结合CAP理论分析ElasticSearch的分布式实现方式\_zjltju1203的博客-CSDN博客
结合 CAP 理论分析 ElasticSearch 的分布式实现方式
本文链接:https://blog.csdn.net/zjltju1203/article/details/100830271
版权
简介
首先引出本人对 ElasticSearch 分布式的特点;再者针对分布式系统 CAP 理论,来论证分析 ElasticSearch 如何实现分布式?另外分析 ElasticSearch 在 CAP 理论的实现中是如何在三取二中权衡的?最后回归到论点。
一,ElasticSearch 分布式的特点
1.强一致性,ES保证每一次的数据的更新都更新都所有的节点。2.高可用,ES保证在某些节点/分片挂掉后仍不影响对外的响应。3.低分区容错性。
以上是个人对 ElasticSearch 的分布式方式的特点认知,非官方观点。有其他观点的同学可以留言讨论。
二,CAP 理论
如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据,对调用者而言数据具有强一致性 (strong consistency) (又叫原子性 atomic、线性一致性 linearizable consistency)
所有读写请求在一定时间内得到响应,可终止、不会一直等待
在网络分区的情况下,被分隔的节点仍能正常对外服务
CAP 是一个理想的理论,现实应用中不会出现 CAP 三个特点都占齐的分布式系统。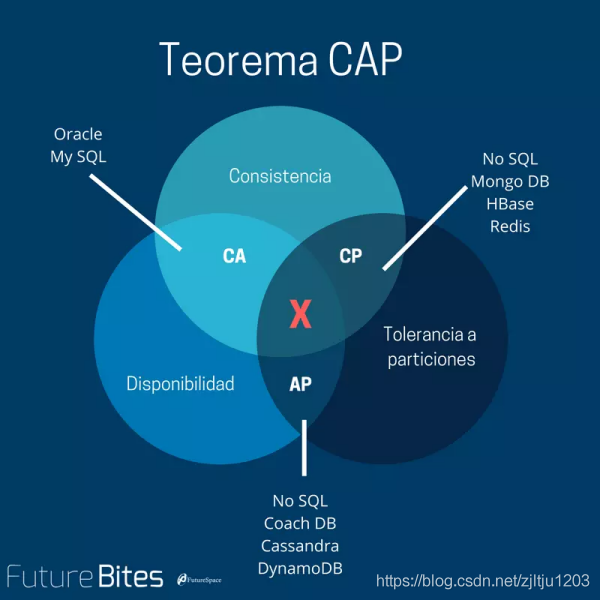
CA without P丢弃P:对于一个分布式系统,如果不能满足分区容错性,那么意味着集群的各个节点之间都保证相互之间的协调工作,如果网络异常,那么和单个节点没有两样,也不能称之为分布式系统。因此分区容错性是必须要保证的。CP without A丢弃A:如果牺牲可用性,换来数据一致性。对于这种情况也有相应的应用场景,比如淘宝在双十一的高峰,为了保证数据的一致性,在我们支付的时候,有时候会等待很久都不能支付成功。这是因为并发量太大,必须要保证交易数据的一致性,即使要牺牲一点可用性。AP wihtout C丢弃C:如果牺牲一致性,换来可用性。对于这种情况,比较典型的就是火车订票系统,我们常常会在抢票的时候发现系统显示还有剩余的票,但是当在下单付款的时候却已没有剩余的票。这样虽然会降低用户的使用体验,但是也不至于大量用户请求阻塞服务器。
三,ES 如何支持 CAP 理论?
下面我将结合 CAP 理论讨论一下 ElasticSearch 如何满足上面三个特性的?
3.1 ES 一致性分析
3.1.1,ES 集群管理一致性
ES 实现分布式是实现了一个集群系统,在这个系统中各个节点都可以接收请求消息和存储数据,并通过内部的一套路由算法实现各个节点协调一致地工作。在这个集群系统中,需要一个集群管理员来负责集群的所有管理工作,这个集群管理员称之为 Master 节点。Master 节点的唯一性是 ElasticSearch 一致性的一个重要组成部分,Master 节点的选举依赖与 ElasticSearch 内部一套独特的 Master 节点选举策略。下面简单分析一下:
1,首先简单介绍一下 ElasticSearch 的节点类型
ElasticSearch 有四种节点类型,这里主要介绍两种:
- Master-eligible node
Master 候选节点,有权利发起集群选举和参与其他节点发起的选举。yml 默认设置为 true,即开启一个 ElasticSearch 节点则默认为 Master 候选节点。 - Data node
数据节点
数据节点承担数据的存储和数据相关的增删改查等操作,并且包括数据的搜索和聚合。
另外两种节点不在此介绍,详情可见 ES 官方文档:ElasticSearch 节点
2,ES 节点发现:ZenDiscovery‘
实现机制核心的点:广播
