先来个GitHub地址: https://github.com/uber-common/jvm-profiler
简介(机翻,将就看下):Uber JVM Profiler提供了一个Java Agent,以分布式的方式收集Hadoop/Spark JVM进程的各种指标和堆栈跟踪,例如CPU/内存/IO指标。
Uber JVM Profiler还提供了高级分析功能,可以在不需要更改用户代码的情况下跟踪用户代码上的任意Java方法和参数。该特性可用于跟踪每个Spark应用程序的HDFS名称节点调用延迟,并识别名称节点的瓶颈。它还可以跟踪每个Spark应用程序读取或写入的HDFS文件路径,并识别热文件以进行进一步优化。
这个分析器最初是用来分析Spark应用程序的,通常一个应用程序有几十个或几百个进程/机器,所以人们可以很容易地将这些不同进程/机器的指标联系起来。它也是一个通用的Java代理,也可以用于任何JVM进程。
思路:这个插件呢,是个Java agent,不侵入代码,友好,带有这个插件的sparkjob会在后台每隔指定时间间隔往我们指定的reporter(console,Kafka等)发送内存cpu资源消耗数据。刚好我们在配置一个spark任务的时候指定cpu内存资源时都是按照经验写的🙃,多数情况下为了保证任务正常运行,资源都是给多了,其实浪费了,而有了这个插件就能为我们对资源参数优化提供数据支撑了。
说完废话,开整~,我的任务运行在k8s中,通过spark-k8s-operator。
conf.set("spark.executor.extraJavaOptions",s"-javaagent:/opt/spark/jars/jvm-profiler-1.0.0.jar=reporter=com.uber.profiling.reporters.KafkaOutputReporter,metricInterval=10000,brokerList=broker01:9092,topicPrefix=spark_executor_jvm_profiler_")/*** spark.executor.extraJavaOptions 这个是指定executor的额外的Java启动参数,当然还能指定driver的* -javaagent:/opt/spark/jars/jvm-profiler-1.0.0.jar= 指定Java agent的jar包位置。* reporter=com.uber.profiling.reporters.KafkaOutputReporter 指定为Kafkareporter* metricInterval=10000 数据采集时间间隔 毫秒* brokerList=broker01:9092 Kafka的broker地址* topicPrefix=spark_executor_jvm_profiler_ topic前缀,最后会有两个topic,spark_executor_jvm_profiler_CpuAndMemory 和 spark_executor_jvm_profiler_ProcessInfo*/
结果Kafka数据:
{"heapMemoryMax":1049100288,"role":"executor","nonHeapMemoryTotalUsed":131975152,"bufferPools":[{"totalCapacity":446329,"name":"direct","count":9,"memoryUsed":446330},{"totalCapacity":0,"name":"mapped","count":0,"memoryUsed":0}],"heapMemoryTotalUsed":385725280,"vmRSS":926433280,"epochMillis":1705601229434,"nonHeapMemoryCommitted":134635520,"heapMemoryCommitted":1049100288,"memoryPools":[{"peakUsageMax":251658240,"usageMax":251658240,"peakUsageUsed":33978944,"name":"Code Cache","peakUsageCommitted":34275328,"usageUsed":33978944,"type":"Non-heap memory","usageCommitted":34275328},{"peakUsageMax":-1,"usageMax":-1,"peakUsageUsed":87132352,"name":"Metaspace","peakUsageCommitted":88956928,"usageUsed":87132352,"type":"Non-heap