1 大数据简介
平台架构
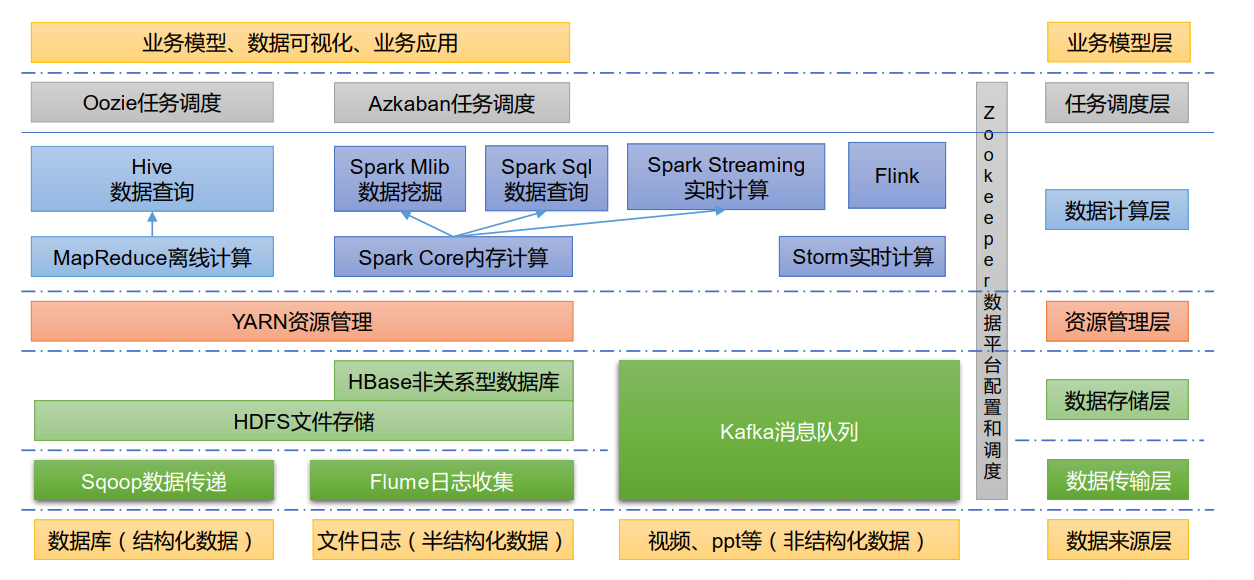
1) Sqoop: Sqoop 是一款开源的工具,主要用于在 Hadoop、 Hive 与传统的数据库(MySQL)
间进行数据的传递,可以将一个关系型数据库(例如 : MySQL, Oracle 等)中的数据导进
到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2) Flume: Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,
Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3) Kafka: Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4) Spark: Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数
据进行计算。
5) Flink: Flink 是当前最流行的开源大数据内存计算框架。 用于实时计算的场景较多。
6) Oozie: Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7) Hbase: HBase 是一个分布式的、面向列的开源数据库。 HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。
8) Hive: Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张