Node 启动后,首先要通过 yml 配置文件中配置的 discovery.zen.ping.unicast.hosts 的值去发送广播到每一个节点,各个节点接收到消息后发起响应,集群的 Master 节点(有就用当前 Master 节点,无就选举)加入集群。
ZenDiscovery 是 ES 自己实现的一套用于节点发现和选主等功能的模块,没有依赖 Zookeeper 等工具。
3,Master 节点选举
当集群启动后,每一个 Master-eligible node 都会每隔一定时间去 ping 集群的各个节点确定集群的 Master 是否存活。如果集群刚启动没有 Master 节点或者 Master 节点由于网络原因或者负载较大没有及时响应,此时 Master-eligible node 就会发起一次选举,并让集群中的节点给自己投票。当该节点收到的票数大于等于(Nodes/2+1)个票数时(即超过半数),该节点选举为 Master 节点。
为了保证选举的一致性,ElasticSearch 还有另外一套机制 - 选举周期。即在一个选举周期内的票数在有效,否则的话清空选票重新选举。
4,集群扩缩容
当集群建立后,集群节点的加入或离开保证集群平衡也是 ElasticSearch 一致性的一个重要组成部分。
split brain脑裂问题脑裂是指在同一个ES集群中出现两个Master节点。可能出现的原因:1.网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片2.节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。3.内存回收:data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。脑裂问题解决方案:1.减少误判:discovery.zen.ping_timeout节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数。2.选举触发 discovery.zen.minimum_master_nodes:1该参数是用于控制选举行为发生的最小集群主节点数量。当备选主节点的个数大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n/2)+1,n为主节点个数(即有资格成为主节点的节点个数)增大该参数,当该值为2时,我们可以设置master的数量为3,这样,挂掉一台,其他两台都认为主节点挂掉了,才进行主节点选举。3.角色分离:即master节点与data节点分离,限制角色主节点配置为:node.master: true node.data: false从节点配置为:node.master: false node.data: true
3.1.2,Master 节点管理一致性
ElasticSearch 集群中 Master 节点为了协调一致地管理集群,保证所有节点的信息同步是一致性的必要条件。
ElasticSearch 采用给所有节点发送 ClusterState 信息体,同步各个节点的信息,保证一致性。
1,什么是 ClusterState
在 ES 中,Master 节点是通过发布 ClusterState 来通知其他节点的。Master 会将新的 ClusterState 发布给其他的所有节点,当节点收到新的 ClusterState 后,会把新的 ClusterState 发给相关的各个模块,各个模块根据新的 ClusterState 判断是否要做什么事情,比如创建 Shard 等。即这是一种通过 Meta 数据来驱动各个模块工作的方式。
集群中的每个节点都会在内存中维护一个当前的 ClusterState,表示当前集群的各种状态。ClusterState 中包含一个 MetaData 的结构,MetaData 中存储的内容更符合 meta 的特征,而且需要持久化的信息都在 MetaData 中,此外的一些变量可以认为是一些临时状态,是集群运行中动态构建出来的。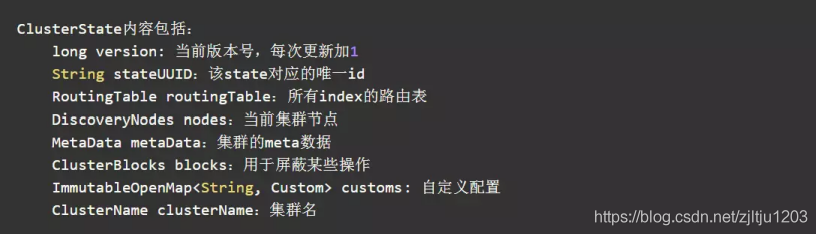
