一、Binary Search Tree(二叉搜索树)
1. 二分查找法,Binary Search
//递归实现template<typename T>int binarySearch(T arr[],int n,T target){int mid = n/2;if(n==0)return -1;else if(arr[mid] == target)return mid;else if(arr[mid] < target){return binarySearch(arr+mid+1,n-mid-1,target);}else{return binarySearch(arr,mid,target);}}//循环实现template<typename T>int binarySearch(T arr[],int n,T target){int l = 0,r = n-1;while(l<=r){//不用(l+r)/2的原因是,两个数都非常大时,相加可能溢出int mid = l+(l-r)/2;if (arr[mid] == target)return mid;else if(arr[mid]<target)l = mid +1;elser = mid -1;}return -1;}
- 对于有序数组,才能使用二分查找法
- 二分查找法的思想在1946年提出,第一个没有bug的二分查找在1962年才出现
2. 查底与查顶,Floor and Ceil
在经典的BinarySearch中,如果查找目标在数组中存在重复元素,那么将不确定返回哪个目标的index
Floor和Ceil则是为了解决这个问题而产生的二分查找的变种:
- Floor返回数组中第一个目标元素索引,Ceil返回数组中最后一个目标元素索引
- 若数组中没有找到目标,则Floor返回与目标最近的小于目标的元素索引;Ceil返回与目标最近的大于目标的元素索引
```cpp
template
int Floor(T arr[], int n, T target) { //如果target小于arr所有的元素,则返回-1 int l = -1, r = n - 1; //这里不能写等于,因为l在循环中是有可能不会变的,所以l = mid = midL = midR = r时就可能会死循环,也不需要写等于,因为l索引对应的元素是已经搜索过的 while (l < r) {
} return l; }//当l = r - 1时,mid = r,这里不能让mid = l,因为后面l的变化值为midR,若midR = mid且arr[mid]<target,会陷入l值不变的死循环int mid = l + (r - l + 1) / 2;int midL = mid;int midR = mid;while (midL - 1 >= 0 && arr[midL - 1] == arr[midL])midL--;while (midR + 1 <= n - 1 && arr[midR + 1] == arr[midR])midR++;if (arr[mid] == target)return midL;else if (arr[mid] < target)l = midR;elser = midL - 1;
template
Floor和Ceil的实现思路:
- Floor和Ceil的第一个特性很容易实现,只需要在`arr[mid] = target`时,使用while循环将索引移动到第一个或最后一个与arr[mid]相等的元素即可,而且既然存在已排好序的重复元素,我们在搜索缩小范围时也不用一个一个元素排除了,可以直接排除所有的重复元素。
- Floor和Ceil的第二个特性就需要思考了。
我们分析普通的BinarySearch,如果一个元素不等于target,就会在下一次循环中将其排除,比如从序列`{1,2,3,5,6}`中查找4时,`arr[mid] = 3`,下一次搜索就会从`{5,6}`中进行,`{3}`被排除,而Floor函数需要找的就是的`{3}`索引,那么我们要实现的就是在不排除所有mid元素的情况下不断缩小搜索范围,直到`l = r`,Floor需要的是target左边最末尾的索引,那么我们需要排除的就是其他重复元素,留下末尾这个元素,即当`arr[mid]<target`时,`l = midR`而非经典BinarySearch的`l = midR+1`。
<a name="RIJqe"></a>
## 3. 二叉搜索树,Binary Search Tree
二叉搜索树的主要用途是来实现**查找表**,即**Key-Value**的字典数据结构<br />
> Q:如果Key是整数的话,为什么不用普通数组来实现字典结构呢
> A:是可以的,如果Key的范围比较小,且连续性高的话;如果Key范围较大,分布较离散,那么就会造成许多的空间浪费,从时间复杂度上来讲,数组也没有优势
| | 查找元素 | 插入元素 | 删除元素 |
| --- | --- | --- | --- |
| 普通数组 | O(n) | O(n) | O(n) |
