Selection Sort
Bubble Sort
Insertion Sort
Shell Sort
Merge Sort
Quick Sort
以上部分仅仅实现了代码放在文末,所以就不展开了
一、Heap Sort
重点放在Heap这种数据结构上,而非排序,排序只是堆的一个应用
1. 堆和优先队列,Heap and Priority Queue
普通队列:先进先出,后进后出,优先级按到来的时间顺序
优先队列:出队顺序和入队顺序无关,和优先级有关;
操作系统执行任务的顺序就是一种优先队列 ,动态选择优先级最高的任务来执行。
在优先队列中,任务会不断增加和减少,任务的优先级会实时变化。
在一些高级的优先队列中,除了随队列增减改变外,甚至已存在的任务的优先级也会随时变化,如操作系统的任务执行队列。
所以, 优先队列的执行顺序问题就是一个复杂的动态问题,靠一次排序无法解决,而实时的排序开销又很大。
那么我们为何不借用插入排序的思想,来维护一个本身就已经排好序的队列呢?这就涉及到了优先队列数据结构的选择:
对于总共的N个入队或出队请求:
- 使用普通数组或顺序数组,最差情况的时间复杂度:O(n^2)
- 使用堆:O(nlgn)
2. 堆的实现,The implement of Heap
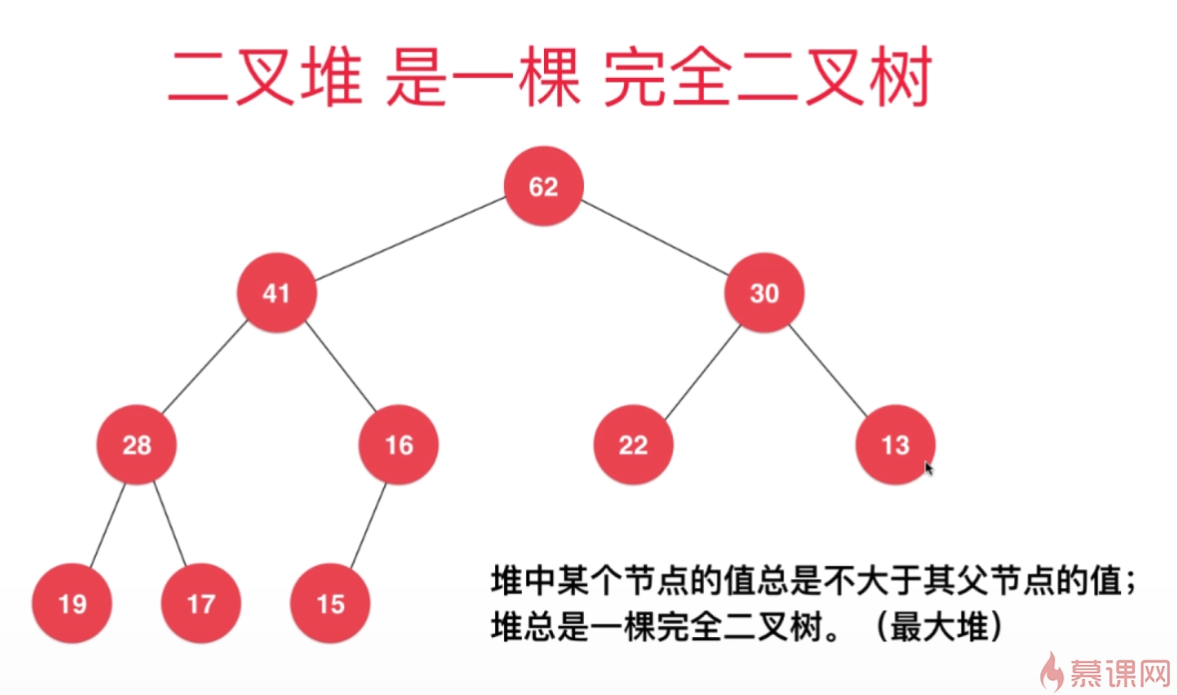
二叉堆的两个性质:
- 必须是一颗完全二叉树(除了最后一层,其他层的节点个数必须达到最大,最后一层若没有填满,其节点需集中在左边)
- 任意一个节点的值总是不大于其父节点的值(最大堆,根是最大值)
这并不意味着上层节点的值一定大于下层节点,因为左子树
和右子树并未规定大小关系
二叉堆既然是一颗树的话,那么我们是不是应该用树来实现二叉堆呢?其实完全二叉树有一种经典的实现那就是数组,所以我们用数组来实现二叉堆。