2,什么是 Meta?Meta 的组成?Meta 的存储?Meta 恢复?
Meta 是用来描述数据的数据。在 ES 中,Index 的 mapping 结构、配置、持久化状态等就属于 meta 数据,集群的一些配置信息也属于 meta。这类 meta 数据非常重要,假如记录某个 index 的 meta 数据丢失了,那么集群就认为这个 index 不再存在了。ES 中的 meta 数据只能由 master 进行更新,master 相当于是集群的大脑。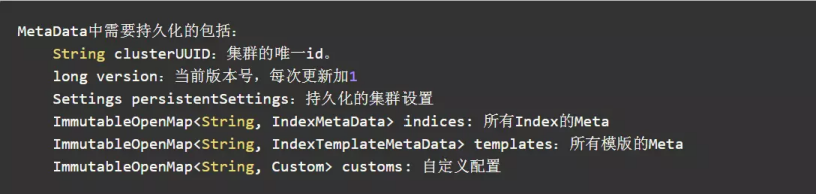
ElasticSearch 会把 Meta 和 Data 都写入到这个目录中,其中目录名为_state 的代表该目录存储的是 meta 文件。
假设 ES 集群重启了,那么所有进程都没有了之前的 Meta 信息,需要有一个角色来恢复 Meta,这个角色就是 Master。所以 ES 集群需要先进行 Master 选举,选出 Master 后,才会进行故障恢复。
当 Master 选举出来后,Master 进程还会等待一些条件,比如集群当前的节点数大于某个数目等,这是避免有些 DataNode 还没有连上来,造成不必要的数据恢复等。
当 Master 进程决定进行恢复 Meta 时,它会向集群中的 MasterNode 和 DataNode 请求其机器上的 MetaData。对于集群的 Meta,选择其中 version 最大的版本。对于每个 Index 的 Meta,也选择其中最大的版本。然后将集群的 Meta 和每个 Index 的 Meta 再组合起来,构成当前的最新 Meta。
3,ClusterState 更新流程
ElasticSearch 为了保证集群信息同步的一致性,采用两阶段提交的方式。当 ElasticSearch 向集群发送同步 ClusterState 的请求,所有的节点接收到信息后向发起者发起响应,如果超过半数则发起提交请求。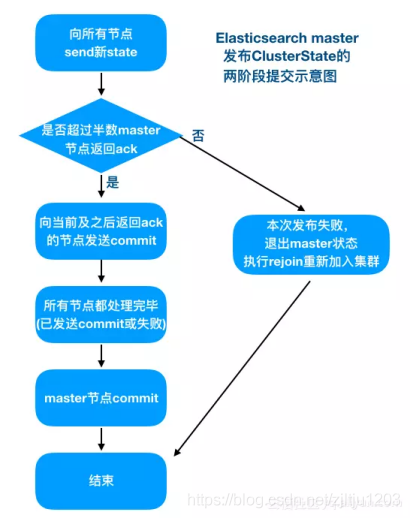
3.1.3,数据写入一致性
1,数据写入流程
ES 写入流程为先写入 Primary,再并发写入 Replica,最后应答客户端,流程如下:
1,检查 Active 的 Shard 数。String activeShardCountFailure = checkActiveShardCount();
2,写入 Primary。primaryResult = primary.perform(request);
3,并发的向所有 Replicate 发起写入请求 performOnReplicas(replicaRequest, globalCheckpoint, replicationGroup.getRoutingTable());
4,等所有 Replicate 返回或者失败后,返回给 Client。
private void decPendingAndFinishIfNeeded() {assert pendingActions.get() > 0 : "pending action count goes below 0 for request [" + request + "]";if (pendingActions.decrementAndGet() == 0) {finish();}}
2,PacificA 算法
That model is based on having a single copy from the replication group that acts as the primary shard. The other copies are called replica shards. The primary serves as the main entry point for all indexing operations. It is in charge of validating them and making sure they are correct. Once an index operation has been accepted by the primary, the primary is also responsible for replicating the operation to the other copies.
