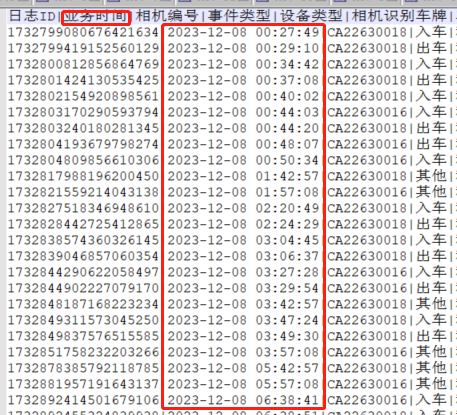
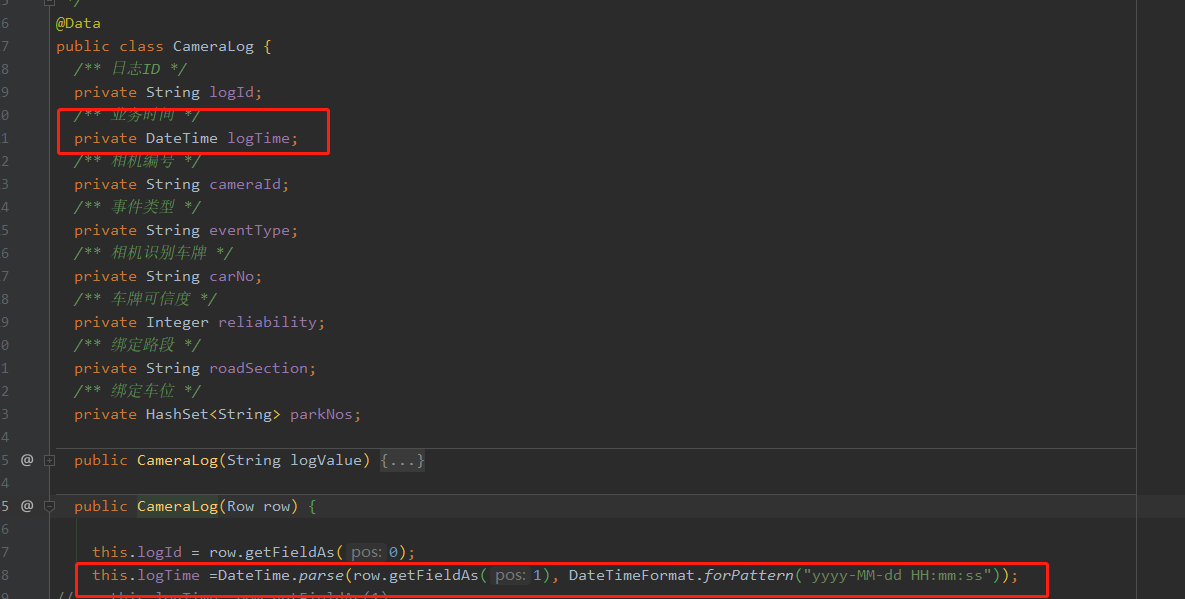
有以上这么一份csv数据,在用flink处理时,将每行数据转为一个对象,其中业务时间这个字段用jodatime进行解析;在后面算子处理时用到这个业务时间属性时,却报空指针;排查一下发现是在日志源数据转为对象后发送到下游算子时业务时间属性已经为空了。
解决办法:第一步,引入kyro依赖,第二步指定序列化器
<dependency><groupId>de.javakaffee</groupId><artifactId>kryo-serializers</artifactId><version>0.45</version></dependency>
env.registerTypeWithKryoSerializer(DateTime.class, JodaDateTimeSerializer.class);
顺便记录一下flink序列化器
addDefaultKryoSerializer(Class<?> type, Serializer<?> serializer):使用给定的 type 注册 Kryo 序列化器实例。addDefaultKryoSerializer(Class<?> type, Class<? extends Serializer<?>> serializerClass):使用给定的 type 注册 Kryo 序列化器实例。
registerTypeWithKryoSerializer(Class<?> type, Serializer<?> serializer):使用 Kryo 注册给定的类型,并为他指定一个序列化器。使用 Kryo 注册一个类型,可以使该类型的序列化更加有效。registerKryoType(Class<?> type):如果类型最终被 Kryo 序列化,之后它将会被注册到 Kryo,以确定值写入标签信息(integer ID)。如果类型没有被 Kryo 序列化,则每个示例的整个类名都将会被序列化,这将导致很多 I/O 消耗。
registerPojoType(Class<?> type):使用序列化堆栈注册给定的类型。如果类型最终被序列化为 POJO,然后类型就会使用 POJO 序列化器注册。如果类型最终被序列化为 Kryo,然后他将会被注册为 Kryo,以保证值写入标签。如果类型没有被注册为 Kryo,则每个实例的整个类名都将会被序列化,这将导致很高的 I/O 消耗。
注意,使用 registerKryoType() 注册的类型对于 Flink 的 POJO 序列化器实例中是不可用的。disableAutoTypeRegistration():默认开启类型自动注册。用户代码会使用 Kryo 和 POJO 序列化器来自动类型注册所有的类型,包括子类型。
再顺便记录一下 de.javakaffee 下的kryo-serializers
简介:Additional kryo (http://kryo.googlecode.com) serializers for standard jdk types (e.g. currency, jdk proxies) and some for external libs (e.g. joda time, cglib proxies, wicket).

若有收获,就点个赞吧
0 人点赞