用数组来实现二叉堆:
- 左节点的节点号是父节点的2倍
- 右节点的节点号是父节点的2倍加1
- 节点编号除以2就是父节点(C++取整除法)
如果从0开始标号,上述规律会发生改变,如果想要使用原规律,我们可以从数组的1号位开始存储根节点数据
Heap.h:
#ifndef HEAPSORT_H#define HEAPSORT_H#include <iostream>#include <cassert>#include <algorithm>#include <cmath>template <typename Item>class MaxHeap{private:Item *data; //堆int count; //节点个数int capacity; //最大容量void shiftUp(int);void shiftDown(int);public:MaxHeap(int capacity) : capacity(capacity), count(0){data = new Item[capacity + 1];}MaxHeap(const Item arr[], int n, int capacity) : capacity(capacity), count(n){data = new Item[capacity + 1];for (int i = 1; i <= n; i++){data[i] = arr[i - 1];}for (int i = count / 2; i >= 1; i--){shiftDown(i);}}~MaxHeap() { delete[] data; }bool isEmpty() const { return count == 0; }int size() const { return count; }void insert(Item item){assert(count < capacity);data[++count] = item;shiftUp(count);}Item extractMax(){assert(!isEmpty());std::swap(data[1], data[count]);count--;shiftDown(1);return data[count + 1];}std::ostream &show(std::ostream &os) const;friend std::ostream &operator<<(std::ostream &os, const MaxHeap &maxHeap){return maxHeap.show(os);}};template <typename T>std::ostream &printNum(std::ostream &os, int n, T item){for (int i = 0; i < n; i++)os << " ";os << item;if (typeid(item).name() == "int" && item > 10)os << ' ';for (int i = 0; i < n; i++)os << " ";os << " ";return os;}template <typename Item>std::ostream &MaxHeap<Item>::show(std::ostream &os) const{int h = log2(count); //层数,从零开始int lastFloor = pow(2, h); //最后一层能容纳的最大数量int blankNum = lastFloor - 1; //第一层应打印的空格数int rest = count; //堆剩余元素的数量for (int i = 0; i <= h; i++){int j;for (j = 0; j < fmin(rest, pow(2, i)); j++){printNum(os, blankNum, data[(int)pow(2, i) + j]);}os << std::endl;blankNum /= 2;rest -= j;}return os;}template <typename Item>void MaxHeap<Item>::shiftUp(int k){Item aux = data[k];while (k / 2 >= 1 && data[k / 2] < aux){ //当节点k有父节点,且父节点小于子节点时data[k] = data[k / 2];k /= 2;}data[k] = aux;}template <typename Item>void MaxHeap<Item>::shiftDown(int k){Item aux = data[k];while (2 * k <= count){ //当节点k有子树时,只需要选出子树节点中最大的节点与父节点比较就行,比父节点大的话就上去int j = 2 * k;if (j + 1 <= count && data[j + 1] > data[j])j += 1;if (data[j] > aux){data[k] = data[j];k = j;}elsebreak;}data[k] = aux;}template <typename T>void heapSort(T array[], int n){MaxHeap<T> maxHeap = MaxHeap<T>(array, n, n);for (int i = n - 1; i >= 0; i--){array[i] = maxHeap.extractMax();}}#endif
堆的关键操作:
- void shiftUp(int k),O(logn)
- void shiftDown(int k),O(logn)
- 根据数组生成堆(维护乱序堆),
heapify算法,从第一个非叶子节点(从1开始编号的话,就是count/2)开始按序号递减顺序依次进行shiftDown,O(n)
堆的维护就是靠shiftUp和shiftDown来实现:
当插入新的节点时,我们将节点置于二叉堆的最末尾,然后对该节点进行shiftUp操作就可以完成插入;
当取出根节点时,我们将根节点与二叉堆的最后一个节点交换位置,然后对根节点进行shiftDown操作就可以完成取出;_shiftUp_操作只需要不断向父节点比较就可以了,但_shiftDown_需要先选出子节点中较大的那一个再进行比较;判断节点 k是否有父节点_if(k/2>=1)_,是否有子树_if(2*k<=count)_
3. 堆排序
通过构建上面的堆,我们可以很显然的得到一个排序的方法,使用Heapify算法构建一个MaxHeap,然后依次取出根节点就行了,构建过程的时间复杂度是O(n),依次取出n个根节点的排序过程是O(nlogn)。
这个排序可以在需要排序的原数组上完成,也可以新开辟一个二叉堆数组空间来完成。下面给出原地完成的算法:
heapSort.h:
template <typename T>
void shiftDownLocal(T array[], int k, int count)
{
T aux = array[k];
while (2 * k + 1 <= count - 1)
{
int j = 2 * k + 1;
if (j + 1 <= count - 1 && array[j + 1] > array[j])
j += 1;
if (aux < array[j])
{
array[k] = array[j];
k = j;
}
else
break;
}
array[k] = aux;
}
template <typename T>
void heapSortLocal(T array[], int n)
{ //原地堆排序需要注意的问题就是,数字编号是从零开始的,子节点就是,2k+1和2k+2,父节点就是(k+1)/2 -1
for (int i = n / 2 - 1; i >= 0; i--)
{
shiftDownLocal(array, i, n);
}
for (int i = 0; i < n; i++)
{
std::swap(array[0], array[n - 1 - i]);
shiftDownLocal(array, 0, n - 1 - i);
}
}
4. 更高级的索引堆
普通二叉堆的问题:
- 在使用 Heapify 算法来构建堆的过程,需要频繁进行元素交换,如果元素的构造比较复杂(比如每个元素都是十万字的文章),则会造成较大的开销
- 在建堆的过程中,元素的位置发生了改变,所以在建堆完成后,难以再索引到之前的元素,如果原始索引和数据之间存在特殊意义,那么建堆后这种特殊意义将会被破坏
比如操作系统的任务,数组索引是任务进程 id,而索引中的数据就是对应任务的优先级,在建堆后这种对应关系将会破坏
这些问题可以通过建立索引堆来解决:
- 索引堆的思想就是使用数据的索引来代替数据本身,用一个额外的数组来存储这些索引,然后对这些索引进行建堆,索引之间的大小比较就看索引指向的数据的大小
- 因为对索引进行建堆,所以为了方便的连接索引的父子节点,索引数组的计数可以从1开始,而数据数组不建堆,其数组的计数就可以从零开始
对用户而言,他们所看到的只是一个普通的数组
索引堆主要是为了解决索引带有特殊意义的优先队列问题,所以难免会遇到需要修改data数组特定编号下的内容的情况,当data数组某个编号下的值被修改后,索引堆需要对该值的索引进行一次
shiftUp()、shiftDown()来维护堆,那么查找data数组的编号在索引堆的位置就是一个O(n)时间级别的开销,我们可以用一个rev数组记录每个data数组编号在索引堆中的位置来将O(n)时间上的开销转化为O(n)空间上的开销