该算法具有以下几个特点:
1、强一致性。
2、单 Primary 向多 Secondary 的数据同步模式。
3、使用额外的一致性组件维护 Configuration。
4、少数派 Replica 可用时仍可写入。
3.2 ES 可用性分析
3.2.1,主副分片同步
副片:es 为了更好地稳定性和容灾,除了进行必要的索引备份外,副本的添加可以更好地维持集群数据完整性。
当数据写入主分片后然后将数据同步到副本分片中,一旦系统中的主分片异常,则副本分片则可以很好地替补主分片保证数据的完整性。
分片的路由算法:shard = hash(routing) % number_of_primary_shards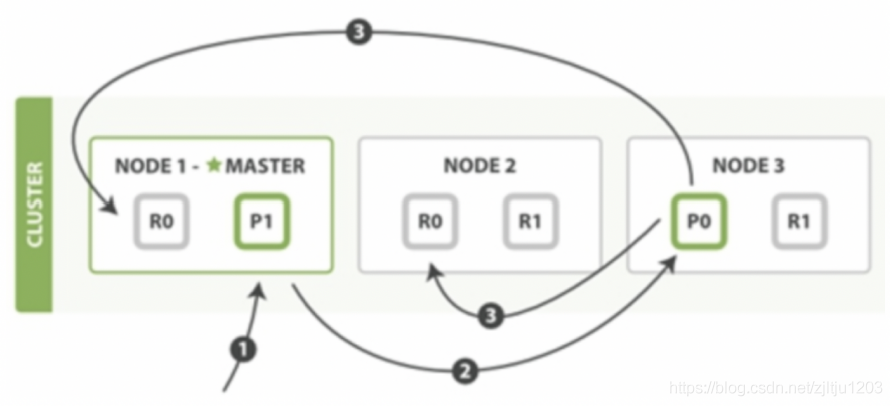
缺点:写入延迟,效率低
优点:防止数据丢失,高可用
3.2.2,多节点提升系统的可用性
ElasticSearch 是多节点集群系统,ElasticSearch 中可以启动多个节点,各个分片均匀地分布在各个节点。并且 ElasticSearch 会将主分片和其副本分片分布在不同的节点上,一旦主分片所在节点挂掉了,则另一个节点的备份分片立即升级为主分片,保证系统的可用性。
3.2.3,Pending Task
有一些任务只能由主节点去处理,比如创建一个新的 索引或者在集群中移动分片。
由于一个集群中只能有一个主节点,所以只有这一节点可以处理集群级别的元数据变动。
大多数情况下,master 可以处理,但当集群元数据改变的速度超过了 master 节点处理的速度时,
将会导致这些元数据操作的任务被缓存入队列中,即 pending tasks。
pending task API 将会显示队列中被挂起的所有的集群元数据改变的任务。
3.3 ES 分区容忍性分析
ES 分区脑裂
高分区容忍性的定义是讲分布式系统中一旦发生网络分区或者某一些节点因为网络等原因无法连接到分布式系统中时,这些节点可以依旧对外提供完整独立的服务,也就是将每一个节点拥有的功能是完整的,节点与节点之间的耦合度较低,任意一个节点都可以对外提供完整的服务。
现在我们来观测 ElasticSearch 集群的特点,ElasticSearch 集群各个节点各个节点是高度协调,高度耦合的。
原因如下:
1,各个节点地位平等,各个节点都用于存储数据,每个节点都接收请求数据,当发现数据不在本身节点时将请求路由到对应节点获取数据返回;各个节点是高度协调运作的。
2,ElasticSearch 的主分片是均匀分布在各个节点上,可以假设这样一种场景:ELasticSearch 中存在两个节点,建立一根索引 index,2 个主分片 0 个副本分片,现在两个主分片均匀地分布在两个节点上;当网络发生异常时,此时集群状态是 RED 状态,任意一个节点也无法对外提供服务,此时系统处于瘫痪状态。各个节点是高度耦合的。
综合上面两点,ElasticSearch 是一个低分区容忍性的系统。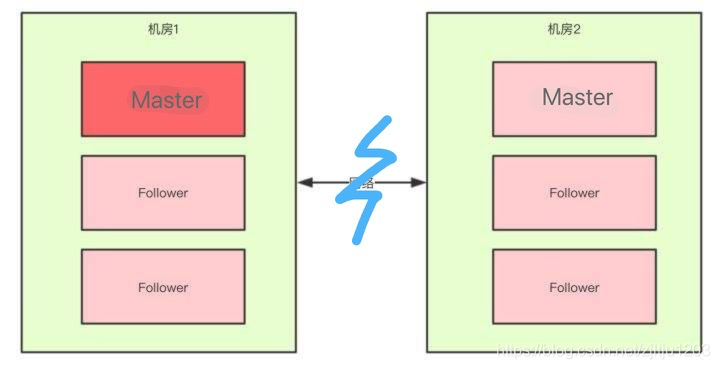
4 总结
综上分析,ElasticSearch 是一个高一致性,高可用,低分区容忍性的(CA)分布式系统。
此观点是个人观点,且观点不唯一,如果各位同学有什么其他更好的理解可以留言本人细致讨论,谢谢。
下面是一些国外众网友对 ElasticSearch 结合 CAP 理论的理解,大家有兴趣可以了解一下。
elasticsearch and the CAP theorem
【Elastic 讨论区】elasticsearch and the CAP theorem
【Elastic 讨论区】CAP theorem





