- 写在前面
- 概述
- 一、复现步骤
- 步骤一:下载源码
- 步骤二:下载package(下面默认都是再新环境下执行命令)
- 1.建立新环境
- 2.安装pytorch
- 3.安装其他的package
- 4.安装coco数据集的package(这是一个坑)
- https://github.com/philferriere/cocoapi,这个的下方介绍了如何使用,但是我试了这个上面的方法,失败了(但不是一定失败,我有同学试过,是可以直接按git给的方式成功安装的),并在网上找了很多的方式,都失败了,但其中有一个方法是可以的,网址如下:http://www.mamicode.com/info-detail-2660241.html。下面给出可能的解决方案。">说明:通过pip install 或者conda install 都失败了,根据了解,是这个数据集的作者明确表示不开通windows的使用,但是有牛人在git上写了在windows上的应用,网址如下:https://github.com/philferriere/cocoapi,这个的下方介绍了如何使用,但是我试了这个上面的方法,失败了(但不是一定失败,我有同学试过,是可以直接按git给的方式成功安装的),并在网上找了很多的方式,都失败了,但其中有一个方法是可以的,网址如下:http://www.mamicode.com/info-detail-2660241.html。下面给出可能的解决方案。
- 步骤三:下载coco数据集
- 步骤四:按git所给的方式运行训练coco数据集的命令
- 1.错误:ImportError: cannot import name ‘PILLOWVERSION’ from ‘PIL’ (E:\Anaconda\lib\site-packages\PIL_init.py)
- 2.ModuleNotFoundError: No module named ‘pycocotools’(实际已安装的情况下)
- 3.下载.pth文件速度太慢
- 4.路径不存在:
- E:\py-learn\pytorch-retinanet\coco\images\train2017
- 5.错误:BrokenPipeError: [Errno 32] Broken pipe
- 6.提示:CUDA out of memory
- 7.pycharm的system/cache下的content.dat.storageData数据过大,且默认在系统盘下,导致程序结束运行
- 步骤五:运行结果
- 步骤六:可视化(visualize.py)结果(只是截取其中几张,作为参考)
- 二、代码分析
- ">

- 9.optimizer.zero_grad()
- 10.torch.nn.utils.clipgrad_norm(retinanet.parameters(), 0.1)