数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运
行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开
发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9) ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、
名字服务、分布式同步、组服务等。
应用
2 Hadoop架构组成
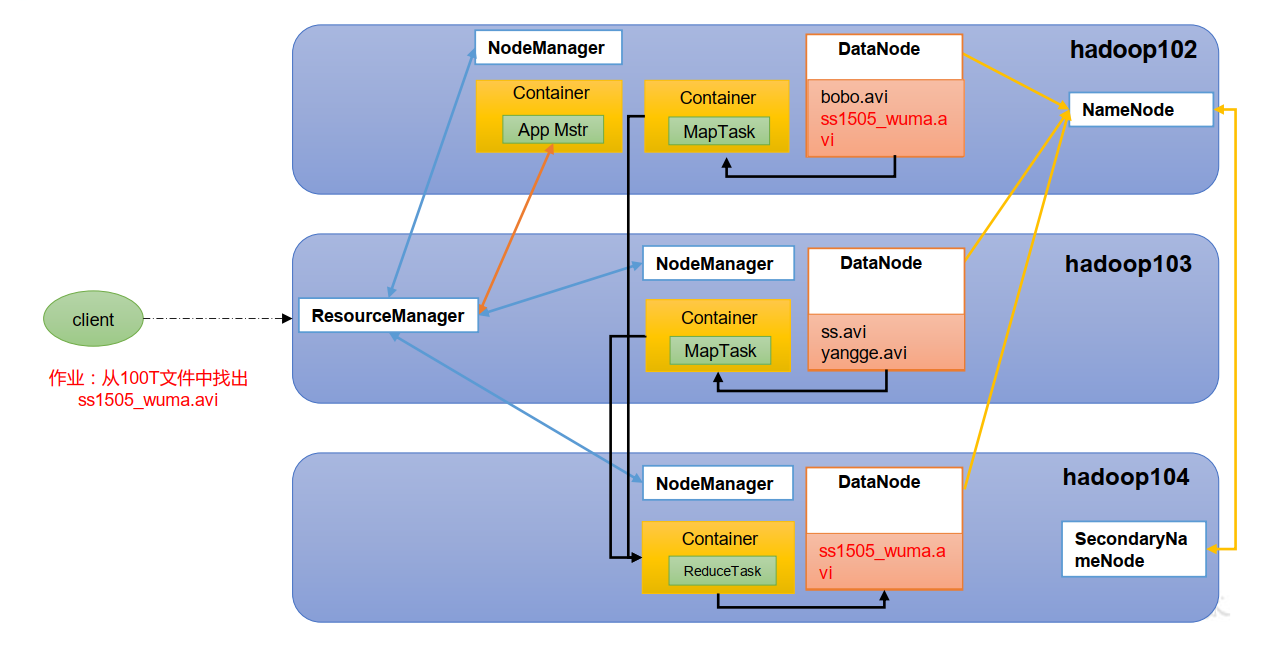
HDFS
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
- NameNode
nn存储文件的元数据,如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的DataNode - DataNode
dn存储文件块数据及其校验和 - Secondary NameNode
2nn对元数据备份
YARN
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者, 是 Hadoop 的资源管理器。
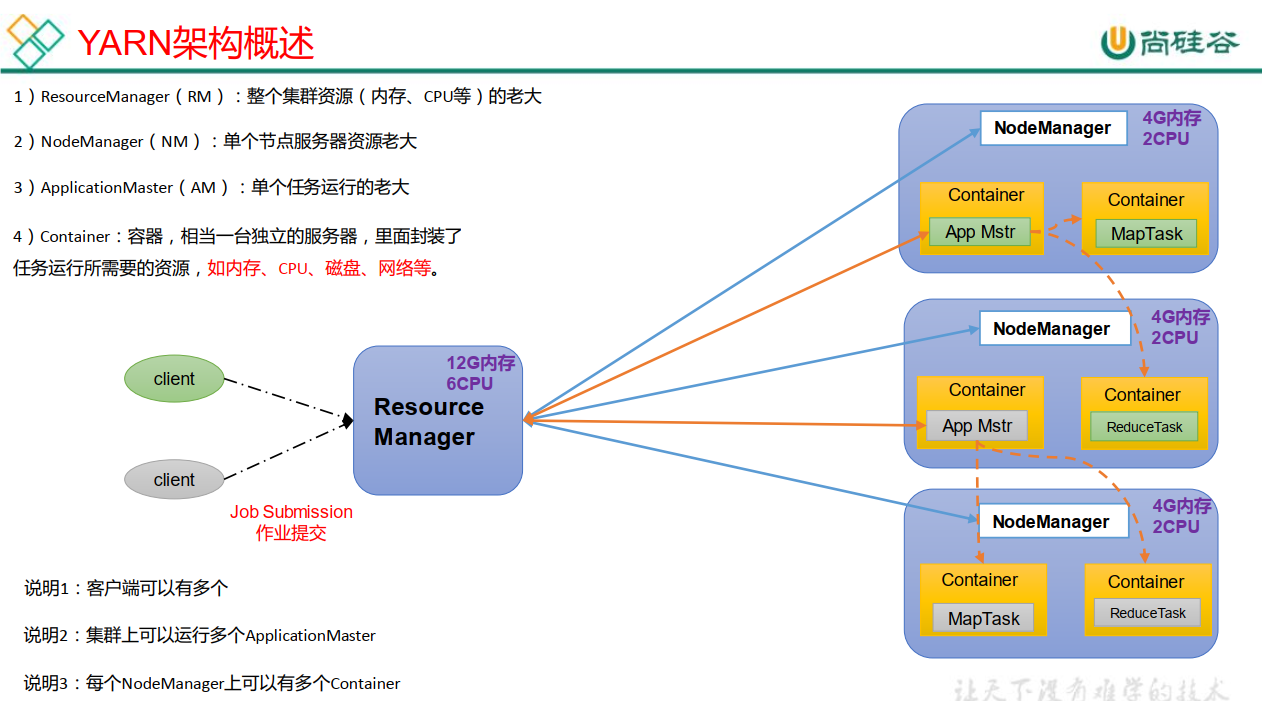
MapReduce
MapReduce 将计算过程分为两个阶段: Map 和 Reduce
1) Map 阶段并行处理输入数据
2) Reduce 阶段对 Map 结果进行汇总
三者关系
3 构建Hadoop集群
(1)模板虚拟机准备
(2)克隆虚拟机3台
(3)集群安装