扫一扫,分享海报


收藏 1

打赏
打赏
沧 hi
你的鼓励将是我创作的最大动力
C 币 余额
¥2 ¥4 ¥6 ¥10 ¥20 ¥50
您的余额不足,请先充值哦~去充值

举报- 关注 关注
- 一键三连
点赞 Mark 关注该博主, 随时了解 TA 的最新博文
已标记关键词 清除标记
08-25
[
win8 64 位系统测试可用 需要用 vs2013 打开, 也可以去找 vs 工程在线降级的, 转换成低版本打开
](https://download.csdn.net/download/qq_18132581/7817953)
06-21 
7 万 +
[
在弄清楚这个问题之前,我们先了解一下什么是分布式的CAP定理。 根据百度百科的定义,CAP定理又称CAP原则,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),最多只能同时三个特性中的两个,三者不可兼得。 一、CAP的定义 Consistency (一致性): “all nodes see…
](https://blog.csdn.net/yeyazhishang/article/details/80758354)


插入表情
































































添加代码片
- HTML/XML
- objective-c
- Ruby
- PHP
- C
- C++
- JavaScript
- Python
- Java
- CSS
- SQL
- 其它
还能输入1000个字符

码哥
mlzdev:cp 才对 6 月前回复
举报


wudalang5:?没回复上看不到呢 2 年前回复
举报
1e0zj: 综上分析,ElasticSearch 是一个高一致性,高可用,低分区容忍性的(CA)分布式系统。分布式系统不应该讨论的是在 P 的情况下,ES 是 CP 还是 AP 应用吗。。。2 年前回复
举报- <
- 1
- >
相关推荐
[
2019 java 面试题_yyjava 的专栏
](https://blog.csdn.net/yyjava/article/details/102511156)
2-27
[
ElasticSearch 作为一个建立在全文搜索引擎 Apache Lucene 基础上的实时的分布式搜索和分析引擎, 适用于处理实时搜索应用场景。此外, 使用 ElasticSearch 全文搜索引擎, 还可以支持多词条查询、匹配度与权重、自动联想、拼写纠错等高级功能。因此,…
](https://blog.csdn.net/yyjava/article/details/102511156)
[
〈四〉ElasticSearch的认识: 基础原理的补充_代码小牛的…
](https://blog.csdn.net/qq_41154882/article/details/102386294)
3-20
[
第一篇我们认识了ElasticSearch, 大概知道了ElasticSearch的作用 — 搜索, 也了解了一些倒排索引和分词器的知识 (需要补充), 然后学习了如何搭建环境 (需要补充一下关于基础的集群知识), 然后讲了一些基础的ElasticSearch概念 (重新讲述, 加深了解)。
](https://blog.csdn.net/qq_41154882/article/details/102386294)
12-18
1 万 +
[
大家在看书或者参加会议的时候,对于数据架构设计的时候,一定经常听到CAP原理,比如根据CAP原理,对于分布式设计系统,只能做到数据的最终一致性而不是实时事务的一致性;那么,这些行家或者架构师常挂在嘴边的CAP到底是什么? 先问问度娘,百度百科一下: CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
](https://architect.blog.csdn.net/article/details/53730991)
10-14
6345
[
本文固定链接: http://www.chepoo.com/elasticsearch-distributed-architecture.html | IT 技术精华网 今天介绍下ElasticSearch的分布式架构,如果你熟悉 cassandra、hadoop、mongodb,你会发现ElasticSearch里面有很多他们的影子,没错,ElasticSearch吸收了目前主流的分布
](https://blog.csdn.net/thinkone/article/details/49120709)
[
软件开发随笔系列一——分布式架构_实现__cfy_fantasyxx…