- 三、模型
- 四、概念意义
写在前面
1.这篇文章是自己作为一个初学者(或者说什么都不会)在复现yhenon的pytorch-retinaNet代码的整个过程记录,以及遇到的各种问题,文中大量引用了别人的博客或文章内容,都给了详细的网址,作为注释和学习参考。
2.yhenon的pytorch-retinaNet源码网址:https://github.com/yhenon/pytorch-retinanet,这个源码的下面写明了如何运行,本文下面的运行方式就是按照原文来的。
3.目前为止,对于retinaNet个人觉得对于帮助我的理解最大的一篇文章:
网址:https://blog.csdn.net/qq_43284847/article/details/98472472
概述
1.下载源码
2.安装pytorch
3.下载coco的package
4.下载coco数据集
5.错误:ImportError: cannot import name ‘PILLOWVERSION’ from ‘PIL’ (E:\Anaconda\lib\site-packages\PIL_init.py)
6.ModuleNotFoundError: No module named ‘pycocotools’(实际已安装的情况下)
7.下载.pth文件速度太慢
8.错误:BrokenPipeError: [Errno 32] Broken pipe
9.提示:CUDA out of memory
10.pycharm的system/cache下的content.dat.storageData数据过大,且默认在系统盘下,导致程序结束运行
11.epoch、iteration、batch、batch_size
12.IoU、anchor
13.Focal loss
一、复现步骤
步骤一:下载源码
下载retinaNet的代码,网址如下:https://github.com/yhenon/pytorch-retinanet
下载完成后放到一个project中。
步骤二:下载package(下面默认都是再新环境下执行命令)
1.建立新环境
首先,建立一个新的环境,在anaconda的控制台下:
输入命令,创建一个新的环境
conda env list #查看已有的环境conda create --name your_env_name #创建一个名为your_env_name的新环境conda activate your_env_name #进入创建的新环境中conda deactivate #退出环境
conda命令的使用入门和anaconda安装可以看下面的网址:
https://www.jianshu.com/p/742dc4d8f4c5
2.安装pytorch
法一:在上述的环境中输入命令:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