以上内容参考atguigu文档即可。
4 Hadoop运行
安装
- 解压jdk并配置环境变量
- 解压hadoop 并配置环境变量
运行简介
hadoop目录如下:
(1) bin 目录:存放对 Hadoop 相关服务(hdfs, yarn, mapred)进行操作的脚本
(2) etc 目录: Hadoop 的配置文件目录,存放 Hadoop 的配置文件
(3) lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
(4) sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
(5) share 目录:存放 Hadoop 的依赖 jar 包、 文档、 和官方案例
hadoop运行模式:
Hadoop 运行模式包括: 本地模式、 伪分布式模式以及完全分布式模式。
➢ 本地模式:单机运行,只是用来演示一下官方案例。 生产环境不用。
➢ 伪分布式模式: 也是单机运行,但是具备 Hadoop 集群的所有功能, 一台服务器模
拟一个分布式的环境。 个别缺钱的公司用来测试,生产环境不用。
➢ 完全分布式模式: 多台服务器组成分布式环境。 生产环境使用。
完全分布式启动
1)准备 3 台客户机(关闭防火墙、静态 IP、主机名称)
2)安装 JDK
3)配置环境变量
4)安装 Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8) 配置 ssh
m-shell脚本
9) 群起并测试集群
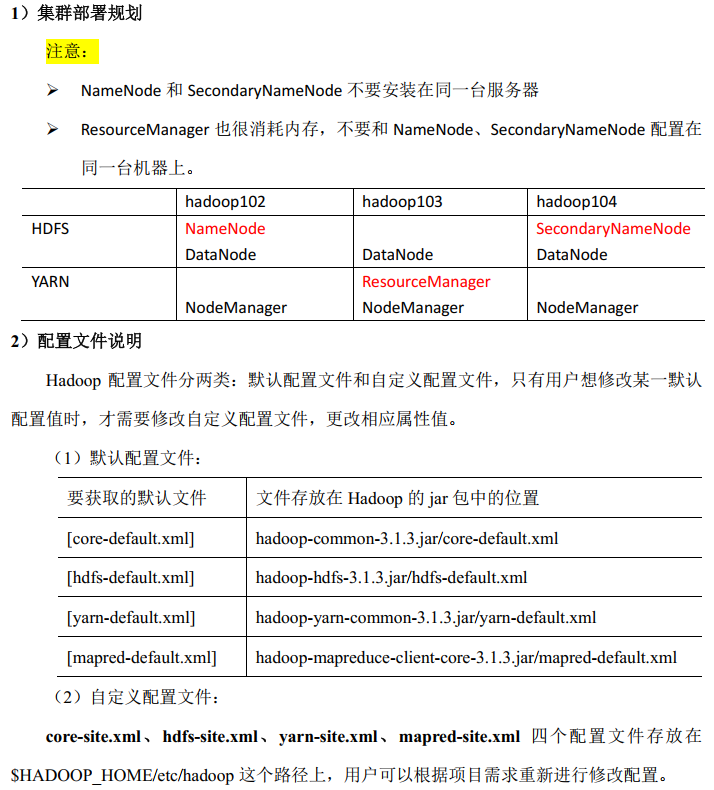
集群部署规划

若有收获,就点个赞吧
0 人点赞