](https://blog.csdn.net/cfy_fantasyxx/article/details/104597346)
3-14
[
因此, PA + 最终一致性成为分布式系统最常用的选择了, 基本就是被表述为 BASE 了, 与 ACID 站在了两个极端。 CAP__理论作者 Eric Brewer 在《CAP Twelve Years Later: How the “Rules” Have Changed》一文中提到, 分区并不是总出现的。 Because …
](https://blog.csdn.net/cfy_fantasyxx/article/details/104597346)
[
分布式微服务架构体系详解GitChat微服务架构
](https://blog.csdn.net/valada/article/details/80993643)
3-20
[
了解分布式系统的一致性有哪些问题以及一致性的几种实现程度的模型: 线性一致性 (强一致性)、顺序一致性及因果一致性、最终一致性; 分布式一致性相关的理论 CAP(CA、CP、AP 的相关算法) 的介绍以及适合用于哪些实践; …
](https://blog.csdn.net/valada/article/details/80993643)
10-29
696
[
如下图所示,在网络中有两个节点分别为 G1 和 G2,这两个节点上存储着同一数据的不同副本,现在数据是一致的,两个副本的值都为 V0,A、B 分别是运行在 G1、G2 上与数据交互的应用程序。 ▲网络节点及数据分布图 在正常情况下,操作过程如下 (如下图所示): (1)A 将 V0 更新,数据值为 V1; (2)G1 发送消息 m 给 G2,数据 V0 更新为 V1; (3)B 读取到 G2 中的数据 V1。 ▲…
](https://blog.csdn.net/zhou85xin/article/details/84493654)
03-08
1985
[
笔者做过的一个项目中,同时用到了Elasticsearch和 Tidb 两种存储相关的产品。这两者适用的场景有些差异,但其实又有交集。前者偏向搜索,后者则主打分布式存储。下面根据自己的理解从不同维度分析下二者的相同点和不同点。 对比维度 Elasticsearch TiDB 产地 公司现在的名称是 Elastic,其实它的员工遍布世界各地,一般认为公司的总部是阿姆斯特丹 公司是 PinCa…
](https://blog.csdn.net/pony_maggie/article/details/104733964)
[
Day0701分布式教程之分布式系统详解一一哥分布式教程
](https://blog.csdn.net/syc000666/article/details/90795011)
3-13
[
一致性在系统的角度和用户的角度又有不同的等级划分, 如果要保证强一致性, 那么会影响可用性与性能, 在一些应用 (比如电商、搜索) 中是难以接受的. 如果要保证最终一致性, 那么就需要处理数据冲突的情况.CAP、FLP 这些理论告诉我们, 在分布式系统…
](https://blog.csdn.net/syc000666/article/details/90795011)
[
【ElasticSearch】all metadata 引出对 mapping 思考海…
](https://blog.csdn.net/hongwei15732623364/article/details/110821563)
3-8
[
了解这两种查询方式, 我们再来看以上两个搜索为何结果不同? 1:GET/website/article/_search?q=2017-01-01 1 搜索的是_all field,document 所有的 field 都会拼接成一个大串, 进行分词 2017-01-02 my second article this is my second…
](https://blog.csdn.net/hongwei15732623364/article/details/110821563)
07-05
128
[
1、概念介绍 CAP原则,又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本) 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性) 分区容忍性…
](https://adong.blog.csdn.net/article/details/107146930)
06-23
86
[
The short summary of the article is that CAP isn’t “C, A, or P, choose two,” but rather “When P happens, choose A or C.” Partitions, like death and taxes, are unavoidable – think of machin…
