一、通用脚本
1、集群分发脚本xsync
#!/bin/bash#1. 判断参数个数if [ $# -lt 1 ]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器for host in hadoop102 hadoop103 hadoop104doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidonedone
详解:
- scp(secure copy) 安全拷贝
scp 可以实现服务器与服务器之间的数据拷贝。 (from server1 to server2)
scp -r $pdir/$fname $user@$host:$pdir/$fname命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称eg:scp -r /opt/module/jdk1.8.0_212 atguigu@hadoop103:/opt/module
- rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别: 用 rsync 做文件的复制要比 scp 的速度快, rsync 只对差异文件做更
新。 scp 是把所有文件都复制过去。
rsync -av $pdir/$fname $user@$host:$pdir/$fname命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称-a 归档拷贝-v 显示复制过程
- 脚本构建过程 ```shell 需求分析: rsync 命令原始拷贝: rsync -av /opt/module atguigu@hadoop103:/opt/
期望脚本: xsync 要同步的文件名称 期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径) [atguigu@hadoop102 ~]$ echo $PATH /usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atgu igu/.local/bin:/home/atguigu/bin:/opt/module/jdk1.8.0_212/bin
脚本实现 在/home/atguigu/bin 目录下创建 xsync 文件 [atguigu@hadoop102 opt]$ cd /home/atguigu [atguigu@hadoop102 ~]$ mkdir bin [atguigu@hadoop102 ~]$ cd bin [atguigu@hadoop102 bin]$ vim xsync
修改脚本 xsync 具有执行权限 [atguigu@hadoop102 bin]$ chmod +x xsync 测试脚本 [atguigu@hadoop102 ~]$ xsync /home/atguigu/bin 将脚本复制到/bin 中,以便全局调用 [atguigu@hadoop102 bin]$ sudo cp xsync /bin/ 同步环境变量配置(root 所有者) [atguigu@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh 注意:如果用了 sudo,那么 xsync 一定要给它的路径补全。 让环境变量生效 [atguigu@hadoop103 bin]$ source /etc/profile [atguigu@hadoop104 opt]$ source /etc/profile
<a name="Po00E"></a>## 2、SSH免密登录<br /> 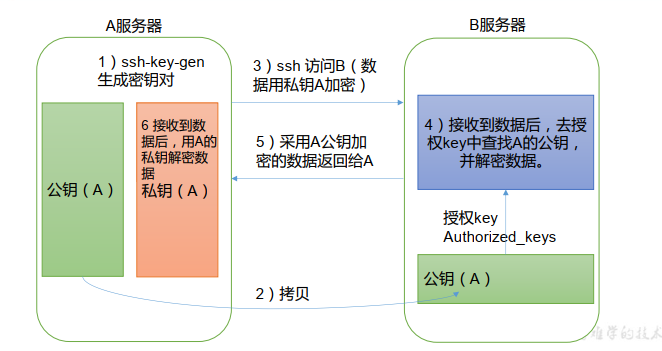```shell生成公钥和私钥[atguigu@hadoop102 .ssh]$ pwd/home/atguigu/.ssh[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、 id_rsa.pub(公钥)将公钥拷贝到要免密登录的目标机器上[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104还需要在 hadoop103 上采用 atguigu 账号配置一下无密登录到 hadoop102、 hadoop103、hadoop104 服务器上。还需要在 hadoop104 上采用 atguigu 账号配置一下无密登录到 hadoop102、 hadoop103、hadoop104 服务器上。还需要在 hadoop102 上采用 root 账号,配置一下无密登录到 hadoop102、 hadoop103、hadoop104;.ssh 文件夹下(~/.ssh) 的文件功能解释known_hosts 记录 ssh 访问过计算机的公钥(public key)id_rsa 生成的私钥id_rsa.pub 生成的公钥authorized_keys 存放授权过的无密登录服务器公钥
03 hadoop群起
#!/bin/bashif [ $# -lt 1 ]; thenecho "No Args Input..."exitficase $1 in"start")echo " =================== 启动 hadoop 集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver";;"stop")echo " =================== 关闭 hadoop 集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh";;*)echo "Input Args Error...";;esac
04 jpsall
#!/bin/bashfor host in hadoop102 hadoop103 hadoop104; doecho =============== $host ===============ssh $host jpsdone

若有收获,就点个赞吧
0 人点赞