注:(1)该命令来自于pytorch官网,是不断更新的
官网地址:https://pytorch.org/get-started/locally/
(2)第一次用正常安装会很慢,安装过程可参照下面的文章:
地址:https://www.yuque.com/yanyu-thlhi/aro3o2/xw9rwr
3.安装其他的package
方法一:可以在pycharm中直接通过点击(代码旁的红色错误警告:一个灯的形状)下载安装
方法二:在控制台(anaconda进入环境或者pycharm下的terminal都可以),通过
pip install package_name#或者conda install package_name
4.安装coco数据集的package(这是一个坑)
说明:通过pip install 或者conda install 都失败了,根据了解,是这个数据集的作者明确表示不开通windows的使用,但是有牛人在git上写了在windows上的应用,网址如下:https://github.com/philferriere/cocoapi,这个的下方介绍了如何使用,但是我试了这个上面的方法,失败了(但不是一定失败,我有同学试过,是可以直接按git给的方式成功安装的),并在网上找了很多的方式,都失败了,但其中有一个方法是可以的,网址如下:http://www.mamicode.com/info-detail-2660241.html。下面给出可能的解决方案。
#git原网上的安装方式(要求windows安装过visual c++ build tool,#但是我安装了也不行,可以先试试命令可不可以)pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI#我的解决方式#(1)直接网址下载coco文件,放到项目文件夹下,或者使用以下命令:#最好在pycharm的terminal中输入,目的是使文件在项目文件中git clone https://github.com/pdollar/coco.gitcd coco/PythonAPI#(2)控制台操作:python setup.py build_ext --inplacepython setup.py build_ext install
在控制台第一个命名执行后,可能会出错,则使用以下的方式:报错的话如果是cl: 命令行 error D8021 :无效的数值参数“/Wno-cpp” 和 cl: 命令行 error D8021 :无效的数值参数“/Wno-unused-function”,不用担心,打开上面的setup.py文件,直接删除这两个参数就可以: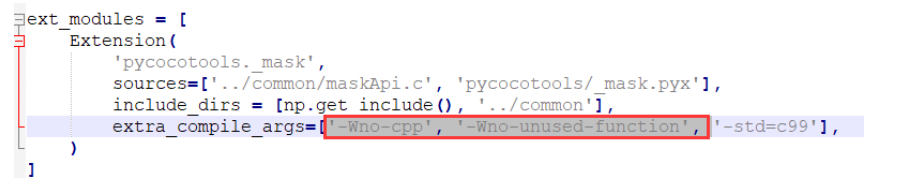
然后再按照上面的两个命令运行就可以了,安装完成后可以再将删去的代码再次加回去就可以了。