](https://blog.csdn.net/weixin_30562507/article/details/95745458)
分布式搜索 4-ElasticSearch的分布式架构原理(吐血整理!)
11-17
96
[
1、前言: (1)在搜索这块,lucene 是最流行的搜索库。几年前业内一般都问,你了解 lucene 吗?你知道倒排索引的原理吗?现在早已经 out 了,因为现在很多项目都是直接用基于 lucene 的分布式搜索引擎—— ElasticSearch,简称为 ES。 (2)现在分布式搜索已经成为大部分互联网行业 Java 系统的标配,其中尤为流行的就是 ES,前几年 ES 没火的时候,大家一般用 solr。但是这两年基本大部分企业和项目都开始转向 ES 了。所以互联网面试,肯定会跟你聊聊分布式搜索引擎,也就一
](https://blog.csdn.net/lf18879954995/article/details/109747597)
分布式搜索 2-Elasticsearch如何实现分布式(吐血整理)
11-17
112
[
(1)大概说:索引是 ES 中存储数据的基本单位,ES 中用索引存储数据,索引是拆分成多个 shard 分片进行分布式存储的,存储在多个机器上 (2)详细说:分片 Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因是为了保证分布式环境下的高可用,同时也扩大了存储空间。es 也是 master-slave 架构,在 es 中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。值得注意的是,只有建立索引和类型需要经过
](https://blog.csdn.net/lf18879954995/article/details/109747735)
08-23
4212
[
1、C# 添加 DirectShow 库 添加引用,选择 “浏览”,添加 Windows/System32/quartz.dll,引用中自动增加 QuartzTypeLib。 2、代码如下: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using S
](https://blog.csdn.net/Zhangchen9091/article/details/47916299)
08-22
2259
[
Elasticseasrch 的架构遵循其基本概念:一个采用 Restful API 标准的 高扩展性 和 高可用性 的 实时数据分析 的全文搜索工具。 高扩展性:体现在Elasticsearch添加节点非常简单,新节点无需做复杂的配置,只要配置好集群信息将会被集群自动发现。 高可用性:因为Elasticsearch是分布式的,每个节点都会有备份,所以 down 一两个节点也不会出现问题,集群会通过备份…
](https://blog.csdn.net/zx711166/article/details/81952827)
拥抱 Elasticsearch:给 TiDB 插上全文检索的翅膀
12-10
1170
[
作者介绍:孙晓光,知乎技术平台负责人,与薛宁(@Inke)、黄梦龙(@PingCAP)、冯博(@知乎)组队参加了 TiDB Hackathon 2019,他们的项目 TiSearch 获得了 CTO 特别奖。 “搜索”是大家在使用各种 APP 中非常重要的一个行为,对于知乎这样以海量优质内容为特色的产品来说,借助搜索帮助用户准确、快速地触达想要寻找的内容更是至关重要。而 “全文检索” 则是隐藏在简…
](https://blog.csdn.net/TiDB_PingCAP/article/details/103473555)
elasticsearch 代码分析之 modules and services
10-09
934
[
最近需要研究搜索的集群。由于大脑日渐萎缩,只好把代码记下来以供参考,好久没在 csdn 上写东西了,呵呵。elasticsearch是一个基于 lucene 的搜索集群,关于 lucene 的介绍有如下参考:Annotated-Lucene 源码剖析中文版 Architecture and Implementation of Apache Lucene Lucene 源码_分析_elasticsesarch 作为一
](https://blog.csdn.net/ttjslbz/article/details/48996531)
©️2020 CSDN 皮肤主题: 大白 设计师: CSDN 官方博客 返回首页
- 关于我们
- 招贤纳士
- 广告服务
- 开发助手

