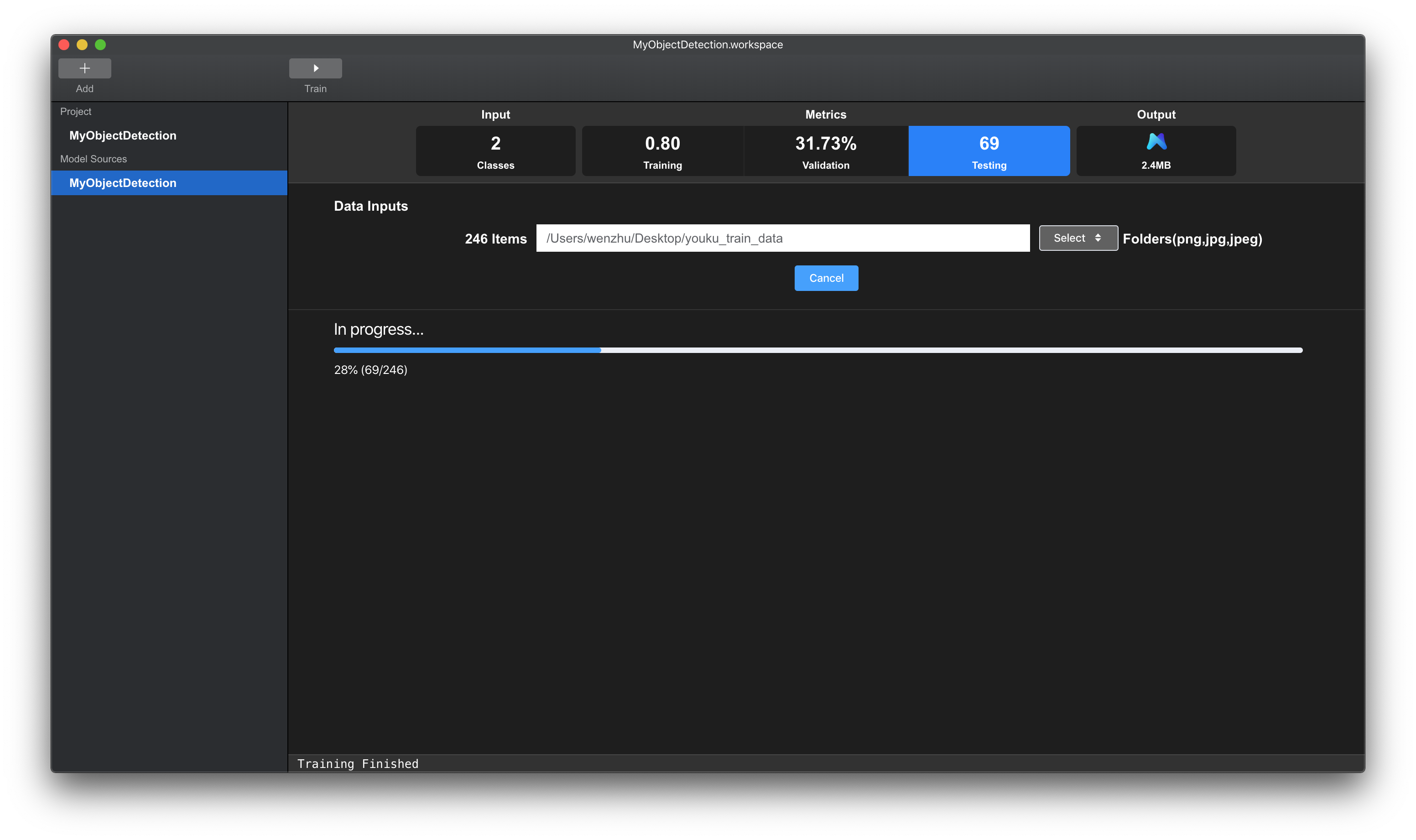
待批量预测完成后,界面会显示模型预测结果,如下图所示。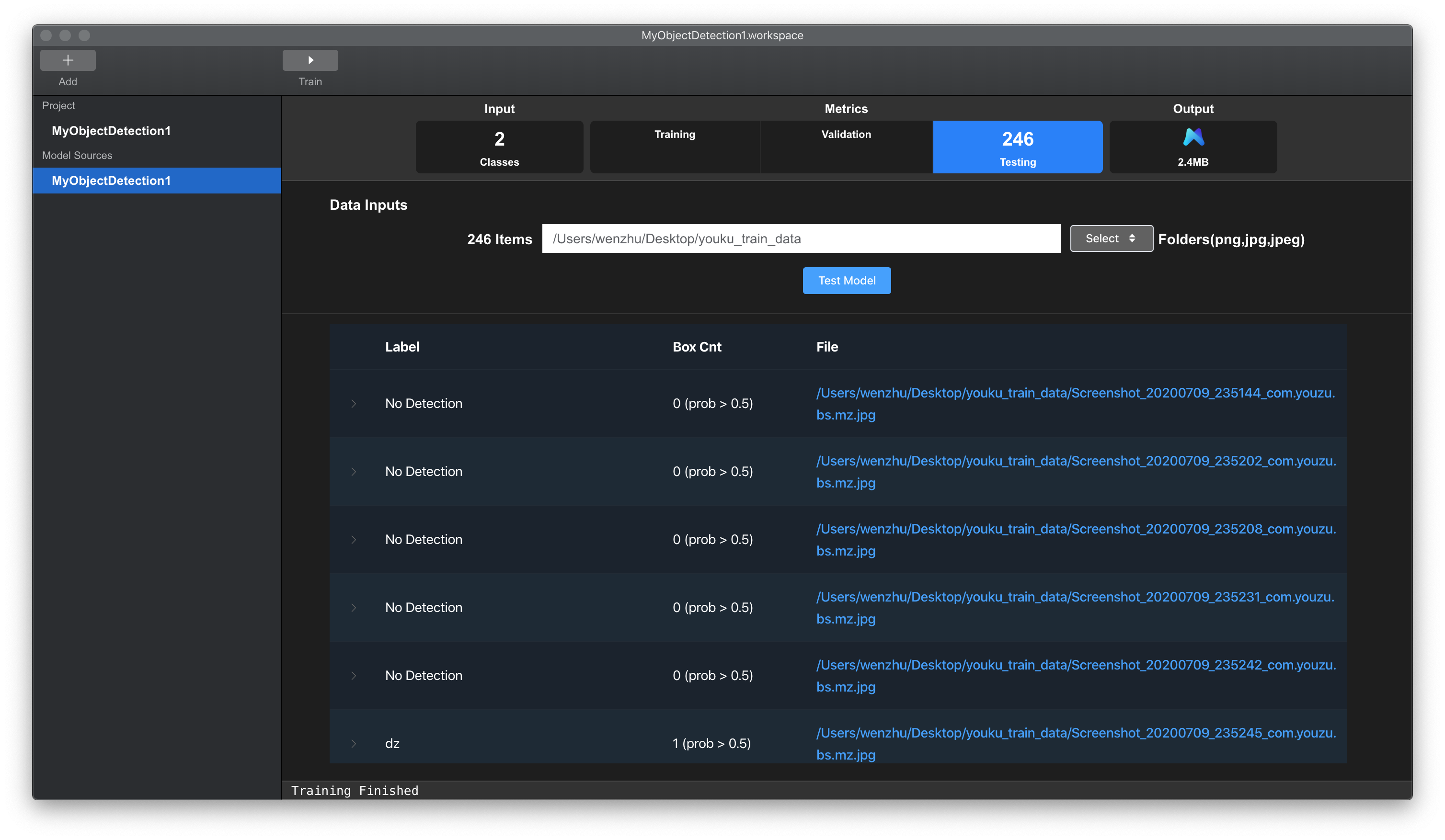
测试结果以表格形式展示:
Label列,该图片中预测出的所有标签。Box Cnt列,设定概率下,预测框的个数。括号中显示当前最小概率,低于该概率的预测框被排除。File列,图片文件路径。点击可打开图片所在的文件夹。