IndexMaxHeap.h:
template <typename Item>
class IndexMaxHeap
{
private:
Item *data; //最大堆数据
int *index; //数据的索引,用索引代替数据构建堆
int *rev; //记录索引在堆中的位置,与index相反的指针;reverse,反向的
int count; //当前堆中数据的个数
int capacity; //索引堆的最大容量
void changeIndex(int arrIndex, int arrData)
{ //使用该函数来改变index数组的内容,同时维护rev数组
index[arrIndex] = arrData;
rev[arrData] = arrIndex;
}
void shiftDown(int k);
void shiftUp(int k);
public:
IndexMaxHeap(int capacity) : capacity(capacity), count(0)
{
//为方便理解,以下的索引指的是Index里的内容,编号指的是数组的编号,所以Index存储的索引指的是data数组里Item的编号
data = new Item[capacity]; //存储堆中的数据,从外部来看,数据应当是以一个普通数组的形式存在,所以data从零开始编号
index = new int[capacity + 1]; //因为真正变成堆的是索引,索引从1开始计数,方便计算索引的父子节点
rev = new int[capacity]; //索引的范围是[0,capacity),故rev的容量为capacity即可
for (int i = 0; i < capacity; i++)
{
rev[i] = -1;
index[i] = -1;
}
index[capacity] = -1;
}
IndexMaxHeap(Item array[], int n, int capacity) : capacity(capacity), count(n)
{
data = new Item[capacity]; //存储堆中的数据,从外部来看,数据应当是以一个普通数组的形式存在,所以data从零开始编号
index = new int[capacity + 1]; //因为真正变成堆的是索引,索引从1开始计数,方便计算索引的父子节点
rev = new int[capacity]; //索引的范围是[0,capacity),故rev的容量为capacity即可
for (int i = 0; i < capacity; i++)
{
rev[i] = -1;
index[i] = -1;
}
index[capacity] = -1;
for (int i = 0; i < count; i++)
{
data[i] = array[i];
changeIndex(i + 1, i);
}
for (int i = count / 2; i >= 1; i--)
{
shiftDown(i);
}
}
~IndexMaxHeap()
{
delete[] data;
delete[] index;
delete[] rev;
}
bool isEmpty() const { return count == 0; }
int size() const { return count; }
Item extractMax()
{
assert(!isEmpty());
int temp = index[1];
changeIndex(1, index[count]);
changeIndex(count, temp);
count--;
shiftDown(1);
return data[index[count + 1]];
}
void insert(int k, Item item)
{
assert(k < capacity);
data[k] = item;
count++;
changeIndex(count, k);
shiftUp(count);
}
void change(int k, Item item)
{
data[k] = item;
shiftUp(rev[k]);
shiftDown(rev[k]);
}
bool contain(int k) const //堆中是否包含数组编号k
{
assert(k >= 1 && k <= capacity);
return rev[k] >= 1 && rev[k] <= count;
}
};
template <typename Item>
void IndexMaxHeap<Item>::shiftDown(int k)
{
Item aux = index[k]; //与插入排序相似的操作,先申请一个辅助空间
while (2 * k <= count)
{ //若存在子树
int j = 2 * k;
if (j + 1 <= count && data[index[j + 1]] > data[index[j]])
j += 1;
if (data[aux] >= data[index[j]])
break;
else
{
changeIndex(k, index[j]);
k = j;
}
}
changeIndex(k, aux);
}
template <typename Item>
void IndexMaxHeap<Item>::shiftUp(int k)
{
Item aux = index[k];
while (k / 2 >= 1 && data[index[k / 2]] < data[aux])
{
changeIndex(k, index[k / 2]);
k /= 2;
}
changeIndex(k, aux);
}
以上代码基本上实现了索引堆,但是还有一个小点没有实现,那就是 _extractMax()_中 data数组数据没有删除,这个问题在普通二叉堆中不需要考虑,因为被取出的数据会移动到数组末尾,被排除在 count 之外;
而索引堆中,如果_extractMax()_如果不将 data数组数据删除,count的意义在data数组上会失效,按上面的实现方法,在用户按规则_insert(int k,Item item)_的情况下,data数组的空间会无法有效利用;
这个问题有两种解决办法:
- 在
_extractMax()_过程中删除数组数据,然后data数组索引依次前移,对应索引堆中的数组编号依次减一,这个很简单实现,利用rev快速查找到原编号所在的索引堆位置,利用changeIndex函数将编号减一即可,但计算开销变大 - 在
extractMax()过程中删除数组数据,存储删除的位置到栈,下一次insert()时,插入栈顶的位置,若栈空则插入到数组末尾,这样的做法计算开销小,但又需要一个数组的空间来作为栈
5. 和堆相关的问题