步骤三:下载coco数据集
coco数据集的官方链接是可以直接用的,但是使用chrome下载时网速几乎为零,根本不动,而coco数据集很大,后来找到了解决方案,使用迅雷下载,这样基本可以按正常网速下载了,下面提供2017coco数据集的链接:
(1)train2017:http://images.cocodataset.org/zips/train2017.zip
(2)val2017:http://images.cocodataset.org/zips/val2017.zip
(3)test2017:http://images.cocodataset.org/zips/test2017.zip
(4)trainval2017:http://images.cocodataset.org/annotations/annotations_trainval2017.zip
(5)trainval2017:http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
(6)image_info_test2017:http://images.cocodataset.org/annotations/image_info_test2017.zip
下载后解压放到coco文件夹下。
步骤四:按git所给的方式运行训练coco数据集的命令
在pycharm的terminal下运行如下命令:
python train.py --dataset coco --coco_path ..coco --depth 50
1.错误:ImportError: cannot import name ‘PILLOWVERSION’ from ‘PIL’ (E:\Anaconda\lib\site-packages\PIL_init.py)

原因:torchvision在运行时要调用PIL模块的PILLOWVERSION函数。但是PILLOWVERSION在Pillow 7.0.0之后的版本被移除了,Pillow 7.0.0之后的版本使用__version函数代替PILLOW_VERSION函数。
解决方案:打开最后的一个文件链接,定位错误处,再用version函数代替PILLOW_VERSION函数。
参考网址:https://blog.csdn.net/Lee_lg/article/details/103901632
2.ModuleNotFoundError: No module named ‘pycocotools’(实际已安装的情况下)
解决方案:再次安装。
3.下载.pth文件速度太慢
地址:https://download.pytorch.org/models/resnet50-19c8e357.pth
解决方案:根据网址使用迅雷下载,下载后放到train的同名文件夹下即可。
