三大数据结构分别是:
➢ RDD : 弹性分布式数据集
➢ 累加器:分布式共享只写变量
➢ 广播变量:分布式共享只读变量
1 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
➢ 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
核心属性
➢ 分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
protected def getPartitions: Array[Partition]
➢ 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
➢ RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
➢ 分区器(可选)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
@transient val partitioner: Option[Partitioner] = None
➢ 首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。 Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
1) 启动 Yarn 集群环境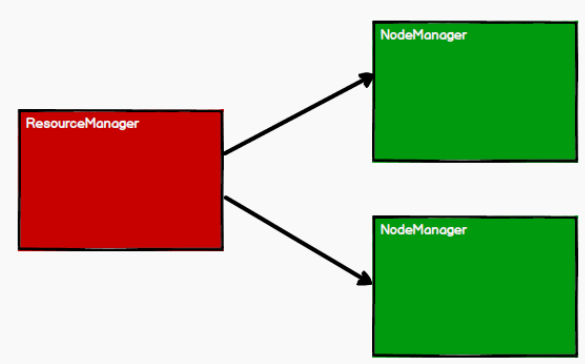
2) Spark 通过申请资源创建调度节点和计算节点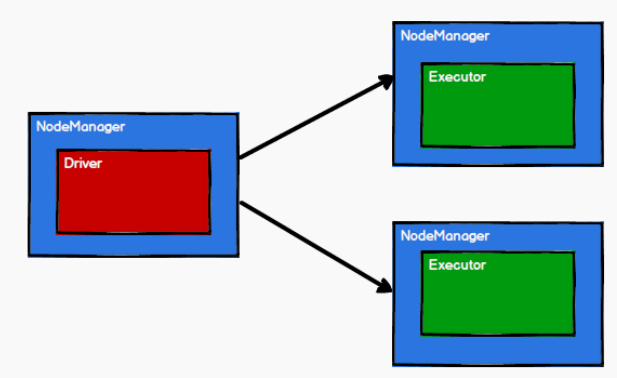
3) Spark 框架根据需求将计算逻辑根据分区划分成不同的任务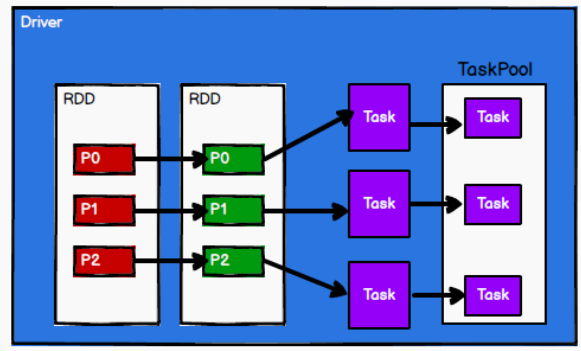
4) 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算,接下来我们就一起看看 Spark 框架中 RDD 是具体是如何进行数据处理的。
基础编程
RDD 创建 在 Spark 中创建 RDD 的创建方式可以分为四种:
1) 从集合(内存)中创建 RDD: 两个方法:parallelize 和 makeRDD
// TODO 创建RDD// 从内存中创建RDD,将内存中集合的数据作为处理的数据源val seq = Seq[Int](1,2,3,4)// parallelize : 并行// val rdd: RDD[Int] = sc.parallelize(seq)// makeRDD方法在底层实现时其实就是调用了rdd对象的parallelize方法。val rdd: RDD[Int] = sc.makeRDD(seq)rdd.collect().foreach(println)// 从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法def makeRDD[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism): RDD[T] = withScope {parallelize(seq, numSlices)}
2) 从外部存储(文件)创建 RDD
// TODO 创建RDD// 从文件中创建RDD,将文件中的数据作为处理的数据源// path路径默认以当前环境的根路径为基准。可以写绝对路径,也可以写相对路径// sc.textFile("F:\\bigData\\idea_workspace5\\data\\1.txt")// val rdd: RDD[String] = sc.textFile("data/1.txt")// path路径可以是文件的具体路径,也可以目录名称// val rdd = sc.textFile("data")// path路径还可以使用通配符 *val rdd = sc.textFile("data/1*.txt")// path还可以是分布式存储系统路径:HDFS// val rdd = sc.textFile("hdfs://linux1:8020/test.txt")rdd.collect().foreach(println)
由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集, 比如 HDFS、HBase 等。
3) 从其他 RDD 创建 主要是通过一个 RDD 运算完后,再产生新的 RDD。详情请参考后续章节
4) 直接创建 RDD(new) 使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。
RDD 并行度与分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
// TODO 创建RDD// RDD的并行度 & 分区// makeRDD方法可以传递第二个参数,这个参数表示分区的数量// 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度)// scheduler.conf.getInt("spark.default.parallelism", totalCores)// spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism// 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数// val rdd = sc.makeRDD(List(1,2,3,4),2)val rdd = sc.makeRDD(List(1,2,3,4))=============================================================================// TODO 创建RDD// textFile可以将文件作为数据处理的数据源,默认也可以设定分区。// minPartitions : 最小分区数量// math.min(defaultParallelism, 2)// val rdd = sc.textFile("data/1.txt")// 如果不想使用默认的分区数量,可以通过第二个参数指定分区数// Spark读取文件,底层其实使用的就是Hadoop的读取方式// 分区数量的计算方式:// totalSize = 7// goalSize = 7 / 2 = 3(byte)// 7 / 3 = 2...1 (1.1) + 1 = 3(分区)val rdd = sc.textFile("data/1.txt",2)rdd.saveAsTextFile("output")=============================================================================// 1. 数据以行为单位进行读取// spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系// 2. 数据读取时以偏移量为单位,偏移量不会被重复读取/*1@@ => 0122@@ => 3453 => 6*/// 3. 数据分区的偏移量范围的计算// 0 => [0, 3] => 12// 1 => [3, 6] => 3// 2 => [6, 7] =>// 【1,2】,【3】,【】val rdd = sc.textFile("data/1.txt",2)rdd.saveAsTextFile("output")=============================================================================// [1,2],[3,4]// val rdd = sc.makeRDD(List(1,2,3,4),2)// [1],[2],[3,4]// val rdd = sc.makeRDD(List(1,2,3,4), 3)// [1],[2,3],[4,5]val rdd = sc.makeRDD(List(1,2,3,4,5), 4)=============================================================================// 如果数据源为多个文件,那么计算分区时以文件为单位进行分区val rdd = sc.textFile("data/1.txt",2)
读取内存数据时,数据可以按照并行度的设定进行数据的分区操作,数据分区规则的 Spark 核心源码如下:
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {(0 until numSlices).iterator.map { i =>val start = ((i * length) / numSlices).toIntval end = (((i + 1) * length) / numSlices).toInt(start, end)}

若有收获,就点个赞吧
0 人点赞