- 使用堆实现优先队列
游戏中优先锁敌、操作系统中的优先任务调度、在1,000,000
个元素中选出前100名
在1,000,000(N)个元素中选出前100(M)名,这个问题看似是O(MlogN)的时间复杂度,O(N)的空间复杂度,实际上可以做到O(NlogM)的时间复杂度,O(M)的空间复杂度。 前者是用1,000,000的数组构建最大堆,
extraMax()100次; 后者是先用100的数组构建最小堆,然后遍历剩余的999,900个元素,每次insert()一个新元素后都extraMin()一个最小元素,最后就得到了最大的前100个元素

- 多路归并排序,当分成n路时,就退化成了堆排序
需要比较每一路中元素的大小,可以将每一路中开头的元素都放入最小堆中,每次_extractMin()_一个元素后再_insert()_该路的下一个元素
- d叉堆
层数下降的代价是维护过程中需要更多次的比较,如_shiftDown()_

- 还剩下capacity动态扩容没有实现

- 可以使用两个索引数组构建一个最大堆、最小堆

- 速度更快或特殊场合有更好性能
二、Sort Conclusion,排序总结
1. 插入、归并、快速、堆排序比较

归并排序在合并时需要O(n)大小的空间,快速排序因为有O(logn)层的递归,每层递归都需要常数级别的空间来保存临时变量、返回地址等。
2. 排序算法的稳定性
插入排序,归并排序,冒泡排序是稳定排序,其他常见排序都是不稳定的:
- 快速排序随机选择标定点,如果后方的相等元素先被选择,且实现时,该元素最后被交换到了相等部分的前方,则稳定性被破坏。
- 选择排序涉及到大跨度的交换,例子:{10,10,7}
- 希尔排序也涉及到大跨度的交换,稳定性难以保障
- 插入排序和归并排序和冒泡排序的稳定性和等于号怎么处理关系很大,他们都可以实现成稳定排序
排序算法的稳定性问题可以通过重载
<来解决

三、选择、冒泡、插入、希尔、归并、快速排序的实现
代码比较多就不展开了,放上代码地址:

若有收获,就点个赞吧
0 人点赞