4.路径不存在:
E:\py-learn\pytorch-retinanet\coco\images\train2017
原因:数据集train2017直接放在了coco目录下
解决方案:更正目录即可
5.错误:BrokenPipeError: [Errno 32] Broken pipe
参考网址:https://blog.csdn.net/qq_33666011/article/details/81873217
原因:该问题的产生是由于windows下多线程的问题,和DataLoader类有关
解决方案:修改调用torch.utils.data.DataLoader()函数时的 num_workers 参数,修改num_works参数为 0 ,只启用一个主进程加载数据集,避免在windows使用多线程即可。
注:num_works设置为0可能对速度影响很大,建议改小一些试试
6.提示:CUDA out of memory
可能原因:batch的值大了
解决方案:将batch的值设小一些,但是batch小了,会影响迭代和io,进而影响整体的速度(且影响很大)
7.pycharm的system/cache下的content.dat.storageData数据过大,且默认在系统盘下,导致程序结束运行
解决方案,为C盘下的system和config文件夹创建副本文件夹,
具体方法:
1.在pycharm中点击Help->edit custom properties,然后点击create,在新文件中输入以下内容:
注:建议输入的内容,将图中最后的trunk-删去
原因:经过我的操作,系统后自动在这个文件夹中再次创建config和system文件夹,所以trunk-的文件夹可能就没用了。
2.找到自己pycharm的主目录,如下: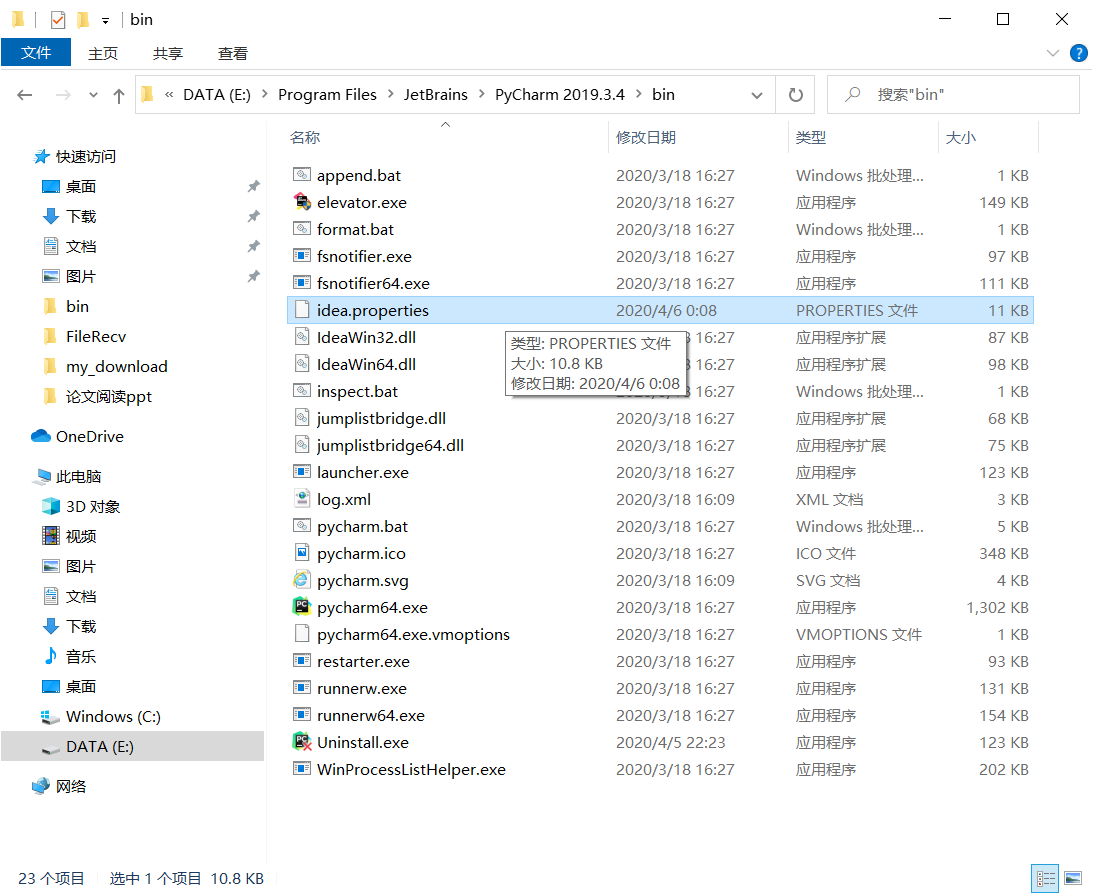
3.以记事本方式打开idea.properties,然后将红色圈出的两行的#注释取消掉,然后保存退出: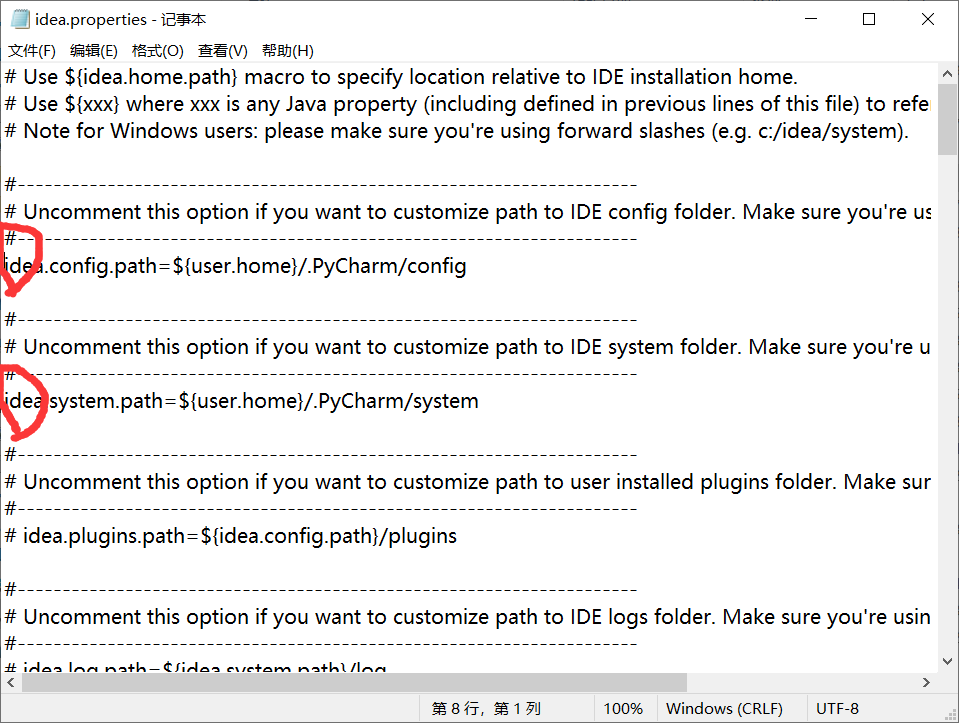
4.然后就可以了,但是你可以将c盘下的config和system文件夹复制到新的文件夹下,并删除就文件夹下那个最大的文件(content.dat.storageData)就可以了(建议不要删除整个文件夹,可能会有不好的后果)。
步骤五:运行结果
注:受限于机器的条件,运行过慢,只能完成一个epoch的训练任务,下面是结果: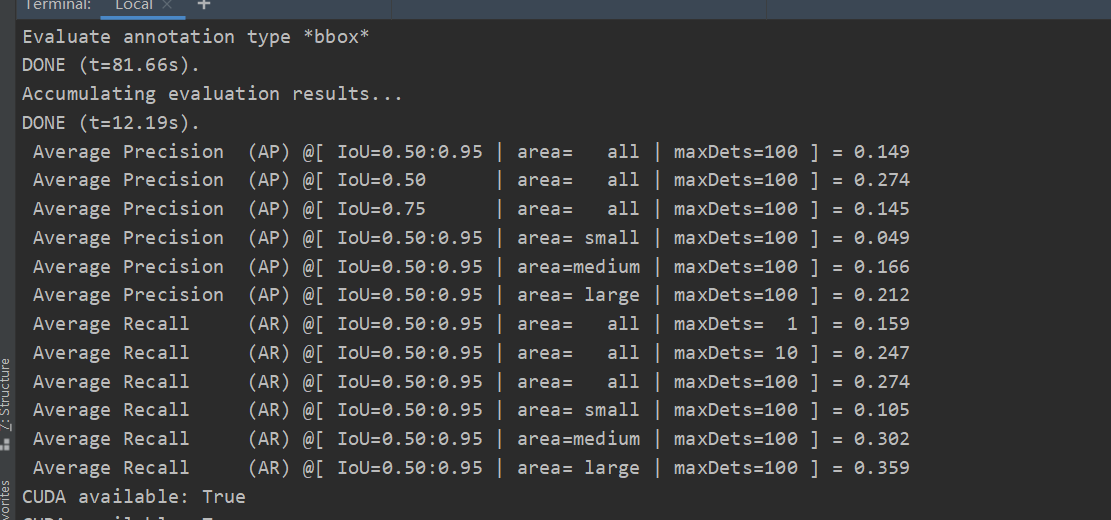
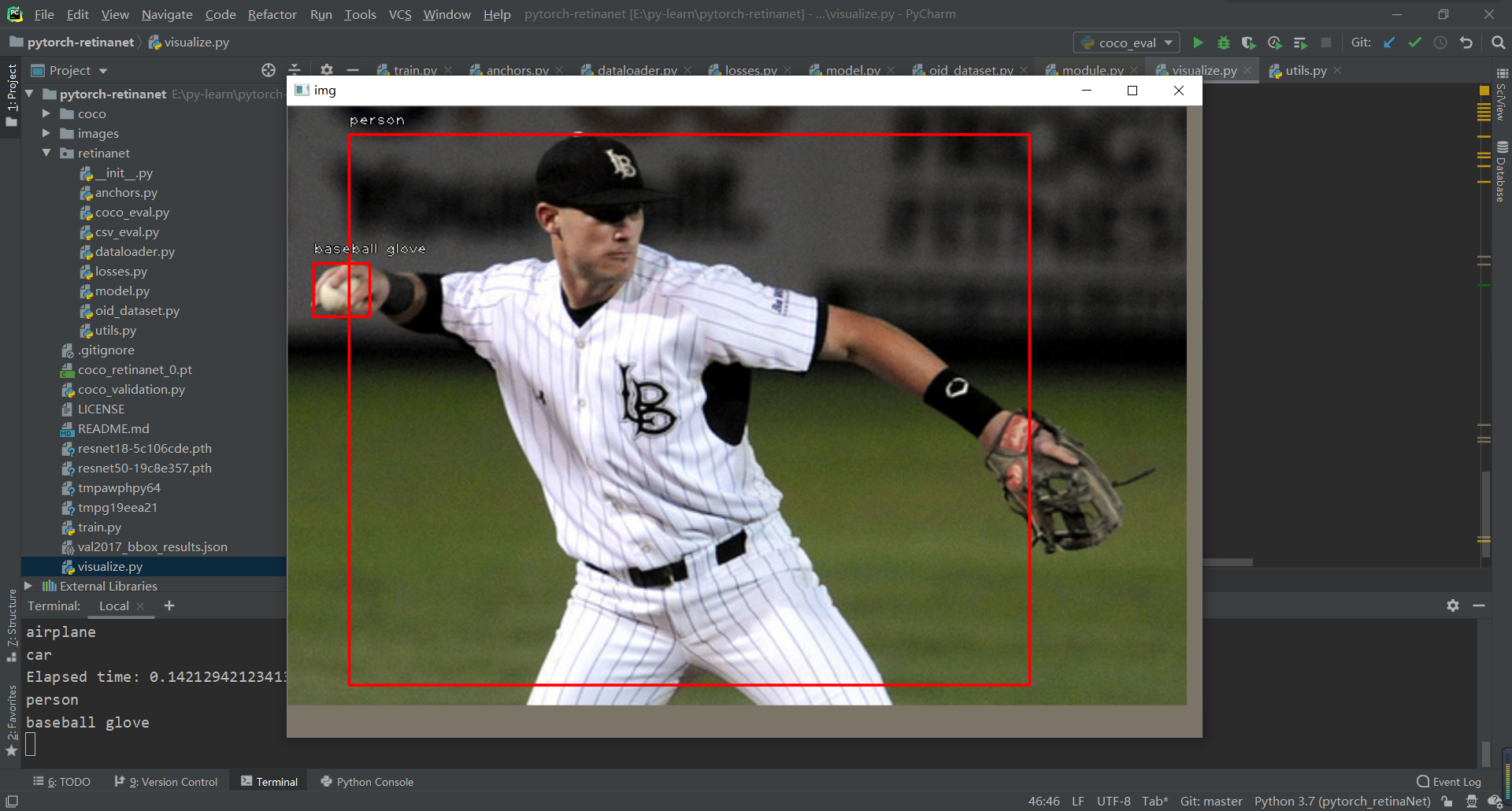
步骤六:可视化(visualize.py)结果(只是截取其中几张,作为参考)
注:运行方式见git源码下的介绍
1.
2.
3.
二、代码分析