memory","usageCommitted":88956928},{"peakUsageMax":1073741824,"usageMax":1073741824,"peakUsageUsed":10863856,"name":"Compressed Class Space","peakUsageCommitted":11403264,"usageUsed":10863856,"type":"Non-heap memory","usageCommitted":11403264},{"peakUsageMax":344981504,"usageMax":309329920,"peakUsageUsed":340787200,"name":"PS Eden Space","peakUsageCommitted":340787200,"usageUsed":92549024,"type":"Heap memory","usageCommitted":308805632},{"peakUsageMax":58720256,"usageMax":24117248,"peakUsageUsed":44559888,"name":"PS Survivor Space","peakUsageCommitted":58720256,"usageUsed":3010920,"type":"Heap memory","usageCommitted":24117248},{"peakUsageMax":716177408,"usageMax":716177408,"peakUsageUsed":290179432,"name":"PS Old Gen","peakUsageCommitted":716177408,"usageUsed":290179432,"type":"Heap memory","usageCommitted":716177408}],"processCpuLoad":0.10739614994934144,"systemCpuLoad":0.11448834853090172,"processCpuTime":93190000000,"vmHWM":926433280,"appId":"spark-2d8e2e97d77542a48132dc8cc5697049","vmPeak":3852488704,"name":"37@jobname-2024-01-18-1705600859876-exec-1","host":"jobname-2024-01-18-1705600859876-exec-1","processUuid":"1493c603-54d3-424a-8343-65e9980338df","nonHeapMemoryMax":-1,"vmSize":3852484608,"gc":[{"collectionTime":1351,"name":"PS Scavenge","collectionCount":217},{"collectionTime":203,"name":"PS MarkSweep","collectionCount":3}]}
ok,这就拿到了我们的监控数据了:
接着我们可以写一个数据处理任务来处理这些监控数据,在此之前我们得知道这些数据是什么含义:
更详细的官方文档:https://github.com/uber-common/jvm-profiler/blob/master/metricDetails.md
| 指标key | 含义 | 备注 |
|---|---|---|
| heapMemoryMax | 可以使用的最大内存量(以字节为单位) | |
| role | executor or driver | |
| heapMemoryTotalUsed | 堆内存使用总量 | |
| vmRSS | 以字节为单位的JVM物理内存使用量(常驻集大小)。 | |
| vmHWM | JVM的常驻集的峰值大小(“高水位”),以字节为单位。 | |
| appId | spark任务的appid | |
| vmPeak | JVM虚拟内存使用的峰值(以字节为单位) | |
| host | 主机名称 | |
| vmSize | JVM的虚拟内存大小。 | |
| systemCpuLoad | 系统cpu负载 | |
| processCpuLoad | 进程cpu负载 |
最后,离线任务跑出统计数据,上看板
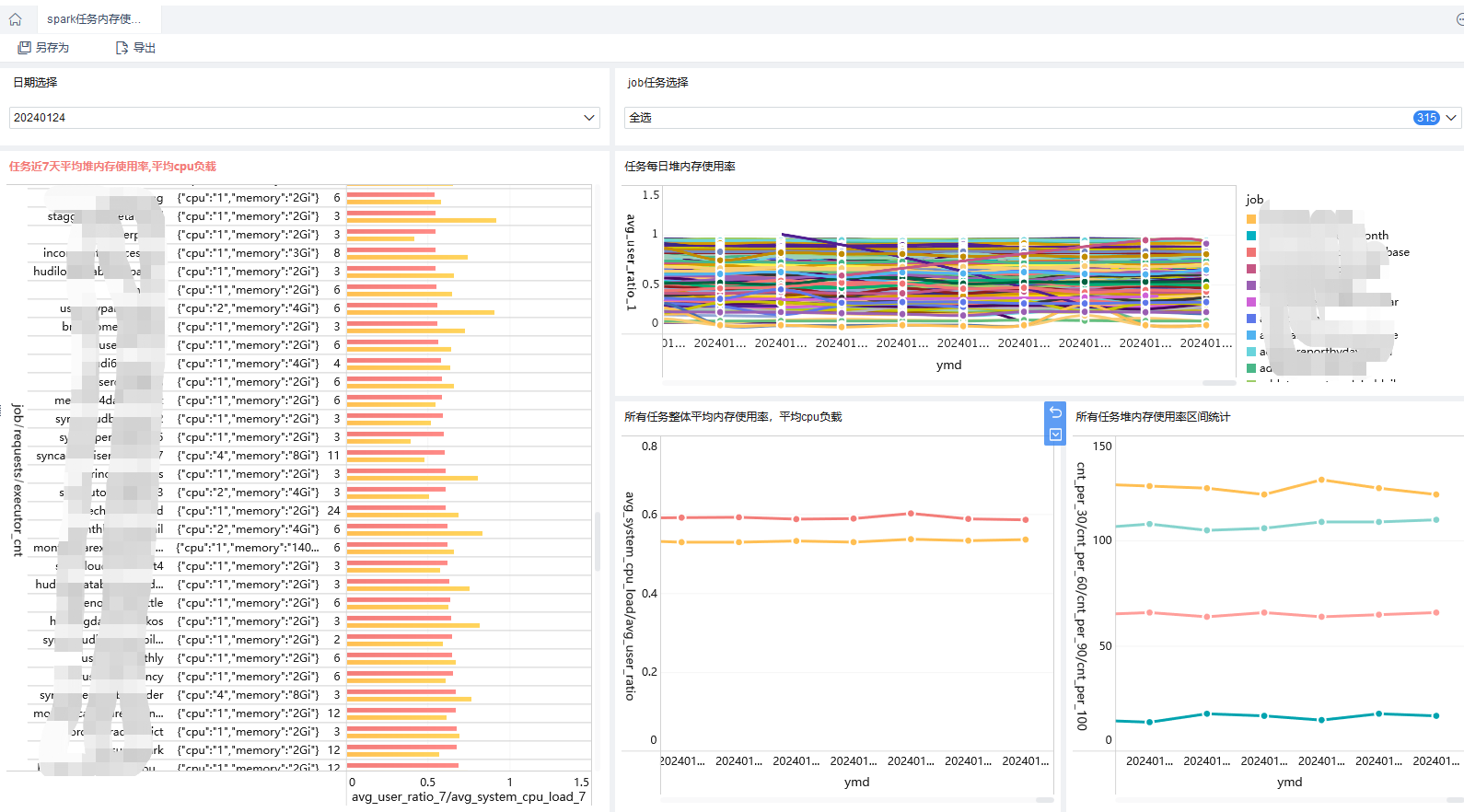

若有收获,就点个赞吧
0 人点赞