| 顺序数组 | O(log<sub>2</sub>n) | O(n) | O(n) |
| 二分搜索树 | O(log<sub>2</sub>n) | O(log<sub>2</sub>n) | O(log<sub>2</sub>n) |
二分搜索树的优点:
- 高效地查找、插入、删除
- 可以方便地解决min、max、floor、ceil、rank、select的问题
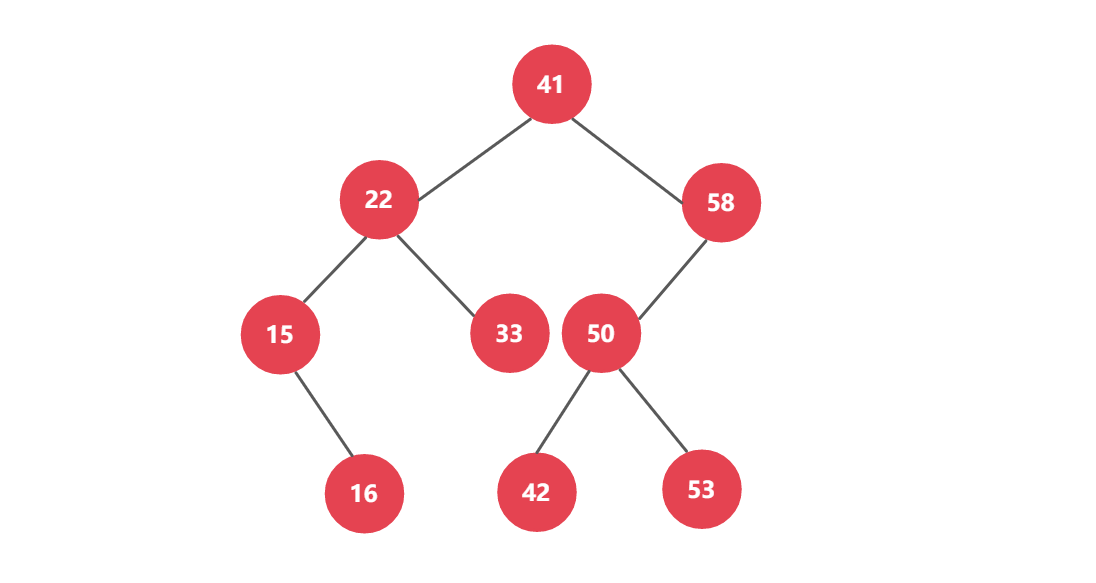
二分搜索树的特点:
- 每个节点的键值大于左孩子,小于右孩子,以左右孩子为根的子树仍为二分搜索树
- 不需要是一颗完全二叉树
_所以用数组来模拟并不方便,堆用数组来模拟是因为堆是完 全二叉树_
- 上图节点中的值是Key的值,Value的值并没有表现
---
二叉搜索树插入:
```cpp
template <typename Key, typename Value>
BST<Key, Value>::Node *BST<Key, Value>::insertNode(Node *node, Key key, Value value)
{
//node为根节点,nodeI为要插入的节点,返回值为插入的树的根
if (node == nullptr)
{
count++;
return new Node(key, value);
}
else if (node->key == key)
{
node->value = value;
return node;
}
else if (node->key < key)
{
node->right = insertNode(node->right, key, value);
}
else
node->left = insertNode(node->left, key, value);
return node;
}
template <typename Key, typename Value>
void BST<Key, Value>::insert(Key key, Value value)
{
root = insertNode(root, key, value);
}
二叉搜索树查找:
template <typename Key,typename Value>
Value* BST<Key,Value>::search(Key key){
Node* node = root;
while(node!=nullptr){
if(node->key == key)
return &(node->value);
else if(node->key < key)
node = node->right;
else
node = node->left;
}
return nullptr;
}
逻辑简单,但需要注意返回值的设计:
- 返回Node, Node属于private成员,牵扯到Node的成员函数全部属于priavte,目的就是不要让用户感觉到Node的存在。返回Node暴露给外部Node的存在会影响封装性。
- 返回Value,当没有找到对应值时,难以返回合适的值。也有解决方法,那就是在search中加上
assert(isContain()),这样会增大开销 - 返回Value*,当没有找到对应值时,返回nullptr,找到对应值就返回对应值的指针
二叉搜索树的遍历:
前中后序遍历的前、中、后表示的是访问根结点顺序。
在析构函数中就应该使用后序遍历来对整个树完成析构
前序遍历并打印:(深度优先遍历)
template <typename Key,typename Value> void BST<Key,Value>::preOrder(Node* root){ if(root==nullptr) return; std::cout<<root->key; preOrder(root->left); preOrder(root->right); } template <typename Key,typename Value> void BST<Key,Value>::preOrder(){ preOrder(root); }中序遍历: ```cpp template
void BST return; inOrder(root->left);std::cout<
key; inOrder(root->right); } template void BST
按从小到大的顺序输出,因为二分搜索树的左子树<根<右子树
- 后序遍历:
```cpp
template <typename Key,typename Value>
void BST<Key,Value>::postOrder(){
template <typename Key,typename Value>
void BST<Key,Value>::postOrder(){
postOrder(root);
}
广度优先遍历(层序遍历),使用队列
template

若有收获,就点个赞吧
0 人点赞