点击行左侧的灰色箭头(>),会展开显示图片和预测结果,我们可以根据模型预测结果动态调整模型预测框,如下图所示。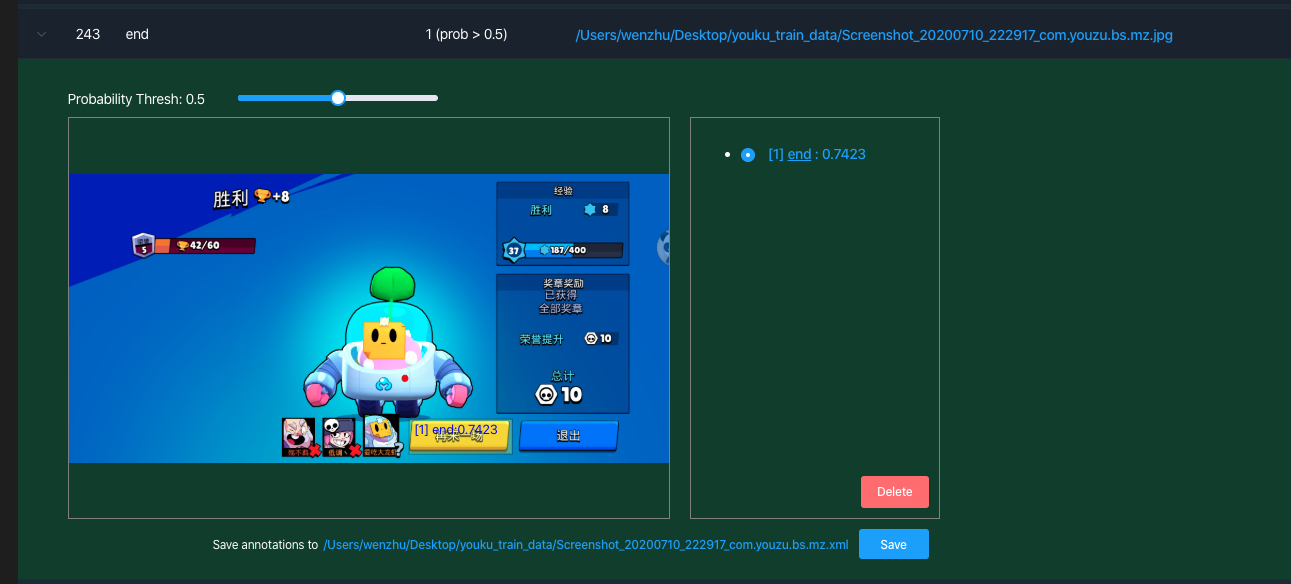
也可以通过双击预测结果界面右侧的标签来修改目标检测框标签。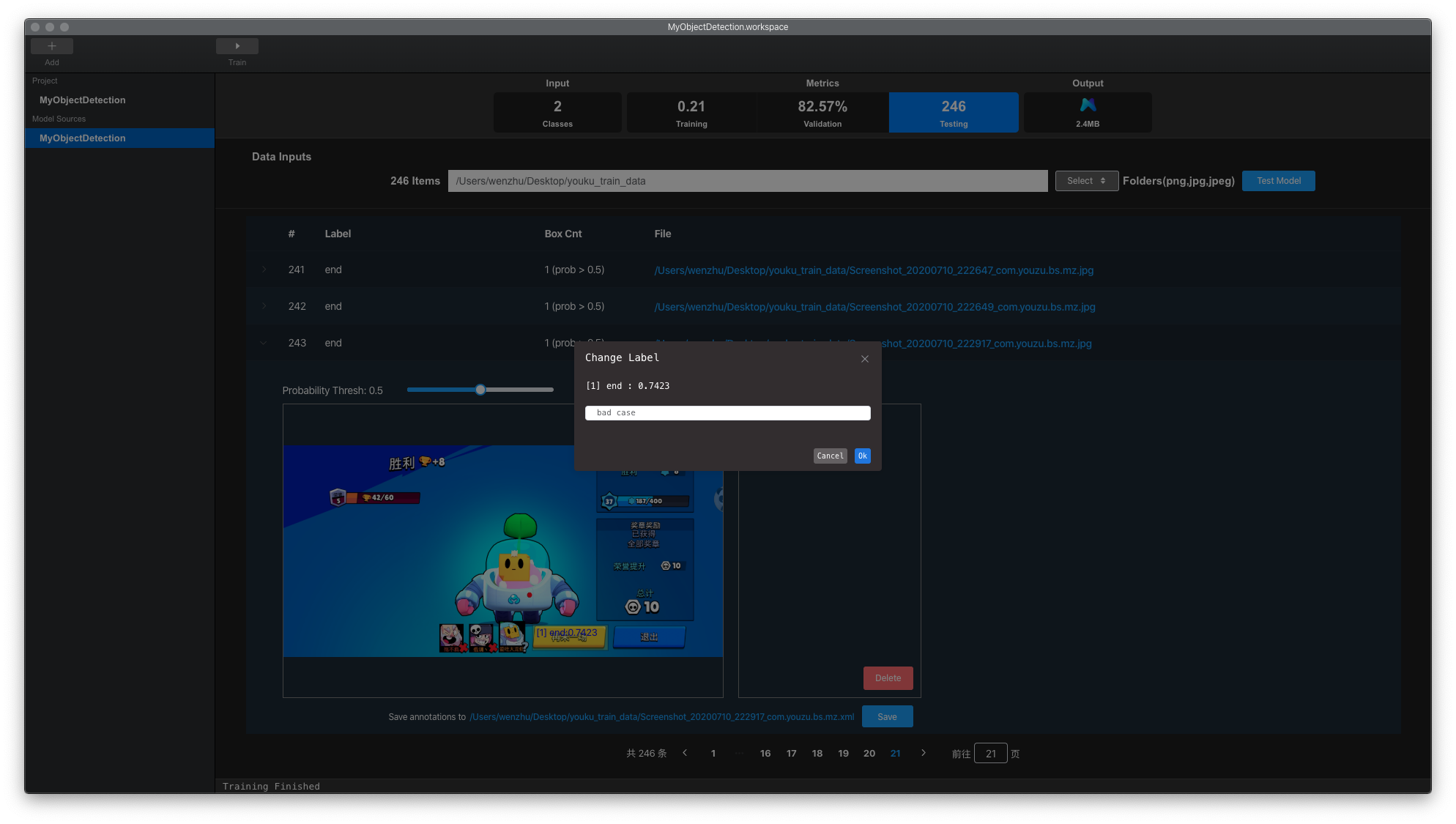
当修改完成后,我们点击Save按钮,标签会保存在该数据文件夹中,标签与图片同名。
5.5 如何设置超参Max Iteration?
工作台会根据训练数据集大小推荐一个Max Iteration数值,用户也可以根据需求适当增加或者减少该值大小。一般情况下,Max Iteration值越大,模型对数据拟合度越高,对应的训练耗时也更长。
5.6 怎么通过训练提高模型的精度?
首先,需要保证模型已经训练充分,如何判断模型训练充分请参考5.1节。当模型训练充分之后,如果发现模型在测试集上的泛化能力不强,可以参考以下措施:
如果在测试集上发现模型预测结果准确,但是目标检测框的得分都不高,比如得分区间大都分布在0.5-0.6。这种情况说明模型并没有很好区别检测目标与背景的差别,一般情况是由于数据量不够造成的,可以通过增加该类别的训练数据提高模型的泛化能力。
如果在测试集上发现误检比较严重,且该类别的误检比较高,可以通过半自动标注工具修改预测结果标签,将其标注为其它类别,如”bad case”,并保存标签。将这类数据加入训练数据集中,在原有工程基础上继续训练一次,可以有效的减少对该类数据的误检。
6 数据集

若有收获,就点个赞吧
0 人点赞