1.获取数据集,transform()函数和Resizer(), Augmenter(), Normalizer()
其中,transform:Python中图像数据读入一般都是 nChanns x H x W的numpy数组。常规的做法是使用Dataset中的transform对数据进行转换,输出torch类型的数组。
在目标检测中,一般将图像进行缩放,使其尺寸满足一定要求,具体可以参考之前的博客。也就是要实现一个Resizer()的类进行变换。此外,通常要对图像进行标准化处理,以及水平翻转等变换。因此,在实现Dataset时要实现的变换有三个: Resizer()、Normalizer()和Augmenter()。
详细内容,参考网址:https://www.cnblogs.com/zi-wang/p/9972102.html
2.DataLoader()和AspectRatioBasedSampler()

AspectRatioBasedSampler()函数:位于dataloader.py文件中:

该函数的目的是为给DataLoad()函数传递batch_sample参数,所以其内参数介绍放在下面的DataLoader()函数中,
sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
DataLoad()函数:
首先简单介绍一下DataLoader,它是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py中,只要是用PyTorch来训练模型基本都会用到该接口(除非用户重写…),该接口的目的:将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练。
官方对DataLoader的说明是:“数据加载由数据集和采样器组成,基于python的单、多进程的iterators来处理数据。”关于iterator和iterable的区别和概念请自行查阅,在实现中的差别就是iterators有iter和next方法,而iterable只有iter方法。
DataLoad()的参数介绍:
dataset(Dataset): 传入的数据集batch_size(int, optional): 每个batch有多少个样本shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为Falsebatch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on eachworker subprocess with the worker id (an int in [0, num_workers - 1]) asinput, after seeding and before data loading. (default: None)