400-660-0108
kefu@csdn.net
在线客服- 工作时间 8:30-22:00

公安备案号 11010502030143- 京 ICP 备 19004658 号
- 京网文〔2020〕1039-165 号
- 经营性网站备案信息
- 北京互联网违法和不良信息举报中心
- 网络 110 报警服务
- 中国互联网举报中心
- 家长监护
- Chrome 商店下载
- ©1999-2021 北京创新乐知网络技术有限公司
- 版权与免责声明
- 版权申诉
沧 hi CSDN 认证博客专家 CSDN 认证企业博客
码龄 4 年 
暂无认证
[
47
原创
](https://blog.csdn.net/zjltju1203)
[
9 万 +
周排名
](https://blog.csdn.net/rank/list/weekly)
[
13 万 +
总排名
](https://blog.csdn.net/rank/list/total)
2 万 +
访问

等级
757
积分
31
粉丝
31
获赞
7
评论
119
收藏
关注

热门文章
- 24 种设计模式(一)
5946 - Error accessing PooledConnection. Connection is invalid. 问题处理总结
2618 - 结合 CAP 理论分析 ElasticSearch 的分布式实现方式
1874 - Android Studio 删除创建的 Virtual Device
1693 - java 三年面试题(分布式篇)不定期更新
1459
分类专栏






最新评论
- 结合 CAP 理论分析 ElasticSearch 的分布式实现方式
mlzdev: cp 才对 - Android Studio 删除创建的 Virtual Device
hope dust: 我记得 avd 必须要和 sdk 是在同一路径下才能使用的,我把 sdk 删了之后,重新看那个虚拟机的下载界面,这次它需要下载。 - Android Studio 删除创建的 Virtual Device
hope dust: 没用,就算你删除了虚拟机,但是,你在 avd 下载里面找你刚刚删除的那个虚拟机(去它的下载界面看看),你会发现它不需要下载,因为你没删除干净。 我折腾半天了,就算是把整个. android 文件夹删除了,只要你运行一下 avd 它就又回来了。 - 结合 CAP 理论分析 ElasticSearch 的分布式实现方式
1e0zj 回复 wudalang5: 因为分布式系统中所有节点读到的数据都是一致的啊(都是旧数据或者都是新数据),不会有部分节点新部分节点是旧数据这种情况 - 结合 CAP 理论分析 ElasticSearch 的分布式实现方式
wudalang5: ?没回复上看不到呢
最新文章
目录
目录
分类专栏
举报
选择你想要举报的内容(必选)
- 内容涉黄
- 政治相关
- 内容抄袭
- 涉嫌广告
- 内容侵权
- 侮辱谩骂
- 样式问题
- 其他
原文链接(必填)
请选择具体原因(必选)
- 包含不实信息
- 涉及个人隐私
请选择具体原因(必选)
- 侮辱谩骂
- 诽谤
请选择具体原因(必选)
- 搬家样式
- 博文样式
补充说明(选填)
取消
确定

新手
引导
客服 举报 
返回
顶部
https://blog.csdn.net/zjltju1203/article/details/100830271

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}