详细内容,参考网址:https://www.cnblogs.com/ranjiewen/p/10128046.html
注2:训练神经网络中最基本的三个概念:Epoch, Batch, Iteration,详见四.1
3.retinaNet package下的model.resnet
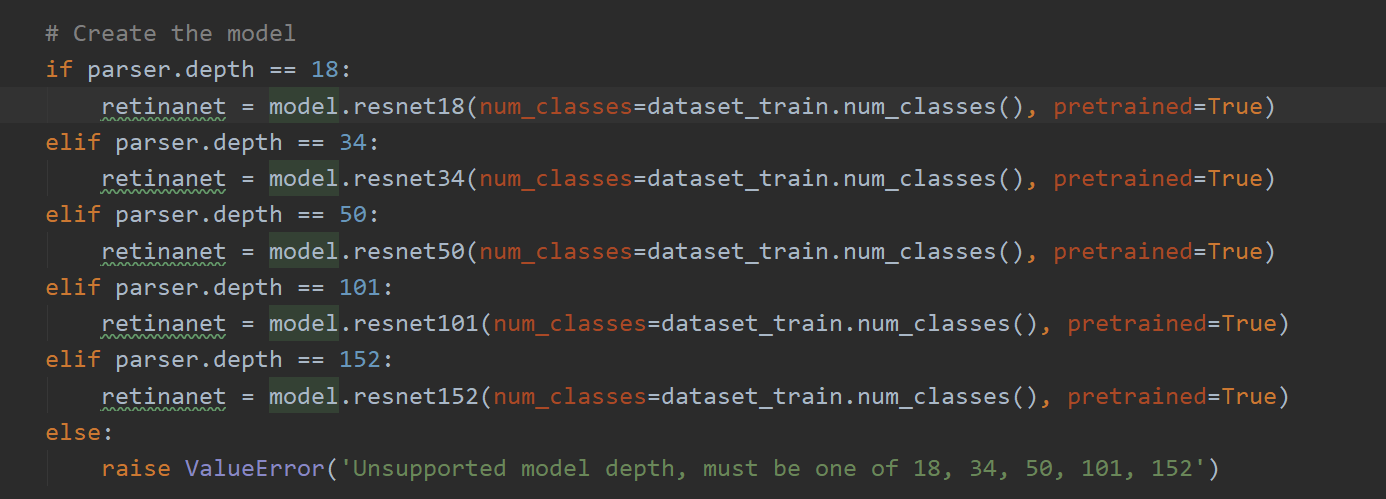
4.torch.cuda.is_available()
cuda是nvidia gpu的编程接口,该函数检测cuda是否可用
5.torch.nn.DataParallel()
pytorch中文文档介绍:https://pytorch-cn.readthedocs.io/zh/latest/search.html?q=torch.nn.DataParallel
6.optimizer =optim.Adam(retinanet.parameters(), lr=1e-5)
torch.optim是一个实现了多种优化算法的包,为了使用torch.optim,需先构造一个优化器对象Optimizer。
参数lr:学习率
表示retinanet.parameters()将使用1e-5的学习率
详细介绍网址推荐:https://blog.csdn.net/kgzhang/article/details/77479737
7.collections.deque(maxlen=500)
deque(maxlen=N)创建一个固定长度的队列。当有新纪录加入而队列已满时会自动移除最老的那条记录。
如果不指定队列的大小,也就得到了一个无界限的队列,可以在两端执行添加和删除操作。
详细介绍网址推荐:https://blog.csdn.net/windy135/article/details/84576600
8.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, verbose=True)
介绍:当网络的评价指标不在提升的时候,可以通过降低网络的学习率来提高网络性能所使用的类
参数:
optimer:网络优化器
patience:容忍网路的性能不提升的次数(epoch),高于这个次数就降低学习率
verbose:如果为True,则为每次更新向stdout输出一条消息。 默认值:False
factor:factor 学习率每次降低多少,new_lr = old_lr * factor。默认值:0.1
详细介绍网址推荐:https://blog.csdn.net/weixin_40100431/article/details/84311430
https://blog.csdn.net/u011622208/article/details/86574291
9.optimizer.zero_grad()
梯度置零
10.torch.nn.utils.clipgrad_norm(retinanet.parameters(), 0.1)
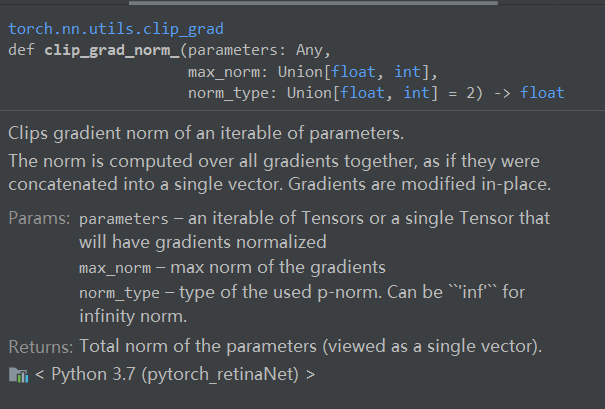
中文介绍网址推荐:https://blog.csdn.net/yangwangnndd/article/details/99110334
三、模型
1.retinaNet模型图

第一步:resnet模型,降低网络深度增加带来的梯度消失的负影响
第二步:FPN模型,整合不同维度特征
第三步:SubNet,分类和回归,得到一系列的anchor
第四步:Focal loss,分析误差,降低“类别不平衡”的负面影响
2.resnet
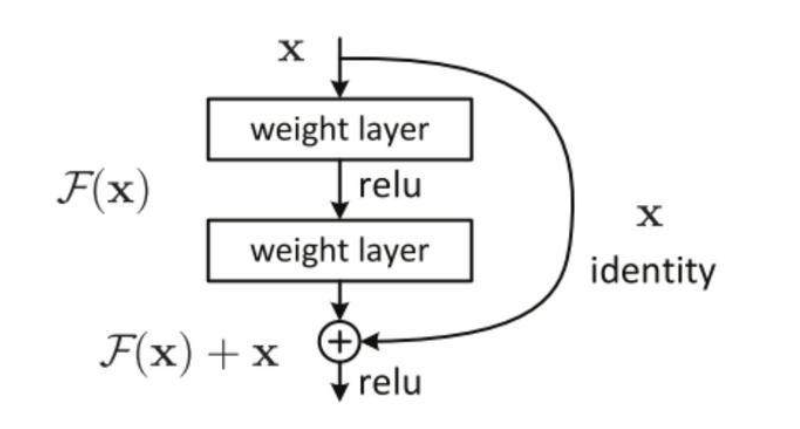
推荐网址:https://www.cnblogs.com/wanghui-garcia/p/10775860.html
四、概念意义
1.epoch、iteration、batch、batch_size
epoch:对训练集的数据进行一次完整的训练,称为一个epoch;
batch:由于训练集的数量很大,一个epoch的数据分成多个batch;
batch_size:指每个batch所含的训练数量;
iteration:表示一个epoch共有多少个batch。
详细介绍可参照以下网址:
1:https://zhuanlan.zhihu.com/p/29409502
2.https://zhuanlan.zhihu.com/p/66021413
2.IoU、anchor
目标检测基本是基于滑动窗口实现的,anchor就是这个窗口,为了框选到我们的目标我们将窗口不断移动,并缩放比例,确保我们能够选中目标,而为了判断是否选中目标,我们引入了IoU,指anchor与正确的框住要识别的物体的方框的面积交并比,在这篇文章里IoU小于0.4则被视为背景,大于0.5则被视为框住了物体,而在0.4和0.5之间的anchor则因为难以下定论而直接被视为无效anchor。
3.Focal loss
这是retinanet论文作者对交叉熵函数提出改良: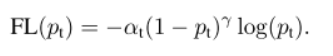 ,这就是focal loss。通过增加类别权重α 和 样本难度权重调因子(modulating factor)(1−pt)γ,来减缓样本不平衡问题,提升模型精确。从而使one-stage的准确率高于two-stage的准确率,同时保持了one-stage的速度.
,这就是focal loss。通过增加类别权重α 和 样本难度权重调因子(modulating factor)(1−pt)γ,来减缓样本不平衡问题,提升模型精确。从而使one-stage的准确率高于two-stage的准确率,同时保持了one-stage的速度.
待完善……

若有收获,就点个赞吧
0 人点赞
